索引到底是什么
- 索引是帮助MySQL高效获取数据的排好序的数据结构
- 索引存储在文件里
- 索引结构
- 二叉树
- 红黑树
- HASH
- BTREE(至于为什么选BTREE 这种数据结构,回头单独写一篇文章)
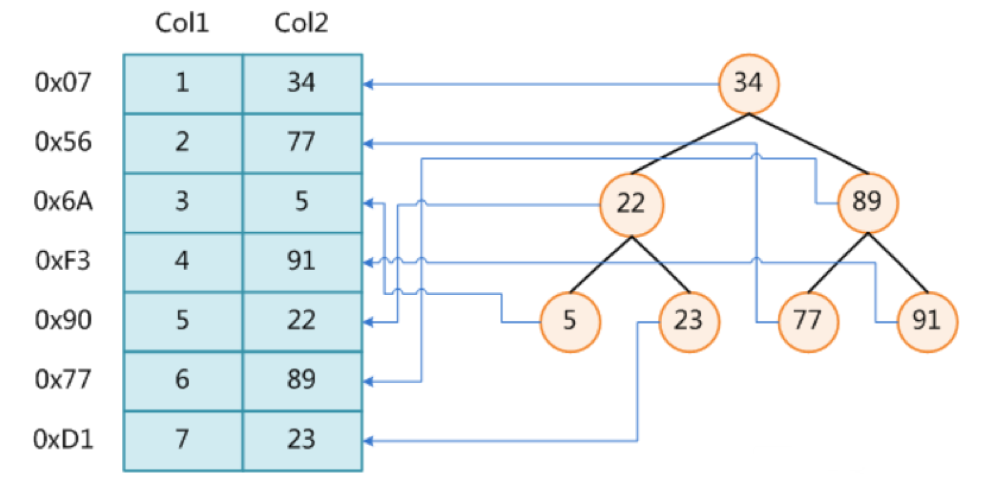
- B-Tree
- 度(Degree)-节点的数据存储个数
- 叶节点具有相同的深度
- 叶节点的指针为空
- 节点中的数据key从左到右递增排列
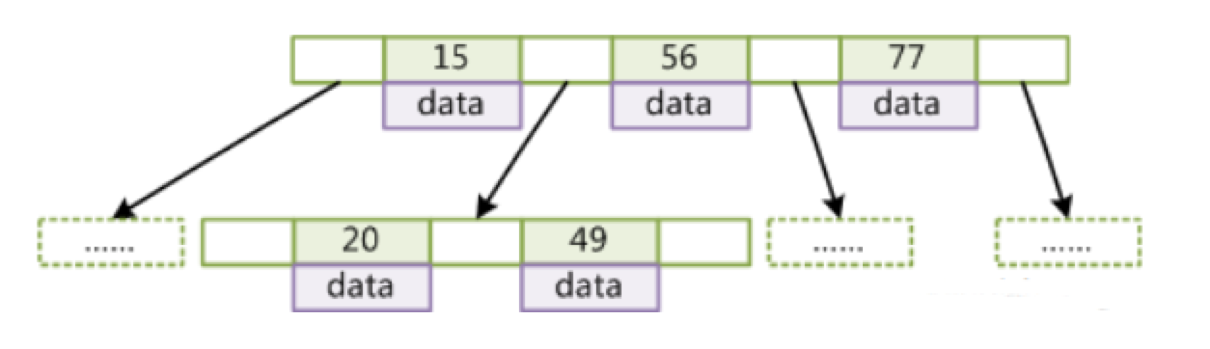
- B+Tree(B-Tree变种,mysql真正的数据结构)
- 非叶子节点不存储data(占用内存小),只存储索引(冗余),可以放更多的索引
- 叶子节点不存储指针
- 顺序访问指针,提高区间访问的性能
-
我们看到默认是16k的大小(为什么?16K)
- 而磁盘的一次IO是可以把16K数据load到内存的
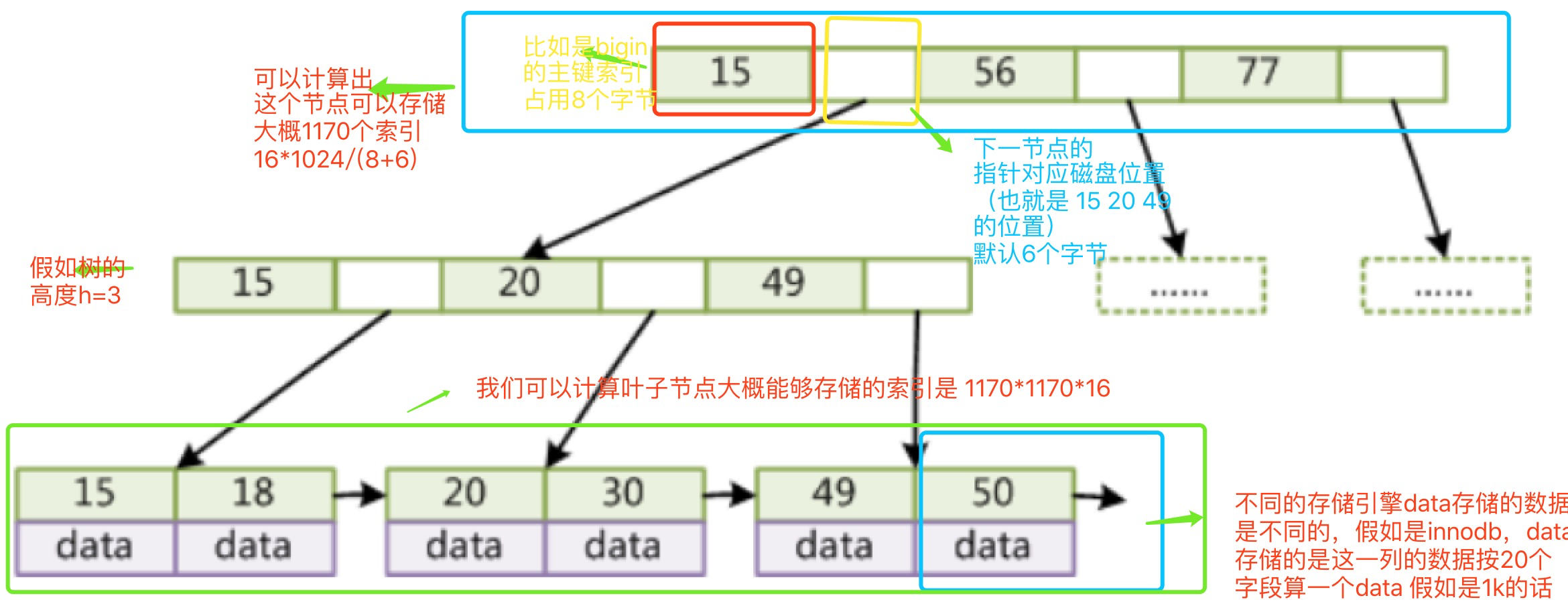
- 第二 我们假如数的高度是3,下图做下简单的分析,可以计算出大概可以存储2000万的索引元素
-
2千万的数据查询30的数据只需要3次磁盘的IO.效率很高。
-
MyISAM索引实现(非聚集) 表级别 不支持事物
- MyISAM索引文件和数据文件是分离的
- 我们用MyISAM搜索引擎创建的表会有三个文件分别是
- .frm 文件 (表结构).myd (数据文件) .myi(也就是我们说的索引文件)
-
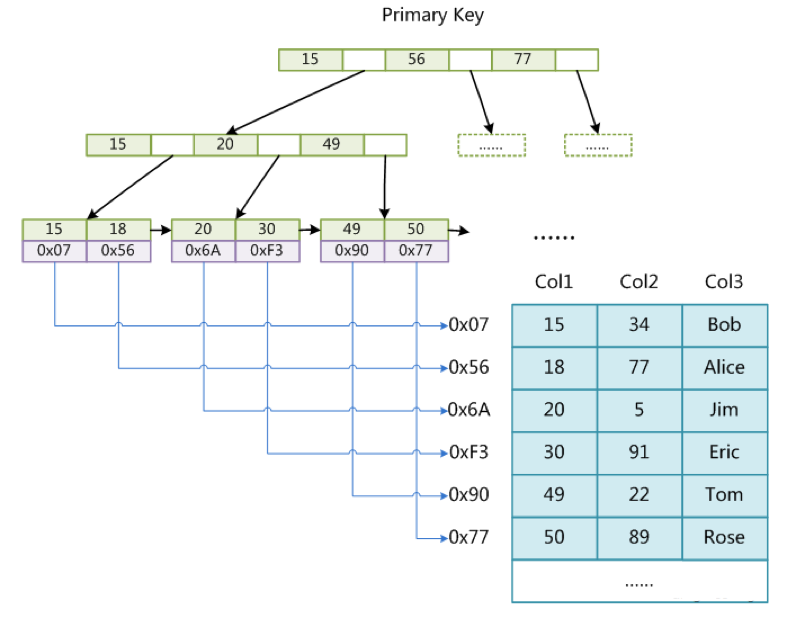
分析下主键索引
- 如下图,假如把Col1这个字段作为索引字段那么这一列的数据将会存在到myi文件(索引文件)也就是如下图所示这部分
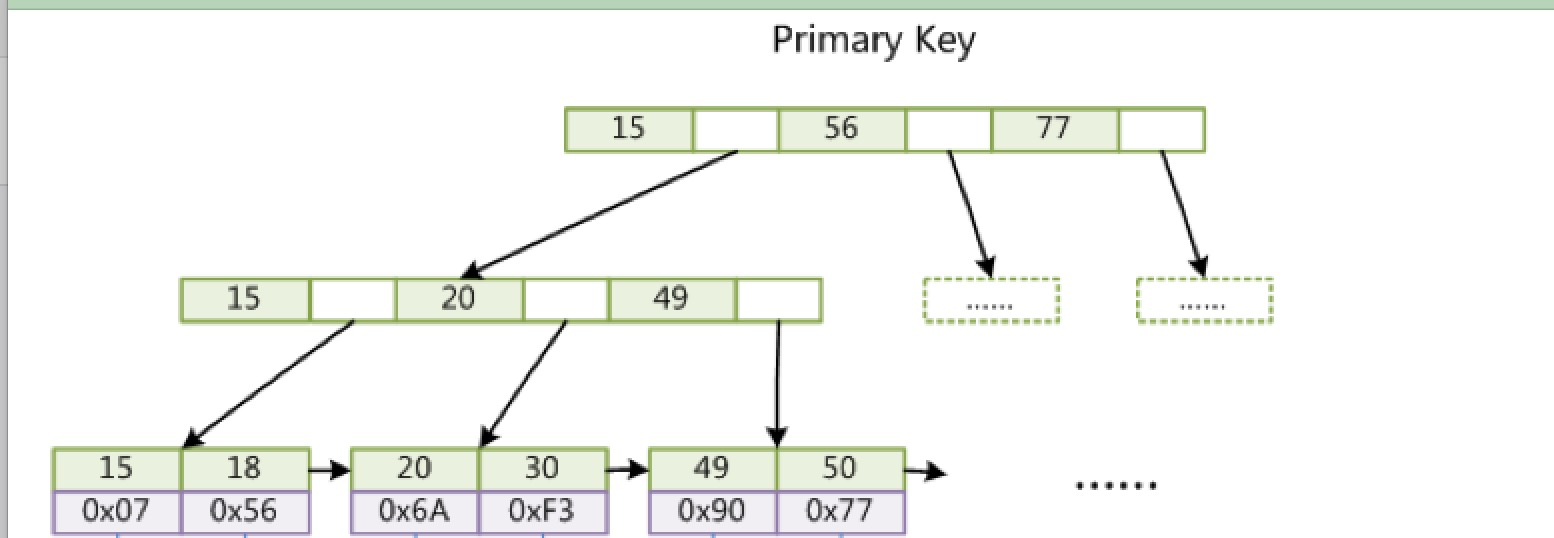
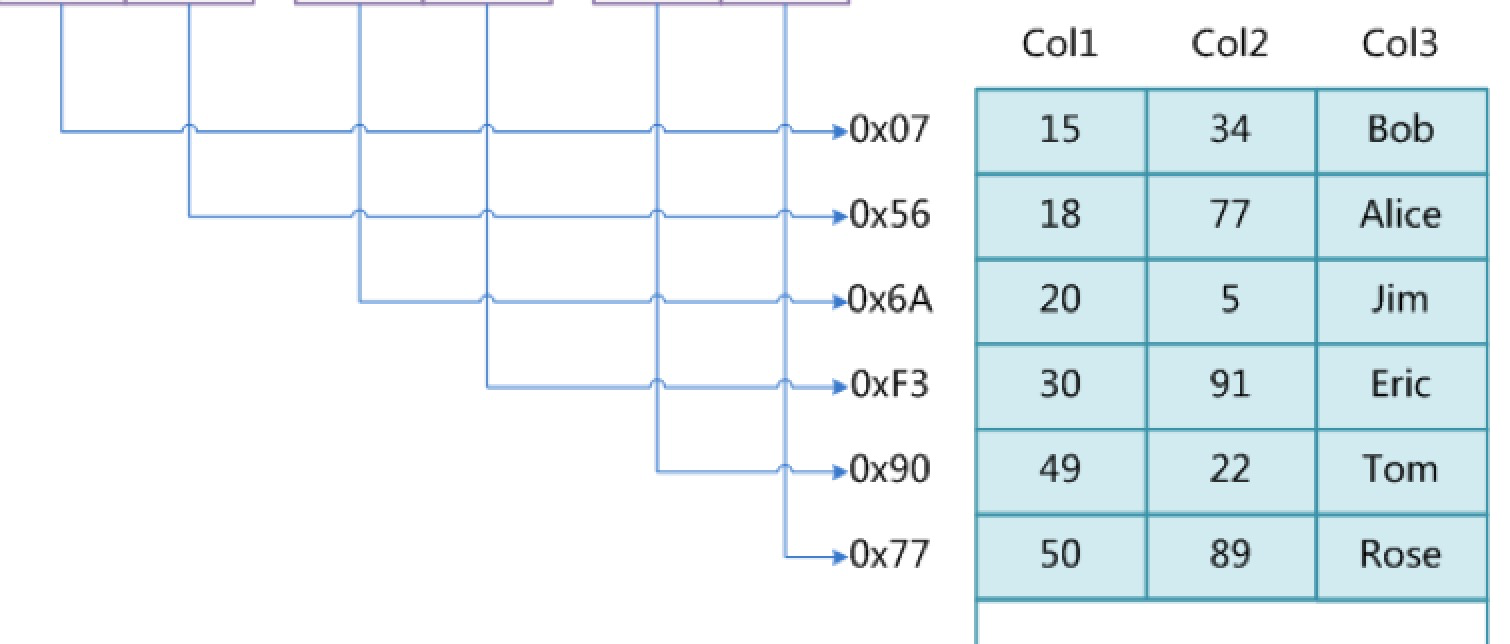
- 如下图,假如把Col1这个字段作为索引字段那么这一列的数据将会存在到myi文件(索引文件)也就是如下图所示这部分
-
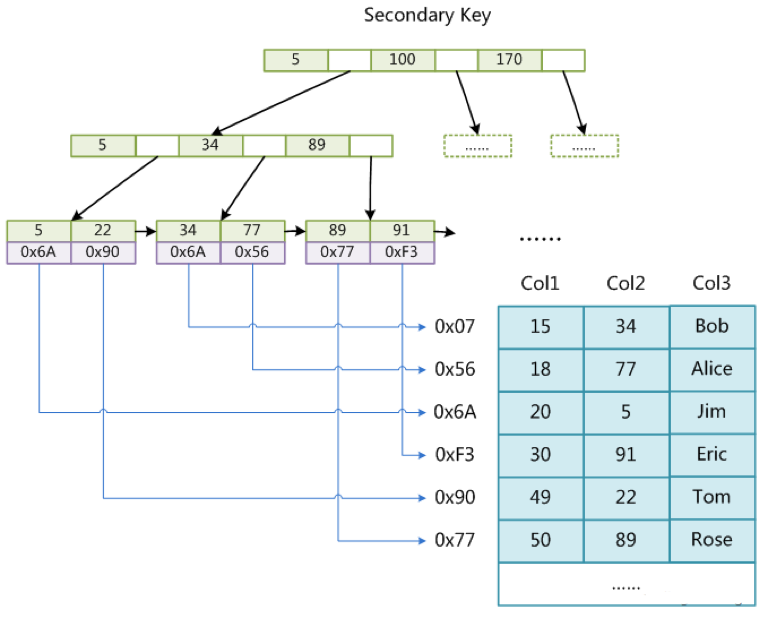
非主键索引同上。
-
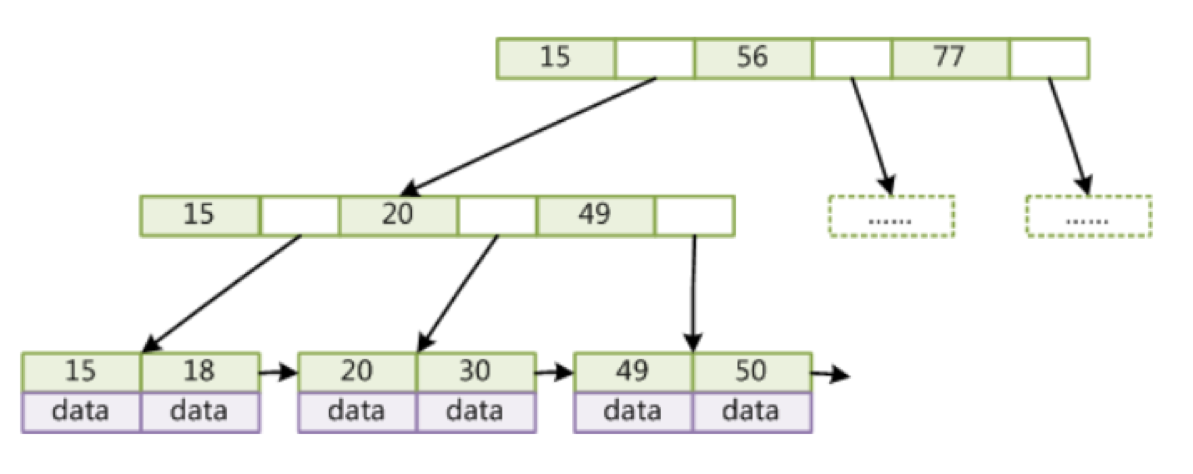
InnoDB索引实现(聚集(主键索引是集聚))
- 我们用InnoDB搜索引擎创建的表会有二个文件分别是
- .frm 文件 (表结构).IBD (数据跟索引文件)
- 数据文件本身就是索引文件
- 表数据文件本身就是按B+Tree组织的一个索引结构文件
- 聚集索引-叶节点包含了完整的数据记录
-
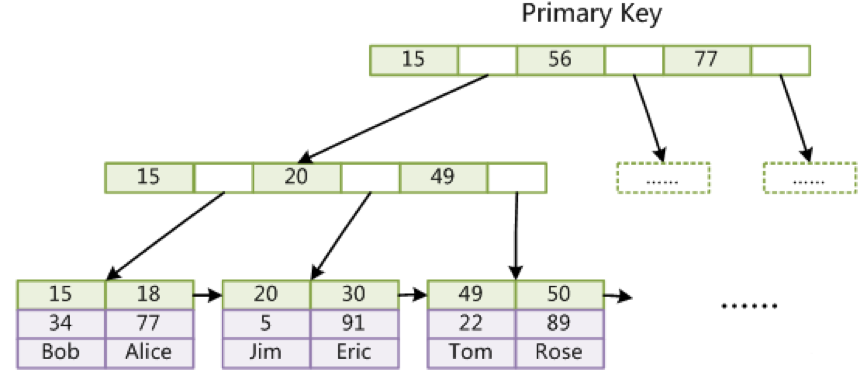
主键索引
-
为什么InnoDB表必须有主键,并且推荐使用整型的自增主键?
- 必须有主键:是因为B+Tree 的数据结构需要主键去组织。
- 假如我们的表没有创建主键的话,如果设置了唯一键索引,使用唯一键,如果没有唯一键索引,使用隐藏字段。row_id 一个自增六位的int型。
- 推荐使用整型的自增主键:
- 因为索引的树结构需要排序,整形的排序效率是高于其他数据类型的,并且叶子节点间是一个双向地址指针,便于快速查找下一个节点。
- 还有一点就是假如不是递增的主键,会导致新插入的数据可能会插到某些以查找好的节点中(比如20-30这个节点之间),而每个节点存储的数据是有限制(16k)的还会导致一个分裂的问题,会进行一系列的操作影响效率。而递增是不会出现这中问题的发生,这也是为何递增的一个点。
-
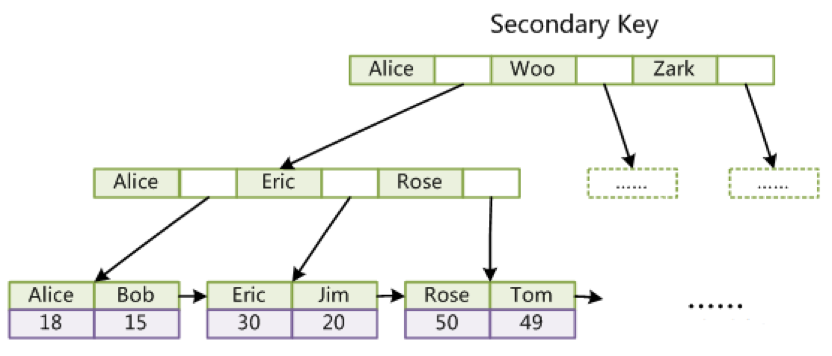
非主键索引
- 我们可以发现它的叶子节点存储的是主键值呢,为什么?(一致性和节省存储空间)
- 如果也存储数据的话,每次数据变动需要维护多份数据,存在数据一致性的问题
- 节省存储空间
- 我们可以发现它的叶子节点存储的是主键值呢,为什么?(一致性和节省存储空间)
-
联合索引的数据结构长什么样?(索引最左前缀原理)
- 三个字段自上而下的结构