

项目介绍: 分析携程用户用户行为数据来挖掘潜在价值,通过数据来深入了解用户画像及行为偏好,找到最优算法,挖掘出影响用户流失的关键因素,在精确度97%以上的前提下求出最大召回率
机器学习的流程: 1:分析题目与数据集 2:根据题意选择一个合适的算法:根据题意和数据集可以明显知道这个是一个分类问题,使用有监督学习方法,在这里使用xgbooost 3:选择最合适的评估模型:精确率 召回率 F1 F2score AUC/ROC 4:了解业务和数据,开始建模: 数据分析以及预处理 特征处理: 调节参数: 评价模型的好坏: 模型的融合
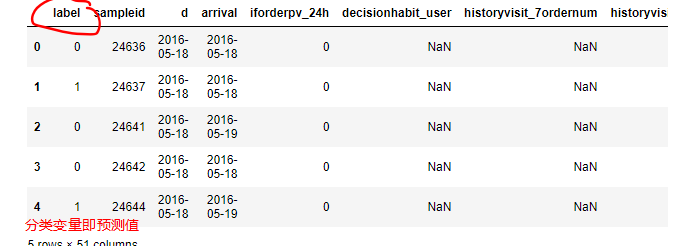
分析数据集:这里有两个数据集,一个是train.txt一个是test.txt,两个数据集的区别是test.txt没有Label变量,那么对于模型数据集的拆分方法是,把训练集分成两份对模型进行训练以及评估,再用最好的模型进行预测test.txt的数据下面的数据集的与数据集各个特征的分类



画图计算数据缺失率后排序
#计算数据缺失率后排序
non_rate = (len(data) - data.count())/len(data)
tmp = non_rate.sort_values(ascending = False)
tmp = pd.DataFrame(tmp)
fig = plt.figure(figsize=(8,12))#图形大小
plt.barh(tmp.index,tmp[0], color= 'red', alpha = 1)
# 添加轴标签
plt.xlabel('data_na_rate')
#设置X轴的刻度范围
plt.xlim([0, 1])
for i in range(0,50):
plt.hist(data[data.columns[i]].dropna().get_values(),bins = 50, edgecolor = 'k')
plt.xlabel(data.columns[i])
plt.show()
def fill_values(data):
for col in fillNauWith999:
data[col] = data[col].fillna(-999)
for col in fillNauWithMean:
data[col] = data[col].fillna(data[col].mean())
for col in fillfeatureswith0:
data[col] = data[col].fillna(0)
for col in specialdata:
data[col]=data[col].map(lambda x:1 if x>40 else 0)
return data
特征工程:特征工程有以下三点
特征提取:从文字图像声音等其他非结构化数据中提取新信息作为特征,比如在淘宝宝贝 中提取产品类别等
特征创造:把现有的特征进行组合或者相互计算得到新的特征
特征选择:在所有特征 中选择对模型有帮助的特征,避免所有特征都拿去训练的情况
对数据进行特征提取:分析数据的所有特征,可以知道simpleid这特征对于模型来说没有作用,但是在这里要注意,因为数据集给的id并不是用户的id,而是单纯记录每个用户的行为,比如对一个用户浏览了A B C D四家酒店都会留下四条记录。所以这时候不能直接删除simpleid,所以我们暂时不做处理,在后面再删除。
特征创造:在根据上面的分析中可以知道我们需要对用户进行聚类,我们可以根据用户的行为对用户进行聚类。
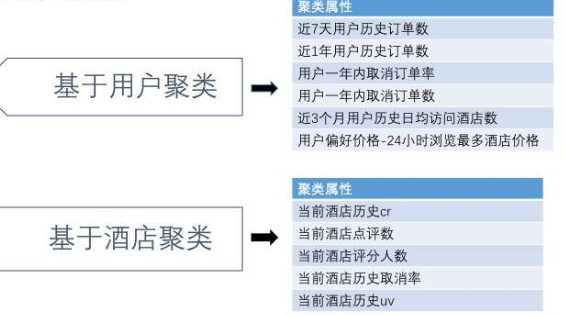
def deal_with_Kmeans(data):
user_group = data[['historyvisit_7ordernum','historyvisit_totalordernum','ordercanceledprecent','historyvisit_visit_detailpagenum','historyvisit_avghotelnum','lowestprice_pre']]
hotel_group = data[['commentnums','novoters','cancelrate','hoteluv','hotelcr','lowestprice']]
#转成二维数组
for i in range(len(user_group.columns)):
user_group[user_group.columns[i]] = MMS.fit_transform(user_group[user_group.columns[i]].values.reshape(-1,1))
for i in range(len(hotel_group.columns)):
hotel_group[hotel_group.columns[i]] = MMS.fit_transform(hotel_group[hotel_group.columns[i]].values.reshape(-1,1))
#聚类
data['user_type'] = KMeans(n_clusters=5,init='k-means++',random_state=SEED).fit_predict(user_group)
data['hotel_type'] = KMeans(n_clusters=5,init='k-means++',random_state=SEED).fit_predict(hotel_group)
#根据酒店和用户的信息,给用户分配id
return data
def createUsrTag(dataProcessed):
dataProcessed['usertag']= dataProcessed['ordercanncelednum'].map(str) + dataProcessed['historyvisit_avghotelnum'].map(str) + dataProcessed['ordernum_oneyear'].map(str)+dataProcessed['customer_value_profit'].map(str) + dataProcessed['ctrip_profits'].map(str) + dataProcessed['cr'].map(str) + dataProcessed['visitnum_oneyear'].map(str)
dataProcessed['usertag'] = dataProcessed['usertag'].map(lambda x:hash(x))
return dataProcessed
最后还有一类特征是根据现有特征衍生出来的一些特征,比如访问日期和实际入住日期之间的差值,还有访问日期和入住日期是不是周末等特征。在机器学习中,是否为周末这个特征往往是非常重要的。
def is_weekend(ser):
if int(ser) in [0,1,2,3,4] :
return 0 #工作日
else:
return 1 #非工作日
def deal_time_and_ceate(data):
data['d']=pd.to_datetime(data['d'],format='%Y-%m-%d')
data['arrival']=pd.to_datetime(data['arrival'],format='%Y-%m-%d')
data['weekday'] = data['arrival'].map(lambda x:x.weekday())#转为星期几
data['book_arr_gap'] = (data['arrival']-data['d']).map(lambda x:x.days).astype(int)#计算入职时间差
data['is_weekend'] = data['weekday'].apply(is_weekend)
return data
在创造完特征后对所有数据进行查看,用箱型图来观察数据的分布情况,在这里主要使考虑到了用户的消费水平,根据二八原则可以知道,大多数人的消费水平还是处于中等或者中等偏下的,所以我们观察箱型图的三个分位来对一些特征进行连续特征离散化。
for i in range(len(data.columns)):
sns.boxplot(x=data.columns[i], y=data[data.columns[i]], data=data,
linewidth = 2, # 线宽
width = 0.8, # 箱之间的间隔比例
fliersize = 3, # 异常点大小
palette = 'hls', # 设置调色板
)
特征选择:可以去除方差为0的特征还可以根据特征与流失标签的相关性进行筛选。
观察结果可以知道starprefer(星级偏好),consuming_capacity(消费能力),avgprice(平均价格)的数据计较集中,我们把这三个特征离散化,然后再数据的所有离散特征进行热编码
def deal_starprefer(x):
if x==-999:
return 0
elif x<50:
return 1
elif x<80:
return 2
else:
return 3
def deal_avgprice(x):
if x==-999:
return 0
elif x< 300:
return 1
elif x<1000:
return 2
else:
return 3
def deal_consuming_capacity(x):
if x==-999:
return 0
elif x< 50:
return 1
else:
return 2
def deal_scr_fea(data):
#根据箱型图来处理集中的连续变量使其离散化
data['starprefer'] = data['starprefer'].map(lambda x :str(deal_starprefer(int(x))))
data['consuming_capacity'] = data['consuming_capacity'].map(lambda x: str(deal_consuming_capacity(int(x))))
data['avgprice'] = data['avgprice'].map(lambda x: str(deal_avgprice(int(x))))
data[['decisionhabit_user',"user_type","hotel_type"]]=data[['decisionhabit_user',"user_type","hotel_type"]].applymap(str)
ohr = OneHotEncoder(handle_unknown='ignore')
result = ohr.fit_transform(data[['starprefer','consuming_capacity','avgprice','decisionhabit_user',"user_type","hotel_type"]]).toarray()
result = pd.DataFrame(result)
data = pd.concat([data,result],axis=1)
data.drop(['starprefer','consuming_capacity','avgprice','decisionhabit_user',"user_type","hotel_type",'d','arrival','sampleid','firstorder_bu'],axis=1,inplace=True)
return data
之后进行数据集划分,之前说过把训练集的数据拆分训练后评估模型,再来用模型来预测训练集。在这里我们处理完所有数据后要对模型进行调参,可以用gridsearch()函数进行 交叉验证,取出最好的参数后对模型进行预测。在这里我要强调一下,因为考虑电脑性能一般所以我的树的数量只弄了五十,在最终评估最适合的参数n_estimators=1000的,在所有的结果中最后找出最高的参数即可。
def adjust_param():
#树的深度跟叶子节点
param_test1 = {
'max_depth':range(3,10,2),
'min_child_weight':range(1,6,2)
}
#学习率
param_test2 = {
'learning_rate':[0.0001,0.001,0.01,0.1,0.2,0.3]
}
#colsample_tree每棵树随机采样的比例
#susample样本随采样的比例
param_test3 = {
'subsample':[i/10.0 for i in range(6,11)],
'colsample_bytree':[i/10.0 for i in range(5,11)]
}
#步长
param_test4 = {
'gamma':[i/10.0 for i in range(0,5)]
}
model = XGBClassifier()
grid_seach1 = GridSearchCV(estimator=XGBClassifier(learning_rate=0.1,n_estimators=50,max_depth=9,min_child_weight=5,gamma=0.2,
subsample = 1.0,colsample_bytree=0.5,objective= 'binary:logistic', nthread=1,
scale_pos_weight=1, seed=27),param_grid = param_test4,scoring='roc_auc',
n_jobs=1,iid=False, cv=5)
grid_seach1.fit(trainx,trainy)
means = grid_seach1.cv_results_['mean_test_score']
params = grid_seach1.cv_results_['params']
print('best:%f using %s,model%s'%(grid_seach1.best_score_,grid_seach1.best_params_,grid_seach1.best_estimator_))
for mean,param in zip(means,params):
print('%f,with: %r'%(mean,param))
#最终参数
def best_model():
model =XGBClassifier(learning_rate=0.1,n_estimators=50,max_depth=6,min_child_weight=5,gamma=0.2,
subsample = 0.8,colsample_bytree=0.8,objective= 'binary:logistic', nthread=1,
scale_pos_weight=1, seed=27)#训练好的参数
model.fit(trainx,trainy)
lst = model.feature_importances_
print('finished')
return lst,model
def get_result():
thresholds,model = best_model()
test_predict = model.predict_proba(testx)[:,0]
pred_prob = model.predict_proba(processeddata3)[:,0]
auc = roc_auc_score(testy,test_predict)
precision,recall,thresholds = precision_recall_curve(testy,test_predict)
print(precision,recall,thresholds)
pr = pd.DataFrame({'precision':precision,'recall':recall})
prc = pr[pr.precision>=0.97].recall.max()
print(prc)
return pred_prob,pr,prc
模型融合:模型融合其实优缺点都非常明显 模型融合可以对的各种各类的分分类器,第一阶段得出各自的成果第二阶段用前一阶段训练结果。能有效防止模型过拟合,提高模型的准确度。但是缺点是效率大大降低。在这里简单介绍一下模型融合。因为模型融合的运行速度很慢,我的电脑带不起,所以在这里介绍一下模型融合的其他例子
第一步:写出所有模型,并且进行训练最后进行评分,然后取出模型的的平均预测值进行评估:
def get_models():
"""Generate a library of base learners."""
nb = GaussianNB()
svc = SVC(C=100, probability=True)
knn = KNeighborsClassifier(n_neighbors=3)
lr = LogisticRegression(C=100, random_state=SEED)
nn = MLPClassifier((80, 10), early_stopping=False, random_state=SEED)
gb = GradientBoostingClassifier(n_estimators=100, random_state=SEED)
rf = RandomForestClassifier(n_estimators=10, max_features=3, random_state=SEED)
models = {'svm': svc,
'knn': knn,
'naive bayes': nb,
'mlp-nn': nn,
'random forest': rf,
'gbm': gb,
'logistic': lr,
}
return models
def train_predict(model_list):
"""Fit models in list on training set and return preds"""
P = np.zeros((ytest.shape[0], len(model_list)))
P = pd.DataFrame(P)
print("Fitting models.")
cols = list()
for i, (name, m) in enumerate(models.items()): #返回给items添加索引
print("%s..." % name, end=" ", flush=False)
m.fit(xtrain, ytrain)
P.iloc[:, i] = m.predict_proba(xtest)[:, 1]
cols.append(name)
print("done")
P.columns = cols
print("Done.\n")
return P
def score_models(P, y):
"""Score model in prediction DF"""
print("Scoring models.")
for m in P.columns:
score = roc_auc_score(y, P.loc[:, m])
print("%-26s: %.3f" % (m, score))
print("Done.\n")
第二步:这时候有个问题,每个模型模型是否是高度相关,我们可以认为剔除一些评分比较低的模型,从而提高stacking 的准确度
#查看各个模型的相关度
from mlens.visualization import corrmat
corrmat(P.corr(), inflate=False)
plt.show()
在剔除评分较低的模型的时候我们不可能每次都手动剔除,我们可以用xgboost来帮我们,这就是模型的二次训练
首先实例化两个模型
base_learners = get_models()#基础模型
#二次模型
meta_learner = GradientBoostingClassifier(
n_estimators=1000,
loss="exponential",
max_features=4,
max_depth=3,
subsample=0.5,
learning_rate=0.005,
random_state=SEED
)
#数据集拆分
#这里数据集我们只用训练集拆分
xtrain_base, xpred_base, ytrain_base, ypred_base = train_test_split(
xtrain, ytrain, test_size=0.5, random_state=SEED)
之后把训练集再次拆分,分别用训练集的数据取训练新的模型,再用原来的数据集进行预测
#数据集拆分
#这里数据集我们只用训练集拆分
xtrain_base, xpred_base, ytrain_base, ypred_base = train_test_split(
xtrain, ytrain, test_size=0.5, random_state=SEED)
#用训练集的训练集训练数据
def train_base_learners(base_learners, inp, out, verbose=True):
"""Train all base learners in the library."""
if verbose: print("Fitting models.")
for i, (name, m) in enumerate(base_learners.items()):
if verbose: print("%s..." % name, end=" ", flush=False)
m.fit(inp, out)
if verbose: print("done")
train_base_learners(base_learners, xtrain_base, ytrain_base)
#用训练集的预测集来预测,然后返回所有模型的预测结果,Dataframe来装
def predict_base_learners(pred_base_learners, inp, verbose=True):
"""Generate a prediction matrix."""
P = np.zeros((inp.shape[0], len(pred_base_learners)))
if verbose: print("Generating base learner predictions.")
for i, (name, m) in enumerate(pred_base_learners.items()):
if verbose: print("%s..." % name, end=" ", flush=False)
p = m.predict_proba(inp)
# With two classes, need only predictions for one class
P[:, i] = p[:, 1]
if verbose: print("done")
return P
P_base = predict_base_learners(base_learners, xpred_base)
#用七个模型的预测结果来训练第二个模型
再用上面模型的预测结果作为训练集来给第二个模型进行训练
meta_learner.fit(P_base, ypred_base)
#用基础模型训练test数据,然后再用xgboost来预测
def ensemble_predict(base_learners, meta_learner, inp, verbose=True):
"""Generate predictions from the ensemble."""
P_pred = predict_base_learners(base_learners, inp, verbose=verbose)
return P_pred, meta_learner.predict_proba(P_pred)[:, 1]
P_pred, p = ensemble_predict(base_learners, meta_learner, xtest)
print("\nEnsemble ROC-AUC score: %.3f" % roc_auc_score(ytest, p)
这样做会让我们损失部分数据,训练集拆分的预测部分就可以说没有训练到了下面用超级模型来解决这个问题
from mlens.ensemble import SuperLearner
# Instantiate the ensemble with 10 folds
sl = SuperLearner(
folds=10,
random_state=SEED,
verbose=2,
backend="multiprocessing"
)
# Add the base learners and the meta learner
sl.add(list(base_learners.values()), proba=True)
sl.add_meta(meta_learner, proba=True)
# Train the ensemble
sl.fit(xtrain, ytrain)
# Predict the test set
p_sl = sl.predict_proba(xtest)
print("\nSuper Learner ROC-AUC score: %.3f" % roc_auc_score(ytest, p_sl[:, 1]))
总结stacking 就是把训练拆分,用训练集的训练集取训练一次模型,用训练集的预测集取预测然后返回一个所有模型的预测结果,再把预测结果和训练集的预测ytest训练第二个模型,最后用原本的预测集的xtest取预测结果 done!
