

基本内容
- 补充计算机系统、语言的编译汇编等知识
- 完成阅读论文
- 加入qemu devel mailing list,浏览了一些问题
补充的知识
由于之前没有上过《深入理解计算机系统》的课程,所以对于C语言的程序如何最终变为可执行文件之前没有一个从头到尾的认识,在这里稍加补充相关知识。
预处理、编译、汇编、链接
参考链接1:预处理、编译、汇编、链接
参考链接2:如何编译目标文件
需要注意的是,在经过编译之后得到的文件实际上仍是文本文件,而QEMU需要处理的target object file实际上是二进制的文件,即经过汇编之后的文件;四个过程如下图(图中“汇编”与“编译”二字放错了地方):
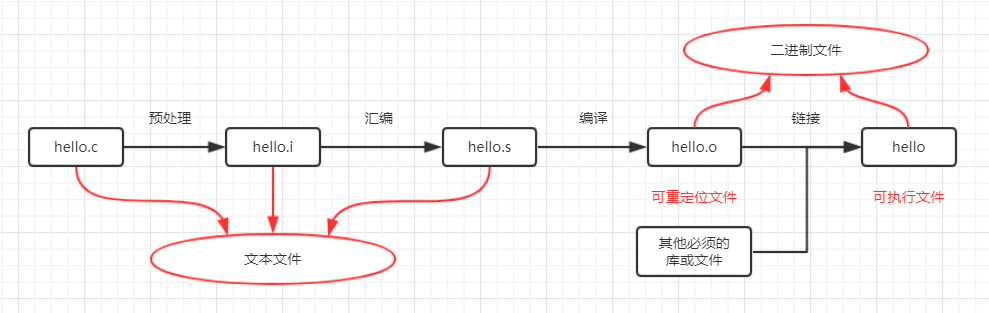
在Linux中,hello.o以及hello均为为ELF文件(见下节)。
ELF文件
参考链接:详解ELF文件
故前面的hello.o实际上是可重定位文件,hello为可执行文件。
汇编语法
由于x86的广泛使用,QEMU也将其作为首先完成的host CPU,故需要对x86汇编语法进行一些了解:
需要了解C语言到汇编语言的运行机制:
由此同时也加深了对于编译原理的理解。
论文阅读
Bellard, F. (2005). QEMU, a fast and portable dynamic translator. USENIX 2005 Annual Technical Conference, 41–46.
作者将使用的关键技术命名为dyngen:
A compile time tool called dyngen uses the object file containing the micro operations as input to generate a dynamic code generator. This dynamic code generator is invoked at runtime to generate a complete host function which concatenates several micro operations.
即,将由 micro operation 构成的在 target CPU 上运行的object file作为输入,由dyngen生成动态代码生成器(dynamic code generator)。这个动态代码生成器相当于一个“解释器”,即可以动态地将原始的micro operations拼接,并生成C语言的函数,执行在host CPU上。
此处我们需要看一下 micro operation 的概念(内容来自Wikipedia):
In computer central processing units, micro-operations (also known as a micro-ops or μops) are detailed low-level instructions used in some designs to implement complex machine instructions (sometimes termed macro-instructions in this context).
Usually, micro-operations perform basic operations on data stored in one or more registers, including transferring data between registers or between registers and external buses of the central processing unit (CPU), and performing arithmetic or logical operations on registers.
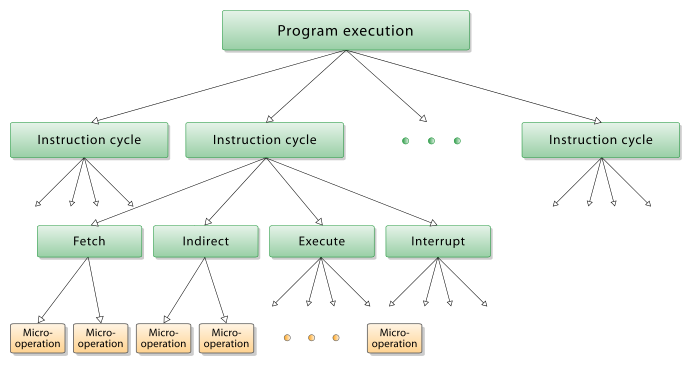
以及,micro operation 和 instruction 的关系(参考链接):
A micro-operation is an elementary CPU operation, performed during one clock pulse. An instruction consists of a sequence of micro-operations.
论文中的示例
lkao考虑一条PowerPC指令:
addi r1,r1,-16 # r1 = r1 - 16
PowerPC翻译器会将其转变为如下micro operations:
movl_T0_r1 # T0 = r1
addl_T0_im -16 # T0 = T0 - 16
movl_r1_T0 # r1 = T0
其中,movl_T0_r1编码为:
void op_movl_T0_r1(void)
{
T0 = env->regs[1];
}
env是一个包含目标CPU状态的结构体。32个PowerPC寄存器被被保存到数组env->regs[32]中。
而movl_r1_T0的实现同理。
addl_T0_im实现如下:
extern int __op_param1;
void op_addl_T0_im(void)
{
T0 = T0 + ((long)(&__op_param1));
}
如先前所述,实际上就是把一个micro operation转化为了C的函数实现
未解决的问题:为何第4行中要取变量地址?
之后,code generator 调用这些函数,由micro operation stream 生成 generated code:
[...]
for(;;) {
switch(*opc_ptr++) {
[...]
case INDEX_op_movl_T0_r1:
{
extern void op_movl_T0_r1();
memcpy(gen_code_ptr,
(char *)&op_movl_T0_r1+0,
3);
gen_code_ptr += 3;
break;
}
case INDEX_op_addl_T0_im:
{
long param1;
extern void op_addl_T0_im();
memcpy(gen_code_ptr,
(char *)&op_addl_T0_im+0,
6);
param1 = *opparam_ptr++;
*(uint32_t *)(gen_code_ptr + 2) =
param1;
gen_code_ptr += 6;
break;
}
[...]
}
}
[...]
}
原文中对这一过程的表述如下:
The code generator generated by dyngen takes a micro operation stream pointed by opc_ptr and outputs the host code at position gen_code_ptr. Micro operation parameters are pointed by opparam_ptr.
编码的动态变化及指针指向如下:
dyngen ---generates---> code generator
micro operation stream ---input---> code generator ---output---> host code
opc_ptr ---point to---> input micro opration stream
opparam_ptr ---point to---> input parameters
gen_code_ptr ---point to---> output host code
我们关注其中的一部分:
case INDEX_op_movl_T0_r1:
{
extern void op_movl_T0_r1();
memcpy(gen_code_ptr, (char *)&op_movl_T0_r1+0, 3);
gen_code_ptr += 3;
break;
}
可以看到,此处将从&op_movl_T0_r1这个地址起的三个字节的内容,拷贝到了gen_code_ptr指针指向的位置。至于为什么是三个字节,以及这三个字节的内容具体是什么,还需要进一步的探究。而op_movl_T0_r1实际上是一个函数,op_movl_T0_r1本身也就代表了其函数的首地址,最初不理解为什么要加取地址符&,查阅资料:

个人的理解是,对于取函数首地址的操作中,为了统一函数与变量(至少让它看起来一样),所以将函数视为一个对象,像变量一样使用取地址符号,便于阅读和理解代码。
论文之后的内容均为文字性的说明,直接找来论文阅读即可。阅读的过程中,对于QEMU的实现细节有了一个大题的了解。其中包括一些精妙的地方,如:
Knowing that we had a 32 bit addition from the con- stant stored in CC OP, we can recover A, B and R from CC SRC and CC DST. Then all the corresponding con- dition codes such as zero result (ZF), non-positive result (SF), carry (CF) or overflow (OF) can be recovered if they are needed by the next instructions.
The condition code evaluation is further optimized at translation time by using the fact that the code of a com- plete TB is generated at a time. A backward pass is done on the generated code to see if CC OP, CC SRC or CC DST are not used by the following code. At the end of TB we consider that these variables are used. Then we delete the assignments whose value is not used in the following code.
QEMU采用的lazy condition code evaluation的方式,减少了对于那些可以通过已有数据推算出来的数据的存储。如在x86中eflags寄存器中的部分位。
由于一个TB(Translated Blocks)是一次执行完成,故在TB执行时不会发生CPU状态的改变,而对于运算中会发生改变的状态位,可以通过CC_SRC,CC_DST,CC_OP计算出来。
若将其全部存储,这种方式或许是由于QEMU在host上将target register映射到内存中,而从内存中读取数据的速度远低于直接从寄存器中取数据,随时保存的意义不大,故为了简化只在必要时计算需要的量。
论文其余部分由于小组成员已有较为详尽的翻译的笔记,故此处不再复述。
此外,由于初次阅读,对于论文的内容和实现仍有许多需要深入理解的地方,之后对于这些部分要定向阅读代码。
关于mailing list
QEMU社区有多个Mailing List,如:
之前已经加入了users mailing list,作为社区贡献者,加入developers mailing list
对于项目代码的研究,可以参照mailing list中的提问:
How to get started with the source code of Qemu?
A very rough survey:
- The main() function is in "vl.c"
- The target CPU emulation code is in the "target-xxx" directories
- The host backends for the CPU emulation is in the "tcg" directory (TCG means Tiny Code Generator)
- Other hardware emulation can be found in the "hw" directory
- Host networking code is in the "net" folder
- Guest firmware (BIOS) code can be found in the "pc-bios" folder
