

ast示例
定义模版如下
<div id="app">
<p>测试</p>
<p :v-if="true">v-if</p>
<div v-for="item in array">
<span>{{item}}</span>
</div>
</div>
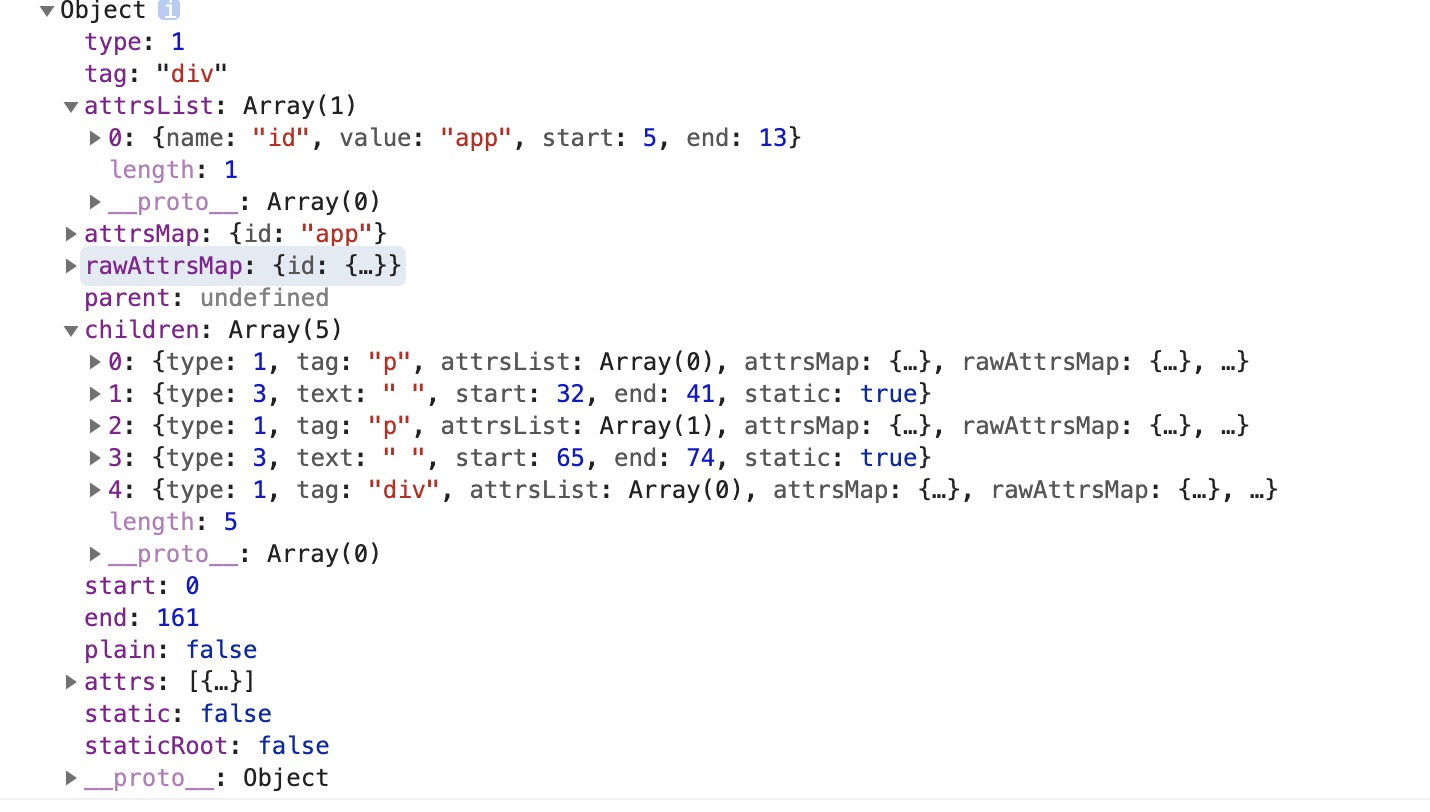
我们debugger调试查看生成的ast如下
最外层的div被转化为如下结构,div下有五个子节点,分别是两个p标签,两个文本节点,一个div节点
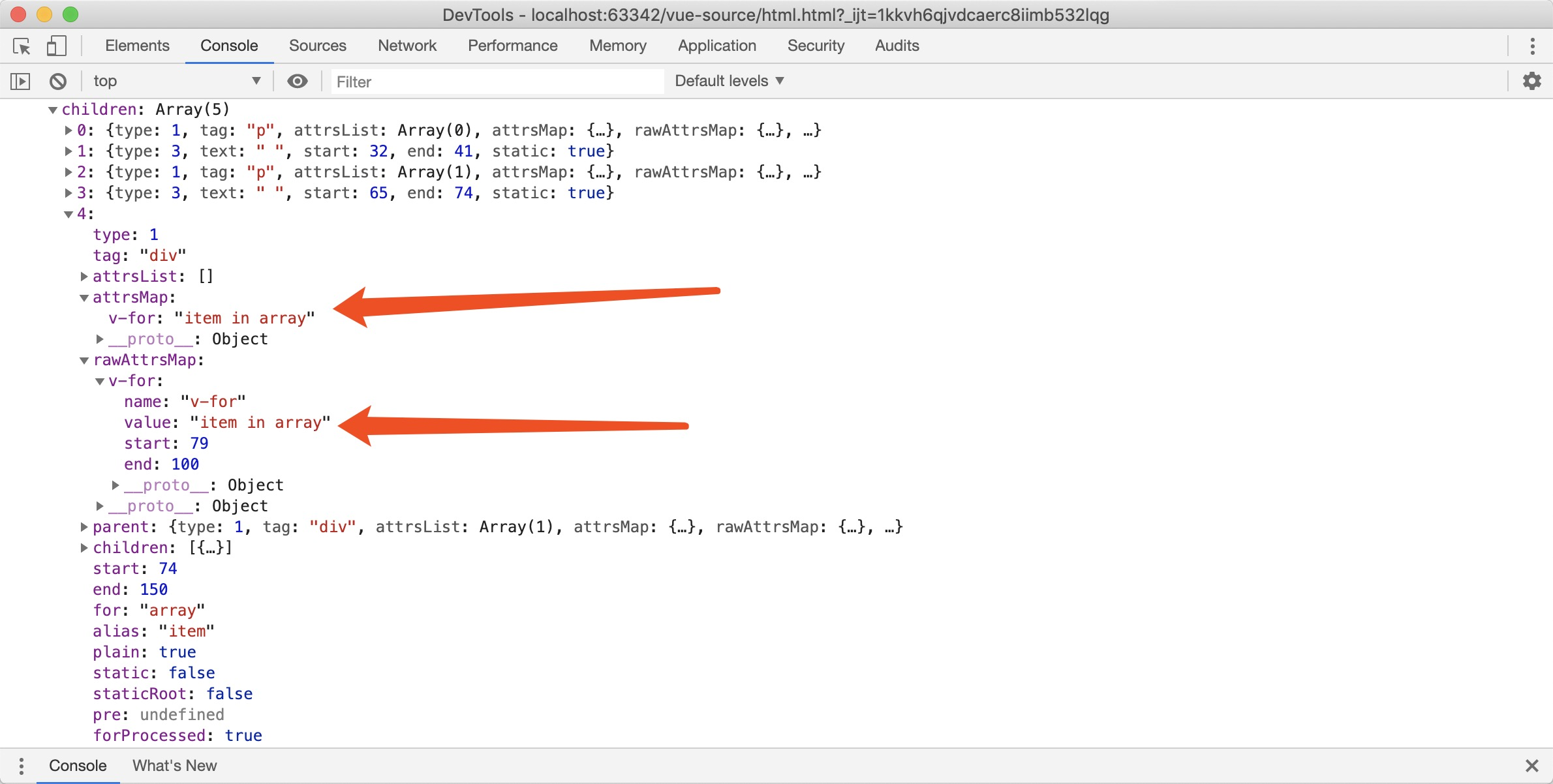
v-for被转化为如下
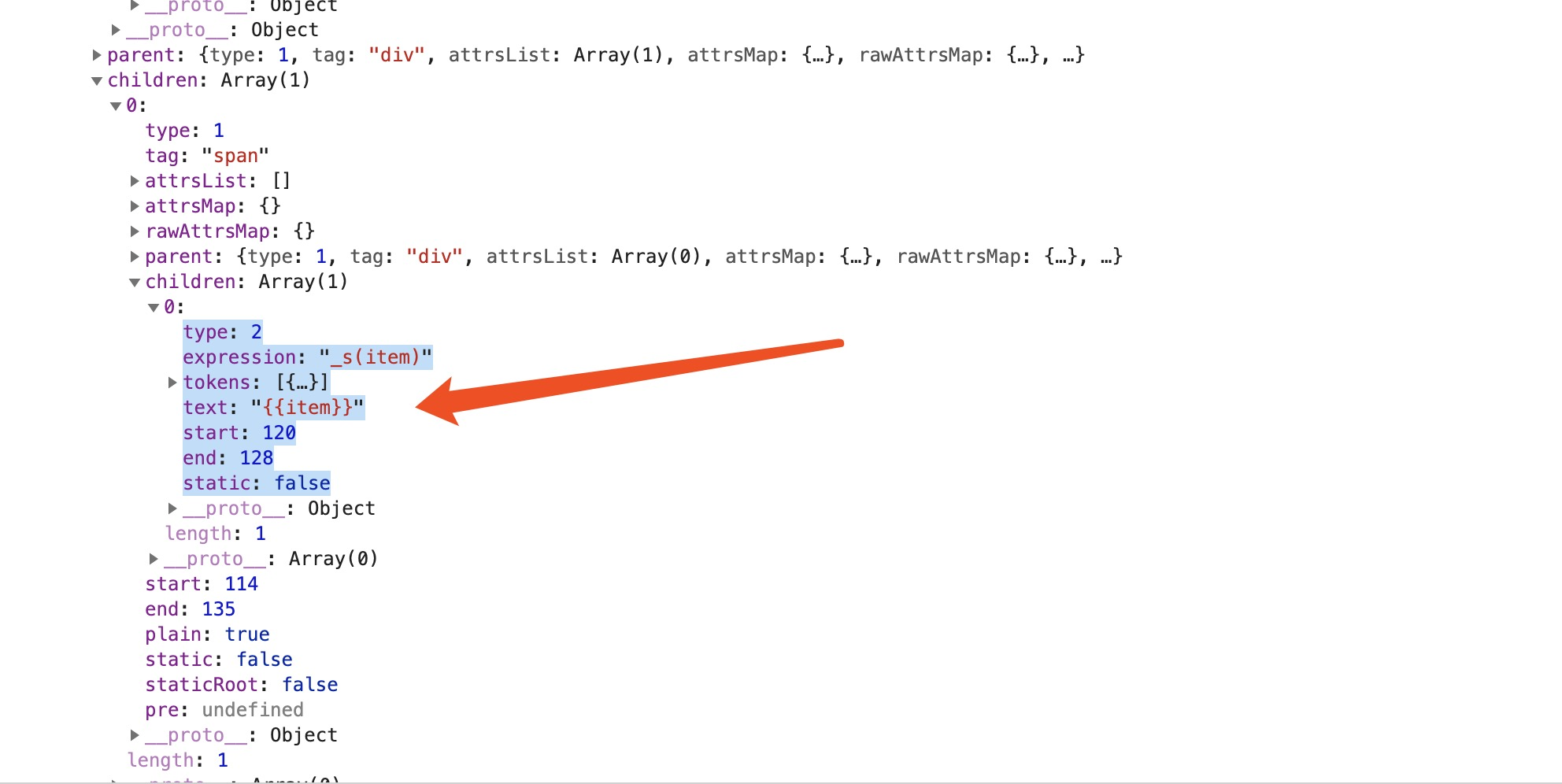
{{item}} 双打括号包裹的表达是会被转换为如下方式
parse(template,options)
此方法的作用就是生成ast,ast是抽象语法树
此方法接受两个参数,一个template字符串就是传入的模版字符串
第二个参数是由baseOptins和用户调用compileToFunctions传入的第二个参数 合并之后的产物
以下是compileToFunctions传入的options,就是一些方法和配置
compileToFunctions(template, {
outputSourceRange: process.env.NODE_ENV !== 'production',
shouldDecodeNewlines,
shouldDecodeNewlinesForHref,
// 改变纯文本插入分隔符 默认是 ["{{", "}}"] 如果改成 ['${', '}'] 那么模板上就可以用 ${}去包裹数据了
delimiters: options.delimiters,
// 当设为 true 时,将会保留且渲染模板中的 HTML 注释。默认行为是舍弃它们。
comments: options.comments
}, this)
以下是baseOptions定义,也是一些方法
baseOptions: CompilerOptions = {
expectHTML: true,
modules,
directives,
// 是否是pre标签
isPreTag,
// 没有内容的标签
isUnaryTag,
// 用来检测一个属性在标签中是否要使用元素对象原生的 prop 进行绑定
mustUseProp,
// 可无结束标签
canBeLeftOpenTag,
// 是原生标签,非自定义
isReservedTag,
// 获得标签命名空间,即判断是svg相关标签 还是 math相关标签
getTagNamespace,
staticKeys: genStaticKeys(modules)
我们debugger看一下最终合并后的options
我们可以看到baseOptions会被保存在原型中
这些方法在parse中用到了再详细讲解
outputSourceRange: true
shouldDecodeNewlines: false
shouldDecodeNewlinesForHref: false
delimiters: undefined
comments: undefined
warn: ƒ (msg, range, tip)
__proto__:
expectHTML: true
modules: (3) [{…}, {…}, {…}]
directives: {model: ƒ, text: ƒ, html: ƒ}
isPreTag: ƒ (tag)
isUnaryTag: ƒ (val)
mustUseProp: ƒ (tag, type, attr)
canBeLeftOpenTag: ƒ (val)
isReservedTag: ƒ (tag)
getTagNamespace: ƒ getTagNamespace(tag)
staticKeys: "staticClass,staticStyle"
__proto__: Object
接下来我们着重看一下parse是如何将模版编译为ast的
parse的主要逻辑就是先将options中的方法取出来,组装一个参数传入parseHTML方法中,parse重点就是parseHTML这个方法
/**
* Convert HTML string to AST.
*/
// 将html字符串转化为抽象语法树
export function parse (
template: string,
options: CompilerOptions
): ASTElement | void {
// 警告函数,没有的话用基础的
warn = options.warn || baseWarn
// 拿到isPreTag函数,如果 参数 === 'pre' 返回true,用于判断是否是pre标签
platformIsPreTag = options.isPreTag || no
// 用来检测一个属性在标签中是否要使用元素对象原生的 prop 进行绑定
platformMustUseProp = options.mustUseProp || no
platformGetTagNamespace = options.getTagNamespace || no
// 判断是html标签或者svg标签
const isReservedTag = options.isReservedTag || no
// 可能是组件
maybeComponent = (el: ASTElement) => !!el.component || !isReservedTag(el.tag)
transforms = pluckModuleFunction(options.modules, 'transformNode')
preTransforms = pluckModuleFunction(options.modules, 'preTransformNode')
postTransforms = pluckModuleFunction(options.modules, 'postTransformNode')
// 表示 模板上 包裹表达式的开始和结束字符 默认是 ["{{", "}}"]
delimiters = options.delimiters
const stack = []
const preserveWhitespace = options.preserveWhitespace !== false
const whitespaceOption = options.whitespace
let root
let currentParent
let inVPre = false
let inPre = false
let warned = false
function warnOnce (msg, range) {/*代码省略*/}
function closeElement (element) {/*代码省略*/}
function trimEndingWhitespace (el) {/*代码省略*/}
function checkRootConstraints (el) {/*代码省略*/}
parseHTML(template, {
warn,
expectHTML: options.expectHTML,
isUnaryTag: options.isUnaryTag,
canBeLeftOpenTag: options.canBeLeftOpenTag,
shouldDecodeNewlines: options.shouldDecodeNewlines,
shouldDecodeNewlinesForHref: options.shouldDecodeNewlinesForHref,
shouldKeepComment: options.comments,
outputSourceRange: options.outputSourceRange,
start (tag, attrs, unary, start, end) {/*代码省略*/},
end (tag, start, end) {/*代码省略*/},
chars (text: string, start: number, end: number) {/*代码省略*/},
// 处理注释
comment (text: string, start, end) {/*代码省略*/}
})
return root
}
接下来我们逐步分析parse方法
首先先将options中的方法赋值给一堆变量,我们一一分析每个方法的作用
// 拿到isPreTag函数,如果 参数 === 'pre' 返回true,用于判断是否是pre标签
platformIsPreTag = options.isPreTag || no
// 用来检测一个属性在标签中是否要使用元素对象原生的 prop 进行绑定
platformMustUseProp = options.mustUseProp || no
platformGetTagNamespace = options.getTagNamespace || no
// 判断是html标签或者svg标签
const isReservedTag = options.isReservedTag || no
// 可能是组件
maybeComponent = (el: ASTElement) => !!el.component || !isReservedTag(el.tag)
// 遍历modules数组中每一个数组的transformNode方法
// 如[
// klass, // klass = { staticKeys: ['staticClass'],transformNode,genData}
// style,
// model
// ] 每一项的transformNode
transforms = pluckModuleFunction(options.modules, 'transformNode')
// 同上拿到所有preTransformNode方法,保存至一个数组中
preTransforms = pluckModuleFunction(options.modules, 'preTransformNode')
// 同上拿到所有postTransformNode方法,保存至一个数组中
postTransforms = pluckModuleFunction(options.modules, 'postTransformNode')
// 表示 模板上 包裹表达式的开始和结束字符 默认是 ["{{", "}}"]
delimiters = options.delimiters
isPreTag(tag)
isPreTag方法很简单,就判读tag是否是pre
export const isPreTag = (tag: ?string): boolean => tag === 'pre'
mustUseProp(tag, type, attr)
// attributes that should be using props for binding
const acceptValue = makeMap('input,textarea,option,select,progress')
// 判断 input,textarea,option,select,progress标签的value属性
// option的selected属性,input的checked属性,video的muted属性是否存在
// 如果这些标签的属性存在的话, 将被保存至ast对象的el.props属性中
export const mustUseProp = (tag: string, type: ?string, attr: string): boolean => {
return (
(attr === 'value' && acceptValue(tag)) && type !== 'button' ||
(attr === 'selected' && tag === 'option') ||
(attr === 'checked' && tag === 'input') ||
(attr === 'muted' && tag === 'video')
)
}
getTagNamespace(tag)
// 获得标签命名空间,即判断是svg相关标签 还是 math相关标签
export function getTagNamespace (tag: string): ?string {
if (isSVG(tag)) {
return 'svg'
}
// basic support for MathML
// note it doesn't support other MathML elements being component roots
if (tag === 'math') {
return 'math'
}
}
isReservedTag()
判断是原生标签(非自定义标签,即组件)
// 是原生标签
export const isReservedTag = (tag: string): ?boolean => {
return isHTMLTag(tag) || isSVG(tag)
}
接下来我们重点分析以下parseHTML方法
通过分析parseHTML方法源码我们可得知,此方法主要是在逐步的将html字符串转换为ast
处理过程如下
例如html字符串如下
<div id="app">123</div>
首先解析起始标签< div id="app">, 标签的属性将被处理为对象的形式,然后调用options.start()方法将起始标签编译为ast
处理后进入下一次循环,此时html = 123< /div> 经过一系列判断此时需要处理‘123’这个文本节点,调用options.char方法将文本转化为ast,
处理后又进入下一个循环,此时html= < /div>经过判断得知此时需要处理一个结束标签,调用options.end方法将结束标签转化为ast
html模版就是一点一点的被转化为ast的
// 解析html
export function parseHTML (html, options) {
// 定义一个栈
const stack = []
// web环境是true
const expectHTML = options.expectHTML
// 无内容的标签 如<link href=xxx></link>
const isUnaryTag = options.isUnaryTag || no
// 可以不闭合的标签
// 例如:
// <table>
// <thead>
// <tr>
// <th scope="col">Income
// <th scope="col">Taxes
// <tbody>
// <tr>
// <td>$ 5.00
// <td>$ 4.50
// </table>
const canBeLeftOpenTag = options.canBeLeftOpenTag || no
let index = 0
let last, lastTag
// 当html字符串不为空
while (html) {
// 保存上一次处理的html字符串
last = html
// Make sure we're not in a plaintext content element like script/style
// 确保父级标签不是 script,style,textarea
// 如果上一次处理的标签不是 script,style,textarea
if (!lastTag || !isPlainTextElement(lastTag)) {
// 第一个 '<' 的位置
let textEnd = html.indexOf('<')
// 第一个字符是 '<'
if (textEnd === 0) {
// Comment:
// 处理注释
if (comment.test(html)) {
// 拿到注释结尾的下标
const commentEnd = html.indexOf('-->')
if (commentEnd >= 0) {
if (options.shouldKeepComment) {
// 调用传进来的comment处理方法
options.comment(html.substring(4, commentEnd), index, index + commentEnd + 3)
}
// advanc方法就是截取字符串,html.substring(n)
advance(commentEnd + 3)
continue
}
}
// http://en.wikipedia.org/wiki/Conditional_comment#Downlevel-revealed_conditional_comment
// 如果以<![ 开头 啥也没做,直接略过了
if (conditionalComment.test(html)) {
const conditionalEnd = html.indexOf(']>')
if (conditionalEnd >= 0) {
advance(conditionalEnd + 2)
continue
}
}
// Doctype:
// 如果匹配到有文档类型相关的字符串 同样滤过
const doctypeMatch = html.match(doctype)
if (doctypeMatch) {
advance(doctypeMatch[0].length)
continue
}
// End tag:
// 如果遇到结束标签
const endTagMatch = html.match(endTag)
if (endTagMatch) {
const curIndex = index
// 截取掉结束标签
advance(endTagMatch[0].length)
// 处理结束标签
parseEndTag(endTagMatch[1], curIndex, index)
continue
}
// Start tag:
// 匹配开始标签 匹配的属性都保存在对象的attrs中
const startTagMatch = parseStartTag()
if (startTagMatch) {
// 处理起始标签
// 主要逻辑是处理attrs,并调用options.start方法
handleStartTag(startTagMatch)
if (shouldIgnoreFirstNewline(startTagMatch.tagName, html)) {
advance(1)
}
continue
}
}
let text, rest, next
// 如果首个字符不是'<', 即起始和结束标签中的文本
if (textEnd >= 0) {
// 截取到从下一个'<' 到结束
rest = html.slice(textEnd)
// 如果没有匹配到结束标签注释,开始标签,注释,文档类型声明
// 说明'<'是 文本节点中的,并非标签的'<'
while (
!endTag.test(rest) &&
!startTagOpen.test(rest) &&
!comment.test(rest) &&
!conditionalComment.test(rest)
) {
// < in plain text, be forgiving and treat it as text
// 如果之后没有'<'了,退出循环
// 否则继续往后找
next = rest.indexOf('<', 1)
if (next < 0) break
textEnd += next
rest = html.slice(textEnd)
}
// 此时拿到的就是标签之间的文本
text = html.substring(0, textEnd)
}
// 如果没有'<'字符,那么就是一个纯文本了,没有标签
if (textEnd < 0) {
text = html
}
if (text) {
advance(text.length)
}
if (options.chars && text) {
// 调用chars方法处理文本节点,生成对应的ast
options.chars(text, index - text.length, index)
}
} else {
// 如果上一次处理的标签是 script,style,textarea
// 以下逻辑主要是在处理 script,style,textarea中的文本内容
let endTagLength = 0
const stackedTag = lastTag.toLowerCase()
const reStackedTag = reCache[stackedTag] || (reCache[stackedTag] = new RegExp('([\\s\\S]*?)(</' + stackedTag + '[^>]*>)', 'i'))
const rest = html.replace(reStackedTag, function (all, text, endTag) {
endTagLength = endTag.length
if (!isPlainTextElement(stackedTag) && stackedTag !== 'noscript') {
text = text
.replace(/<!\--([\s\S]*?)-->/g, '$1') // #7298
.replace(/<!\[CDATA\[([\s\S]*?)]]>/g, '$1')
}
if (shouldIgnoreFirstNewline(stackedTag, text)) {
text = text.slice(1)
}
if (options.chars) {
options.chars(text)
}
return ''
})
index += html.length - rest.length
html = rest
// 处理结束标签
parseEndTag(stackedTag, index - endTagLength, index)
}
// 如果下一次的html和上一次的相等
if (html === last) {
// 那么直接调用chars方法把剩余的剩余的html字符串当作文本处理
options.chars && options.chars(html)
if (process.env.NODE_ENV !== 'production' && !stack.length && options.warn) {
options.warn(`Mal-formatted tag at end of template: "${html}"`, { start: index + html.length })
}
// 退出while循环
break
}
}
// Clean up any remaining tags
// 清空stack,stack保存了起始标签生成的ast
parseEndTag()
// 去掉字符串前面n个字符
function advance (n) {/*代码省略*/}
function parseStartTag () {/*代码省略*/}
// 处理开始标签 主要是在处理 attrs, 调用options.start方法
function handleStartTag (match) {/*代码省略*/}
// 解析闭合标签, 调用options.end方法
function parseEndTag (tagName, start, end) {/*代码省略*/}
}
接下来我们介绍三个ast生成函数start,char,end
start()
start方法的作用就是将标签和标签上的属性解析为ast
ast的结构如下
{
// type为1表示标签节点,如启始标签
type: 1,
tag: tag,
attrsList: [{name: "id", value: "app", start: 5, end: 13},
attrsMap: {
id: "app"
},
rawAttrsMap: {},
parent: parent,
children: []
}
start (tag, attrs, unary, start, end) {
// check namespace.
// inherit parent ns if there is one
// 获得命名空间
const ns = (currentParent && currentParent.ns) || platformGetTagNamespace(tag)
// handle IE svg bug
/* istanbul ignore if */
// 如果是svg 处理ie的bug
if (isIE && ns === 'svg') {
attrs = guardIESVGBug(attrs)
}
// 创建ast的结构
let element: ASTElement = createASTElement(tag, attrs, currentParent)
// 如果命名空间存在,就给当前ast赋值
if (ns) {
element.ns = ns
}
if (process.env.NODE_ENV !== 'production') {
// 如果是开发环境,outputSourceRange为true的话,那么给ast设置start,end等属性表示源代码所处的位置
if (options.outputSourceRange) {
element.start = start
element.end = end
// 将attrsList数组转化为 对象,key就是属性名称
element.rawAttrsMap = element.attrsList.reduce((cumulated, attr) => {
cumulated[attr.name] = attr
return cumulated
}, {})
}
attrs.forEach(attr => {
// 校验属性名称是否合法
if (invalidAttributeRE.test(attr.name)) {
warn(
`Invalid dynamic argument expression: attribute names cannot contain ` +
`spaces, quotes, <, >, / or =.`,
{
start: attr.start + attr.name.indexOf(`[`),
end: attr.start + attr.name.length
}
)
}
})
}
// 如果是被禁止的标签 并且不是服务端渲染
if (isForbiddenTag(element) && !isServerRendering()) {
element.forbidden = true
process.env.NODE_ENV !== 'production' && warn(
'Templates should only be responsible for mapping the state to the ' +
'UI. Avoid placing tags with side-effects in your templates, such as ' +
`<${tag}>` + ', as they will not be parsed.',
{ start: element.start }
)
}
// apply pre-transforms
// 调用preTransform 处理element 对象 默认就是options.mouduls传入的对象中的preTransform函数
//
for (let i = 0; i < preTransforms.length; i++) {
// 默认情况下 这里主要在处理 input 元素
element = preTransforms[i](element, options) || element
}
// 如果是不在pre中
if (!inVPre) {
processPre(element)
// 如果解析次元素有 v-pre
if (element.pre) {
// 子节点都会被标识为inPre
// 跳过这个元素和它的子元素的编译过程
inVPre = true
}
}
// 如果是pre标签
if (platformIsPreTag(element.tag)) {
inPre = true
}
// 如果是V-pre
if (inVPre) {
// 只简单处理一下属性
processRawAttrs(element)
} else if (!element.processed) {
// 否则如果该元素还未被处理过,因为有写标签可能预处理过如input
// structural directives
// 处理v-for
processFor(element)
// 处理v-if
processIf(element)
// 处理v-once
processOnce(element)
}
// 如果root为空的话,root就等于这个el
if (!root) {
root = element
if (process.env.NODE_ENV !== 'production') {
//如果是开发环境 检查一波
checkRootConstraints(root)
}
}
// 如果不是无内容标签
if (!unary) {
currentParent = element
// 将该元素入栈
stack.push(element)
} else {
// 否则调用闭合标签函数
closeElement(element)
}
}
chars()
chars方法主要就是处理文本节点,将文本转化为如下结构
{
// type为3表示文本节点
type: 3,
text
}
保存至父节点的children属性当中
