

本文主要介绍一下,什么是前端缓存,前端缓存能做什么以及一些使用方法。
提到前端缓存,那么一定会联想到后端缓存。那么这两个有什么区别那?
基本的网络请求就三个步骤:请求、处理、相应。后端缓存主要是集中在“处理”这一步骤中的,例如保留数据库连接、存储处理结果等缩短处理时间,使请求晶块进入“响应”步骤。而前端缓存则一般在剩下的两步,即“请求”和“响应”中进行,具体的做法,后面会详细讲到。
前端缓存主要有两种:HTTP缓存和浏览器缓存。
HTTP缓存是在HTTP请求传输时用到的缓存,主要在服务器以及相应的代码上做设置,做处理。浏览器缓存则主要由前端开发在前端js上进行设置。想要做好前端缓存,就要了解服务器相关知识以及前端和浏览器知识。
前端主要的缓存,如下图:
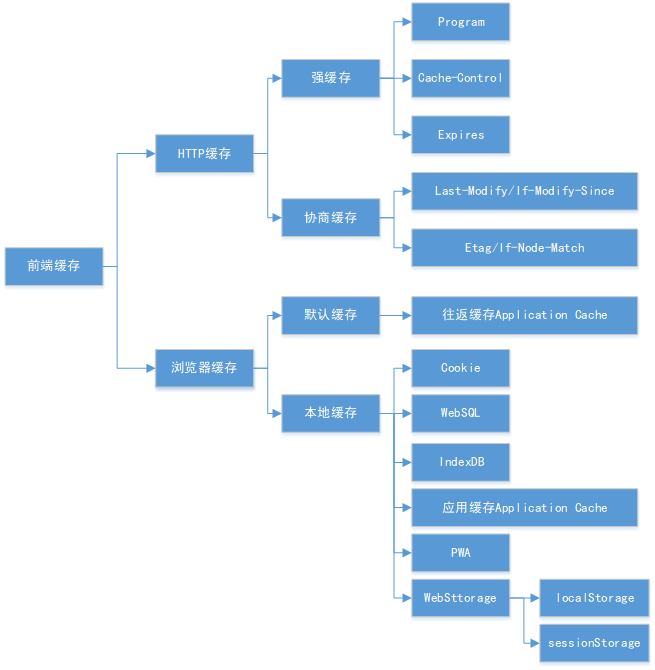
HTTP缓存
浏览器和服务器之间的通信是应答式的,即浏览器发起HTTP请求-服务器响应请求,之间又涉及到DNS查询、CDN请求、TCP三次握手四次挥手等。
1.强缓存
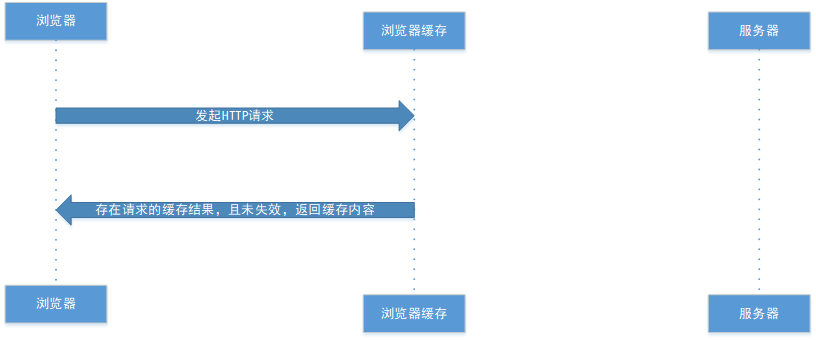
强制缓存就是向浏览器缓存查找该请求结果,并根据该结果的缓存规则来决定是否使用该缓存结果的过程。强缓存分为三种情况:不存在缓存、存在缓存但缓存失效、存在缓存且缓存未失效。
① 不存在该缓存结果和缓存标识,强制缓存失效,则直接向服务器发起请求(一般是第一次发起请求时)
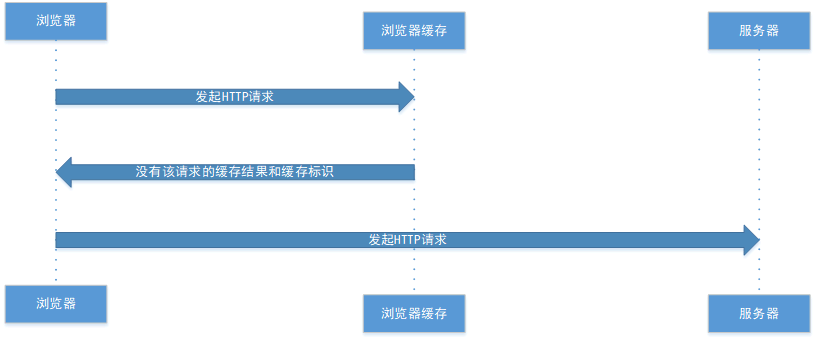
那么是如何判断缓存是否存在,缓存是生效还是失效的那?强缓存有着一套缓存规则,放在HTTP头里。控制强缓存的字段分别为:Expires和Cache-Control,Cache-Control的优先级比Expires高,也就是同时设置了这两个,则Cache-Control会生效。
① Expires
Expires是HTTP/1.0控制网页缓存的字段,其值为服务器返回该请求结果缓存的到期时间,即再次发起该请求时,如果客户端的时间小于Expires的值时,直接使用缓存结果。到了HTTP/1.1,Expires已经被Cache-Control替代,原因在于Expires控制缓存的原理是使用客户端的时间与服务端返回的时间做对比,那么如果客户端与服务端的时间因为某些原因(例如时区不同;客户端和服务端有一方的时间不准确)发生误差,那么强制缓存则会直接失效,这样的话强制缓存的存在则毫无意义。
② Cache-Control
在HTTP/1.1中,Cache-Control是最重要的规则,主要用于控制网页缓存。
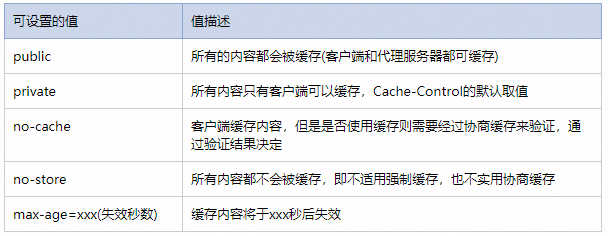
Cache-Control可设置的值有5个:
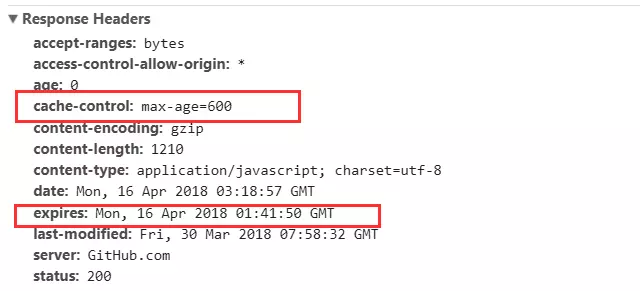
- HTTP响应报文中expires的时间值,是一个时间点
- HTTP响应报文中Cache-Control为max-age=600,是一个数值
- Cache-Control优先级高,则它会生效,而expires会不生效
- 在600秒内再次请求,直接取缓存结果
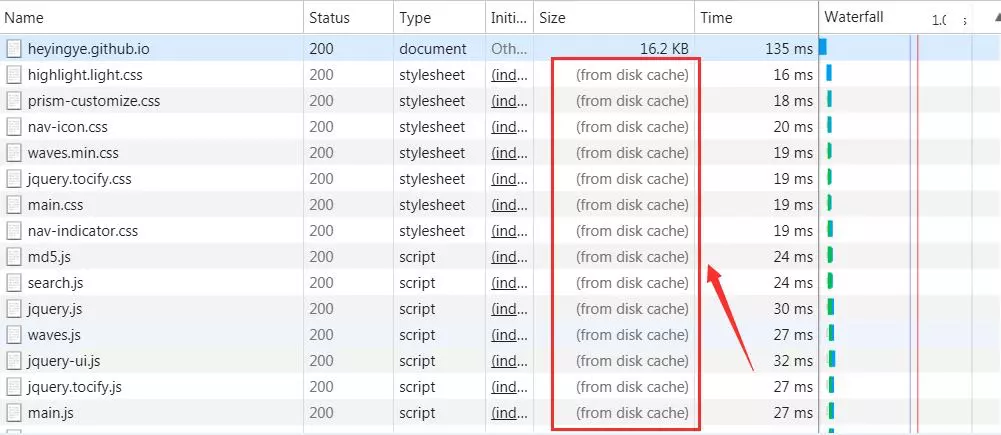
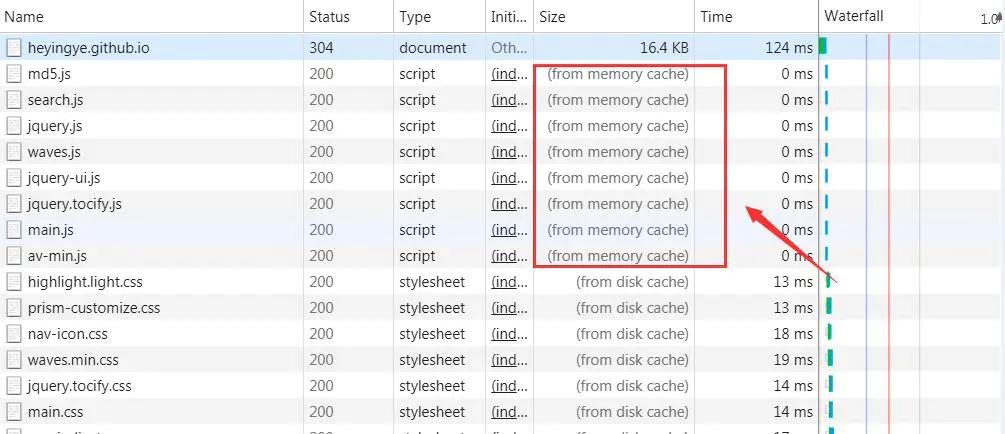
浏览器的缓存存放在哪里,如何在浏览器中判断强制缓存是否生效?下图是一个HTTP请求的一个列表,观察其中的结果。
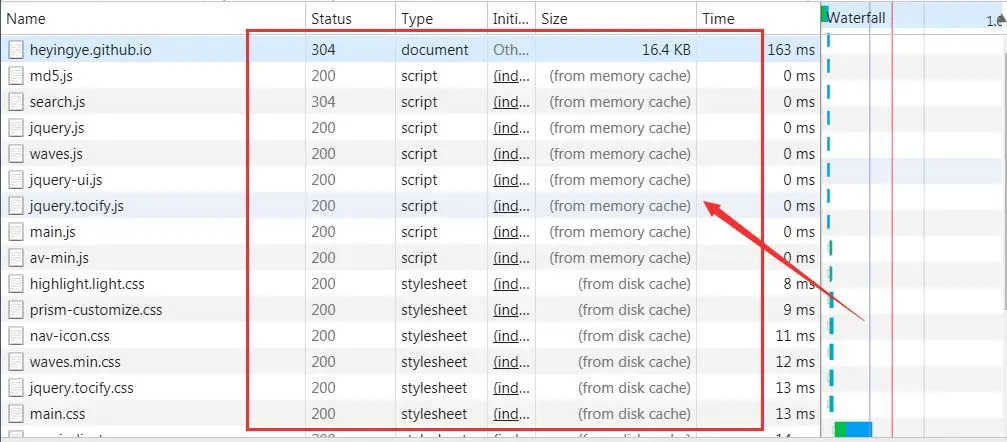
那么from memory cache 和 from disk cache又分别代表的是什么呢?什么时候会使用from disk cache,什么时候会使用from memory cache呢?
from memory cache代表使用内存中的缓存,from disk cache则代表使用的是硬盘中的缓存,浏览器读取缓存的顺序为memory –> disk –> 服务器请求。
接下来详细分析一下缓存的读取问题:
首次访问:
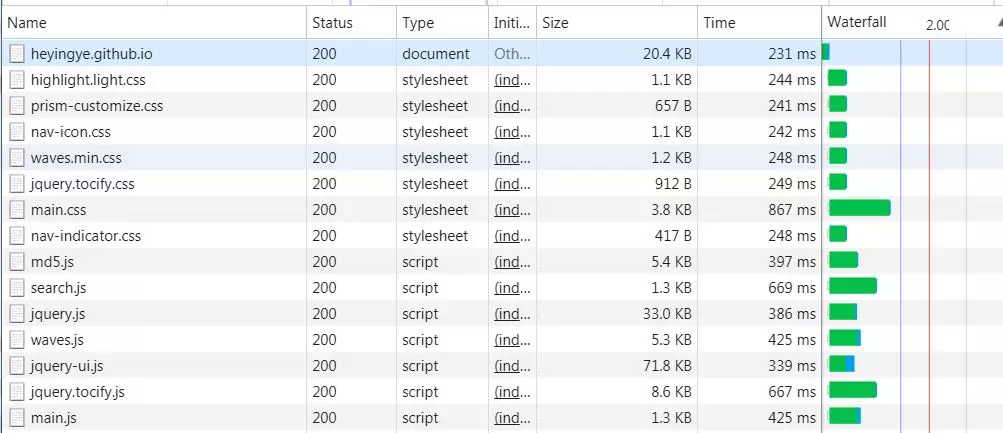
- 内存缓存(from memory cache):读取速度快、有时间限制
- 硬盘缓存(from disk cache):硬盘缓存则是直接将缓存写入硬盘文件中,读取缓存需要对该缓存存放的硬盘文件进行I/O操作,然后重新解析该缓存内容,读取复杂,速度比内存缓存慢
- 页面关闭则内存缓存会失效,硬盘缓存不会
- 浏览器会把JS和图片等文件解析后直接放到内存中,刷新页面直接从内存中读取;而CSS文件则会存入硬盘中,所以每次渲染页面都要从硬盘中读取缓存。
- 页面关闭时会把内存中的缓存存在硬盘缓存中,再次打开页面则都从硬盘缓存中读取数据
2.协商缓存
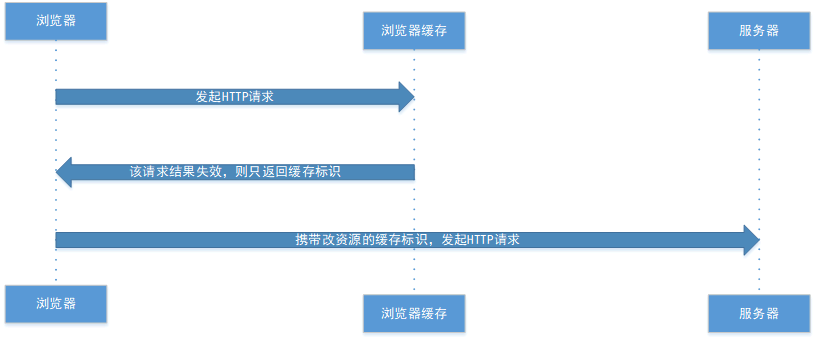
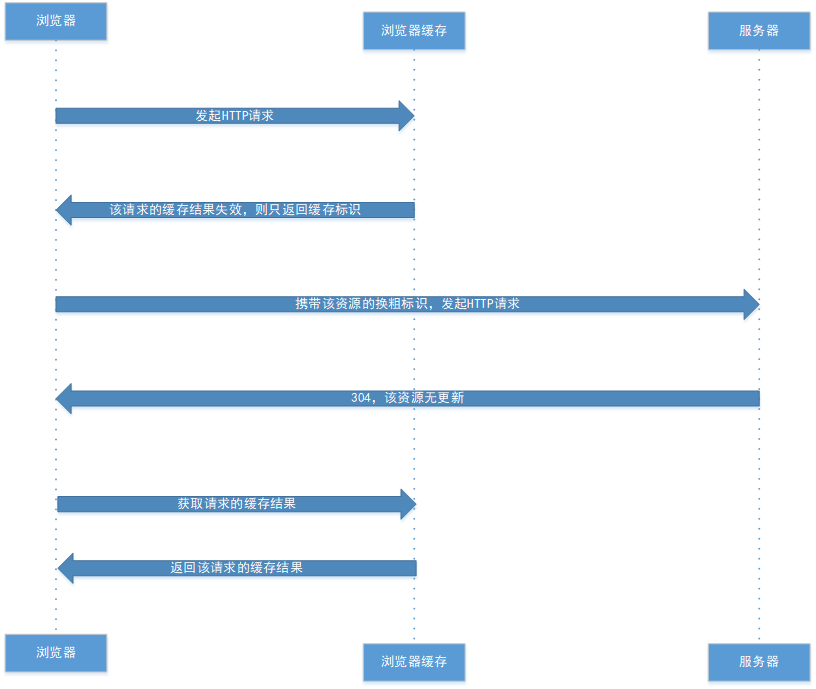
协商缓存就是强制缓存失效后,浏览器携带缓存标识向服务器发起请求,由服务器根据缓存标识决定是否使用缓存的过程,主要有两种情况:协商缓存生效、协商缓存失效。
① 协商缓存生效,返回304
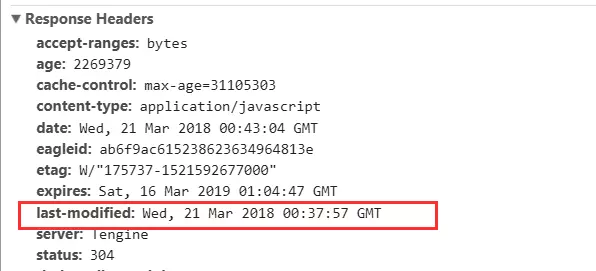
① Last-Modified / If-Modified-Since
Last-Modified是服务器响应请求时,返回该资源文件在服务器最后被修改的时间
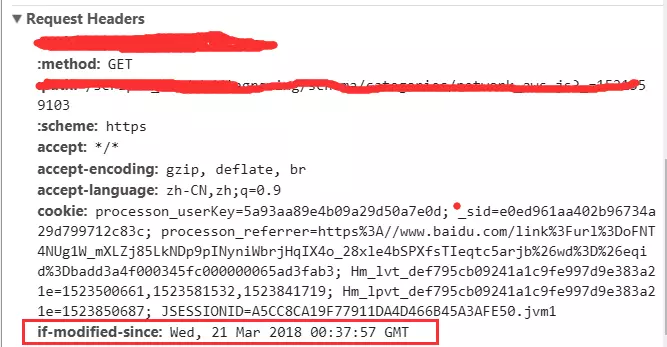
Etag是服务器响应请求时,返回当前资源文件的一个唯一标识(由服务器生成)
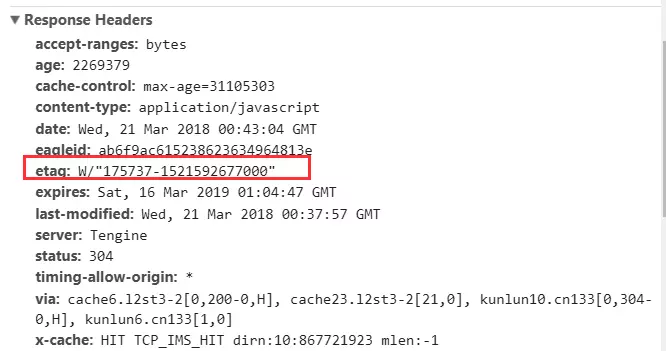
ETag的时间更精确
总结:
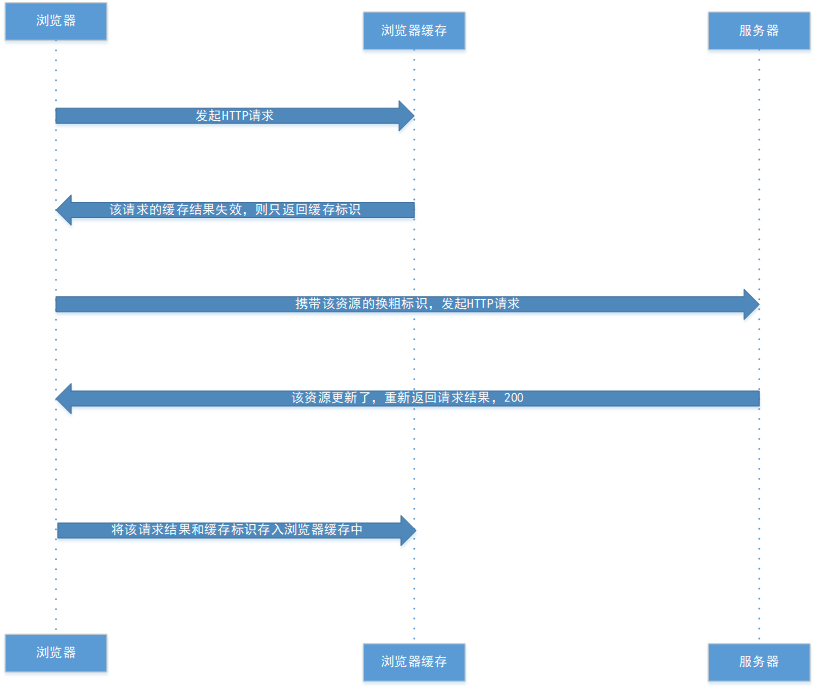
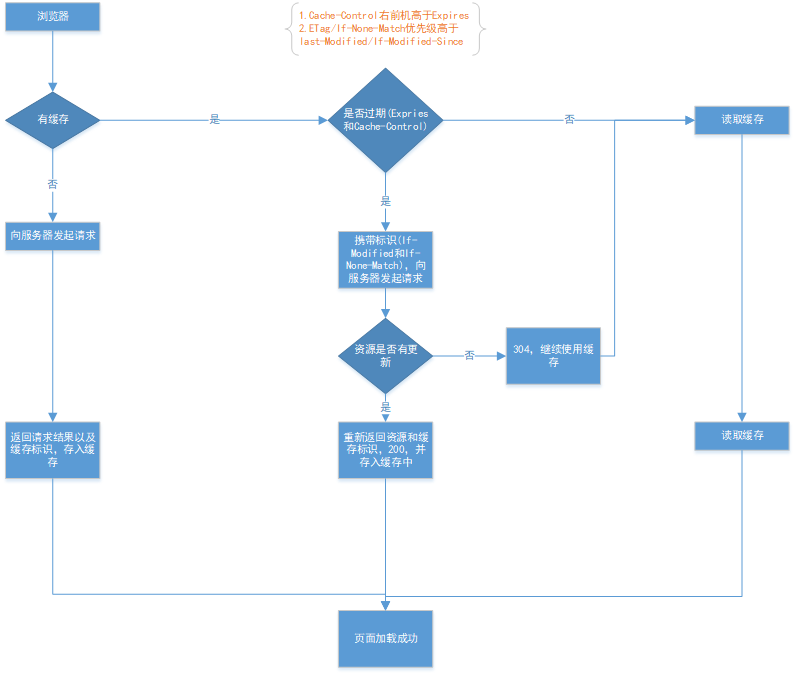
强制缓存优先于协商缓存进行,若强制缓存(Expires和Cache-Control)生效则直接使用缓存,若不生效则进行协商缓存(Last-Modified / If-Modified-Since和Etag / If-None-Match),协商缓存由服务器决定是否使用缓存,若协商缓存失效,那么代表该请求的缓存失效,重新获取请求结果,再存入浏览器缓存中;生效则返回304,继续使用缓存,主要过程如下:
3.CDN缓存
对于一些用户访问量巨大的网站而言,如果所有用户都去服务器请求数据,服务器会很快崩溃,并且在不同网络以及不同地区的用户,请求服务器的速度也不一样。为了提高这部分用户的访问速度,CDN 中又提出了新的网络架构,即创建一些最接近用户网络的边缘服务器,然后将文件缓存在这些边缘服务器(节点)上,这就是 CDN 缓存。
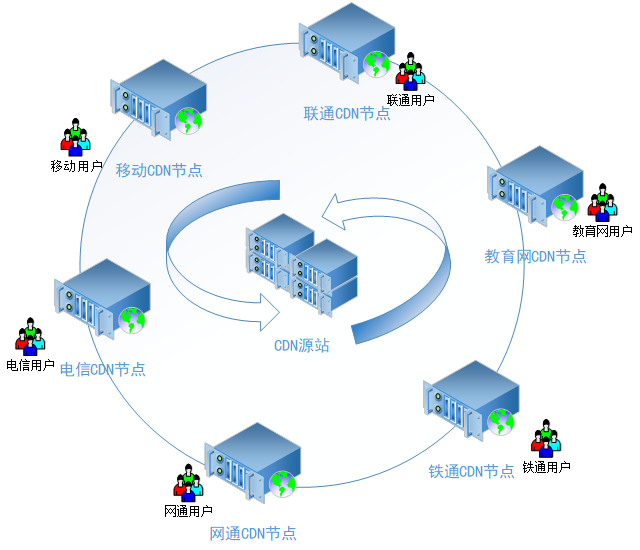
CDN缓存弊端
CDN 缓存不仅减少了用户的访问延时,相应的也减少了源服务器的负载,但这里需要注意,当源服务器资源更新后,如果 CDN 节点上缓存数据还未过期,用户访问到的依旧是过期的缓存资源,这会导致用户最终访问出现偏差。因此,开发者需要手动刷新相关资源,使 CDN 缓存保持为最新的状态。
CDN缓存刷新
CDN边缘节点对开发者是透明的,相比于浏览器Ctrl+F5的强制刷新来使浏览器本地缓存失效,开发者可以通过CDN服务商提供的“刷新缓存”接口来达到清理CDN边缘节点缓存的目的。这样开发者在更新数据后,可以使用“刷新缓存”功能来强制CDN节点上的数据缓存过期,保证客户端在访问时,拉取到最新的数据。
4.DNS缓存
DNS(Domain Name System): 负责将域名URL转化为服务器主机IP。 DNS查找流程:首先查看浏览器缓存是否存在,不存在则访问本机DNS缓存,再不存在则访问本地DNS服务器。所以DNS也是开销,通常浏览器查找一个给定URL的IP地址要花费20-120ms,在DNS查找完成前,浏览器不能从host那里下载任何东西。 TTL(Time To Live):表示查找返回的DNS记录包含的一个存活时间,过期则这个DNS记录将被抛弃。浏览器DNS缓存也有自己的过期时间,这个时间是独立于本机DNS缓存的,相对也比较短,例如chrome只有1分钟左右。
DNS缓存使用
当客户端的DNS缓存为空时,DNS查找的数量与Web页面中唯一主机名的数量相等。所以减少唯一主机名的数量就可以减少DNS查找的数量。但是问题来了,有时候需要多设置主机数量,来增加DNS的负载均衡,因此减少DNS查找和增加主机数量形成了矛盾关系,一般情况下DNS设置2-4个主机名是最佳的。更多负载均衡可以用其他方式实现,例如用nginx做负载均衡。
浏览器缓存
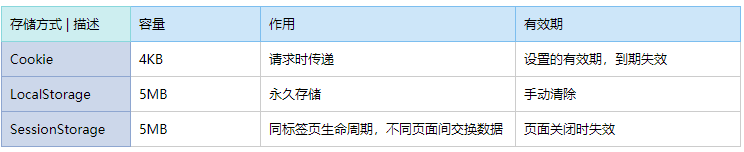
1.本地小容量存储
Cookie主要用于用户信息的存储,Cookie的内容可以自动在请求的时候被传递给服务器。LocalStorage的数据将一直保存在浏览器内,直到用户清除浏览器缓存数据为止。SessionStorage的其他属性同LocalStorage,只不过它的生命周期同标签页的生命周期,当标签页被关闭时,SessionStorage也会被清除。
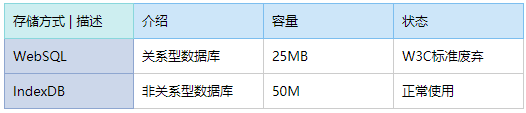
2.本地大容量存储
WebSql和IndexDB主要用在前端有大容量存储需求的页面上,例如,在线编辑浏览器或者网页邮箱。
3.往返缓存
往返缓存又称为BFCache,是浏览器在前进后退按钮上为了提升历史页面的渲染速度的一种策略。该策略具体表现为,当用户前往新页面时,将当前页面的浏览器DOM状态保存到bfcache中;当用户点击后退按钮的时候,将页面直接从bfcache中加载,节省了网络请求的时间。
4.PWA和Service Worker
PWA就是渐进式web应用(Progressive Web App),service worker是PWA的核心技术之一. Service workers 本质上充当Web应用程序与浏览器之间的代理服务器,也可以在网络可用时作为浏览器和网络间的代理。它们旨在(除其他之外)使得能够创建有效的离线体验,拦截网络请求并基于网络是否可用以及更新的资源是否驻留在服务器上来采取适当的动作。他们还允许访问推送通知和后台同步API。出于安全考量,Service workers只能由HTTPS承载。service worker文档(developer.mozilla.org/zh-CN/docs/…) 关于PWA等这里不足及过多的介绍,其原理和使用请直接看其文档(developer.mozilla.org/zh-CN/docs/…)
5.离线缓存
主要用到的知识是Manifest,Manifest文档(developer.mozilla.org/zh-CN/docs/…)
