

在计算机中,cpu和内存的交互最为频繁,相比内存,磁盘读写太慢,内存相当于高速的缓冲区。
但是随着cpu的发展,内存的读写速度也远远赶不上cpu。因此cpu厂商在每颗cpu上加上高速缓存,用于缓解这种情况。现在cpu和内存的交互大致如下。

cpu上加入了高速缓存这样做解决了处理器和内存的矛盾(一快一慢),但是引来的新的问题 - 缓存一致性 在多核cpu中,每个处理器都有各自的高速缓存(L1,L2,L3),而主内存确只有一个 。
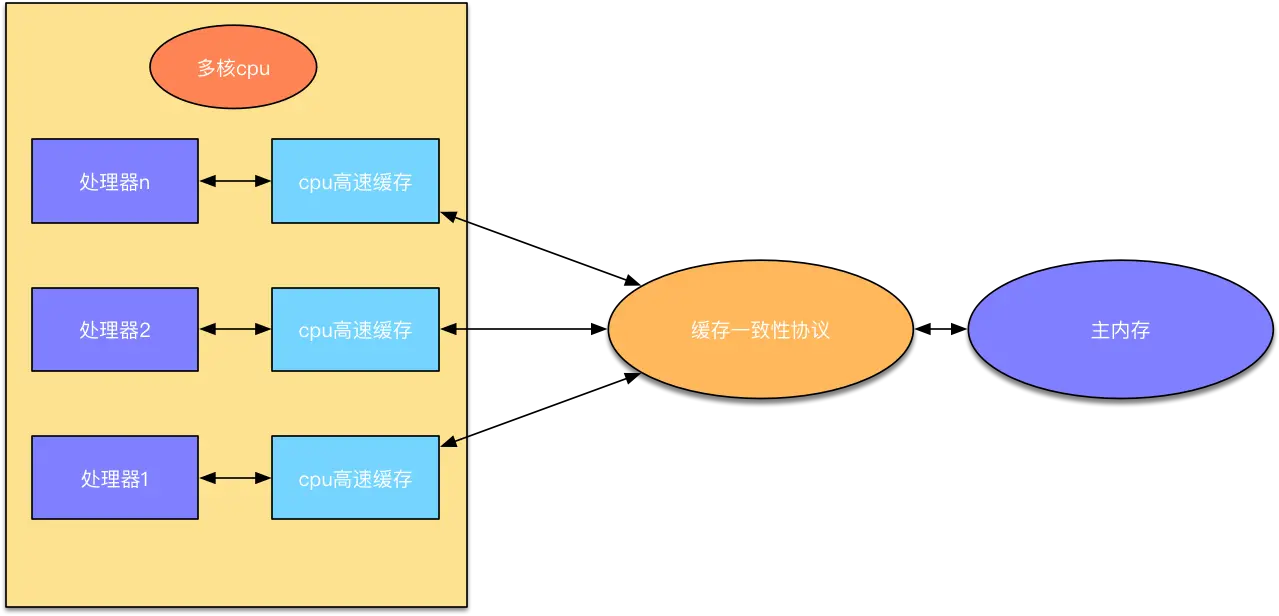
CPU要读取一个数据时,首先从一级缓存中查找,如果没有找到再从二级缓存中查找,如果还是没有就从三级缓存或内存中查找,每个cpu有且只有一套自己的缓存。
如何保证多个处理器运算涉及到同一个内存区域时,多线程场景下会存在缓存一致性问题,那么运行时保证数据一致性?为了解决这个问题,各个处理器需遵循一些协议保证一致性。【如MSI,MESI类似的协议】
在CPU层面,内存屏障提供了个充分必要条件
内存屏障(Memory Barrier)
CPU中,每个CPU又有多级缓存【上图统一定义为高速缓存】,一般分为L1,L2,L3,因为这些缓存的出现,提高了数据访问性能,避免每次都向内存索取,但是弊端也很明显,不能实时的和内存发生信息交换,分在不同CPU执行的不同线程对同一个变量的缓存值不同。
硬件层的内存屏障分为两种:Load Barrier 和 Store Barrier即读屏障和写屏障。【内存屏障是硬件层的】
为什么需要内存屏障
由于现代操作系统都是多处理器操作系统,每个处理器都会有自己的缓存, 可能存再不同处理器缓存不一致的问题,而且由于操作系统可能存在重排序, 导致读取到错误的数据,因此,操作系统提供了一些内存屏障以解决这种问题. 简单来说:
1.在不同CPU执行的不同线程对同一个变量的缓存值不同,为了解决这个问题。
2.用volatile可以解决上面的问题,不同硬件对内存屏障的实现方式不一样。
java屏蔽掉这些差异,通过jvm生成内存屏障的指令。
对于读屏障:在指令前插入读屏障,可以让高速缓存中的数据失效,强制从主内存取。
内存屏障的作用
cpu执行指令可能是无序的,它有两个比较重要的作用
1.阻止屏障两侧指令重排序
2.强制把写缓冲区/高速缓存中的脏数据等写回主内存,让缓存中相应的数据失效。
volatile型变量
当我们声明某个变量为volatile修饰时,这个变量就有了线程可见性,volatile通过在读写操作前后添加内存屏障。
volatile实现原理
volatile是怎样实现了?比如一个很简单的Java代码:
instance = new Instancce() //instance是volatile变量
在生成汇编代码时会在volatile修饰的共享变量进行写操作的时候会多出Lock前缀的指令(具体的大家可以使用一些工具去看一下,这里我就只把结果说出来)。我们想这个Lock指令肯定有神奇的地方,那么Lock前缀的指令在多核处理器下会发现什么事情了?
主要有这两个方面的影响:
- 将当前处理器缓存行的数据写回系统内存;
- 这个写回内存的操作会使得其他CPU里缓存了该内存地址的数据无效
为了提高处理速度,处理器不直接和内存进行通信,而是先将系统内存的数据读到内部缓存(L1,L2或其他)后再进行操作,但操作完不知道何时会写到内存。如果对声明了volatile的变量进行写操作,JVM就会向处理器发送一条Lock前缀的指令,将这个变量所在缓存行的数据写回到系统内存。但是,就算写回到内存,如果其他处理器缓存的值还是旧的,再执行计算操作就会有问题。
所以,在多处理器下,为了保证各个处理器的缓存是一致的,就会实现缓存一致性协议,每个处理器通过嗅探在总线上传播的数据来检查自己缓存的值是不是过期了,当处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器的缓存行设置成无效状态,当处理器对这个数据进行修改操作的时候,会重新从系统内存中把数据读到处理器缓存里。
因此,经过分析我们可以得出如下结论:
- Lock前缀的指令会引起处理器缓存写回内存;
- 一个处理器的缓存回写到内存会导致其他处理器的缓存失效;
- 当处理器发现本地缓存失效后,就会从内存中重读该变量数据,即可以获取当前最新值。 这样针对volatile变量通过这样的机制就使得每个线程都能获得该变量的最新值。
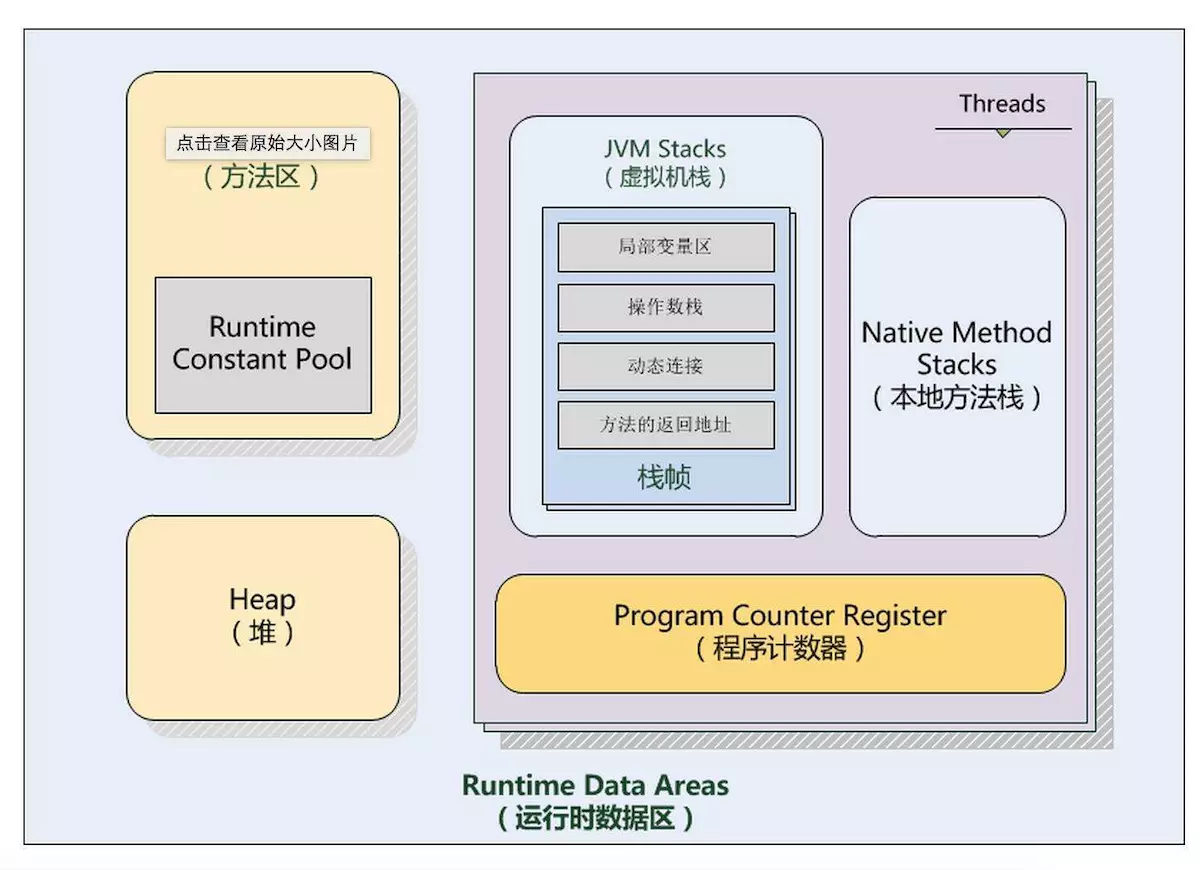
jvm内存模型
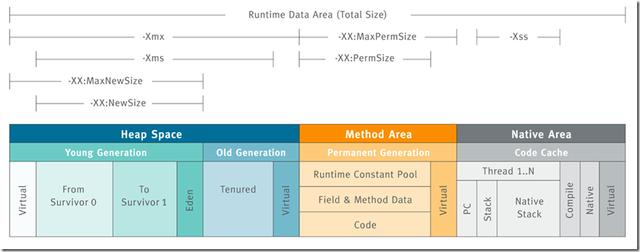
-Xms设置堆的最小空间大小。
-Xmx设置堆的最大空间大小。
-Xmn:设置年轻代大小
-XX:NewSize设置新生代最小空间大小。
-XX:MaxNewSize设置新生代最大空间大小。
-XX:PermSize设置永久代最小空间大小。
-XX:MaxPermSize设置永久代最大空间大小。
-Xss设置每个线程的堆栈大小
-XX:+UseParallelGC:选择垃圾收集器为并行收集器。
此配置仅对年轻代有效。即上述配置下,年轻代使用并发收集,而年老代仍旧使用串行收集。
-XX:ParallelGCThreads=20:配置并行收集器的线程数,
即:同时多少个线程一起进行垃圾回收。此值最好配置与处理器数目相等。
典型JVM参数配置参考:
java-Xmx3550m-Xms3550m-Xmn2g-Xss128k
-XX:ParallelGCThreads=20
-XX:+UseConcMarkSweepGC-XX:+UseParNewGC
-Xmx3550m:设置JVM最大可用内存为3550M。
-Xms3550m:设置JVM促使内存为3550m。此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。
-Xmn2g:设置年轻代大小为2G。整个堆大小=年轻代大小+年老代大小+持久代大小。
持久代一般固定大小为64m,所以增大年轻代后,将会减小年老代大小。
此值对系统性能影响较大,官方推荐配置为整个堆的3/8。
-Xss128k:设置每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。
更具应用的线程所需内存大 小进行调整。
在相同物理内存下,减小这个值能生成更多的线程。
但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000 左右。
