

引言
💎💎💎 一篇思考前端基础知识的文章
相信大家已经对
从URL到页面渲染过程
进程和线程
虚拟DOM
等等的词汇应该是已经非常熟悉甚至有点点想吐的感受了,但就我个人而言,我掌握到的知识还是像水里的浮萍一样,浮在那水面上飘荡,所以今天这篇文章会是对前端部分知识的一个深入过程,今天我就是要把这根给扎下去点。创作不易,喜欢就赞。
内容
输入URL到页面展示
在我之前的理解中,这个过程就是一个一维线性的一个过程,大致就是下面这样:
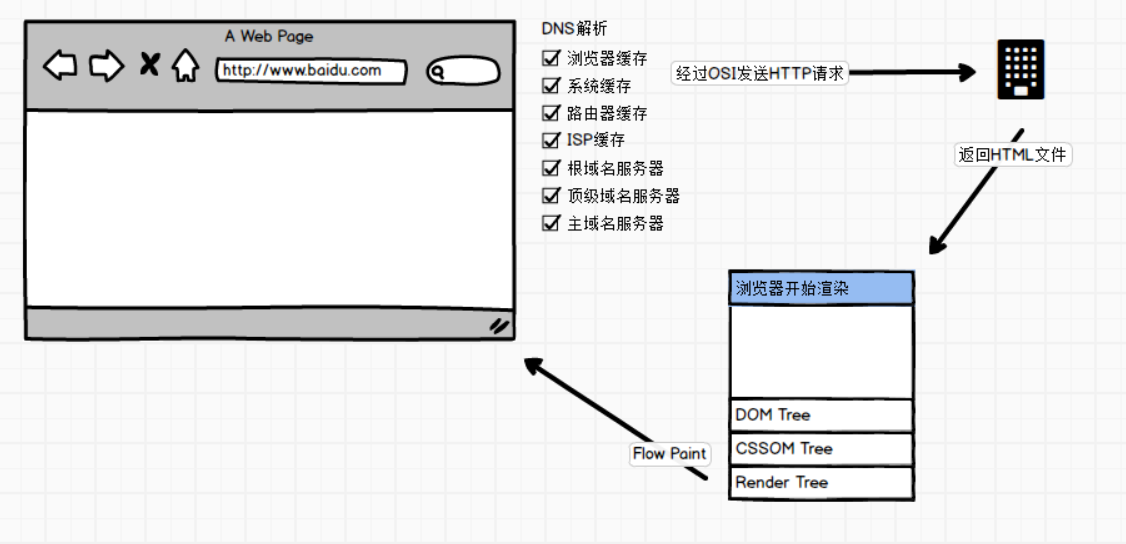
首先就可以看到这个过程就像是x轴、像同步事件一样,就像下面这串代码:
var a = 1
var b = 1
var c = a + b
但其实在这个由浏览器发送请求服务器返回请求的过程其实是多维的,就像是JS中的异步代码一样,总有需要把一些事件拿出去等待回调函数的需求。浏览器也是有很多个进程,包括浏览器进程、网络进程、渲染进程、GPU进程、插件进程
,这些进程各专其职,做着自己擅长的事。
可以想象一下,浏览器是个立体的互联网公司,而浏览器进程事业群负责tab窗口部门、书签部门等在浏览器内容上面的那部分,这些部门都是浏览器事业群管。里面的部门分成不同的小组,有UI小组负责管理URL输入框的管理和联通工作。渲染进程事业群就是负责管理window content(google是这么叫的),里面有很多个部门,部门里又有很多小组,他们负责处理HTML或者其他文件。这些文件都是从浏览器进程事业群那里传过来的,传输文件的是行政部门(IPC),行政部门负责的工作就是保证各个事业群信息流通。每个事业群的资源(数据)是独立的,这很正常,负责的工作不同,资源就不同,你浏览器进程没必要知道渲染进程的事,但是交流还是需要IPC来传输的。
浏览器为啥要分这么多进程呢,就是为了减低复杂度和增加安全性,像插件和GPU这种万一挂掉后,可以在后台重启开启,不会影响到其他进程的运行。各个进程之间会有个IPC通道进行通信,这很重要,因为浏览器在保证不同线程互不干扰的情况下,也需要信息的传递。下面是多维的一个过程:
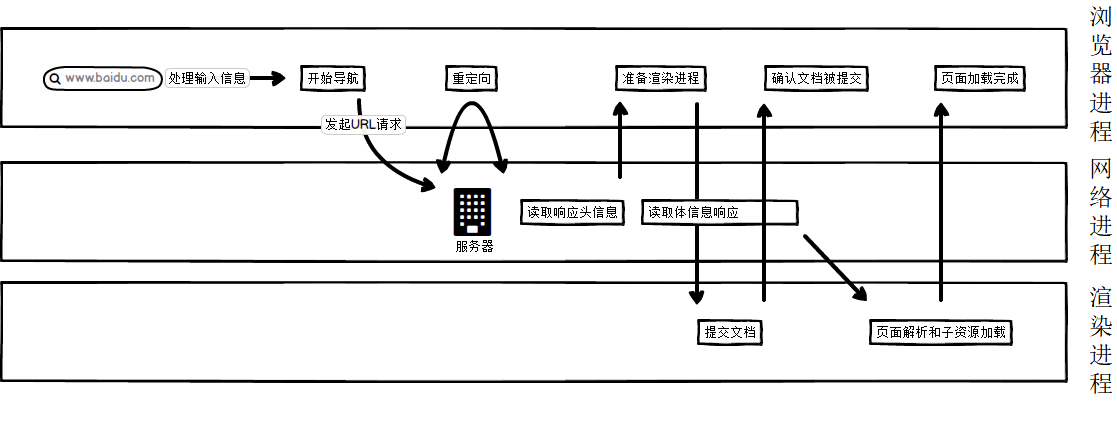
传输的过程很立体,可以把它想象成一个层层堆积的HTML文件一样,不同层级的图层处理着不同的事,我今天主要想讨论的是请求-回应、页面解析-加载
这两个步骤。
页面解析-加载
首先从头开始吧,Chrome的渲染机制是在不断变化的,这群开发者想要把Chrome开发成“面向服务的架构”,所以越来越多的进程被独立出来,目前一般来说打开一个Chrome会有一个浏览器进程,一个网络进程,一个GPU进程,多个渲染进程和多个插件进程。
当浏览器确认提交文档安全无误后,浏览器线程会通过IPC传输确认信息给渲染进程,渲染进程就开始解析HTML了,而渲染进程里又是多线程,GUI线程、JS引擎线程、事件触发线程、定时器触发线程、异步HTTP请求线程都是渲染进程中的常用线程。
回忆一下自己写页面的时候,<!DOCTYPE html>从这开始,GUI线程就会开始解析HTML,构建DOM树,同时为了加速页面的显示,“预加载扫描(preload scanner)”会同时在后台运行。如果页面上有<img>或是<link>之类需要加载的资源,当解析器生成相应的标签时,预加载器就会通知浏览器进程中的网线线程去加载资源。
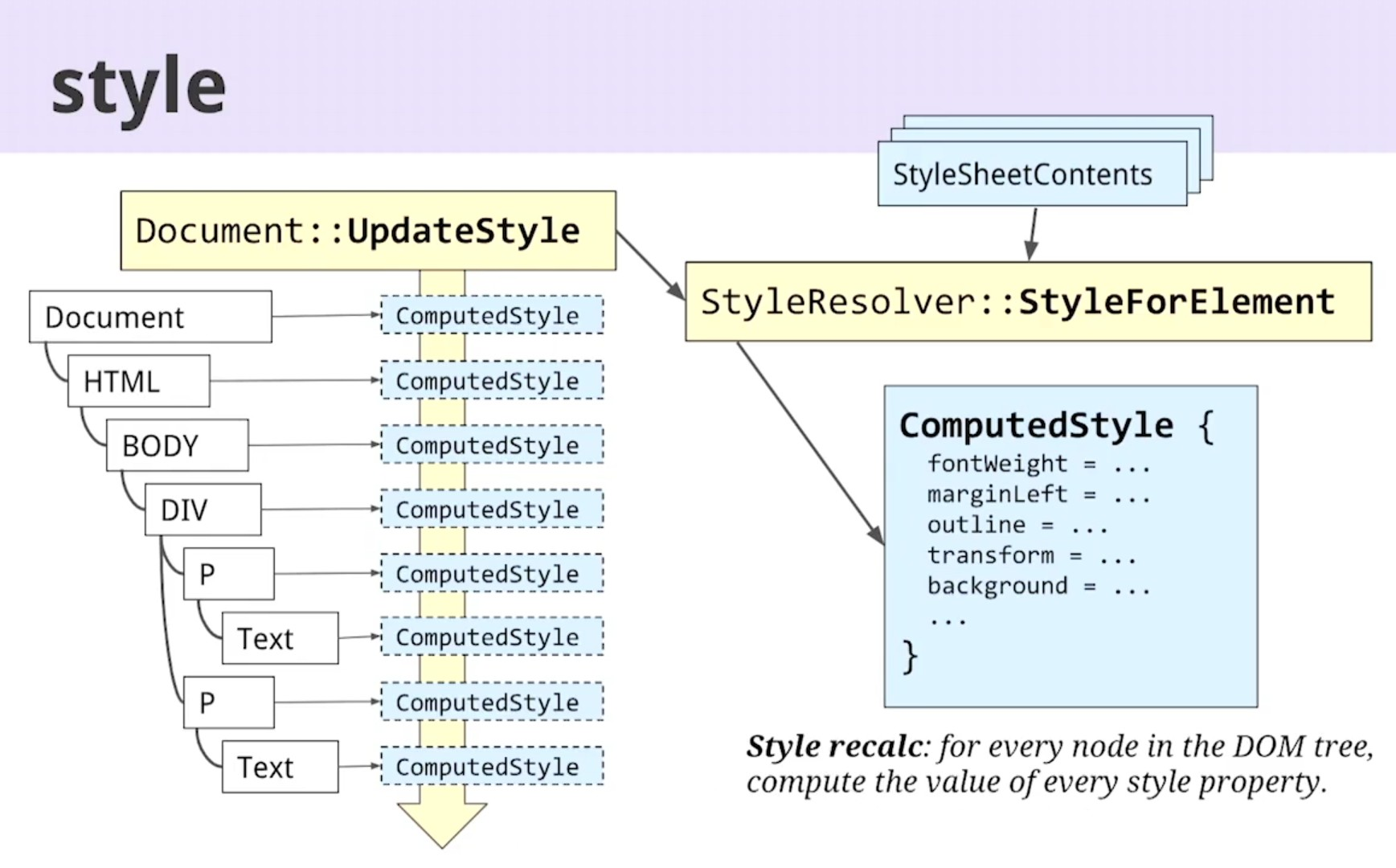
同时CSSParser也在把css文件解析为CSSOM树,就像上图所示,在所有样式规则都解析出来后,会有个样式分析的阶段。在这个阶段,包括默认样式在内的每个样式属性的最终值将会被计算出来,,存储在ComputedStyle对象模型,最终对象会挂载到DOM元素上。所以我们才需要了解选择器的权重排名,方便做样式覆盖。
但是一旦解析器遇到<script>标签,它会停止继续解析剩下的HTML文档,主动阻塞解析,去加载相应的JavaScript代码并执行。这是因为JavaScript代码能够改变文档结构。两者如果同时进行,就有可能争抢同一个资源。
挂载好css对象的DOM树被称为Renderer Process,下面对这个process进行布局了,通过遍历这颗树上所有的样式属性,除非你是display:none,否则连伪元素都是会被计算上生成Layout Tree。
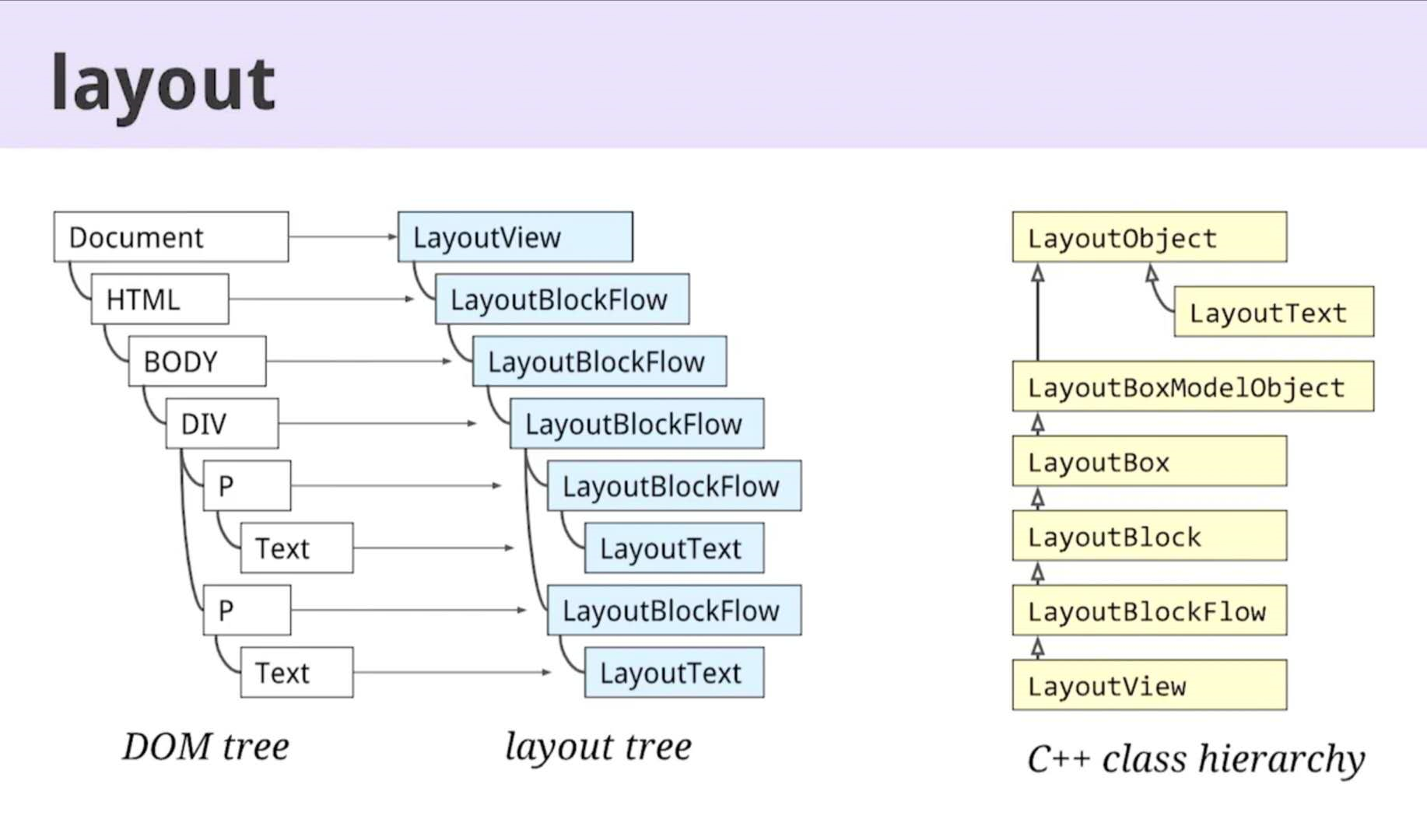
Layout Tree里有很多不同的布局类,每个都对应着不同的算法,因为确定页面的布局是一项非常难的事情,即使是最简单的块级元素从上到下的布局也需要考虑元素内部字体的大小,该如何换行,因为这些都会影响到该元素的形状和大小。甚至可能影响到下一个块级元素的位置。通常来说,元素的高度是由子元素决定的,而元素的宽度是由容器决定的,这就是你在开发中有时候无法改变某个引入组件的高度原因(我遇到过echarts的)。
目前来说,Chrome的Layout是先输入所有样式属性统计出位置后,然后再输出真实布局信息,在这个过程中Layout Tree这个对象包含了布局阶段的输入和输出,下一代的Layout NG计划是更清晰地分离输入和输出阶段。事实上,Chrome团队做的事情非常体现面向服务的架构这一思想,恨不得把所有服务分离开来。
接下来就是绘画过程了,现在大家知道位置了,但也不知道谁在前谁在后啊,红红绿绿的是拌在一起还是一人一半呢。绘制阶段一共有四个阶段:
通俗来讲就是层叠式上下文的排序问题,所以我们才需要理解层叠式上下文的权重排序,无论你是怎么把这些布局信息怎么排的,首先先绘制的肯定是背景,然后是块状、浮动,最后才是行内。这也很符合设计思想,页面就是用来展示信息的,文字放最前,其它的布局、背景这些样式都是装饰铺垫。当然特殊需要可以用z-index哈。。
在这个画出一个正方形的过程中,浏览器主线程会记录整个过程,先画一个白白的背景-->用黑笔描四条边-->完成,这很重要。回忆一下前面的DOM Tree、CSSOM Tree、Renderer Process、Layout Tree,当这些数据结构串联在一起,当任意某个子节点的属性发生变化的时候,后面的属性也能跟着做相应的变化。这就是我们平时说的为什么要减少重排的原因之一。
最后还差一步画到页面上去,首先要知道的是页面有可视区域,我们绘制时需要在GPU中开辟一个内存区域,用一个列表去存储被光栅化的页面。光栅化这个词确实难理解,这玩意就像套接字(socket)一样让人懵X,完全不知道是干嘛的。但说实话物理上是有光栅这个概念的,其实也类似,就是把页面的绘制分成一块一块的,GPU会逐步画上去。如果你的网速很卡的话,你就会发现页面是一块一块出来的,每次有新的可视区域移动时,就会有新的栅格任务,主线程就会通知GPU去执行,然后显示到浏览器中。事实上,这是以前浏览器的处理方式,目前Chrome又对此进行了一系列的优化。
这个优化就是Chrome面向服务的架构思想的完美体现,它们采用合成线程的技术。首先一个页面被分层,被栅格化,因此很多个小块被送到GPU去存储,合成线程是在GPU进程里,当它生成合成帧后,会通过IPC通知浏览器进程。与此同时,可能会有来自js处理的一些合成帧被送到GPU中去合成处理,最后在屏幕中展示。这就是为什么推荐用css动画而不是js动画的原因之一:js处理动画还得等主线程执行之后,合成线程才能继续合成帧。
至此,页面的解析到加载过程就结束了,大致的话由点到面,层层递进,毕竟页面的显示是由浏览器来操作的嘛,你不弄懂这些底层的架构,有时候页面布局出错都不知道为什么,还在baidubaidubaidubalabala。其实其中还有很多很多的细节,像是解析算法、优化算法之类的,但是感觉这种就是Chrome团队这些写浏览器的人需要学习的东西,以后有空的话可以看看Chrome的源码什么的。对于一些对视频很敏感的同学,推荐Chrome团队成员Steve Kobes的Life of a Pixel讲座视频,里面就是讲述像素是怎么呈现到页面的。
请求-回应
关于请求-回应这个阶段是在浏览器发出HTTP请求的时候开始,然后从收到数据响应体结束。由于请求/回应这两个过程就是装箱拆箱的过程,所以只需要讲述装箱的过程即可。我是基于五层体系结构,从基础数据包结构展示说明。
首先背景就是URL带着一些响应头在HTTP服务下通过HTTP(超文本传输协议)生成报文。这种体系用恰当的比喻就像是一个快递体系,假设你是一个淘宝卖家,你需要向某个地址送你卖的茶叶,你首先要做的是call一个上门的快递员,写好一张单子,把这个单子和茶叶一起叫快递小哥送到公司去,这就像首先要做的HTTP协议过程。
请求头一般是这种结构:
| 内容 | 含义 |
|---|---|
| 请求行 | 请求方式 + 请求路径 + 协议版本 |
| 请求头 | 代表浏览器信息以及当前请求的状态 |
| 请求体 | 当前请求所携带的数据,提供给服务器上对应的处理程序使用 |
看,这多像快递单,给小哥的时候不同的东西肯定不同处理啊,就像get和post,简单来说,人就要3斤茶叶,你直接get给他就完事。如果他要3000斤,你会觉得这个人是个傻子,你就会post先试探一下,哦吼,是个土豪,果断茶叶送去。还有就像属性这种东西还是都得记住,毕竟天天发送HTTP请求的人不能不知道这请求是啥啊。
其实应用层这一层主要就是规范通信双方,并且给浏览器提供不同的数据处理方法。毕竟叫应用层,那就是只关心应用程序的逻辑细节,而不是数据在网络中的传输活动。
OK那接下来就是传输层TCP协议,这一层就是为了提供可靠的连接而存在的,经典的三报文握手:
- 为什么三次:为了确定双方有发送和接受的能力,减少网络阻塞。
- 为什么不更多次:无论多少次多会有连接失败,三次是最优解。
其实确定连接和断开连接都是需要四次,但是连接是把中间两步放到一起,所以是三次:
- 一端请求开启/关闭
- 另一端确认开启/关闭
- 另一端请求开启/关闭
- 一端确认开启/关闭
TCP的报文属性是为了流数据传输、可靠、有效流控制、全双工、多路复用的连接而服务的,简单理解就是快递公司拿到茶叶了,有地址了,但是人快递公司有自己的一套体系,需要把你这茶叶按箱子大小给分箱装着发过去,先联系那地方的分部看看那边有没有收发的能力,毕竟万一人顾客要退货啥的呢。这套健全的系统有只需要一条通道,就能满足茶叶卖家的所有货物,并且还能知道哪个包裹路上丢了,就能给补发啥的。具体的报文格式和属性就不多说了,因为太多了,感兴趣的私下自己可以琢磨琢磨。
紧接着这公司就来到自己的派发处,这个部门就是又坑又好,坑的话就是他不会管你送给谁,它只送给指定地点的派发处,好的地方就是无需建立连接,直接传输。这就是网络层IP协议。IP协议的主要目的就是为了转发,一切属性的设计都是为了提高转发的效率,像生存时间就是解决无效的交付数据包,当数据包在几台路由器里面打圈时,这就大大浪费了传输效率,这就需要生存时间(TTL),过了16跳之后,数据包就会被回收,源地址和目的地址就是为了最短路由算法的实现。
这派发部拿到箱子后就开始派快递员去了,快递员就像是数据链路层,在路上开着车车就像是在物理层传输着数据,最终,对面的快递小哥也开着车车在等待,虽然很奇怪,但是也只能这么编了。其实本来是想结合着计算机网络(谢希仁)这本经典著作来展开的,但是估计会非常乏味,所以感兴趣的同学私下自己康康吧。
总结
这就是我对于这个从输入URL到页面展示这个问题的深入思考,其实对于真实开发中来说,也确实有用处(文章中已提及),作为一个实习生的我,我每天需要解决的就是公司的业务,而Chrome的底层可以帮助到我更好地理解和解决问题和BUG。。当然有空看看也是很有意思的,毕竟V8引擎。。
❝如果这篇文章对你有帮助的话,欢迎点赞关注转发,最起码点个赞吧(脸皮真厚嘻嘻)
