

目前有个java程序,对数据库test的A表进行查询
create table A(id int primary key auto_increment, name varchar(12) ,age int);
insert into A(name,age)value("Jack",12),("Helon",13);
select * from A where name = "Jack";
客户端
客户端指python,java等连接mysql服务器的程序
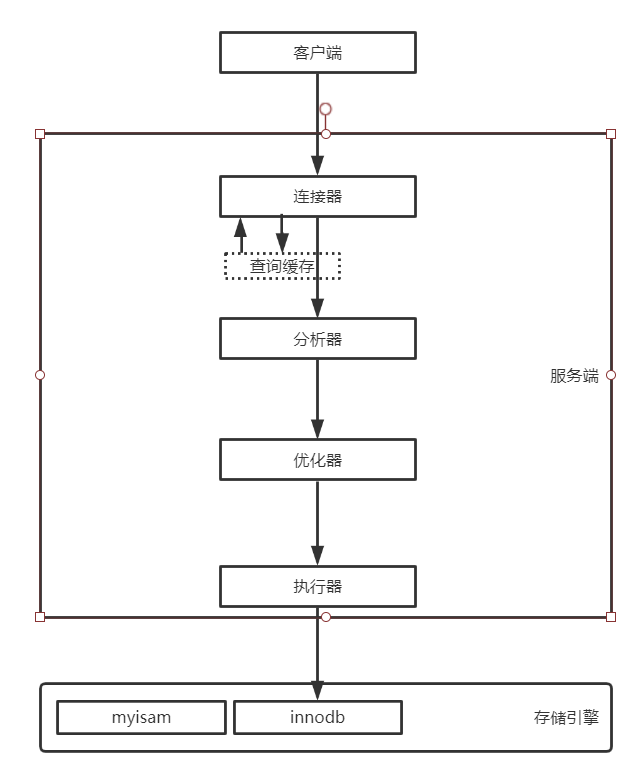
mysql服务器
服务器包括server和存储引擎
server
主要包括连接器,分析器,优化器,执行器
-
连接器
- 对客户端的连接进行管理
- 对连接进行权限验证,不通过直接返回错误给客户端
- 验证成功后,加载权限信息到连接的会话中,所以如果修改权限后,该连接不会生效,需要重新连接
- 因为一个新的连接需要做比较多的操作,建议使用长连接,减少新建连接
- 连接临时使用过内存不会主动回收,所以会导致内存使用越来越多,可以执行mysql_reset_connection进行内存释放
- 如果连接一直空闲超过wait_timeout这个数值,会被连接器断开,所以长连接的客户端需要发送定时检测,确保连接能够使用
-
查询缓存
- 查询缓存在对应表有修改的情况下,会被淘汰掉,所以在变更比较多的表,不要使用缓存,可以对单独的静态表做查询缓存
select SQL_CACHE * from A where name = "Jack";- 默认不开启,mysql8已经移除相关功能
query_cache_type = OFF -
分析器
- 对sql语句的词进行分析,如表,字段等,如果发现字段不存在,表不存在等,直接返回错误
- 对sql语句的语法进行分析,判断sql语句是否合法,不合法直接返回错误
-
优化器
- 对sql语句进行索引选择等优化
- 对sql语句进行优化,如select count(*) from A 这类sql
- 生成执行计划
-
执行器
- 判断有没有执行查询的权限,如果没有,就会返回没有权限的错误
- 调用存储引擎接口,执行优化器生成的执行计划
存储引擎
-
innodb
内存有数据的情况
- 直接返回数据
内存没有数据的情况
没有索引的情况
- 因该语句没有使用索引,直接全表(主键的B+树)扫描
- 找到对应数据页(不是单条记录,是记录所在的数据页),存放到内存,返回给执行器
有索引的情况
- 先对A表的列name添加索引,生成name的B+树,B+树的内容包含了这个索引包含的字段值还有主键的值,如果是联合索引就是多个字段的值和主键的值。
alter table a add index a_name_index(name); insert into A(name,age)value("Lam",12); select * from A where name = "Jack";- 此时优化器生成的执行计划会变成选择name字段作为索引
- 存储引擎对name的B+树进行搜索,找到Jack的数据,因为查询的是所有字段,而name的B+树只存储了name和主键id的值,没有age的值,所以需要回表查询主键id的B+树,把age的值也查询出来,然后查询下一个记录,查询到值为Lam,不满足要求,结束查询,最后把对应记录的数据页放到内存,返回给执行器
涉及的锁
- MDL锁
- 查询语句会开启一个MDL读锁(metadata lock shared read)
- 如果有一个长事务不提交,会导致DDL操作执行不了,进一步影响DML操作。如下图所示,一个查询会话,不提交事务,会导致drop,alter等操作阻塞,并影响之后的select等操作。
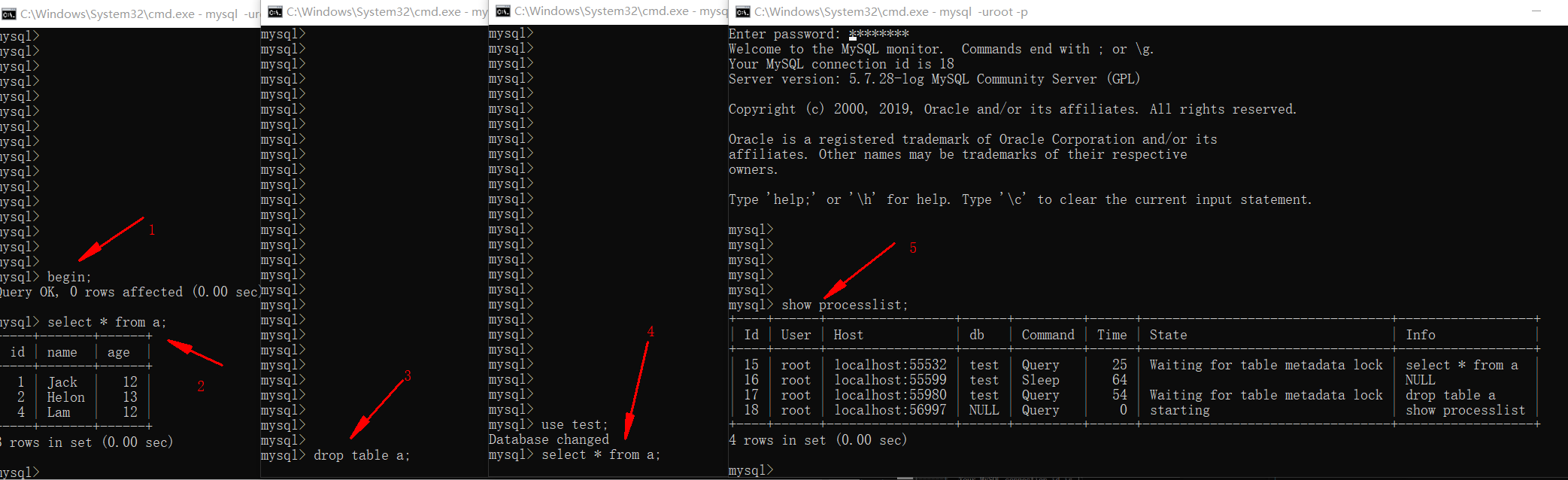
- 思考问题,如果出现这种锁表的情况,如何知道是哪个事务拥有锁?
- 思考问题,如果在查询的时候,有别的连接对该表进行了修改,查询结果会有什么不同,我们来看下不同隔离级别下的实验
不同隔离级别下的表现
- 不提交读(READ-UNCOMMITTED)
- 设置数据库隔离级别为不提交读,并确保两个会话的隔离级别一致,重新设置隔离级别后,只有新的连接生效。
set global transaction_isolation="READ-UNCOMMITTED"; show variables like 'transaction_isolation';

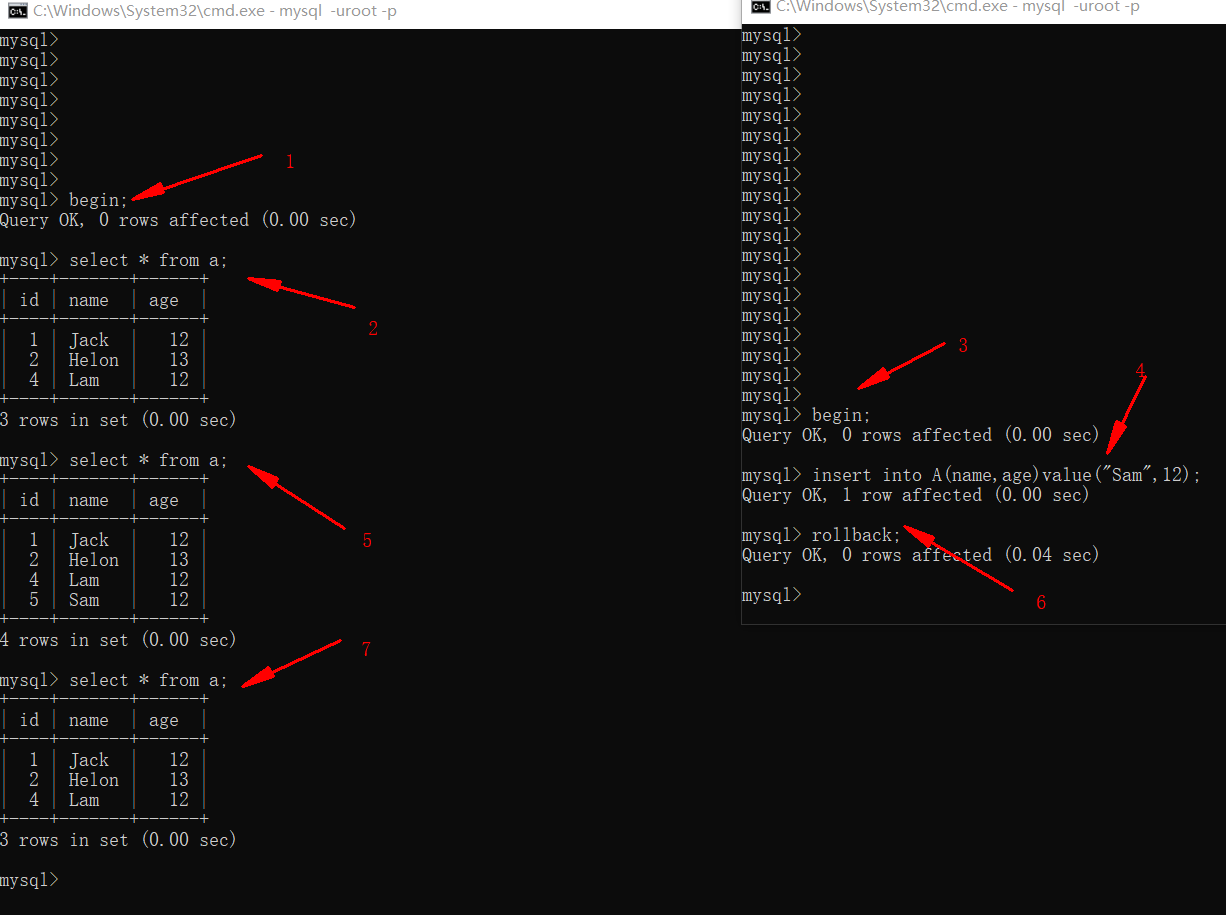
由上图可以看出,第一个事务可以读到第二个还没提交的事务做的变更,这就导致如果第二个事务出现回滚的话,第一个事务读到的数据就会出现无效的数据。
- 可提交读(READ-COMMITTED)
- 设置隔离界级别为可提交读,并确保两个会话的隔离级别一致
set global transaction_isolation="READ-COMMITTED";
show variables like 'transaction_isolation';

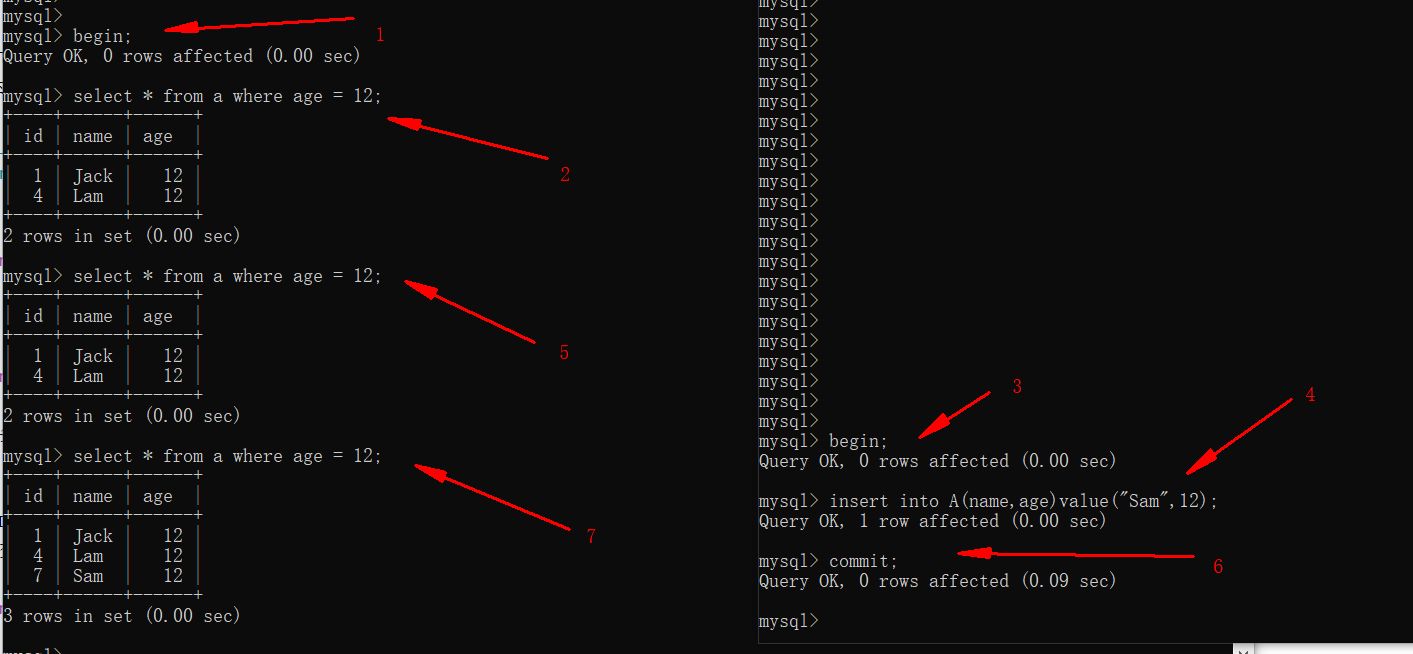
- 可重复读(REPEATABLE-READ)
- 设置隔离级别为可重复读
set global transaction_isolation="REPEATABLE-READ";
show variables like 'transaction_isolation';

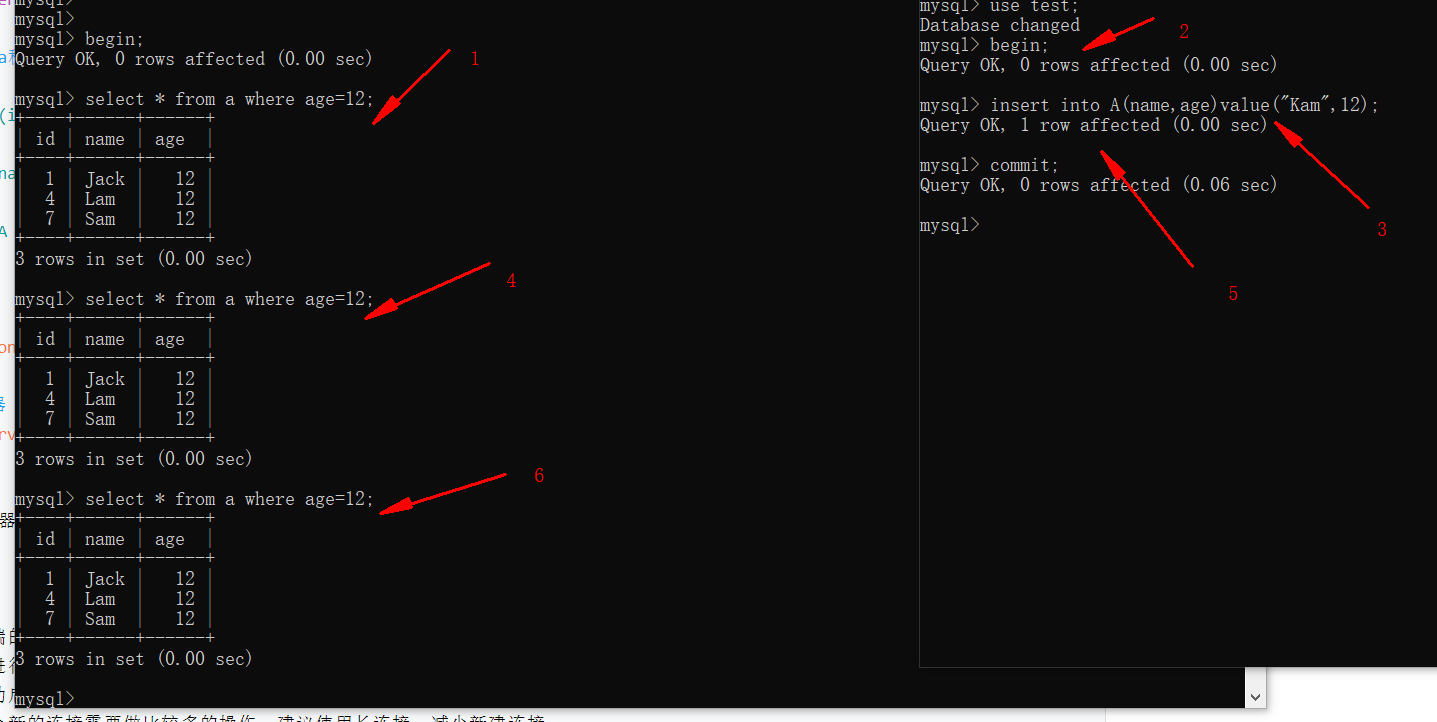
由上图可以看到,事务二提交后,事务一不论读取多少次,还是一样的结果。
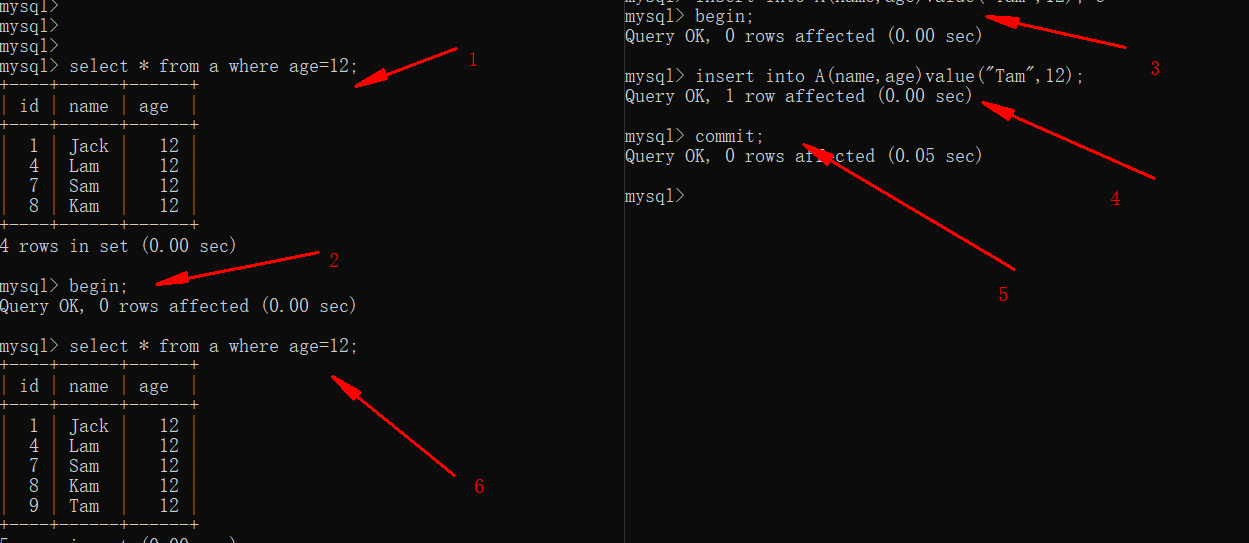
- 串行化
- 因为一般不使用,不做研究
隔离级别小结
- 在可提交读的隔离级别,每次查询都会返回当前记录上最新的值
- 在串行化的隔离级别,会在记录加锁,不允许其它事务访问。
- 在可提交读的隔离级别,每次查询会新建一个一致性视图,视图只能看到已经提交了事务的记录最新值
- 在可重复读隔离级别,第一次查询会新建一个一致性视图,直到该事务提交,所以只能看到视图创建时已经提交了事务的记录最新值,后续提交的事务记录就看不到了。
小结
- 不同隔离级别的查询,会导致结果不一样,所以需要注意数据库的隔离级别
- 查询涉及了MDL锁
问题
- 在可重复读的隔离级别,别的事务变更的记录存放到哪里了,自己的事务看到的记录是怎么来的
- 回滚是怎么做到的
- 为什么查询记录会读取整个数据页,而不是只读取对应的记录
- 优化器是怎么选择索引的
- 索引应该怎么建比较合适(普通索引,唯一索引,前缀索引,覆盖索引)
- select for update,select lock in share mode和普通查询机制一样么
- 出现锁的情况,怎么排查
- sql修改过程是怎么样的
- mysql还有哪些锁
- group by, order by语句查询过程是怎么样的
- 联表查询的过程是怎么样的
- mysql目前为什么默认的隔离级别是可重复读,设置别的隔离级别需要注意什么
- select count(*),count(id),count(1),count(字段)由什么区别
- where 条件字段使用聚合函数能否用到索引
- 从上面的实验看到主键id是不连续的,为什么会出现这种问题
未完待续...
