

示例代码请访问:github.com/wenjianzhan…
常见分析指标
- Wall Time // 程序运行的绝对时间
- CPU Time // cpu 消耗时间
- Block Time
- Menory allocation // 内存的分配
- GC times.time spent // GC次数 GC耗时
示例代码
structs.go
package profiling
type Request struct {
TransactionID string `json:"transaction_id"`
PayLoad []int `json:"payload"`
}
type Response struct {
TransactionID string `json:"transaction_id"`
Expression string `json:"exp"`
}
optmization.go
package profiling
import (
"encoding/json"
"strconv"
"strings"
)
func createRequest() string {
payload := make([]int, 100, 100)
for i := 0; i < 100; i++ {
payload[i] = i
}
req := Request{"demo_transaction", payload}
v, err := json.Marshal(&req)
if err != nil {
panic(err)
}
return string(v)
}
func processRequest(reqs []string) []string {
reps := []string{}
for _, req := range reqs {
reqObj := &Request{}
json.Unmarshal([]byte(req), reqObj)
ret := ""
for _, e := range reqObj.PayLoad {
ret += strconv.Itoa(e) + ","
}
repObj := &Response{reqObj.TransactionID, ret}
repJson, err := json.Marshal(&repObj)
if err != nil {
panic(err)
}
reps = append(reps, string(repJson))
}
return reps
}
optmization_test.go
package profiling
import "testing"
func TestCreateRequest(t *testing.T) {
str := createRequest()
t.Log(str)
}
func TestProcessRequest(t *testing.T) {
reqs := []string{}
reqs = append(reqs, createRequest())
reps := processRequest(reqs)
t.Log(reps[0])
}
func BenchmarkProcessRequest(b *testing.B) {
reqs := []string{}
reqs = append(reqs, createRequest())
b.ResetTimer()
for i := 0; i < b.N; i++ {
_ = processRequestOld(reqs)
}
b.StopTimer()
}
测试脚本
$ go test -bench=.
goos: darwin
goarch: amd64
pkg: github.com/wenjianzhang/golearning/src/ch45
BenchmarkProcessRequest-4 200000 6814 ns/op
PASS
ok github.com/wenjianzhang/golearning/src/ch45 1.745s
开始优化
性能分析
首先生成 cpu.porf
$ go test -bench=.
输出
goos: darwin
goarch: amd64
pkg: github.com/wenjianzhang/golearning/src/ch45
BenchmarkProcessRequests-4 100000 18050 ns/op
PASS
ok github.com/wenjianzhang/golearning/src/ch45 2.501s
利用 ppfor 工具进行分析,进入控制台
$ go tool pprof cpu.prof
输出
Type: cpu
Time: Nov 17, 2019 at 12:24am (CST)
Duration: 3.17s, Total samples = 2.84s (89.66%)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof)
查看耗时比较多的
(pprof) top
输出
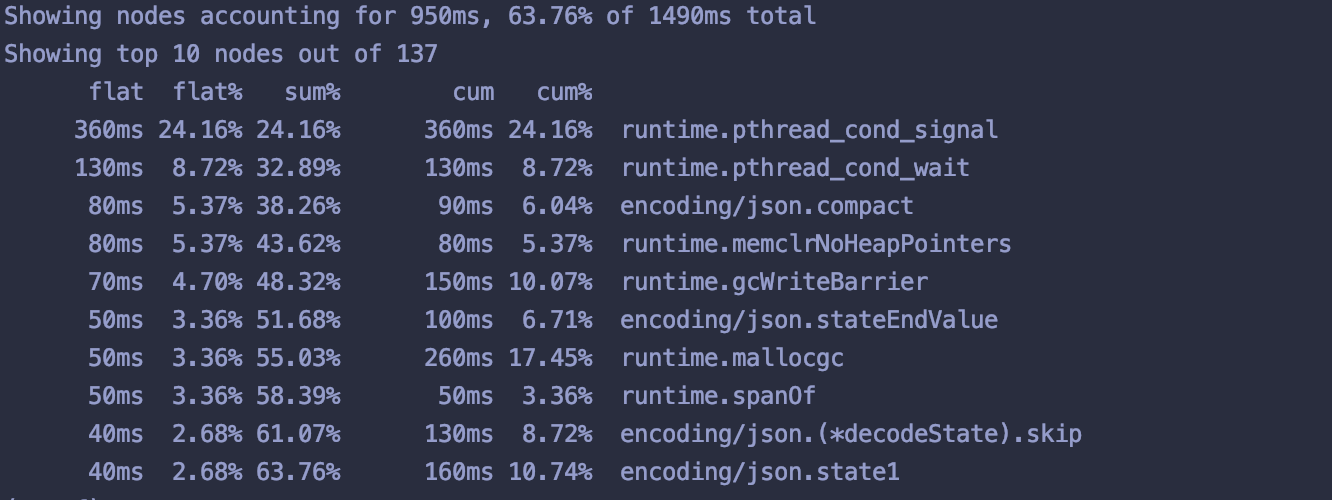
(pprof) top -cum
排序结果
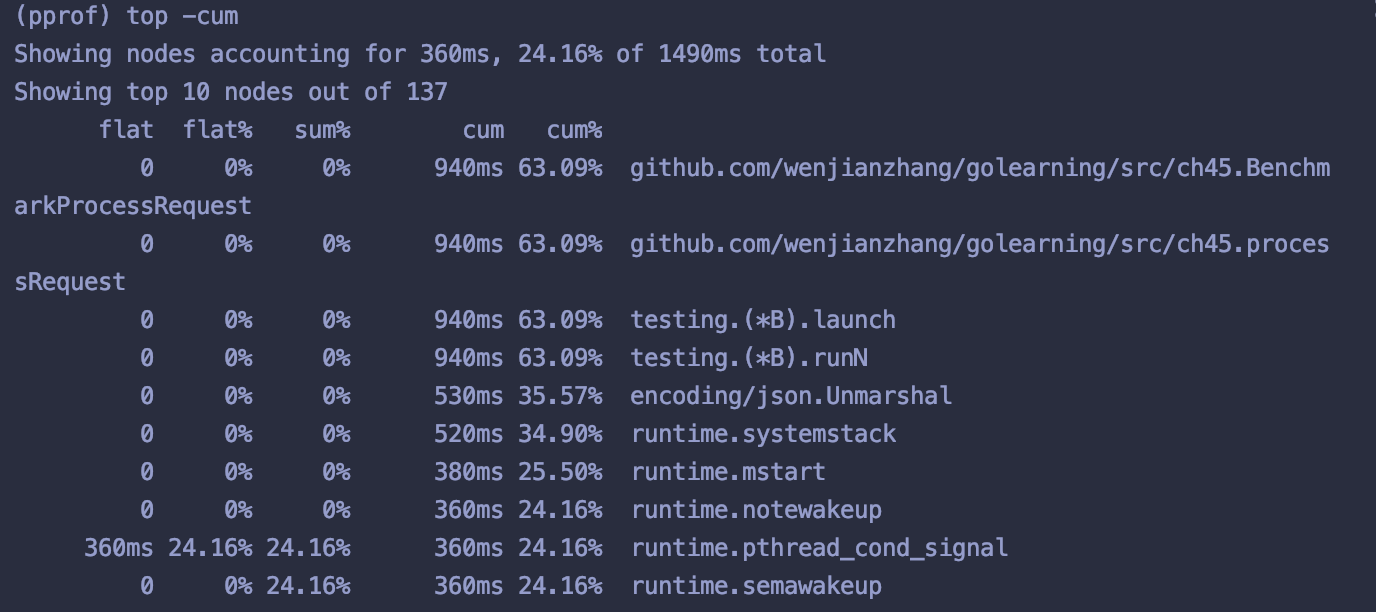
(pprof) list processRequest
分析结果
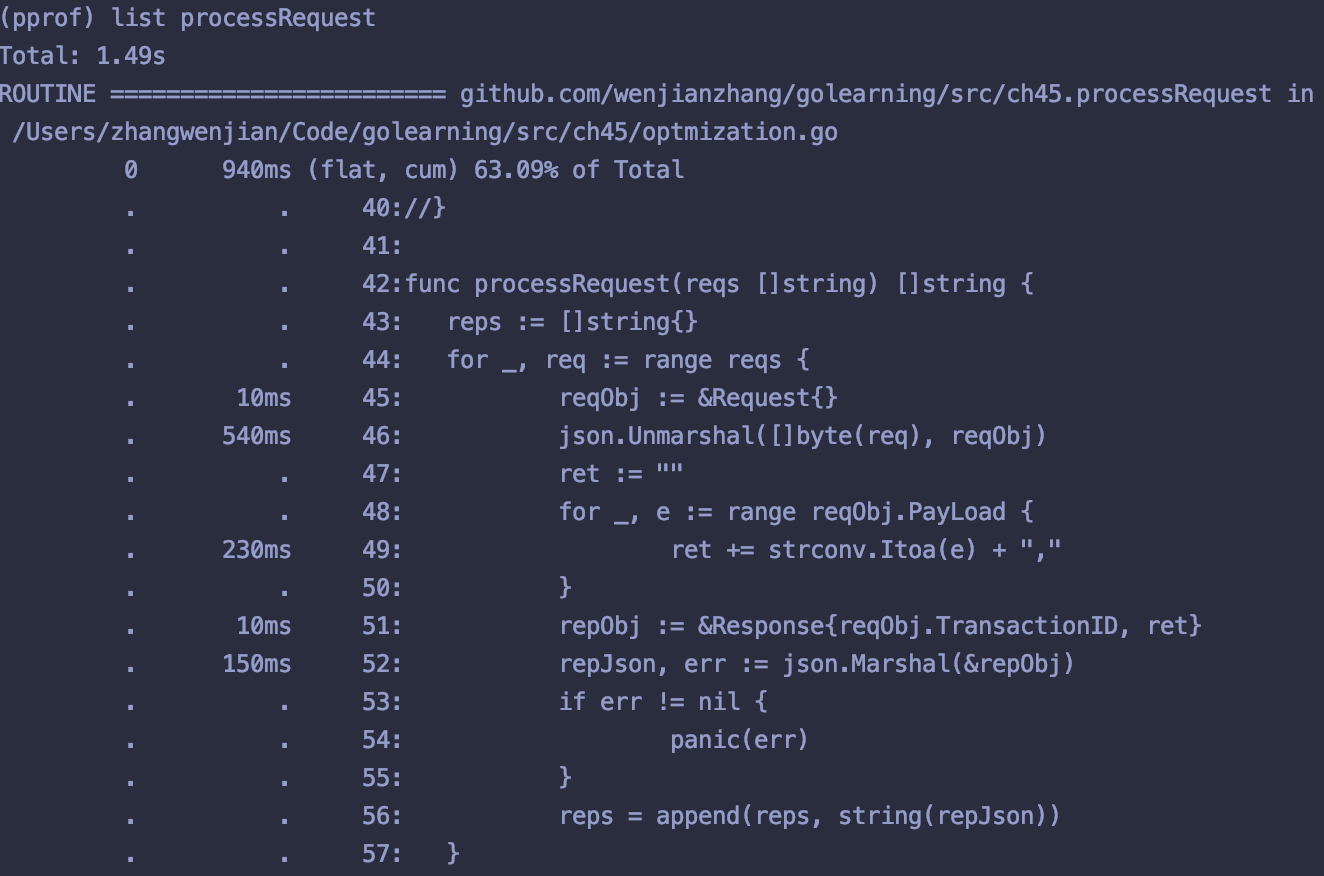
. 540ms 46: json.Unmarshal([]byte(req), reqObj)
因为我们上述代码中使用的是go 内置的 json 序列化、反序列化,而它们是使用反射的机制实现的效率相比之下是会慢一些的 下面,我们使用easyjson进行优化 首先,需要用easyjson工具生成 struct 对象
$ ls

$ easyjson -all structs.go
$ ls

可以看到新生成了一个 structs_easyjson.go 的文件
代码改进
代码段一
// json.Unmarshal([]byte(req), reqObj)
reqObj.UnmarshalJSON([]byte(req))
代码段二
// repJson, err := json.Marshal(&repObj)
repJson, err := repObj.MarshalJSON()
改进后的方法 方法名是 processRequest ,改进前的方法名是 processRequestOld
optmization.go
func processRequest(reqs []string) []string {
reps := []string{}
for _, req := range reqs {
reqObj := &Request{}
reqObj.UnmarshalJSON([]byte(req))
var buf strings.Builder
for _, e := range reqObj.PayLoad {
buf.WriteString(strconv.Itoa(e))
buf.WriteString(",")
}
repObj := &Response{reqObj.TransactionID, buf.String()}
repJson, err := repObj.MarshalJSON()
if err != nil {
panic(err)
}
reps = append(reps, string(repJson))
}
return reps
}
func processRequestOld(reqs []string) []string {
reps := []string{}
for _, req := range reqs {
reqObj := &Request{}
json.Unmarshal([]byte(req), reqObj)
ret := ""
for _, e := range reqObj.PayLoad {
ret += strconv.Itoa(e) + ","
}
repObj := &Response{reqObj.TransactionID, ret}
repJson, err := json.Marshal(&repObj)
if err != nil {
panic(err)
}
reps = append(reps, string(repJson))
}
return reps
}
修改完成后,我们执行测试程序结果和之前一直
=== RUN TestProcessRequest
--- PASS: TestProcessRequest (0.00s)
optimization_test.go:14: {"transaction_id":"demo_transaction","exp":"0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99,"}
PASS
Process finished with exit code 0
重新做一次benchmark
$ go test -bench=.
输出
goos: darwin
goarch: amd64
pkg: github.com/wenjianzhang/golearning/src/ch45
BenchmarkProcessRequests-4 100000 11818 ns/op
PASS
ok github.com/wenjianzhang/golearning/src/ch45 1.870s
进入pprof控制台
$ go test -bench=. -cpuporfile=cpu.prof
$ go tool pprof cpu.porf
ROUTINE ======================== github.com/wenjianzhang/golearning/src/ch45.processRequest in /Users/zhangwenjian/Code/golearning/src/ch45/optmization.go
10ms 210ms (flat, cum) 13.04% of Total
. . 20:
. . 21:func processRequest(reqs []string) []string {
. . 22: reps := []string{}
. . 23: for _, req := range reqs {
. . 24: reqObj := &Request{}
. 30ms 25: reqObj.UnmarshalJSON([]byte(req))
. . 26:
. . 27: ret := ""
. . 28: for _, e := range reqObj.PayLoad {
10ms 140ms 29: ret += strconv.Itoa(e) + ","
. . 30: }
. . 31: repObj := &Response{reqObj.TransactionID, ret}
. 30ms 32: repJson, err := repObj.MarshalJSON()
. . 33: if err != nil {
. . 34: panic(err)
. . 35: }
. 10ms 36: reps = append(reps, string(repJson))
. . 37: }
. . 38: return reps
. . 39:}
. . 40:
. . 41://func processRequest(reqs []string) []string {
(pprof)
之前的540ms 到 30ms 以上代码其实还能继续优化。。。
示例代码请访问:github.com/wenjianzhan…
