

什么时候用ziplist?什么时候用skiplist
数据量小的时候使用ziplist,由两个参数决定
- 元素数量小于128
- 所有member长度大小小于64字节
- 以上两个条件的上限值可通过zset-max-ziplist-entries和zset-max-ziplist-value来修改。
先了解一下skiplist是什么?
个人理解,像是简易版本的树一样,看这块的实现我有种感觉他的物理结构像是btree,不过没有btree那么严格的一层一层的朝上扩充,他是随机的一层一层的,数据落在哪一层由随机算法得出,不过这个随意算出层数的算法也是有点玄机的,类似于层数越高的概率越小,由p和出现的最大层数maxLevel决定,总体是越向上的层数分布越稀疏:伪代码实现:
randomLevel()
level := 1
// random()返回一个[0...1)的随机数
while random() < p and level < MaxLevel do
level := level + 1
return level
类比hash表及平衡树

- 总结对比
- hash不适合范围查找,适合精确查找,zset需要做范围查询
- 不用红黑树等各种平衡树啥的是跳跃表实现比较简单,使用树新增删除时候会导致子树的调整,逻辑与开销比较大
只靠跳跃表是无法实现zset的,还需要依靠字典dict的配合
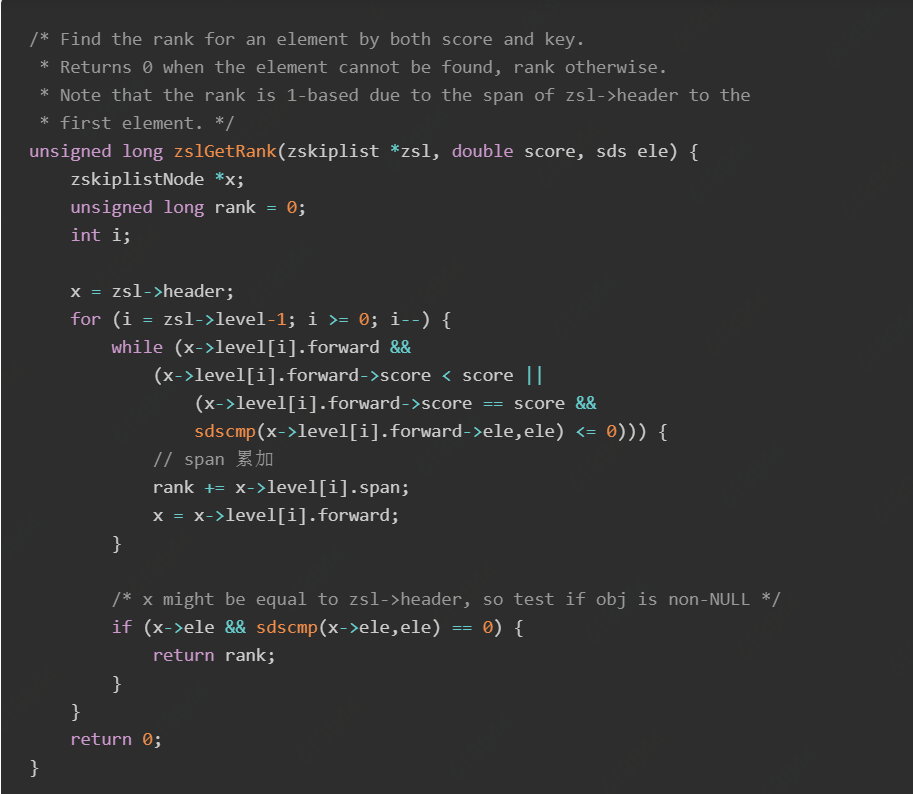
补充一个:zset如何获取一个元素的排名,rank
跳跃表本身是有序的,Redis 在 skiplist 的 forward 指针上进行了优化,给每一个 forward 指针都增加了 span 属性,用来 表示从前一个节点沿着当前层的 forward 指针跳到当前这个节点中间会跳过多少个节点。在上面的源码中我们也可以看到 Redis 在插入、删除操作时都会小心翼翼地更新 span 值的大小。
所以,沿着 “搜索路径”,把所有经过节点的跨度 span 值进行累加就可以算出当前元素的最终 rank 值了
参考如下文章:感谢
