

1、BloomFilter的概念
布隆过滤器(Bloom Filter)是1970年由一个叫布隆的小伙子提出的。实际上是一个很长的二进制向量和一系列随机映射函数。用于检索一个元素是否在一个集合中。优点:空间效率和查询时间远超一般算法。缺点:有一定误识别率和删除困难。
2、BloomFilter原理
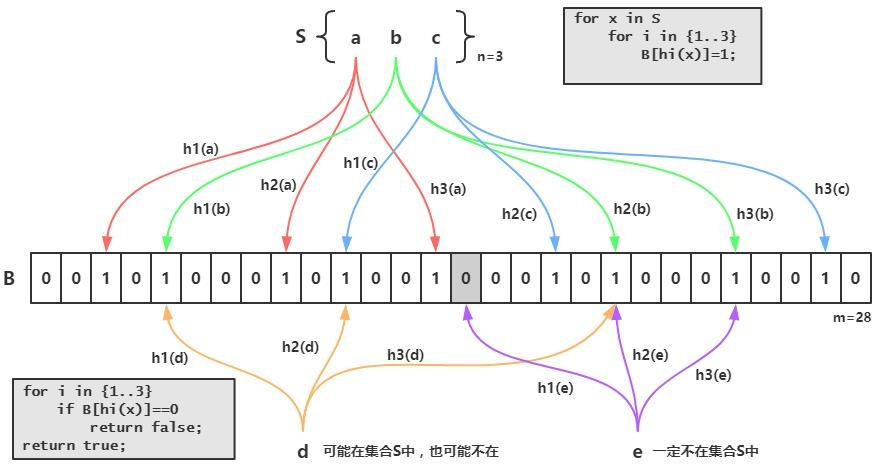
布隆过滤器的原理是,当一个元素被加入集合时,通过K个散列函数将这个元素映射成一个位数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。这就是布隆过滤器的基本思想。
Bloom Filter跟单哈希函数Bit-Map不同之处在于:Bloom Filter使用了k个哈希函数,每个字符串跟k个bit对应。从而降低了冲突的概率。
缓存穿透
每次查询都会直接打到DB
简而言之,言而简之就是我们先把我们数据库的数据都加载到我们的过滤器中,比如数据库的id现在有:1、2、3
那就用id:1 为例子他在上图中经过三次hash之后,把三次原本值0的地方改为1
下次数据进来查询的时候如果id的值是1,那么我就把1拿去三次hash 发现三次hash的值,跟上面的三个位置完全一样,那就能证明过滤器中有1的
反之如果不一样就说明不存在了
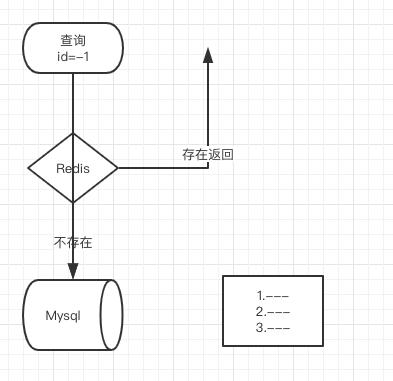
那应用的场景在哪里呢?一般我们都会用来防止缓存击穿
简单来说就是你数据库的id都是1开始然后自增的,那我知道你接口是通过id查询的,我就拿负数去查询,这个时候,会发现缓存里面没这个数据,我又去数据库查也没有,一个请求这样,100个,1000个,10000个呢?你的DB基本上就扛不住了,如果在缓存里面加上这个,是不是就不存在了,你判断没这个数据就不去查了,直接return一个数据为空不就好了嘛。
只转载了一部分,便于自己记录
原文链接:https://juejin.cn/post/6844903982209449991
