

一、栈、队列、双端队列、优先队列本质
-
栈的本质是以后进先出LIFO方式插入删除元素的数据结构
-
队列的本质是以先进先出方式插入删除元素的数据结构
-
双端队列的本质是栈+队列,同时支持先进先出和后进先出
-
优先队列的本质是入队与队列相同,出队按优先级顺序出队,底层实现可能是堆、平衡二叉树等
-
栈、队列、双端队列的的插入删除时间复杂度都是O(1),搜索和遍历时间复杂度都是O(n)
-
优先队列的插入时间复杂度是O(1),取出的时间复杂度是O(logn)
二、哈希表、映射、集合本质
- 哈希表的本质是根据Key直接访问Value的数据结构,通过把Key经过Hash Function映射到表中某个位置,以加快访问速度
- 映射的本质是key-value对,其中key唯一
- 集合的本质是元素唯一
- 哈希表的插入、删除、搜索时间复杂度都是O(1)
三、Queue 和 Priority Queue源码分析
Priority Queue是通过数组实现一个堆,元素在queue数组中并不是完全有序的,仅堆顶元素最大或最小。
poll方法,实际上是获取堆顶元素,然后调整堆。
调整堆的方法(大顶堆为例):
1.判断是否传入comparator,有则按照comparator顺序,否则按照自然顺序排序
2.取节点左右孩子节点的最大值,与父节点交换
四、Java HashMap总结
-
根据键的hashCode值存储数据,访问时间复杂度近似O(1),但遍历顺序不确定
-
非线程安全,任意时刻可以有多个线程同时写HashMap,可能会导致数据混乱,如果需要满足线程安全,可以用 Collections的synchronizedMap方法使HashMap具有线程安全的能力,或者使用ConcurrentHashMap
-
为了解决哈希冲突,Java采用链地址法(另一种方法是开放地址法),底层实现是数组+链表+红黑树的组合
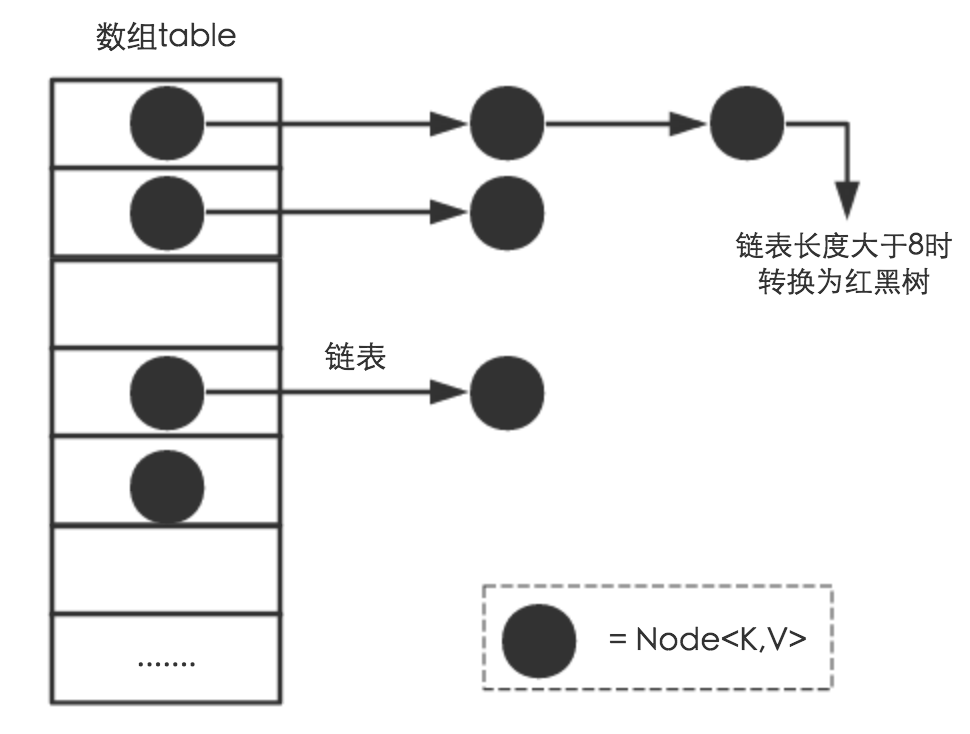
- 具体实现过程为:
- 先调用key的hashCode方法得到hashCode值
- 再通过Hash算法中的高位运算和取模运算,确定键值对的存储位置
- 当HashCode值相等时,发生哈希碰撞,此时先判断当前地址下的的链表长度是否大于8,如果大于8就把链表转为红黑树,否则进行链表的插入操作
- 插入成功后,判断实际存在的键值对数量是否超过最大容量threshold,如果超过就扩容
