1. 锁
1.1 全局锁
全局锁比较典型的应用场景是全库的逻辑备份。mysql提供了一个全局加读锁的方法Flush tables with read lock。所有的DDL(表结构变更)DML(增删改)会被阻塞。对于innodb这些事务存储引擎来说,可以使用一致性视图,来解决这个问题。这个全局锁的方法适用于myisam这些可以使用,如果备份过程中有更新,总是只能取到最新的数据,那么就破坏了备份的一致性。这时,我们就需要使用 FTWRL 命令了。
1.2 表级锁
1.2.1 表锁
表锁的语法是 lock tables … read/write,读锁之间相互不互斥,读写锁互斥,写锁互斥。在还没有出现更细粒度的锁的时候,表锁是最常用的处理并发的方式。而对于 InnoDB 这种支持行锁的引擎,一般不使用 lock tables 命令来控制并发,毕竟锁住整个表的影响面还是太大。
1.2.2 元数据锁MDL
MDL 不需要显式使用,在访问一个表的时候会被自动加上。MDL 的作用是,保证读写的正确性。你可以想象一下,如果一个查询正在遍历一个表中的数据,而执行期间另一个线程对这个表结构做变更,删了一列,那么查询线程拿到的结果跟表结构对不上,肯定是不行的。在 MySQL 5.5 版本中引入了 MDL,当对一个表做增删改查操作的时候,加 MDL 读锁;当要对表做结构变更操作的时候,加 MDL 写锁。
- 读锁之间不互斥,因此你可以有多个线程同时对一张表增删改查。
- 读写锁之间、写锁之间是互斥的,用来保证变更表结构操作的安全性。因此,如果有两个线程要同时给一个表加字段,其中一个要等另一个执行完才能开始执行。
MDL读锁是增删改查操作的时候会自动加上的,写锁是表结构变更的时候才回加,所以当表结构变更的时候,增删改查都会阻塞,所以直接变更表结构会影响线上业务,当表结构更改完成后释放写锁,增删改查的业务才能继续。
阻塞队列:有一点需要注意的是MDL写锁是会阻塞DML增删改查语句的,假如又增删改查语句在线程A执行,这是时候线程B运行DDL改了表结构,这个时候线程B的MDL写锁,会被线程A的MDL读锁阻塞,如果这个时候有线程C来DML查询,那么也会被阻塞,因为他看到线程B被阻塞进了阻塞队列,卧槽,那我也去后面排队吧,MDL这个原数据锁其实是为了保证DDL在改表结构过程中,DML增删改查的操作前后是一致的。所以,在进行表结构更新的时候需要注意,在进行表结构更改时需要添加超市时间,避免因为表更改导致的服务长时间不可用。
ALTER TABLE tbl_name WAIT N add column ..
1.3 行级锁
1.3.1两阶段锁
在 InnoDB 事务中,行锁是在需要的时候才加上的,要等到事务结束时才释放,这就是两阶段锁协议。
所以基于这个协议,那么在代码中,同一事务下,尽量将对同一条数据的更改放在最后面,这样当两个线程跑同一段代码时,前一事务对锁的持有时间会尽量减少。从而提高系统并发度。
1.3.2幻读和间隙锁
-
幻读:
在可重复度隔离级别下,因为普通的读取都是快照读也就是MVCC的一致性视图。但是更新是当前读。因为更新总要根据最新值进行更新。所以其实更新是不会造成幻读的,因为更新使会加上写锁的,造成幻读的是因为插入语句,在更新的与语义下,比如我要更新k=5的行,那么就是说明k=5的行应该都被锁住,不能动,如果这个时候插入了一条新的k=5的行那么首先就会造成语义上的破坏,第二会造成日志的逻辑破坏,因为数据一致性不仅要求数据正确,还要要求日志写入的正确。幻读的问题
- 语义上的破坏
- 一致性的破坏:假如事务A将k=5的数据改为k=100,事务未结束,这事事务B插入了一条k=5的记录,这个时候事务A提交事务,binlog里就会将最后提交事务的事务A将k=5改为k=100记录在后面,这样从逻辑上来讲就是吧新插入的k=5的事务B的记录也给更新了,无论是拿到备份库里执行或者恢复主库都会出错。
-
间隙锁: 为了解决幻读的问题,引入了间隙锁,间隙锁会锁住两个值之间的空隙,跟间隙锁存在冲突关系的,是“往这个间隙中插入一个记录”这个操作,两个相同的间隙锁不会冲突。间隙锁的引入,可能会导致同样的语句锁住更大的范围,这其实是影响了并发度的。 具体的加锁规则如下:
- 加锁的基本单位是next-key lock 就是行锁和GAP锁结合。
- 查找过程中访问到的对象就会加锁。
- 索引上的等值查询,给唯一索引加锁的时候,next-key lock退化为行锁。
- 索引上的等值查询,向右遍历时且最后一个值不满足等值条件的时候,next-key lock退化为间隙锁。
- 唯一索引上的范围查询会访问到不满足条件的第一个值为止。
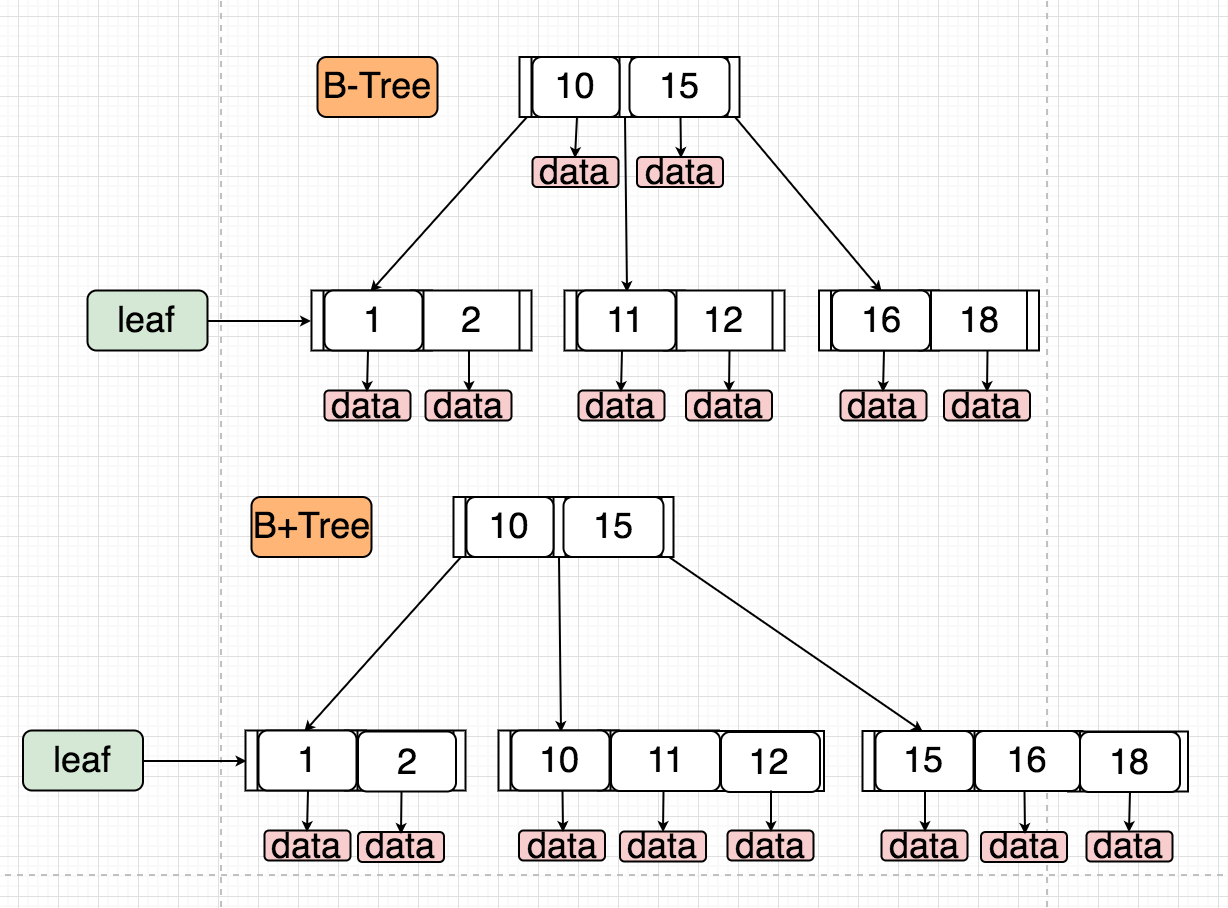
ps:需要注意的是,innodb是索引组织的存储结构,可以简单理解所有的数据都是挂在树上的,树的叶子节点是id,然后id会指向对应的数据条目,那么行锁工作的时候是其实是锁的主树的id的访问的,然后相对于普通索引其实也是这样的,如果只走普通索引的查询,这个时候不会锁住主树的id,那么针对id进行筛选的更新还是可一致性的,锁住的只是这个索引叶子节点的访问。索引的存储之所以经常用B+树来存储,是因为数据都在叶子节点上,那么可以降低树的高度,获得一个稳定的查询效率,这也解释了为什么UUID作主键会降低查询效率,因为无需和过长,会占用存储空间,一页中可存储的数据较少,所以会降低效率。