

Nginx是一款轻量级的Web 服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器,并在一个BSD-like 协议下发行。
Nginx 是一个高性能的 Web 和反向代理服务器, 它具有有很多非常优越的特性:
作为 Web 服务器:相比Apache,Nginx使用更少的资源,支持更多的并发连接,体现更高的效率,这点使 Nginx 尤其受到虚拟主机提供商的欢迎。能够支持高达 50,000 个并发连接数的响应。 Nginx 选择了 epoll and kqueue 作为开发模型。
作为负载均衡服务器:Nginx 既可以在内部直接支持 Rails 和 PHP,也可以支持作为 HTTP代理服务器 对外进行服务。Nginx 用 C 编写, 不论是系统资源开销还是 CPU 使用效率都比 Perlbal 要好的多。
作为邮件代理服务器: Nginx同时也是一个非常优秀的邮件代理服务器(最早开发这个产品的目的之一也是作为邮件代理服务器)。
Nginx一般用七层负载均衡,其吞吐量有一定的限制。为了提高整体的吞吐量,会在DNS和Nginx之间引入LVS(软件负载均衡器)、F5(硬负载均衡器) 可以做四层负载均衡,首先DNS解析到LVS(F5),让后LVS(F5)转发给Nginx,在有Nginx转发给真实的服务器
虚拟主机
1个虚拟主机相当于是一个网站,可以实现在一台服务器虚拟出多个网站
常见类型
基于域名的虚拟主机:不同的域名访问不同虚拟主机(网站)
基于端口:不同的端口访问不同的虚拟主机----网站需要特殊端口的时候使用
基于IP虚拟主机:不同的IP地址访问不同的虚拟主机,在负载均衡的时候也会使用
server{
listen 80;
server_name 192.168.8.18 cszhi.com;
index index.html index.htm index.php;
root /wwwroot/www.cszhi.com;
charset gb2312;
access_log logs/www.ixdba.net.access.log;
main ;
}
server标志定义虚拟主机开始,listen用于指定虚拟主机的服务端口,server_name用来指定IP地址或者域名,多个域名之间用空格分 开。index用于设定访问的默认首页地址,root指令用于指定虚拟主机的网页根目录,这个目录可以是相对路径,也可以是绝对路径。Charset用于 设置网页的默认编码格式。access_log用来指定此虚拟主机的访问日志存放路径,最后的main用于指定访问日志的输出格式。
反向代理
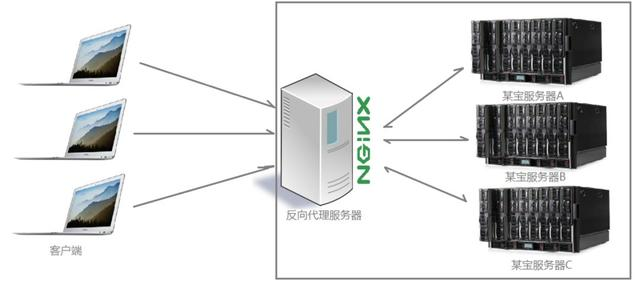
反向代理(Reverse Proxy)方式是指以代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端,此时代理服务器对外就表现为一个反向代理服务器。
作用: 隐藏真实服务器IP地址,保证内网的安全,通常将反向代理作为公网访问地址,Web 服务器是内网。负载均衡,通过反向代理服务器来优化网站的负载。
nginx.conf 配置
server {
listen 80;
server_name 8080.itmayiedu.com; ### 虚拟IP地址
location / {
proxy_pass http://127.0.0.1:8080; ### 真实服务器地址
index index.html index.htm;
}
}
负载均衡
负载均衡,建立在现有网络结构之上,它提供了一种廉价有效透明的方法扩展网络设备和服务器的带宽、增加吞吐量、加强网络数据处理能力、提高网络的灵活性和可用性。 负载均衡,英文名称为Load Balance,其意思就是分摊到多个操作单元上进行执行,例如Web服务器、FTP服务器、企业关键应用服务器和其它关键任务服务器等,从而共同完成工作任务。
负载均衡策略和配置
1、轮询(默认)
每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除。
upstream backserver { ### 配置负载均衡
server 192.168.0.14;
server 192.168.0.15;
}
server {
listen 80;
server_name 8080.itmayiedu.com; ### 虚拟IP地址
location / {
proxy_pass http://backserver; ### 负载均衡地址
index index.html index.htm;
}
}
2、指定权重
指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的情况。
upstream backserver {
server 192.168.0.14 weight=10;
server 192.168.0.15 weight=10;
}
3、IP绑定(ip_hash)
每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session共享的问题。
upstream backserver {
ip_hash;
server 192.168.0.14:88;
server 192.168.0.15:80;
}
4、fair(第三方)
按后端服务器的响应时间来分配请求,响应时间短的优先分配。
upstream backserver {
server server1;
server server2;
fair;
}
5、url_hash(第三方)
按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,后端服务器为缓存时比较有效。
upstream backserver {
server squid1:3128;
server squid2:3128;
hash $request_uri;
hash_method crc32;
}
解决跨域问题(网关接口)
通过反向代理,使得不同项目变成相同的域名。
server {
listen 80;
server_name www.itmayiedu.com;
location /A {
proxy_pass http://a.a.com:81/A;
index index.html index.htm;
}
location /B {
proxy_pass http://b.b.com:81/B;
index index.html index.htm;
}
}
解决Session共享
产生Session共享问题的原因
集群情况下,每次请求可能不会去到同一台服务器中,例如:第一次请求在A服务器上,返回A服务器上的sessionId,然而第二次请求时去到B服务器上,拿不到所要的Session。
解决方案
1、Nginx负载均衡配置IP绑定的方式
每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器
2、利用数据库同步Session
3、利用coolie同步Session
第一次访问把Session存到A服务器,同时存一份到cookie中,第二次访问分发到B服务器,首先检查有没有Session数据,没有的话再检查本地cookie中有没有。但是安全性比较差,且消耗带宽。
4、使用redis保存Session
防盗链
盗链是指在自己的页面上展示一些并不在自己服务器上的内容。通过盗链的方法可以减轻自己服务器的负担,因为真实的空间和流量均是来自别人的服务器。
配置防盗链
location ~ .*\.(jpg|jpeg|JPG|png|gif|icon)$ {
valid_referers blocked 资源的地址;
if ($invalid_referer) {
return 403; ### 如果来源网址不是资源的地址,则返回403
}
}
通过referer,网站可以检测目标网页访问的来源网页,如果是资源文件,则可以跟踪到显示它的网页地址
防御DDos
配置限制请求次数
limit_req_zone $binary_remote_addr zone=one:10m rate=2r/s;
server {
...
location /login.html {
limit_req zone=one;
...
}
}
limit_req_zone命令设置了一个叫one的共享内存区来存储请求状态的特定键值,在上面的例子中是客户端IP($binary_remote_addr)。location块中的limit_req通过引用one共享内存区来实现限制访问/login.html的目的。
宕机容错(高可用)
宕机轮询
超时后自动轮询到下一台服务器
server {
listen 80;
server_name www.itmayiedu.com;
location / {
proxy_pass http://backserver;
index index.html index.htm;
proxy_connect_timeout 1; ### 设置与upstream server的连接超时时间
proxy_send_timeout 1; ### 设置了发送请求给upstream服务器的超时时间
proxy_read_timeout 1; ### 与代理服务器的读取超时时间
}
}
Nginx+Keepalived(一主一从)
Keepalived是一个基于VRRP协议来实现的服务高可用方案,可以利用其来避免IP单点故障,类似的工具还有heartbeat、corosync、pacemaker。但是它一般不会单独出现,而是与其它负载均衡技术(如lvs、haproxy、nginx)一起工作来达到集群的高可用。
keepalived可以认为是VRRP协议在Linux上的实现,主要有三个模块,分别是core、check和vrrp。
core模块为keepalived的核心,负责主进程的启动、维护以及全局配置文件的加载和解析。
check负责健康检查,包括常见的各种检查方式。
vrrp模块是来实现VRRP协议的。
配置Nginx
master和backup两台服务器的nginx的配置完全一样
配置keepalived
主节点
global_defs {
router_id bhz005 ##标识节点的字符串,通常为hostname
}
vrrp_script chk_nginx {
script "/etc/keepalived/nginx_check.sh" ##执行脚本位置
interval 2 ##检测时间间隔
weight -20 ## 如果条件成立则权重减20(-20)
}
## 定义虚拟路由 VI_1为自定义标识。
vrrp_instance VI_1 {
state MASTER ## 主节点为MASTER,备份节点为BACKUP
## 绑定虚拟IP的网络接口(网卡),与本机IP地址所在的网络接口相同(我这里是eth6)
interface eth6
virtual_router_id 172 ## 虚拟路由ID号
mcast_src_ip 192.168.1.172 ## 本机ip地址
priority 100 ##优先级配置(0-254的值)
Nopreempt ##
advert_int 1 ## 组播信息发送间隔,俩个节点必须配置一致,默认1s
authentication {
auth_type PASS
auth_pass bhz ## 真实生产环境下对密码进行匹配
}
track_script {
chk_nginx
}
virtual_ipaddress {
192.168.1.170 ## 虚拟ip(vip),可以指定多个
}
}
备节点
global_defs {
router_id bhz006
}
vrrp_script chk_nginx {
script "/etc/keepalived/nginx_check.sh"
interval 2
weight -20
}
vrrp_instance VI_1 {
state BACKUP
interface eth7
virtual_router_id 173
mcast_src_ip 192.168.1.173
priority 90 ##优先级配置
advert_int 1
authentication {
auth_type PASS
auth_pass bhz
}
track_script {
chk_nginx
}
virtual_ipaddress {
192.168.1.170
}
}
脚本
#!/bin/bash
A=`ps -C nginx –no-header |wc -l`
if [ $A -eq 0 ];then
/usr/local/nginx/sbin/nginx
sleep 2
if [ `ps -C nginx --no-header |wc -l` -eq 0 ];then
killall keepalived
fi
fi
如果Nginx挂了,则重启。
动态负载均衡
Consul+Upsync+Nginx
每次修改完nginx配置信息,不需要重启,nginx实时读取配置信息。
Nginx: 反向代理和负载均衡
Consul:是用go编写(谷歌),实现对动态负载均衡注册与发现功能
upsync:Nginx动态获取最新upStream(Upsync是新浪微博开源的基于Nginx实现动态配置的三方模块。Nginx-Upsync-Module的功能是拉取Consul的后端server的列表,并动态更新Nginx的路由信息。此模块不依赖于任何第三方模块。Consul作为Nginx的DB,利用Consul的KV服务,每个Nginx Work进程独立的去拉取各个upstream的配置,并更新各自的路由
实现动态负载均衡原理:
1、搭建ConsulServer专门存放负载均衡注册配置信息
2、Nginx间隔时间动态获取最新的ConsulServer配置信息
Nginx的内部(进程)模型
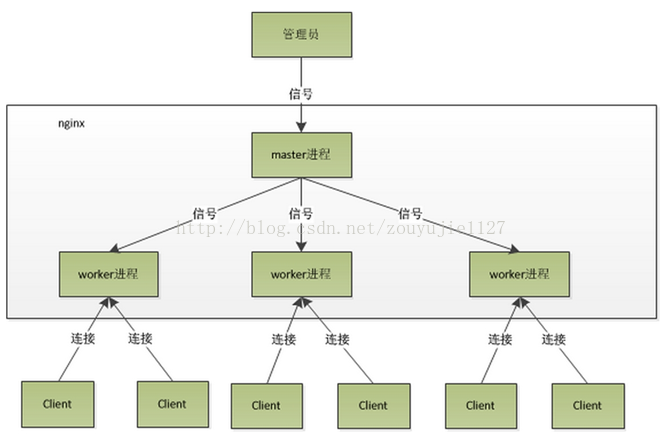
nginx是以多进程的方式来工作的,当然nginx也是支持多线程的方式的,只是我们主流的方式还是多进程的方式,也是nginx的默认方式。nginx采用多进程的方式有诸多好处 .
(1) nginx在启动后,会有一个master进程和多个worker进程。master进程主要用来管理worker进程,包含:接收来自外界的信号,向各worker进程发送信号,监控 worker进程的运行状态,当worker进程退出后(异常情况下),会自动重新启动新的worker进程。而基本的网络事件,则是放在worker进程中来处理了 。多个worker进程之间是对等的,他们同等竞争来自客户端的请求,各进程互相之间是独立的 。一个请求,只可能在一个worker进程中处理,一个worker进程,不可能处理其它进程的请求。 worker进程的个数是可以设置的,一般我们会设置与机器cpu核数一致,这里面的原因与nginx的进程模型以及事件处理模型是分不开的 。
(2)Master接收到信号以后怎样进行处理(./nginx -s reload )?首先master进程在接到信号后,会先重新加载配置文件,然后再启动新的进程,并向所有老的进程发送信号,告诉他们可以光荣退休了。新的进程在启动后,就开始接收新的请求,而老的进程在收到来自master的信号后,就不再接收新的请求,并且在当前进程中的所有未处理完的请求处理完成后,再退出 .
(3) worker进程又是如何处理请求的呢?我们前面有提到,worker进程之间是平等的,每个进程,处理请求的机会也是一样的。当我们提供80端口的http服务时,一个连接请求过来,每个进程都有可能处理这个连接,怎么做到的呢?首先,每个worker进程都是从master进程fork过来,在master进程里面,先建立好需要listen的socket之后,然后再fork出多个worker进程,这样每个worker进程都可以去accept这个socket(当然不是同一个socket,只是每个进程的这个socket会监控在同一个ip地址与端口,这个在网络协议里面是允许的)。一般来说,当一个连接进来后,所有在accept在这个socket上面的进程,都会收到通知,而只有一个进程可以accept这个连接,其它的则accept失败,这是所谓的惊群现象。当然,nginx也不会视而不见,所以nginx提供了一个accept_mutex这个东西,从名字上,我们可以看这是一个加在accept上的一把共享锁。有了这把锁之后,同一时刻,就只会有一个进程在accpet连接,这样就不会有惊群问题了。accept_mutex是一个可控选项,我们可以显示地关掉,默认是打开的。当一个worker进程在accept这个连接之后,就开始读取请求,解析请求,处理请求,产生数据后,再返回给客户端,最后才断开连接,这样一个完整的请求就是这样的了。我们可以看到,一个请求,完全由worker进程来处理,而且只在一个worker进程中处理。
(4):,nginx采用这种进程模型有什么好处呢?采用独立的进程,可以让互相之间不会影响,一个进程退出后,其它进程还在工作,服务不会中断,master进程则很快重新启动新的worker进程。当然,worker进程的异常退出,肯定是程序有bug了,异常退出,会导致当前worker上的所有请求失败,不过不会影响到所有请求,所以降低了风险。当然,好处还有很多,大家可以慢慢体会。
(5).有人可能要问了,nginx采用多worker的方式来处理请求,每个worker里面只有一个主线程,那能够处理的并发数很有限啊,多少个worker就能处理多少个并发,何来高并发呢?非也,这就是nginx的高明之处,nginx采用了异步非阻塞的方式来处理请求,也就是说,nginx是可以同时处理成千上万个请求的 .对于IIS服务器每个请求会独占一个工作线程,当并发数上到几千时,就同时有几千的线程在处理请求了。这对操作系统来说,是个不小的挑战,线程带来的内存占用非常大,线程的上下文切换带来的cpu开销很大,自然性能就上不去了,而这些开销完全是没有意义的。我们之前说过,推荐设置worker的个数为cpu的核数,在这里就很容易理解了,更多的worker数,只会导致进程来竞争cpu资源了,从而带来不必要的上下文切换。而且,nginx为了更好的利用多核特性,提供了cpu亲缘性的绑定选项,我们可以将某一个进程绑定在某一个核上,这样就不会因为进程的切换带来cache的失效
Nginx是如何处理一个请求
首先,nginx在启动时,会解析配置文件,得到需要监听的端口与ip地址,然后在nginx的master进程里面,先初始化好这个监控的socket(创建socket,设置addrreuse等选项,绑定到指定的ip地址端口,再listen),然后再fork(一个现有进程可以调用fork函数创建一个新进程。由fork创建的新进程被称为子进程 )出多个子进程出来,然后子进程会竞争accept新的连接。此时,客户端就可以向nginx发起连接了。当客户端与nginx进行三次握手,与nginx建立好一个连接后,此时,某一个子进程会accept成功,得到这个建立好的连接的socket,然后创建nginx对连接的封装,即ngx_connection_t结构体。接着,设置读写事件处理函数并添加读写事件来与客户端进行数据的交换。最后,nginx或客户端来主动关掉连接,到此,一个连接就寿终正寝了。
当然,nginx也是可以作为客户端来请求其它server的数据的(如upstream模块),此时,与其它server创建的连接,也封装在ngx_connection_t中。作为客户端,nginx先获取一个ngx_connection_t结构体,然后创建socket,并设置socket的属性( 比如非阻塞)。然后再通过添加读写事件,调用connect/read/write来调用连接,最后关掉连接,并释放ngx_connection_t。
说明:nginx在实现时,是通过一个连接池来管理的,每个worker进程都有一个独立的连接池,连接池的大小是worker_connections。这里的连接池里面保存的其实不是真实的连接,它只是一个worker_connections大小的一个ngx_connection_t结构的数组。并且,nginx会通过一个链表free_connections来保存所有的空闲ngx_connection_t,每次获取一个连接时,就从空闲连接链表中获取一个,用完后,再放回空闲连接链表里面。
在这里,很多人会误解worker_connections这个参数的意思,认为这个值就是nginx所能建立连接的最大值。其实不然,这个值是表示每个worker进程所能建立连接的最大值,所以,一个nginx能建立的最大连接数,应该是worker_connections * worker_processes。当然,这里说的是最大连接数,对于HTTP请求本地资源来说,能够支持的最大并发数量是worker_connections * worker_processes,而如果是HTTP作为反向代理来说,最大并发数量应该是worker_connections * worker_processes/2。因为作为反向代理服务器,每个并发会建立与客户端的连接和与后端服务的连接,会占用两个连接。
