

需求场景

- 自动登录网站爬取信息
- 自动化用户操纵,可以帮助完成购买下单等等行为
- 页面自动化测试
核心解析
- 爬取信息个人认为分为两种
- 第一免登录的爬取百度出来的动物照片,或者其他不需要登录的一些官方网站发布的信息,实现思路无非是用服务端语言发送get网站地址的请求,通过正则匹配元素信息,获取有效信息,再加以利用。
- 第二登录型或者说是行为触发类型,不仅需要访问页面而且需要发生页面行为,例如登录购买。
技术解析
- 核心语言python,核心技术webdriver
- 下载python
- 安装python
- 在ide新建python项目文件
from selenium import webdriver # 从selenium导入webdriverimport osfrom selenium.webdriver.chrome.options import Optionsimport timeoptions = Options()pathB = os.path.abspath(os.path.dirname(__file__))pathRes = os.path.join(pathB,'chromedriver.exe') # 这里是你指定chromedriver.exe路径options.binary_location = os.path.join(pathB,'chrome','chrome.exe') # 这里是你指定浏览器的路径driver = webdriver.Chrome(executable_path=pathRes,chrome_options=options)driver.get('https://juejin.cn/post/6844904085674524685')driver.implicitly_wait(5)#这么等待是有问题的# 每n秒执行一次def timer(n): while True: # 找到登录按钮 login = driver.find_elements_by_class_name('login') if(len(login)>0): login[0].click() #登录弹窗 input = driver.find_elements_by_class_name('input') # 输入账号 input[0].send_keys("") # 输入密码 input[1].send_keys("") panel = driver.find_elements_by_class_name('panel') button = panel[0].find_elements_by_tag_name('button') button[0].click() #触发登录 # 延迟时间等待加载 driver.get('https://juejin.cn/post/6844904085674524685') driver.implicitly_wait(10) else: driver.get('https://juejin.cn/post/6844904085674524685') time.sleep(n)timer(5)# 每n秒执行一次- 打包 pyintsaller xx.py --noconfirm
- 项目路径
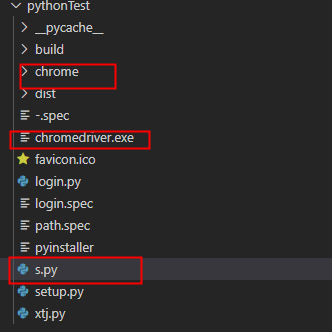
- 打包资源
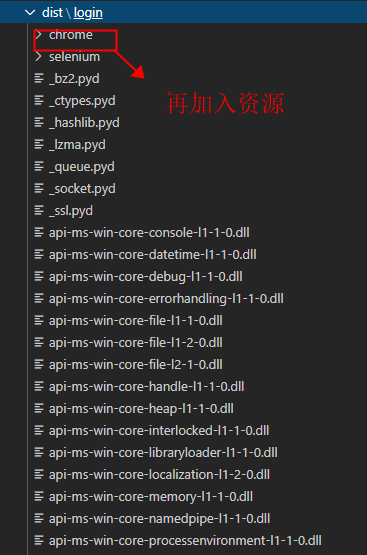
主要事项
- 一定一定一定要注意资源路径引用的问题
- 第一chromedriver.exe 一定要对应相应的谷歌浏览器版本
- 加载cchromedriver.exe和谷歌浏览器一定要在把这两个资源再放到打包出来的那个文件里面开发和打包时一定要适配这个资源路径。切记切记
后记
- 开发还好网上找找代码考一下啥的一定要注意打包
