publicstaticvoidtestArrayHandler()throws SQLException {
//参数是一个数据源,有参的是自动提交事务
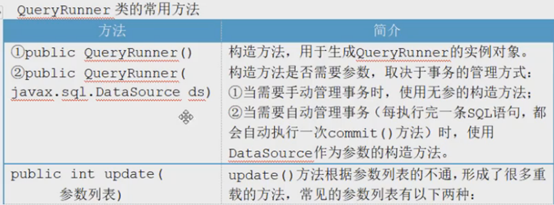
QueryRunner runner = new QueryRunner(getDataSoure());
//第一个参数是sql语句,第二参数是结果集,第三个参数是sql语句的?的值
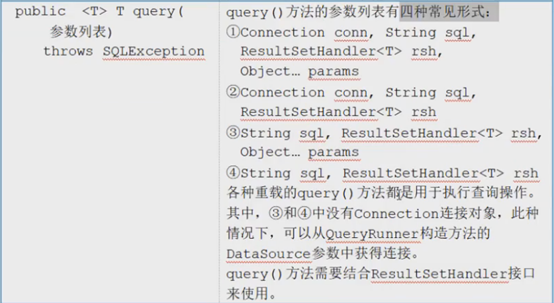
Object[] user = runner.query("select * from t_user where id > ?", new ArrayHandler(), 1);
System.out.println(user[0]+","+user[1]);
}
publicstaticvoidtestArrayListHandler()throws SQLException {
QueryRunner runner = new QueryRunner(getDataSoure());
//第一个参数是sql语句,第二参数是结果集,第三个参数是sql语句的?的值
List<Object[]> users = runner.query("select * from t_user where id>?", new ArrayListHandler(), 1);
for (Object[] user : users) {
System.out.println(user[0]+","+user[1]);
}
}
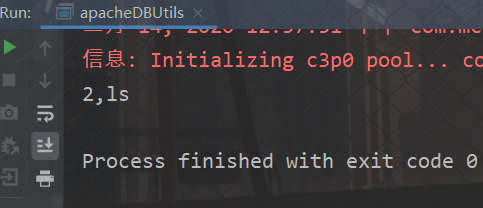
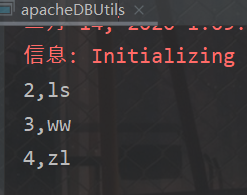
运行结果
这二个的区别在于:一个只能返回一条数据,另外一个可以返回全部数据
实现类BeanHandler : 返回结果集中的第一行数据,并用对象(User)接收
publicstaticvoidtestBeanHandler()throws SQLException {
QueryRunner runner = new QueryRunner(getDataSoure());
//第一个参数是sql语句,第二参数是结果集,第三个参数是sql语句的?的值
User user = runner.query("select * from t_user where id>?", new BeanHandler<User>(User.class), 1);
System.out.println(user.getId()+","+user.getName());
}
publicstaticvoidtestBeanListHandler()throws SQLException {
QueryRunner runner = new QueryRunner(getDataSoure());
//第一个参数是sql语句,第二参数是结果集,第三个参数是sql语句的?的值
List<User> users = runner.query("select * from t_user where id > ? ", new BeanListHandler<User>(User.class), 1);
for (User user : users) {
System.out.println(user.getId()+","+user.getName());
}
}