

原文标题: Optimizations That Aren't, Or Are They?
原文链接: https://oribenshir.github.io/afternoon_rusting/blog/copy-on-write
几年前,我读到了一篇关于C++的很特别的博客。这是我第一次接触到技术博客的概念。它使我在教育体系(如陈旧的经典课程,练习,坐在教室里听老师讲课)之外接触到了完整的软件开发的概念。直到今天,那都是我最喜欢的博客之一,这也使我有了想要写出属于自己的博客的强烈愿望。
The concept of Copy-On-Write
这篇博客是Herb Sutter在20多年前写的,你可以在这里看到。时隔20多年,在讨论这篇博客及为什么与它有关之前,我们需要讲一些背景。它讲述了一种叫做Copy-On-Write的优化,缩写为COW。我会分别在Rust和C++里讨论这个优化。但是也不要担心,我会详细地进行说明,不需要了解很多有关这些语言的背景知识。在我们开始之前,先介绍一下这个词的起源。在Rust里,COW实际上表示Clone-On-Write,这个优化用于处理较大的数据。在Rust里,我们对较大的数据进行克隆(clone)而不是拷贝(copy)。不过幸运的是,克隆(Clone)和拷贝(Copy)的单词开头都是相同的字母,所以只要简单地记为COW就可以了。但是在本文中,如果需要的话,我会一直悄悄变换克隆(clone)和拷贝(copy)的语义。其实我说的都是相同的操作,即把一大块数据从一个地方拷贝到另一个地方。
Copy-On-Write最关键的地方在于拷贝数据是一个成本相对较高的操作。我们想要尽可能地减少这种操作。让我们来考虑一下什么时候有必要拷贝一份数据。如果你对Rust的所有权系统比较熟悉(或许你应该熟悉),可能就会觉得比较直观。当所有权系统会阻止你做一些事情,你需要拷贝数据或者找到其他的方法面对这个问题(这都是后话)。不管怎样,对于你们中对Rust的所有权系统不太熟悉的那些人,让我们展开讨论。只要我们有一个变量引用到一块数据,我们就不应该到处拷贝它。没人能在我们的封装下修改它,这正是我们所担心的场景。拷贝数据只有在多个变量指向同一块数据时才会相关联。但是这里正是COW背后的优化部分。不是每一次,我们都有很多变量指向相同的数据,实际上我们不得不去拷贝它。如果我们所做的只是从变量的位置读取数据,我们仍然没有理由把它到处拷贝。没有人改变它,所以我们没有面对数据竞争。数据竞争是这样一种情况,我们从两个不同的线程中访问数据,它们中至少有一个改变了数据但是没有正确地同步。如果你对数据竞争不熟悉,我强烈建议搜索一下相关主题,因为这对于几乎当今所有的开发者都是很重要的。回到COW,背后的思想并不复杂。就是尽可能地往后推迟数据的拷贝。与其在我们把一片数据赋值给多个变量时进行拷贝,倒不如在通过变量进行写入的时候进行拷贝。
Copy-On-Write in C++
尽管核心思想很简单,但是Rust和C++在实现这种优化上采取了不同的方案。让我们先从C++这边开始,不过我要提醒你这是一个粗略的简介,只是讲一些需要用到的东西,即使你从来没学过C++。在C++里,我们通常在一个类里放入大量的数据,这些数据会有赋值操作。每一次我们把一个变量赋值给另一个变量,我们就会调用这个赋值操作,默认情况下是拷贝整条数据。但是,这个行为是可以修改的,所以通常情况下,COW就是利用这一点来实现的。C++中的COW不是一个单独的抽象,而是每个类进行单独实现。传统的做法是通过修改赋值操作符返回一个指向同一个底层数据的指针。尽管这还不够,但是现在我们已经可以让多个变量指向同一份数据。所以每次我们想修改数据的时候,我们都可能遇到之前提到的数据竞争。我们可以在每次进行修改操作的时候都拷贝数据,但是这样会很浪费。如果我们的变量是唯一指向数据的,我们就没理由拷贝信息。只有我们有多个变量引用到这份数据,我们才需要去拷贝。这意味着我们不得不去跟踪另一个重要的信息,即有多少变量引用同一份数据。我们在赋值操作时增加共享计数,在变量离开作用域时减少计数。新的数据拷贝会有新的计数,其初始化值为一。记住这个计数,这会是本文的一个关键元素。
Copy-On-Write in Rust
和C++不一样,Rust更注重安全,强类型,和显式抽象。因此,COW在Rust中拥有自己的类型便不足为奇,我们可以把这个类型用于已经存在的数据。在Rust中,COW是拥有两个状态的枚举(enums),这两个状态是Owned和Borrowed。对于non-rustacean,你可能想要阅读我另一篇关于 Enum & Pattern Matching - Part 1的文章。Owned包含了一个被拥有类型的值。Borrowed拥有一个对类型的引用的关联类型。这使得Rust的所有权系统能够开始运转。这意味着每一份数据最多只能拥有一个Owned类型的COW变量但是可以有很多Borrowed变量。通过COW,我们可以调用其所依赖的类上的任何不会修改数据的方法。如果我们确实想要修改数据,我们不得不调用COW上的一个名为to_mut的函数。当我们调用to_mut的时候,一个很直观的操作发生了。如果我们在Borrowed状态,这个数据会被克隆,而在Owned状态,我们只是获取这个数据,相当于空操作(no-op)。所以和C++不同,不是所有对数据的引用都生而平等。我们决定什么时候写代码,我们的COW将会有什么类型的状态,哪些因素决定这个数据是否会被克隆。在Rust里,COW是在数据之上一层很方便的包装,允许我们不知道它的所有权,并且因此可以节省不必要的数据克隆。当然,在Rust中使用COW也会有相应的开销。当我们创建一个BorrowedCOW时,Rust所有权系统开始生效。这意味着编译器需要能够证明这个数据活的足够长,这就强制要求只要COW还存在,我们就得持有(hold on)原始的变量,这些我们在C++里是不需要的。所有的这些变化导致了不同的抽象方式。和C++不同,在Rust里,它不是完全不可见的,我们需要做一些工作。我们需要把数据包装(wrap)进一个COW并且回到原始类型的时候需要解包(unwrap)。还有,每当我们想要修改数据的时候,我们不得不调用to_mut。
Is Copy-On-Write a pessimization?
回到Herb Suctter写的那篇文章。尽管我们已经知道COW拥有坚实而有逻辑的基础,但是他很详细地阐述了,在很多情况下,COWs实际上是最差的(方案)。Herb是C++圈子里比较有影响力的人之一,所以难怪在最后,C++11里,禁止了C++的string实现。非常感谢这篇文章,后来,我会详细介绍为什么他提出了这种观点。但是首先,我们应该理解这种观点适用于什么情况。Herb的文章里阐述了必要的前提条件:
- 这个库可能构建于多线程使用,这意味着即使你的程序是单线程的,也可能会受到退化(degradation)的影响
- 例子是用C++写的,但是这个讨论适用于任何语言。
这些前置条件很重要因为它们同样适用于Rust的用例。Rust的COW实现了Send和Sync特性(traits),这是由于Rust的安全性要求,意味着这种实现是设计用于多线程程序中。当然,Herb认为他的观点在任何语言中都是有效的,不只是C++。 最基本的,如果Herb是对的,我们应该预期当使用Rust的COW时,能看到性能上的退化,即使是在单线程程序中。这篇文章的剩余部分就是在解决这些关于COW效率的看上去又相互矛盾的观点。我也会阐述双方都有有力的证据证明各自的观点。最重要的是,我们会找到一个中间位置并解释每个人都是对的。最后,我会解释,为什么是Rust在这些语言的对比中占了上风。
Benchmarking Copy-On-Write in Rust
我们可以从简单的开始,来证明优化就是优化,我们要做的就是使用一些用例的基准测试来证明它。让我们用一个简单的用例来测试Rust的COW。即使是单线程的用例也可以。正如我们在第一个表述中说到的,即使是在单线程情况下,支持多线程用例的COW也会导致退化。我们的用例是简单的,作为开发者我们总会遇到这样的任务。我们有很多客户端,产生类似的数据,但是有不同的格式,我们必须把它们统一成相同的格式。我们的任务要获取URL,其中一些是("https//")协议为前缀,但是其他的不是。如果URL缺少这个前缀,我们就给它加上。这里是对这个任务的5个不同的实现,以各种方式来接收输入和重新得到输出。
pub fn add_http_prefix_1(input: &str) -> String {
if input.starts_with("https://") {
String::from(input)
} else {
["https://", input].concat()
}
}
pub fn add_http_prefix_2(mut input: String) -> String {
if input.starts_with("https://") {
input
} else {
input.insert_str(0, "https://");
input
}
}
pub fn add_http_prefix_3<T: AsRef<str>>(input: T) -> String {
if input.as_ref().starts_with("https://") {
String::from(input.as_ref())
} else {
["https://", input.as_ref()].concat()
}
}
pub fn add_http_prefix_4(input: &str) -> Cow<str> {
if input.starts_with("https://") {
Cow::Borrowed(input)
} else {
Cow::Owned(["https://", input].concat())
}
}
pub fn add_http_prefix_5(input: Cow<str>) -> Cow<str> {
if input.as_ref().starts_with("https://") {
input
} else {
match input {
Cow::Owned(mut input) => {
input.insert_str(0, "https://");
Cow::Owned(input)
}
Cow::Borrowed(input) => {
Cow::Owned(["https://", input.as_ref()].concat())
}
}
}
}
前面三种是比较常见的做法,每一个都做相同的任务,第一个只是借用了输入,第二个拥有完整的所有权,第三个使用了模板,这样能让用户选择是把这个值借我们还是给我们。在所有的情况下,我们不得不返回一个新的被拥有的字符串,因为我们可能会修改输入的内容。第四个实现借用数据,但是没有创建有一个新的字符串,而是充分利用在某些时候下我们不会修改输入内容这一情况。它让我们在没有修改的情况下重新取回COW的借用变量,当有修改发生的情况下,返回被拥有(owned)的版本。第五个实现更进一步地将输入也改成了COW。
这是我第一次用Rust代码进行测试,我选择使用criterion因为它似乎是这类任务的首选。测试在我的家用PC,一台Intel i7 8700,16G内存,运行Windows10的机器上进行。我尝试在性能测试期间尽可能地关闭后台干扰程序。这是我的最基本的测试代码:
pub fn criterion_benchmark(c: &mut Criterion) {
c.bench_function("test1", |b| b.iter(|| cow_perf::add_http_prefix_1(black_box("test"))));
c.bench_function("test2", |b| b.iter(|| cow_perf::add_http_prefix_2(black_box(String::from("test")))));
c.bench_function("test3", |b| b.iter(|| cow_perf::add_http_prefix_3(black_box("test"))));
c.bench_function("test4", |b| b.iter(|| cow_perf::add_http_prefix_4(black_box("test"))));
c.bench_function("test5", |b| b.iter(|| cow_perf::add_http_prefix_5(black_box(Cow::Borrowed("test")))));
c.bench_function("test1_2", |b| b.iter(|| cow_perf::add_http_prefix_1(black_box("https://test"))));
c.bench_function("test2_2", |b| b.iter(|| cow_perf::add_http_prefix_2(black_box(String::from("https://test")))));
c.bench_function("test3_2", |b| b.iter(|| cow_perf::add_http_prefix_3(black_box("https://test"))));
c.bench_function("test4_2", |b| b.iter(|| cow_perf::add_http_prefix_4(black_box("https://test"))));
c.bench_function("test5_2", |b| b.iter(|| cow_perf::add_http_prefix_5(black_box(Cow::Borrowed("https://test")))));
}
fn custom_criterion() -> Criterion {
Criterion::default()
.sample_size(1000)
}
criterion_group!(
name = benches;
config = custom_criterion();
targets = criterion_benchmark);
criterion_main!(benches);
我们不在此处浪费时间去测试,简单地来看一下测试的结果:
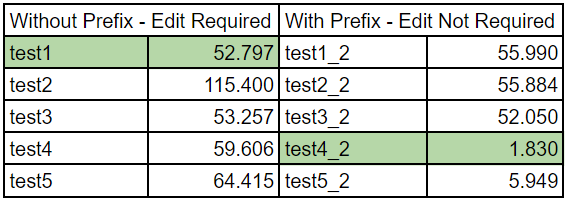
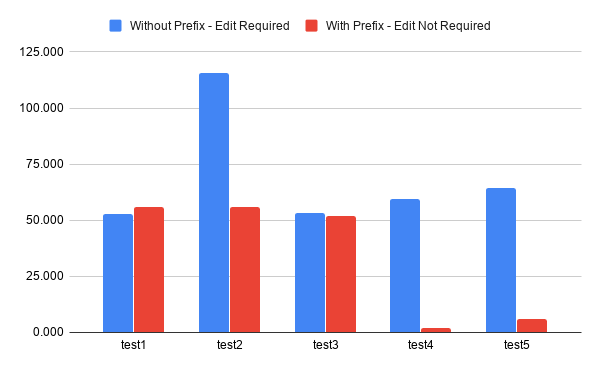 本文的主要内容就是要深入讨论这个测试结果。你们中的一些人可能甚至注意到我没有提供原始数据。其实我确实提供了重现结果需要的所有信息。而且,在深入数字之前,请记住基准测试(benchmark)是一个复杂的主题,比人们通常认为的要复杂的多。结果表明,并没有必要很精确地计较每种实现带来地好处/损失。这些对于我们理解整体的趋势已经是足够了,尤其是与我们的预期相一致时。我们将会把结果精简到我们只关心的那部分,来看看COW是否有助于提升性能。我会只集中讨论第一种和第四种实现。第一种实现,虽然在非COW实现中平均成绩不是表现最好的,但是当需要修改数据时却是性能最好的。第四个实现是使用COW优化的实现中表现最好的。结果显而易见。当我们需要修改数据时,COW比较慢。在这次测试中,第四个实现比第一个实现慢了13%(但是情况不一定每次都一样)。另一方面,当我们不需要修改数据时,第四个实现比第一个实现高出96%。
本文的主要内容就是要深入讨论这个测试结果。你们中的一些人可能甚至注意到我没有提供原始数据。其实我确实提供了重现结果需要的所有信息。而且,在深入数字之前,请记住基准测试(benchmark)是一个复杂的主题,比人们通常认为的要复杂的多。结果表明,并没有必要很精确地计较每种实现带来地好处/损失。这些对于我们理解整体的趋势已经是足够了,尤其是与我们的预期相一致时。我们将会把结果精简到我们只关心的那部分,来看看COW是否有助于提升性能。我会只集中讨论第一种和第四种实现。第一种实现,虽然在非COW实现中平均成绩不是表现最好的,但是当需要修改数据时却是性能最好的。第四个实现是使用COW优化的实现中表现最好的。结果显而易见。当我们需要修改数据时,COW比较慢。在这次测试中,第四个实现比第一个实现慢了13%(但是情况不一定每次都一样)。另一方面,当我们不需要修改数据时,第四个实现比第一个实现高出96%。
最主要的,在Rust中使用COW时,当我们想要做的只是读数据时,只要每次需要修改数据时增加一点儿成本就能获得巨大的收益。有很多用例都可以利用这一点来提高性能。这显然不像是Herb在讨论中提到的最差化(pessimization)。
Understanding why Copy-On-Write might be a pessimization
验证Herb的观点还是比较困难的。我们可以进行一次性能测试,在测试中COW在C++中的应用确实降低了性能。Herb也在他的文章中提到了一些。但是这些还不够,因为有人能够合理地认为问题是出在实现上,或者会提供给我们一个用例以及相关测试。Herb的观点比这更深刻,它们到达了这个优化的核心。他表明这个优化核心里的某些东西导致了在多线程情况下的性能衰退。我们没有办法绕过它,只能好好地去理解。
在Herb的核心观点中,有一些比拷贝数据代价更为昂贵的操作,在我们的用例中,我们讨论的是数据同步。当我们不得不对并发访问的数据进行同步时,这比单纯地拷贝数据需要更多的时间。现在,正如在C++所做的那样,如果我们想要保持COW对用户不可见,所有对COW共享数据的引用必须有相同的行为,是否只有一个这样的变量。和Rust不同,我们不能要求谁应该活的更久,或者给这些引用以各种方式打上标签,因为我们不在没有使用COW优化的引用上这么做。正如我们之前看到的,它会给我们造成一种没有任何额外数据的情况,这样子我就不能确定是否应该去拷贝共享数据。在更早一点儿的时候,我们使用一个引用计数来进行决定。很显然引用计数是需要被同步的,因为它会被并发访问。每一个访问都有可能修改计数的值。Herb认为,同步成本高于由减少数据拷贝带来的性能提升。
Rust’s smart design choice
现在我们已经看到,在Rust的情况中,我们可以使用一个比较聪明的设计来避免同步的成本。但是我们也要付出相应的代价,COW在Rust中是不可见的,我们不得不明确对COW的使用。让我们来看一下Rust是如何避免额外的同步成本的。和几乎是全部用C++实现的COW标准模块不同,Rust采取了另一种方法。正如我们之前所看到的,Rust中的COW只是让我们无法知晓数据的所有权。理解这个地方最本质的一点在于我们在编译期知道所有权。事实上,它是在运行时由输入决定的,但是对于任意的给定值,结果是确定的,我们要么拥有这个数据要么借用它。在我们的例子中,如果数据有"https://"的前缀,我们就只需要借用。否则,我们就拥有数据的所有权。我们只根据在编译期获知的所有权信息来决定是否拷贝数据。因此,我们不需要在对数据不同的引用之间保存额外的信息。因此,Rust中的COW不需要承担同步额外信息所带来的额外开销从而即便在多线程环境下也能实现真正的优化。
所以,我们看到在构建COW抽象的时候一个小小的修改是如何让我们在多线程环境下依然能够保持带来的好处。为此需要承担的代价在很多情况下都是可以忽略不计的,尽管它确实存在。COW的好处有时候也会消失,因为我们可能不得不让原始的数据保存地比它实际需要的时间更久。而且,数据的修改同样十分昂贵。
Why C++ lost to Rust in this front
现在我们剩下最后一个问题了。Rust的设计者尝试提出一种很好的设计来克服Herb在COW中发现的缺点。这似乎只要我们在需要使用COW的时候只需要付出一丁点的开销。但是这个设计只适用于Rust,或者说是以Herb为代表的这类人的疏忽,C++是否能够进行这种抽象?答案比我想的要复杂一些。事实上,C++什么都可以做到,所以我们可以尝试在C++中创建类似的COW。但是C++缺少像Rust的生命周期这样的关键特性使其有可能行得通。我们没有办法在C++中满足保留原始数据的要求。毫无疑问,我们可以告诉用户它们要把原始变量保存地足够长。它和之前听过的C++里不安全的东西还不太一样。尽管,当COW作为成员嵌入到另一个类时,那个类的用户甚至没有意识到COW的存在。要跟踪所需要的数据是否能活那么久几乎是不可能的。并且在C++标准中,这种不安全性也是不会被采纳的。这就告诉我们Rust的安全性确实帮助我们获得了比C++更好的性能。因为一些抽象真的是太不安全了,即使是对C++来讲。
Herb指出COW中存在的缺陷这件事是正确的。为了让优化依然有效,Rust在优化能力和易用性上做了一些妥协。Rust中的COWs更加复杂,也有更多的要求(保持原有数据存在足够长的时间)。不是C++中所有可能的COWs都能在Rust中实现。最明显地,在库内部的事物之后添加COW是不可能的,因为用户必须意识到它。但是Rust的设计者依然是对的,Rust中的COW如果使用合理地话,能够为优化提供很好的可能。我发现这对于C++和Rust拥护者无休止的争议来讲,是一个令人高兴的中间地带,因为有一种语言明显在这个话题上胜出了。Rust为安全性而设计,设计良好的生命周期使得Rust创造出了在C++中一直梦寐以求的更好的抽象。并且在这个特殊的案例中,我们也能看到,这个概念是如何实实在在地改善了性能。这是Rust压倒性的胜利。

