

分库分表原因及使用场景
海量数据的应用场景导致数据库效率低下,即使可以正常工作但是时间效率不尽人意。业界公认MySQL单表容量在1KW以下是最佳状态,因为这时它的BTREE索引树高在3~5之间。
索引(Index)
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。 最基本的查找方法为顺序查找(linear search) 效率很低O(N),其他数据结构 二分查找(binary search) **二叉树查找(binary tree search)**以上每一种数据结构都只能应用相对特定的数据类型。如二分查找要求被检索的数据有序,而二叉树应用于二叉查找树数据库。这样的数据结构将用某种方式引用数据,这种数据结构就是索引。
如下图举例,二叉树的数据结构为左边表的索引
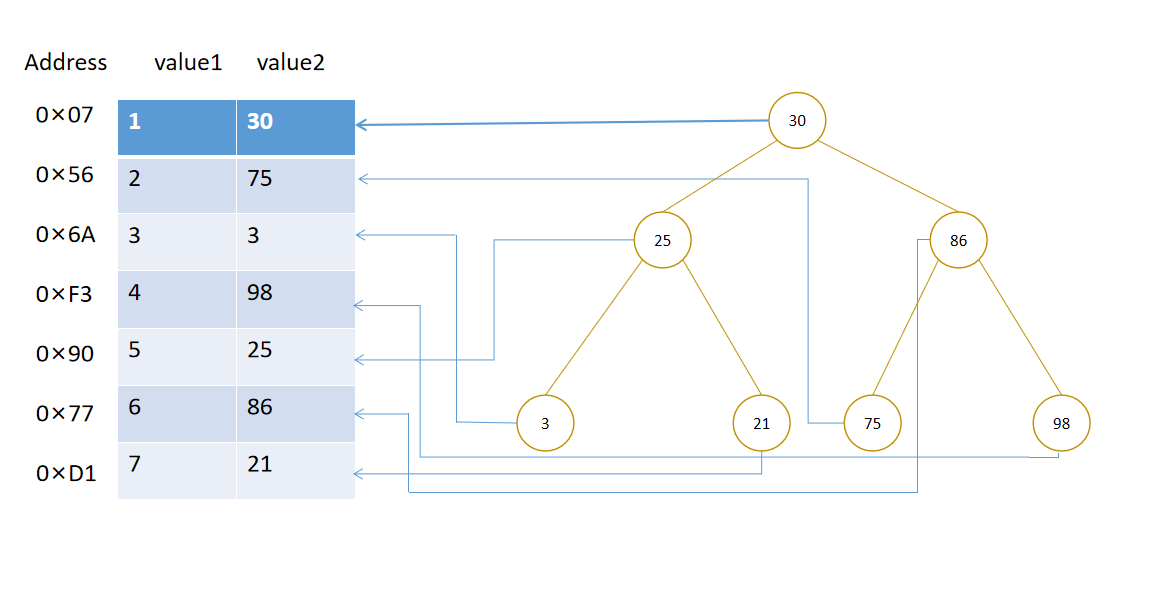
这样的二叉数搜索的时间复杂度为在O(Log2n)到O(n)之间,如果二叉树为平衡二叉树(满足任何节点的两个子树的高度最大差为1)性能最高。
B-Tree B+ Tree索引
B-Tree
- d 为正整数大于1,称为degree(度)。
- h为一个正整数,称为B-Tree的高度。
- 每个非叶子节点由n-1个key和n个point组成,其中d<=n<=2d
- 叶子节点的point都为null
- key和point互相间隔,节点两端是指针
- 一个节点中的key从左到右非递减排列。
B+Tree
B+Tree相对于B-Tree有几点不同:
- 非叶子节点只存储键值信息。
- 所有叶子节点之间都有一个链指针。
- 数据记录都存放在叶子节点中。
读写分离,主从复制
实际使用数据库的过程中往往是读大于写,所以我们可以通过将读写分离的方式优化读取速度。 写入操作必须在主库进行,而读取操作可以在主库和从库上进行
- 当读操作压力很大时,可以考虑添加从库机器来分解大量读操作带来的压力,但是当从库机器达到一定的数量时,就需要考虑分库来缓解压力了。
- 当写压力很大时,就必须进行分库分表操作了。
Relational Database Management System (RDMS)
切分方式重点划分
- 垂直切分:把单一的表拆分成多个表。
- 水平切分:根据表中数据的逻辑关系,将同一个表中的数据按照某种条件拆分成多个表结构相同的表,或者数据拆分到多台数据库(主机)上。
垂直切分。
顾名思义使用垂直切分的方式为了分割大型多列类型的表,减少IO使用量。保证表中较少的字段,避免出现数据库跨页存储的问题。
import pymysql
import dateutil.parser
import datetime,pytz
import time
import pandas as pd
# import datetime
# from time import strftime
# import strptime
a=datetime.datetime.now(pytz.timezone('Asia/Shanghai'))
# print(a)
sql_db = 'base_dev' # 指定mysql数据库名
#### 连接mysql
conn = pymysql.connect(host='***', user='root_dev',
password='***', port=**, charset='utf8')
cursor = conn.cursor()
cursor.execute("USE {}".format(sql_db)) # 连接数据库
#### 读取数据:
# table_list = ['table1', 'table2', 'table3', 'table4', 'table5', 'table6']
# table_list = ['base_mess_send_log', 'base_dict_entry']
table_list = ['base_common_log']
# print(table_list)
for table in table_list:
sql = """
SELECT create_time from base_dev.`{}` GROUP BY create_time
""".format(table)
cursor.execute(sql)
results_sql = cursor.fetchall()
table_date_list = []
results_sql11 = []
# print(table_date_list)
# print(results_sql)
for i in results_sql:
# print(results_sql)
## 此时i[0]的结构为2019-01-03 09:23:37
# create_time = i[0].strftime("%Y%m%d%H%I%M")
results_sql11.append(i[0])
print(results_sql11)
create_time1 = time.strftime('%Y-%m-%d %H:%I:%M', results_sql)
while True:
if len(table_date_list) > 8:
start_date_8 = table_date_list[:8]
create_tab = '{}_8_{}'.format(table, (start_date_8[0]))
print(start_date_8[0])
create_table_sql = """
CREATE TABLE `{}` LIKE `{}`
""".format(create_tab, table)
cursor.execute(create_table_sql)
conn.commit()
print(start_date_8)
for s_date in start_date_8:
format_date = dateutil.parser.parse(s_date)
# format_date = dateutil.parser(s_date)
# date_dash = time.strptime(s_date, '%Y-%m-%d %H:%M:%S')
# date_dash = pd.to_datetime(s_date)
# date_dash = str(format_date.date())
#print('date_dash', date_dash)
# print('######################################"')
# print(format_date)
# print(date_dash)
# print('s_date',s_date)
update_sql = """
INSERT INTO {} SELECT * FROM {} where create_time = '{}';
""".format(create_tab, table, format_date)
cursor.execute(update_sql)
conn.commit()
delete_sql = """
delete from `{}` where create_time = '{}'
""".format(table, format_date)
cursor.execute(delete_sql)
conn.commit()
del table_date_list[:8]
continue
if len(table_date_list) < 8:
print('pass')
break
