

最近在研究图片缓存技术Lurcache。Lurcache是Android封装好了的用于缓存的类,内部维护了一个双向链表LinkedHashMap。当我们想缓存某个图片的时候,它会先判断是否超过了存储容量,如果超过就会删除最老的元素,直到可以把新的元素放进来。而我们每次读取的时候,他会把这个元素放到队尾,这样最老的元素就被放在队首。这么神奇的操作都归功于内部LinkedHashmap以及HashMap的机制,我们今天就来一探究竟。
1.HashMap
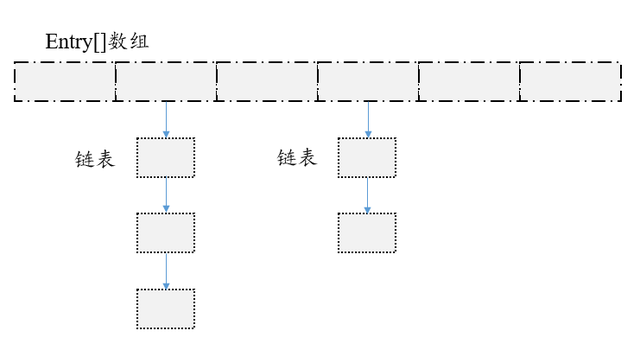
结构
它内部有一个数组,数组中的每个元素又是一个entry(K,V)链表。
put方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
实际是调用了putVal
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
这个方法的逻辑就是先根据key的hash值找到索引,判断是否存在,如果不存在就添加这个元素。如果存在,接着判断key的值是否相等。如果相等,则证明是同一个key,那么就把原来的value覆盖掉。如果不相等,就把他添加到这个下标处的链表的末尾。
特别要强调的是 afterNodeInsertion(evict);这个抽象方法,linkedhashmap里会用到!
get方法就不贴了,和put的思路大致相同,先找下标,再不断循环找到key值相等所对应的value。
2.LinkedHashMap
结构
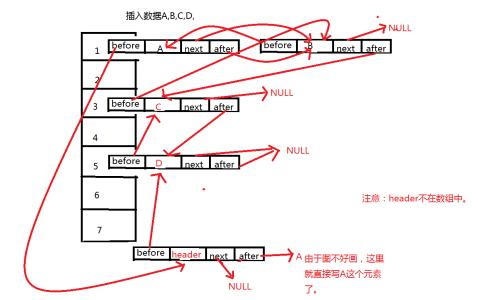
LinkedHashMap 是一个双向链表,继承了hashmap,同时entry添加了before,after两个指针,来实现访问顺序的排序。
put方法
LinkedHashMap没有重写put方法,但是重写了afterNodeInsertion(evict)这个方法。我们来看下
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMapEntry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
这里面有个判断,evict是自己传的,first=head是根据上下文判断的,而removeEldestEntry()默认返回false。如果我们重写了这个方法,就可以添加我们自定义的条件判断是否需要摘除最老的元素,如源码示例
* 源码
* private static final int MAX_ENTRIES = 100;
*
* protected boolean removeEldestEntry(Map.Entry eldest) {
* return size() > MAX_ENTRIES;
* }
*
如果这三个条件都是true,那么就会执行删除最老的元素。
get方法
里面用到了hashmap的getNode,注意下面有个if判断。如果accessOrder为true,就会执行afterNodeAccess方法。
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
我们看下这个方法
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMapEntry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMapEntry<K,V> p =
(LinkedHashMapEntry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
它会在get的同时,把这个entry元素放到链表尾部。这样最老的元素就会处在链表头部。因此,是否执行这一方法就看accessorder的值,Linkedhashmap构造函数默认的是false,并不会执行每次查询都重新排序。
Lurcahe
lurcha里面封装了一个Linkedhashmap,看下构造函数
public LruCache(int maxSize) {
if (maxSize <= 0) {
throw new IllegalArgumentException("maxSize <= 0");
}
this.maxSize = maxSize;
this.map = new LinkedHashMap<K, V>(0, 0.75f, true);
}
这里面最后一个参数true正是accessorder,所以这个linkedhashmap具有上述功能,即:每次调用get,就会把当前元素放在链表尾部,使得最不常用的被排在头部。当我们调用put时,如果我们重写了自己的判断逻辑,就会判断是否超出限定,超出的话会把最不常用的元素移除这个链表。
