

0. 浏览器输入url
对浏览器来说:
* 1.浏览器首先使用 HTTP 协议或者 HTTPS 协议,向服务端请求页面;
* 2.把请求回来的 HTML 代码经过解析,构建成 DOM 树;
* 3.计算 DOM 树上的 CSS 属性;
* 4.最后根据 CSS 属性对元素逐个进行渲染,得到内存中的位图;
* 5.一个可选的步骤是对位图进行合成,这会极大地增加后续绘制的速度;
* 6.合成之后,再绘制到界面上。
1.浏览器首先使用 HTTP 协议或者 HTTPS 协议,向服务端请求页面
1.1 http和tcp
HTTP 协议是基于 TCP 协议出现的,
对 TCP 协议来说,TCP 协议是一条双向的通讯通道
HTTP 在 TCP 的基础上,规定了 Request-Response 的模式,这个模式决定了通讯必定是由浏览器端首先发起的。
HTTP 是纯粹的文本协议,它是规定了使用 TCP 协议来传输文本格式的一个应用层协议
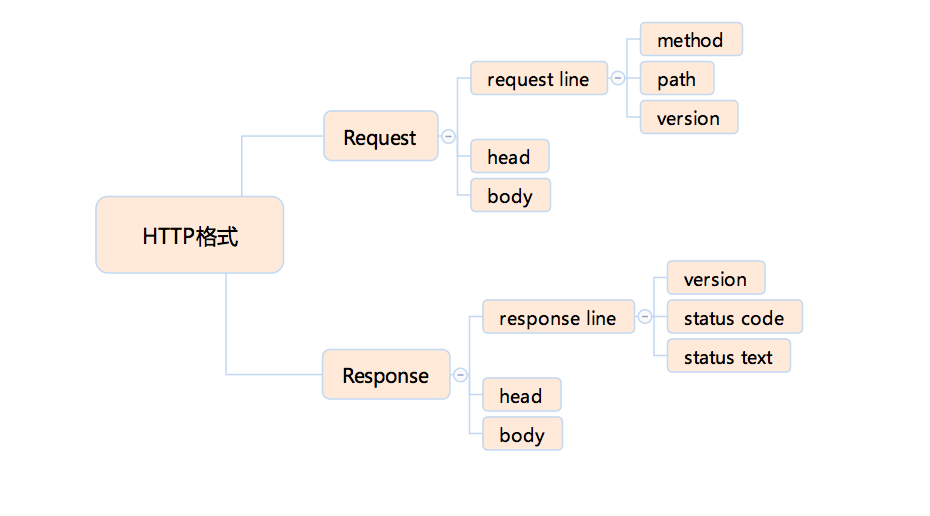
1.2 http协议划分
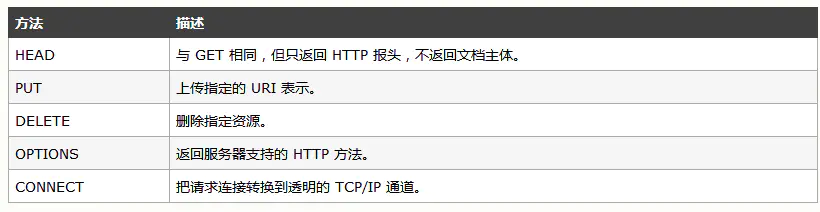
1.3 HTTP Method 方法
- 浏览器通过地址栏访问页面都是 GET 方法。表单提交产生 POST 方法。
- HEAD 则是跟 GET 类似,只返回请求头,多数由 JavaScript 发起
- PUT 和 DELETE 分别表示添加资源和删除资源,但是实际上这只是语义上的一种约定,并没有强约束。
- CONNECT 现在多用于 HTTPS 和 WebSocket。
- OPTIONS 和 TRACE 一般用于调试,多数线上服务都不支持。
1.4 get和post区别
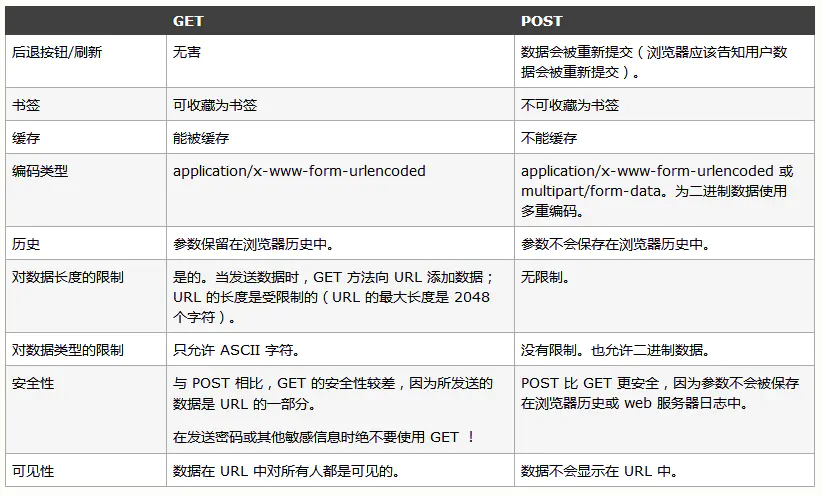
HTTP是基于TCP/IP关于数据如何在万维网中如何通信的协议。(HTTP的底层是TCP/IP。所以GET和POST的底层也是TCP/IP,也就是说,GET/POST都是TCP链接。GET和POST能做的事情是一样一样的。你要给GET加上request body,给POST带上url参数,技术上是完全行的通的。)
GET产生一个TCP数据包;POST产生两个TCP数据包。(对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);而对于POST,浏览器先发送header,(如果header里面带了Expect: 100-continue,服务器响应100 continue,若不带(或者超时),直接发data),浏览器再发送data,服务器响应200 ok(返回数据))
实际上:真正的区别从语义上面,get是获取指定资源,post是请求符合对指定资源做处理。
1.5 HTTP Status code(状态码)和 Status text(状态文本)
- 1xx:临时回应,表示客户端请继续。
- 2xx:请求成功:
- 200:请求成功。
- 3xx: 表示请求的目标有变化,希望客户端进一步处理
- 301&302:永久性与临时性跳转。
- 304:跟客户端缓存没有更新。
- 4xx:客户端请求错误。
- 403:无权限
- 404:表示请求的页面不存在。
- 418:It’s a teapot. 这是一个彩蛋,来自 ietf 的一个愚人节玩笑。
- 5xx:服务端请求错误。
- 500:服务端错误
- 503:服务端暂时性错误,可以一会再试。
对我们前端来说,1xx 系列的状态码是非常陌生的,原因是 1xx 的状态被浏览器 HTTP 库直接处理掉了,不会让上层应用知晓。
2xx 系列的状态最熟悉的就是 200,这通常是网页请求成功的标志,也是大家最喜欢的状态码。
3xx 系列比较复杂,301 和 302两个状态表示当前资源已经被转移,只不过一个是永久性转移,一个是临时性转移。实际上 301 更接近于一种报错,提示客户端下次别来了
304 又是一个每个前端必知必会的状态,产生这个状态的前提是:客户端本地已经有缓存的版本,并且在 Request 中告诉了服务端,当服务端通过时间或者 tag,发现没有更新的时候,就会返回一个不含 body 的 304 状态。
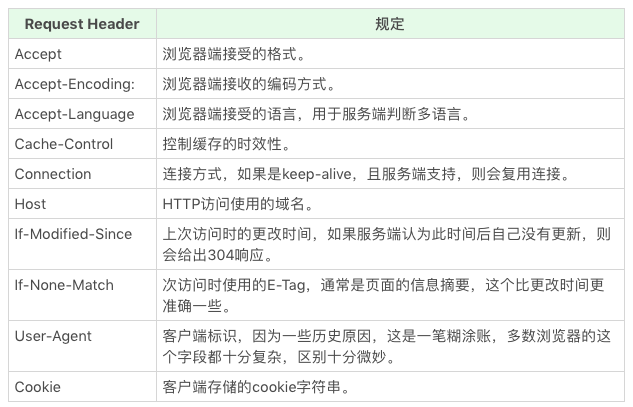
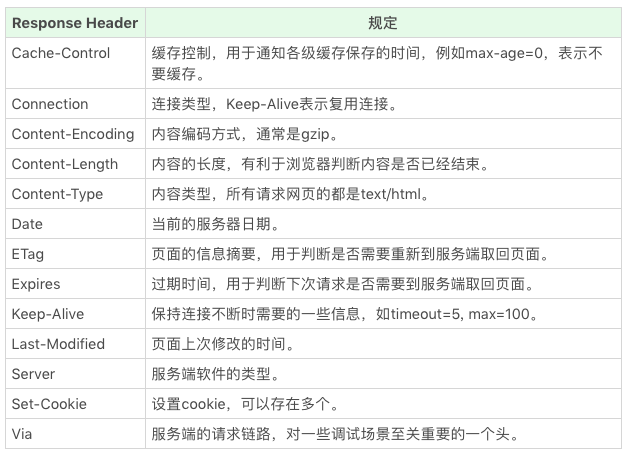
1.6 HTTP Head (HTTP 头)
1.7 HTTP Request Body
常见的 body 格式:
- application/json
- application/x-www-form-urlencoded
- multipart/form-data
- text/xml
我们使用 HTML 的 form 标签提交产生的 HTML 请求,默认会产生 application/x-www-form-urlencoded 的数据格式,当有文件上传时,则会使用 multipart/form-data。
1.8 https
HTTPS 有两个作用:
- 确定请求的目标服务端身份
- 保证传输的数据不会被网络中间节点窃听或者篡改
HTTPS 是使用加密通道来传输 HTTP 的内容。但是 HTTPS 首先与服务端建立一条 TLS 加密通道。TLS 构建于 TCP 协议之上,它实际上是对传输的内容做一次加密,所以从传输内容上看,HTTPS 跟 HTTP 没有任何区别。
1.9 HTTP 2
HTTP 2.0 最大的改进有两点:
- 支持服务端推送
- 支持 TCP 连接复用(需要keep-alive配合)
- 使用二进制代理文本进行传输,极大提高了传输的效率
服务端推送能够在客户端发送第一个请求到服务端时,提前把一部分内容推送给客户端,放入缓存当中,这可以避免客户端请求顺序带来的并行度不高,从而导致的性能问题。
TCP 连接复用,则使用同一个 TCP 连接来传输多个 HTTP 请求,避免了 TCP 连接建立时的三次握手开销,和初建 TCP 连接时传输窗口小的问题。
2.把请求回来的 HTML 代码经过解析,构建成 DOM 树
解析代码
“词”: 指编译原理的术语 token,表示最小的有意义的单元。
HTML 的结构不算太复杂,我们日常开发需要的 90% 的“词”,种类大约只有标签开始、属性、标签结束、注释、CDATA 节点几种。
实际上有点麻烦的是,由于 HTML 跟 SGML 的千丝万缕的联系,我们需要做不少容错处理。“
2.1. 词(token)是如何被拆分的
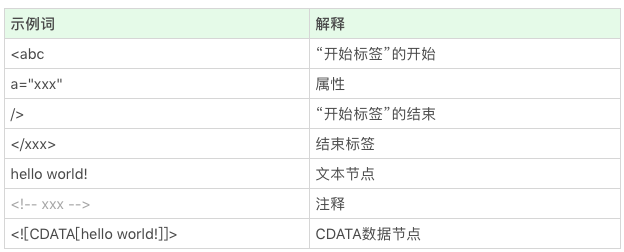
我们每读入一个字符,其实都要做一次决策,而且这些决定是跟“当前状态”有关的。在这样的条件下,浏览器工程师要想实现把字符流解析成词(token),最常见的方案就是使用状态机。
2.2. 状态机
绝大多数语言的词法部分都是用状态机实现的
字符流拆成了词的过程可以称为状态机
HTML规定了状态机实现的语言,对大部分语言来说,状态机是一种实现而非定义。
完整的 HTML 词法状态机比较复杂,有兴趣的可以自己去深入。
构建 DOM 树
2.3 使用栈把词变成 DOM 树
function HTMLSyntaticalParser(){
var stack = [new HTMLDocument];
this.receiveInput = function(token) {
//……
//在接收的同时,即开始构建 DOM 树
//所以我们的主要构建 DOM 树的算法,就写在 receiveInput 当中
}
this.getOutput = function(){
return stack[0];
//当接收完所有输入,栈顶就是最后的根节点,
//我们 DOM 树的产出,就是这个 stack 的第一项
}
}
//完整代码可参考 https://github.com/aimergenge/toy-html-parser
为了构建 DOM 树,我们需要一个 Node 类,接下来我们所有的节点都会是这个 Node 类的实例
通过这个栈,我们可以构建 DOM 树:
- 栈顶元素就是当前节点;
- 遇到属性,就添加到当前节点;
- 遇到文本节点,如果当前节点是文本节点,则跟文本节点合并,否则入栈成为当前节点的子节点;
- 遇到注释节点,作为当前节点的子节点;
- 遇到 tag start 就入栈一个节点,当前节点就是这个节点的父节点
- 遇到 tag end 就出栈一个节点(还可以检查是否匹配)。
HTML 具有很强的容错能力,当 tag end 跟栈顶的 start tag 不匹配的时候如何处理,这个可以去看W3C标准,所以,推荐XHTML,避免不必要的麻烦。
3.把不含样式信息的 DOM 树应用 CSS 规则
从父到子,从先到后,一个一个节点构造,并且挂载到 DOM 树上的,那么这个过程中,同步把 CSS 属性计算出来
在这个过程中,我们依次拿到上一步构造好的元素,去检查它匹配到了哪些规则,再根据规则的优先级,做覆盖和调整。所以,从这个角度看,所谓的选择器,应该被理解成“匹配器”才更合适。
选择器的出现顺序,必定跟构建 DOM 树的顺序一致。这是一个 CSS 设计的原则,即保证选择器在 DOM 树构建到当前节点时,已经可以准确判断是否匹配,不需要后续节点信息。
3.1 词法分析和语法分析
CSS 被解析成了一棵可用的抽象语法树。
3.2 compound-selector
CSS 选择器按照 compound-selector 来拆成数段,每当满足一段条件的时候,就前进一段。 在匹配到本标签的结束标签时回退。
CSS 计算:把 CSS 规则应用到 DOM 树上,为 DOM 结构添加显示相关属性的过程。得到了一棵带有 CSS 属性的树
4. 计算 DOM 树上的 CSS 属性
确定每一个元素的位置,尽可能流式地处理上一步骤的输出
根据样式信息,计算了每个元素的位置和大小
4.1 基本概念
4.1.1 排版
浏览器确定文字、图片、图形、表格等等位置的过程
4.1.2 正常排版
浏览器最基本的排版方案是正常流排版,它包含了顺次排布和折行等规则,这是一个跟我们提到的印刷排版类似的排版方案,也跟我们平时书写文字的方式一致,所以我们把它叫做正常流。
4.1.3 文字排版
文字排版是一个复杂的系统,它规定了行模型和文字在行模型中的排布。
4.1.4 行模型
行模型规定了行顶、行底、文字区域、基线等对齐方式。
4.1.5 双向文字系统
此外,浏览器支持不同语言,因为不同语言的书写顺序不一致,所以浏览器的文本排版还支持双向文字系统。
4.1.6 盒模型
浏览器又可以支持元素和文字的混排,元素被定义为占据长方形的区域,还允许边框、边距和留白,这个就是所谓的盒模型。
在正常流的基础上,浏览器还支持两类元素:绝对定位元素和浮动元素。
除了正常流,浏览器还支持其它排版方式,比如现在非常常用的 Flex 排版,这些排版方式由外部元素的 display 属性来控制(注意,display 同时还控制元素在正常流中属于 inline 等级还是 block 等级)。
4.2 正常流文字排版
advance 代表每一个文字排布后在主轴上的前进距离,它跟文字的宽 / 高不相等,是字体中最重要的属性
在正常流的文字排版中,多数元素被当作长方形盒来排版,而只有 display 为 inline 的元素,是被拆成文本来排版的
display 值为 inline 的元素中的文字排版时会被直接排入文字流中,inline 元素主轴方向的 margin 属性和 border 属性(例如主轴为横向时的 margin-left 和 margin-right)也会被计算进排版前进距离当中。
4.3 正常流中的盒
多数 display 属性都可以分成两部分:内部的排版和是否 inline,带有 inline- 前缀的盒,被称作行内级盒。
浏览器对行的排版,一般是先行内布局,再确定行的位置,根据行的位置计算出行内盒和文字的排版位置
块级盒比较简单,它总是单独占据一整行,计算出交叉轴方向的高度即可。
4.4 绝对定位元素
position 属性为 absolute 的元素,我们需要根据它的包含块来确定位置,这是完全跟正常流无关的一种独立排版模式,逐层找到其父级的 position 非 static 元素即可
4.5 浮动元素排版
float 元素非常特别,浏览器对 float 的处理是先排入正常流,再移动到排版宽度的最左 / 最右(这里实际上是主轴的最前和最后)。
移动之后,float 元素占据了一块排版的空间,因此,在数行之内,主轴方向的排版距离发生了变化,直到交叉轴方向的尺寸超过了浮动元素的交叉轴尺寸范围,主轴排版尺寸才会恢复。float 元素排布完成后,float 元素所在的行需要重新确定位置。
4.6 其它的排版
Flex 排版,支持了 flex 属性,flex 属性将每一行排版后的剩余空间平均分配给主轴方向的 width/height 属性。浏览器支持的每一种排版方式,都是按照对应的标准来实现的
5. 根据 CSS 属性对元素逐个进行渲染,得到内存中的位图
5.1 渲染
在各个领域都有不同的意思,这里统一指的是它在图形学的意义,就是把模型变成位图的过程
浏览器中渲染这个过程,就是把每一个元素对应的盒变成位图。这里的元素包括 HTML 元素和伪元素,一个元素可能对应多个盒(比如 inline 元素,可能会分成多行)。每一个盒对应着一张位图。
不会把子元素绘制到渲染的位图上的,这样,当父子元素的相对位置发生变化时,可以保证渲染的结果能够最大程度被缓存,减少重新渲染
5.2 位图
在内存里建立一张二维表格,把一张图片的每个像素对应的颜色保存进去(位图信息也是 DOM 树中占据浏览器内存最多的信息,我们在做内存占用优化时,主要就是考虑这一部分)
渲染比较复杂,分成图形和文字两个大类
盒的背景、边框、SVG 元素、阴影等特性,都是需要绘制的图形类。这就像我们实现 HTTP 协议必须要基于 TCP 库一样,这一部分,我们需要一个底层库来支持。
5.3 合成
合成的过程,就是为一些元素创建一个“合成后的位图”(我们把它称为合成层),把一部分子元素渲染到合成的位图上面。
合成是一个性能考量,那么合成的目标就是提高性能,根据这个目标,我们建立的原则就是最大限度减少绘制次数原则
<div id="a">
<div id="b">...</div>
<div id="c" style="transform:translate(0,0)"></div>
</div>
把所有子元素进行合成,得到一张位图,改变一下就需要重新绘制所有元素
所有的元素都不合成,很多个位图,改变一下,需要重新绘制所有元素
a、b合成后,就只需要绘制a、b合成好的位图,c元素的位图重新绘制,次数减少了
目前,主流浏览器一般根据 position、transform 等属性来决定合成策略,来“猜测”这些元素未来可能发生变化。
但是,这样的猜测准确性有限,所以新的 CSS 标准中,规定了 will-change属性,可以由业务代码来提示浏览器的合成策略,灵活运用这样的特性,可以大大提升合成策略的效果。
5.4 绘制
绘制是把“位图最终绘制到屏幕上,变成肉眼可见的图像”的过程
浏览器只需要把最终要显示的位图交给操作系统即可
把位图按照 z-index 把它们依次绘制到屏幕上,会带来极其糟糕的性能
实际上,“绘制”发生的频率比我们想象中要高得多。我们考虑一个情况:鼠标划过浏览器显示区域。这个过程中,鼠标的每次移动,都造成了重新绘制,如果我们不重新绘制,就会产生大量的鼠标残影。
计算机图形学中,使用的方案就是“脏矩形”算法,也就是把屏幕均匀地分成若干矩形区域。
当鼠标移动、元素移动或者其它导致需要重绘的场景发生时,我们只重新绘制它所影响到的几个矩形区域就够了。比矩形区域更小的影响最多只会涉及 4 个矩形,大型元素则覆盖多个矩形。
设置合适的矩形区域大小,可以很好地控制绘制时的消耗。设置过大的矩形会造成绘制面积增大,而设置过小的矩形则会造成计算复杂。
我们重新绘制脏矩形区域时,把所有与矩形区域有交集的合成层(位图)的交集部分绘制即可。
6.DOM API
6.1 DOM API 大致会包含 4 个部分。
- 节点:DOM 树形结构中的节点相关 API。
- 事件:触发和监听事件相关 API。
- Range:操作文字范围相关 API。
- 遍历:遍历 DOM 需要的 API。
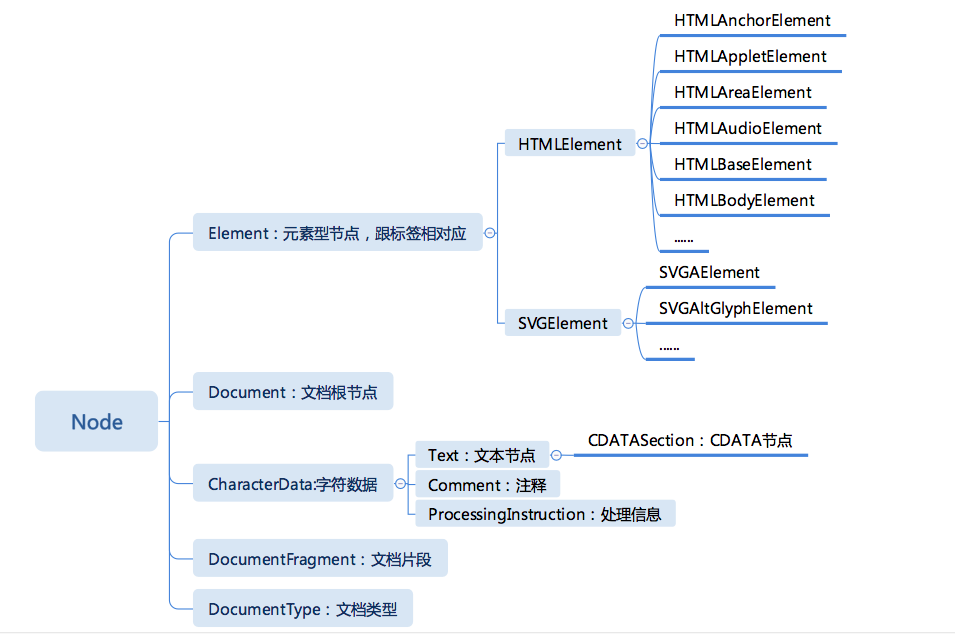
6.2 节点
以上内容根据极客时间教程整理而来
