

在之前,我们探索了类的结构,成员变量,属性和方法是如何存储的,但是我们似乎漏了什么?
类的结构中还剩一个cache_t我们还没有探究,今天我们就来探究在cache_t。
struct objc_class : objc_object {
// Class ISA; 8字节
Class superclass; // 8字节
cache_t cache; // 16字节 // formerly cache pointer and vtable
class_data_bits_t bits; // class_rw_t * plus custom rr/alloc flags
class_rw_t *data() {
return bits.data();
}
......
}
一:cache_t初探
1. 定义
首先我们看看cache_t在源码中如何定义的
struct cache_t {
struct bucket_t *_buckets; // 结构体 8字节
mask_t _mask; // mask_t 是 uint32_t 4字节
mask_t _occupied; // 4字节
}
2. 成员
从源码中可以看出cache_t一共有三个成员:
-
buckets,这是一个bucket_t类型的结构体指针
-
_mask,这是一个mask_t类型,和hash容量相关
-
_occupied,这也是一个mask_t类型,记录已经占用的容量
下面我们来看下bucket_t的定义
struct bucket_t {
private:
// IMP-first is better for arm64e ptrauth and no worse for arm64.
// SEL-first is better for armv7* and i386 and x86_64.
#if __arm64__
MethodCacheIMP _imp;
cache_key_t _key;
#else
cache_key_t _key;
MethodCacheIMP _imp;
#endif
public:
inline cache_key_t key() const { return _key; }
inline IMP imp() const { return (IMP)_imp; }
inline void setKey(cache_key_t newKey) { _key = newKey; }
inline void setImp(IMP newImp) { _imp = newImp; }
void set(cache_key_t newKey, IMP newImp);
};
现在我们大致的了解了cache_t的结构和定义,但是我们还将继续探索下去系统究竟是怎么缓存的呢?
二:LLDB找到问题
既然要研究方法是怎么缓存的,那么首先我们现在WYPerson类中定义三个方法
@interface WYPerson : NSObject
- (void)eat;
-(void)jump;
- (void)smile;
@end
@implementation WYPerson
-(void)eat
{
NSLog(@"eat");
}
-(void)jump
{
NSLog(@"jump");
}
- (void)smile
{
NSLog(@"smile");
}
@end
分别在三个方法前打上断点
WYPerson *p1 = [WYPerson alloc]init];
Class pClass = [p1 class];
[p1 eat]; // 断点
[p1 jump]; // 断点
[p1 smile]; // 断点
NSLog(@"%@ -- %p",p1,pClass);
之前的文章我们通过内存偏移的方式打印出了ro,现在我们用同样的方式,去获取cache_t。
当运行到eat方法,打印cache_t,注意_occupied = 2,确实缓存有[NSObject class]()和[NSObject init]()方法。或许有人会有疑问,为什么没有缓存alloc方法呢?原因在于alloc是类方法,存在元类的cache_t中。
(lldb) p/x pClass
(Class) $0 = 0x0000000100001420 WYPerson
(lldb) p (cache_t *)0x0000000100001430
(cache_t *) $1 = 0x0000000100001430
(lldb) p *$1
(cache_t) $2 = {
_buckets = 0x0000000101954fc0
_mask = 3
_occupied = 2
}
(lldb) p $3[0]
(bucket_t) $5 = {
_key = 4309273064
_imp = 0x00000001003916b0 (libobjc.A.dylib`::-[NSObject class]() at NSObject.mm:2010)
}
(lldb) p $3[1]
(bucket_t) $6 = {
_key = 4309273101
_imp = 0x0000000100393520 (libobjc.A.dylib`::-[NSObject init]() at NSObject.mm:2330)
}
当运行到jump方法,打印cache_t,注意_occupied = 3,确实缓存有[NSObject class]()和[NSObject init](),以及[WYPerson eat]方法
(lldb) p *$1
(cache_t) $3 = {
_buckets = 0x0000000100f34610
_mask = 3
_occupied = 3
}
(lldb) p $12._buckets
(bucket_t *) $13 = 0x000000010188d5f0
(lldb) p *$13
(bucket_t) $14 = {
_key = 4309273064
_imp = 0x00000001003916b0 (libobjc.A.dylib`::-[NSObject class]() at NSObject.mm:2010)
}
(lldb) p $13[0]
(bucket_t) $15 = {
_key = 4309273064
_imp = 0x00000001003916b0 (libobjc.A.dylib`::-[NSObject class]() at NSObject.mm:2010)
}
(lldb) p $13[1]
(bucket_t) $16 = {
_key = 4309273101
_imp = 0x0000000100393520 (libobjc.A.dylib`::-[NSObject init]() at NSObject.mm:2330)
}
(lldb) p $13[2]
(bucket_t) $17 = {
_key = 4294971286
_imp = 0x0000000100000da0 (objc-test`-[WYPerson eat] at WYPerson.m:12)
}
(lldb) p $13[3]
(bucket_t) $18 = {
_key = 0
_imp = 0x0000000000000000
}
当运行到smile方法,打印cache_t,注意_occupied = 1,但是里面缓存的方法却一个都没有,你没有看错,真的一个都没有。
(lldb) p *$1
(cache_t) $4 = {
_buckets = 0x00000001010709b0
_mask = 7
_occupied = 1
}
(lldb) p $2._buckets
(bucket_t *) $3 = 0x0000000102201f80
(lldb) p *$3
(bucket_t) $4 = {
_key = 0
_imp = 0x0000000000000000
}
(lldb) p $3[0]
(bucket_t) $5 = {
_key = 0
_imp = 0x0000000000000000
}
(lldb) p $3[1]
(bucket_t) $6 = {
_key = 0
_imp = 0x0000000000000000
}
当smile执行完成之后,打印cache_t,注意_occupied = 2,从中也的确找到了[WYPerson jump]和[WYPerson smile]
(lldb) p *$1
(cache_t) $5 = {
_buckets = 0x00000001010709b0
_mask = 7
_occupied = 2
}
......shenglue部分无用的打印
(lldb) p $10[2]
(bucket_t) $14 = {
_key = 4294971290
_imp = 0x0000000100000dd0 (objc-test`-[WYPerson jump] at WYPerson.m:16)
}
(lldb) p $10[7]
(bucket_t) $19 = {
_key = 4294971295
_imp = 0x0000000100000e00 (objc-test`-[WYPerson smile] at WYPerson.m:20)
}
通过上面的打印,我们发现似乎和我们预想的不太一样啊,按理说应该会出现1,2,3,4,5的啊,来一个方法缓存一个,再来个方法再缓存一个。现实是很骨感,而且我们惊悚的发现前面缓存的方法没有了,虽然没有了,但是_occupied确实是等于缓存的方法数。这难道就结束了吗?显然没有!
三:源码查漏补缺
通过上面的分析,_occupied取决于缓存的方法数量,而_buckets里面存的就是方法的信息,_mask从3变到7发生了什么呢? 我们只能从cache_t中与mask相关的入手了,我们点击mask()函数,来到了cache_t的源文件
struct cache_t {
struct bucket_t *_buckets; // 结构体 8字节
mask_t _mask; // mask_t 是 uint32_t 4字节
mask_t _occupied; // 4字节
public:
struct bucket_t *buckets();
mask_t mask(); // 从这个mask()入手
mask_t occupied();
在cache_t中,mask()仅仅做了一个返回的操作
mask_t cache_t::mask()
{
return _mask;
}
显然不会那么简单,全局搜索mask(),发现capacity()方法
mask_t cache_t::capacity()
{
return mask() ? mask()+1 : 0;
}
从字面来看,capacity()大概率跟容量有关,我们看看什么地方调用capacity()
1.缓存扩容
贴出关键的一处
void cache_t::expand()
{
cacheUpdateLock.assertLocked();
uint32_t oldCapacity = capacity();
uint32_t newCapacity = oldCapacity ? oldCapacity*2 : INIT_CACHE_SIZE;
if ((uint32_t)(mask_t)newCapacity != newCapacity) {
// mask overflow - can't grow further
// fixme this wastes one bit of mask
newCapacity = oldCapacity;
}
reallocate(oldCapacity, newCapacity);
}
int32_t oldCapacity = capacity();
- 通过
capacity()获取当前容量的大小
uint32_t newCapacity = oldCapacity ? oldCapacity*2 : INIT_CACHE_SIZE;
enum {
INIT_CACHE_SIZE_LOG2 = 2,
INIT_CACHE_SIZE = (1 << INIT_CACHE_SIZE_LOG2)
};
- 判断当前的容量大小,如果为0,则赋值为
INIT_CACHE_SIZE,通过枚举可知INIT_CACHE_SIZE初始值为4,如果当前容量大小不为 0,则直接翻倍,newCapacity扩容到原来的2倍。
if ((uint32_t)(mask_t)newCapacity != newCapacity)
- 检查容量溢出,如果无法再扩容,还是保持原来的容量,但是会重新分配空间,
reallocate方法就是开辟空间,在内部有一个释放旧空间的操作。
if (freeOld) {
cache_collect_free(oldBuckets, oldCapacity);
cache_collect(false);
}
2. 缓存的入口
顺着扩容这根线索,我们看看在什么时候扩容的呢,于是我们找到了cache_fill_nolock
static void cache_fill_nolock(Class cls, SEL sel, IMP imp, id receiver)
{
cacheUpdateLock.assertLocked();
// Never cache before +initialize is done
if (!cls->isInitialized()) return;
// Make sure the entry wasn't added to the cache by some other thread
// before we grabbed the cacheUpdateLock.
if (cache_getImp(cls, sel)) return;
cache_t *cache = getCache(cls);作
cache_key_t key = getKey(sel);
// Use the cache as-is if it is less than 3/4 full newOccupied
mask_t newOccupied = cache->occupied() + 1;
mask_t capacity = cache->capacity();
if (cache->isConstantEmptyCache()) {
// Cache is read-only. Replace it.
cache->reallocate(capacity, capacity ?: INIT_CACHE_SIZE);
}
else if (newOccupied <= capacity / 4 * 3) {
// Cache is less than 3/4 full. Use it as-is.
}
else {
// Cache is too full. Expand it.
cache->expand();
}
// Scan for the first unused slot and insert there.
// There is guaranteed to be an empty slot because the
// minimum size is 4 and we resized at 3/4 full.
bucket_t *bucket = cache->find(key, receiver);
if (bucket->key() == 0) cache->incrementOccupied();
bucket->set(key, imp);
}
}
下面对这个方法作出相应的解释
cacheUpdateLock.assertLocked();加锁的判断if (cache_getImp(cls, sel)) return;取缓存,如果已经有缓存直接返回cache_t *cache = getCache(cls)**先拿到当前类的缓存对象.也就是cache_tcache_key_t key = getKey(sel);根据sel拿到key,getKey内部有一个强转操作mask_t newOccupied = cache->occupied() + 1;在cache已经占用的基础上进行加 1,得到的是新的缓存占用大小newOccupied。mask_t capacity = cache->capacity();获取当前hash表的容量
接下来就是一些判断条件
if (cache->isConstantEmptyCache()) {
// Cache is read-only. Replace it.
cache->reallocate(capacity, capacity ?: INIT_CACHE_SIZE);
}
如果缓存为空了,那么就申请内存并覆盖之前的缓存,之所以这样做是因为缓存是只读的
else if (newOccupied <= capacity / 4 * 3) {
// Cache is less than 3/4 full. Use it as-is.
}
如果新的缓存占用大小 小于等于 缓存容量的四分之三,则可以进行缓存流程
else {
// Cache is too full. Expand it.
cache->expand();
}
如果缓存不为空,且缓存占用大小已经超过了容量的四分之三,则需要进行扩容
bucket_t *bucket = cache->find(key, receiver);通过前面生成的key在缓存中查找对应的bucket_t,也就是对应的方法实现
if (bucket->key() == 0) cache->incrementOccupied();
bucket->set(key, imp);
判断获取到的 bucket 是否是新的,如果是的话,就在缓存里面增加一个占用大小。然后把 key 和 imp 放到里面。
到此为止,我们大概的了解了cache_fill_nolock中的操作,下面就是深入这些方法。
3. 开辟缓存内存空间
reallocate定义
void cache_t::reallocate(mask_t oldCapacity, mask_t newCapacity)
{
bool freeOld = canBeFreed();
bucket_t *oldBuckets = buckets();
bucket_t *newBuckets = allocateBuckets(newCapacity);
// Cache's old contents are not propagated.
// This is thought to save cache memory at the cost of extra cache fills.
// fixme re-measure this
assert(newCapacity > 0);
assert((uintptr_t)(mask_t)(newCapacity-1) == newCapacity-1);
setBucketsAndMask(newBuckets, newCapacity - 1);
if (freeOld) {
cache_collect_free(oldBuckets, oldCapacity);
cache_collect(false);
}
}
void cache_t::setBucketsAndMask(struct bucket_t *newBuckets, mask_t newMask)
{
mega_barrier();// 异常处理
_buckets = newBuckets;
mega_barrier();// 异常处理
_mask = newMask;
_occupied = 0;
}
在reallocate方法中,系统干了三件事情:
-
- 根据传入
newCapacity开辟一块新的内存空间
- 根据传入
-
- 更新
cache成员变量,这一步在setBucketsAndMask(newBuckets, newCapacity - 1);中实现,你会发现去掉异常处理其实结构和cache_t一样,但是需要注意_buckets = newBuckets;现在_buckets指向的是新开辟的内存空间了。而且_mask也是根据外界传入重新赋值。
- 更新
-
- 释放旧空间
注意: 在最上面我们打印的时候曾经出现过_mask为刚开始的 3 变成后来的 7,其实在这个方法中我们找到答案。在setBucketsAndMask(newBuckets, newCapacity - 1);更新成员的时候,系统有一个newCapacity - 1的操作,所以我们看到的容量将会是 3/7/15....
4. 查找缓存
find源码定义
bucket_t * cache_t::find(cache_key_t k, id receiver)
{
assert(k != 0);
bucket_t *b = buckets();
mask_t m = mask();
mask_t begin = cache_hash(k, m);
mask_t i = begin;
do {
if (b[i].key() == 0 || b[i].key() == k) {
return &b[i];
}
} while ((i = cache_next(i, m)) != begin);
// hack
Class cls = (Class)((uintptr_t)this - offsetof(objc_class, cache));
cache_t::bad_cache(receiver, (SEL)k, cls);
}
static inline mask_t cache_hash(cache_key_t key, mask_t mask)
{
return (mask_t)(key & mask);
}
static inline mask_t cache_next(mask_t i, mask_t mask) {
return (i+1) & mask;
}
这里很明显看出,存储缓存是通过hash表来实现的。实际上在cache_t中的结构体指针_buckets其实就是hash表的起始地址,最终find返回的是bucket_t,里面有key(sel)和IMP。
bucket_t *b = buckets();mask_t m = mask();分别直接返回_buckets和_maskmask_t begin = cache_hash(k, m);这句其实就是调用cache_hash方法,key即为sel,这一步是通过key(sel)与mask(掩码)进行按位与操作之后得到sel在hash表中的索引并赋值得begin变量i = begin进行赋值,相当于从i开始找b[i]是取出hash表这个索引位置的bucket_t对象,如果key是否和入参k相等,相等就命中缓存,返回bucket_t对象的地址 &b[i]。(i = cache_next(i, m)) != begin,其实说白了就是从begin位置开始查找,然后i-1的位置继续找,循环找一圈,如果一圈都没有找到,就会走bad_cache,进行相应的异常处理 这个查找过程可以用一张图来概括
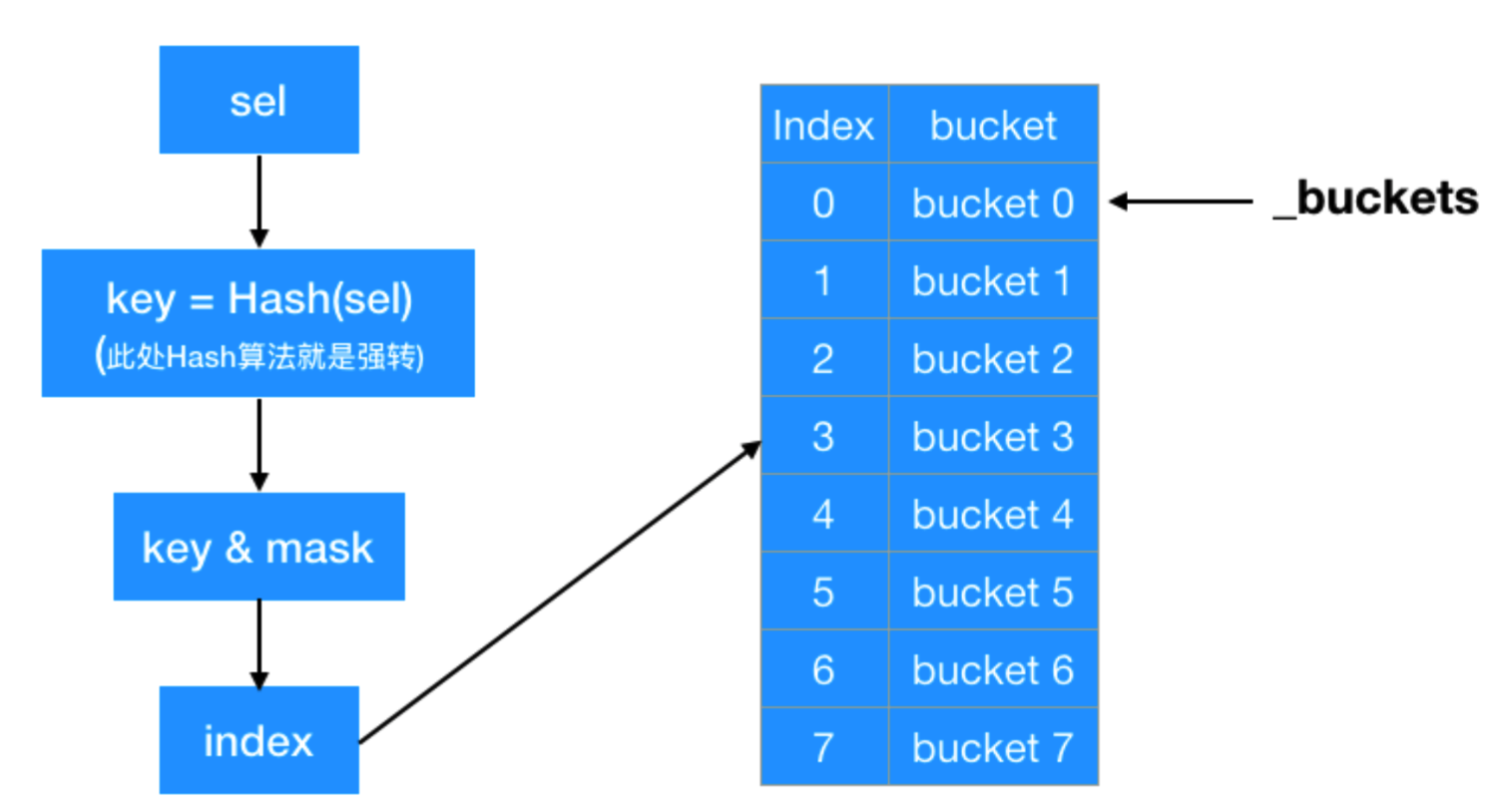
四:总结
整篇文章的思路都是基于探索的一个过程,站在一个探索的角度,而非上帝视角,一上来就知道整个流程。
mask()capacity()expand()cache_fill_nolockreallocatefind
下面我用一张思维导图来总结下缓存的正确流程,相信结合探索的过程,我们将理解的更加深刻
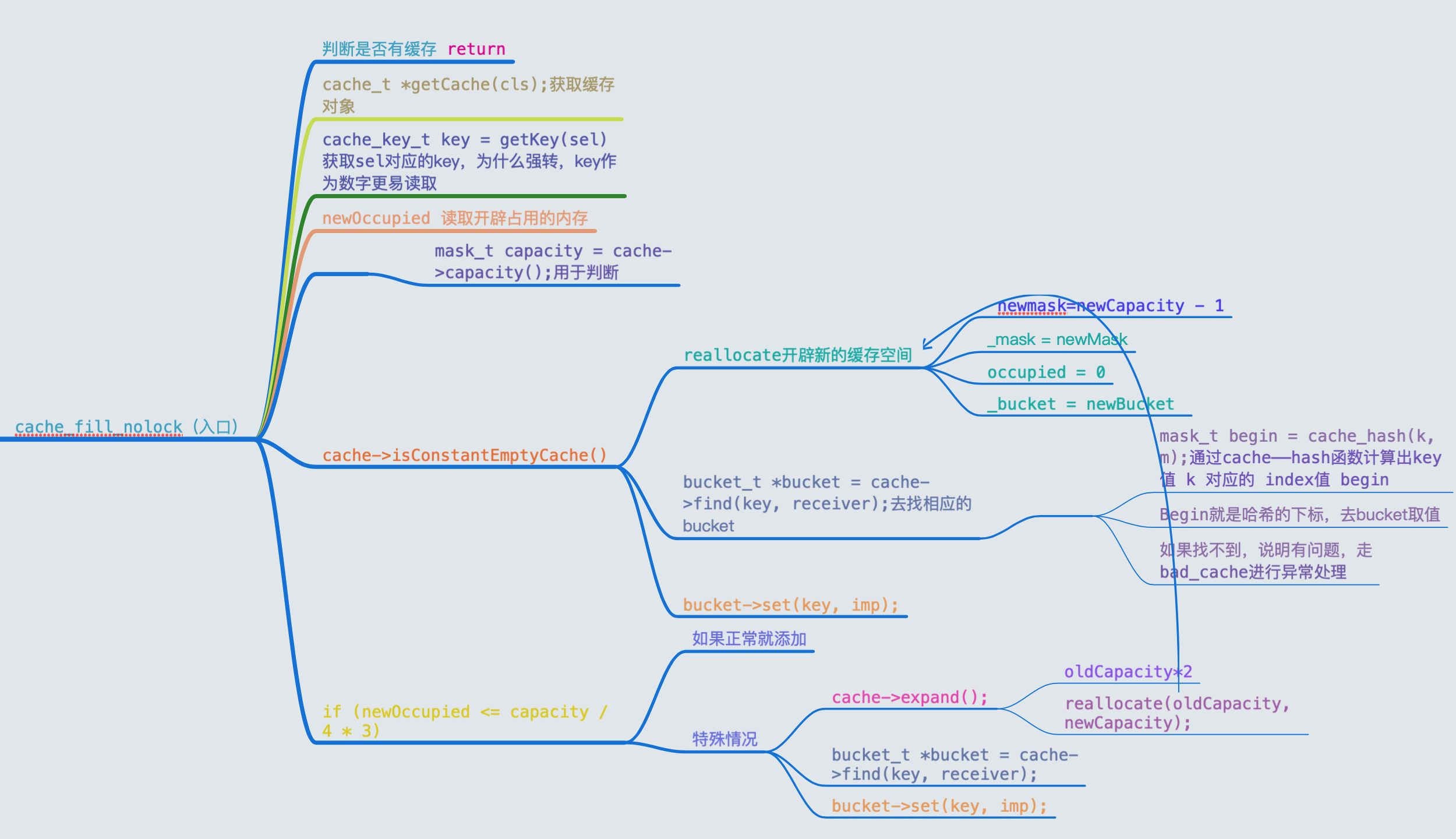
不积跬步无以至千里,不积小流无以成江海
