

论文提出了结合注意力卷积的二叉神经树进行弱监督的细粒度分类,在树结构的边上结合了注意力卷积操作,在每个节点使用路由函数来定义从根节点到叶子节点的计算路径,结合所有叶子节点的预测值进行最终的预测,论文的创意和效果来看都十分不错
来源:晓飞的算法工程笔记 公众号
论文: Attention Convolutional Binary Neural Tree for Fine-Grained Visual Categorization

Introduction

细粒度分类(Fine-Grained Visual Categorization, FGVC)是图片分类的一个分支,由于类别间的相似性非常大,一般人比较难区分,所以是个很有研究意义的领域。受神经树研究的启发,论文设计了结合注意力卷积的二叉神经树结构(attention convolutional binary neural tree architecture, ACNet)用于弱监督的细粒度分类,论文的主要贡献如下:
- 提出结合注意力卷积的二叉神经树结构ACNet用于细粒度分类,在树结构的边上结合了注意力卷积操作,在每个节点使用路由函数从而定义从根节点到叶子节点的计算路径,类似于神经网络。这样的结构让算法有类似于神经网络的表达能力,以及能够从粗到细的层级进行特征学习,不同的分支专注于不同的局部区域,最后结合所有叶子节点的预测值进行最终的预测
- 添加attention transformer模块来加强网络获取关键特征进行准确分类
- 在三个数据集CUB-200-2011、Stanford Cars和Aircraft上达到了SOTA
#Attention Convolutional Binary Neural Tree
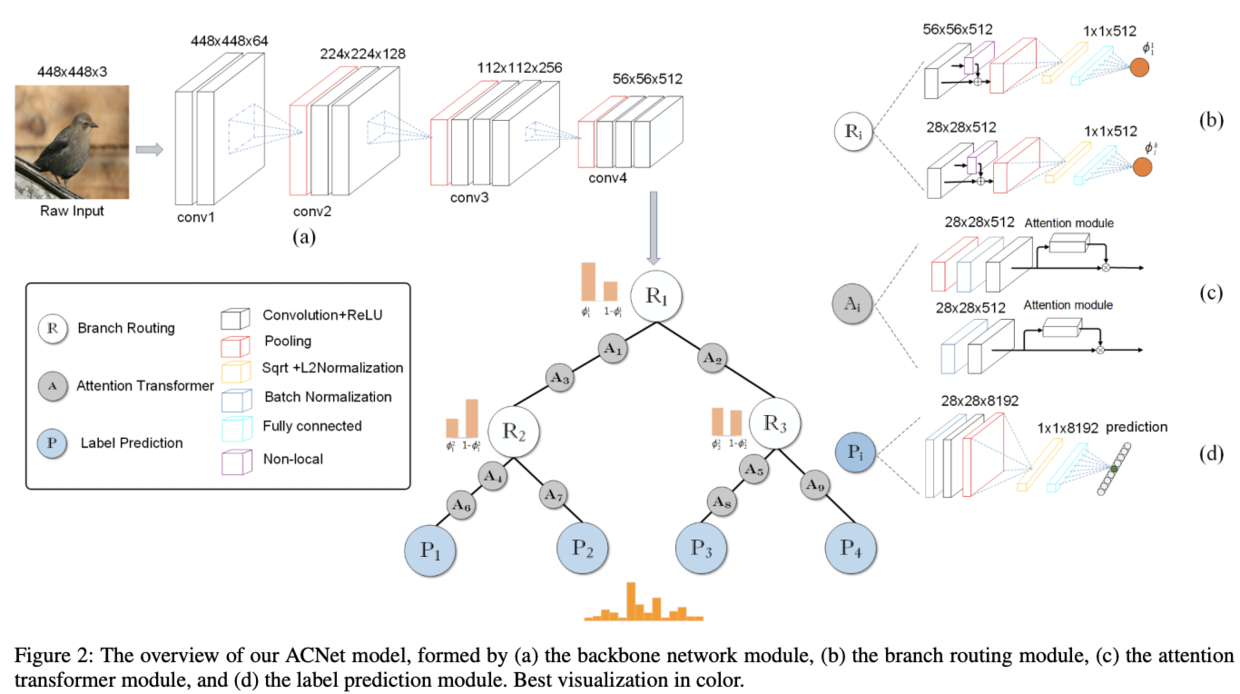
ACNet包含4个模块,分别是主干网络(backbone network)、分支路由(branch routing)、attention transformer和标签预测(label prediction),如图2所示。将ACNet定义为,
为树状拓扑结构,
为树边的操作集。论文使用满二叉树
,
为节点,
为边,对于树深
,共
节点,
边。每个节点为路由模块,决定下一个计算节点,边采用attention transformer进行操作。另外,满二叉树
采用了非对称结构,例如左边使用两个transformer模块,右边使用一个transformer模块,这样有利于提取不同尺寸的特征
Architecture
-
Backbone network module
由于细粒度类别的关键特征都是高度局部的,需要使用相对较小的感受域来提取特征,因此主干网络使用截断的VGG-16网络,输入改为
-
Branch routing module
分支路由用来决定子节点的选择,结构如图2b所示,-th层的
-th路由模块
由
卷积和global context block组成
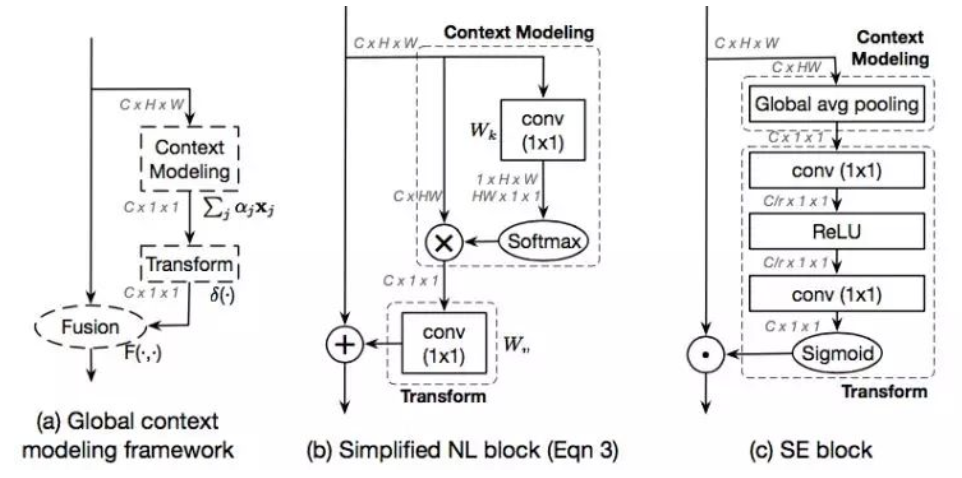
global context block的大概结构如上图a所示,来自GCNet的论文中。在context modeling和fusion步骤使用了simplified NL block,在transform步骤使用了SE block,这个模块能够很好地结合上下文信息来提取特征,最后使用global average pooling、element-wise square-root、L2正则化以及sigmoid激活的全连接层输出标量
假设分支路由模块输出样本
到右边节点的概率为
,则输出到左边节点的概率为
,概率越大的节点对最终结果的影响越大
-
Attention transformer
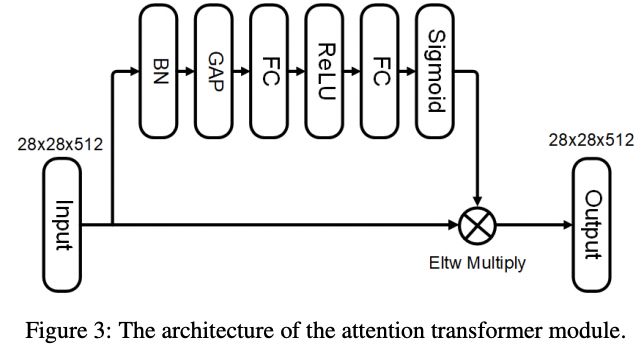
Attention transformer模块用于加强网络获取关键特征的能力,在卷积后面插入结构如图2c所示的attention模块,该模块的旁路输出一个大小为
的channel attention map对输入特征进行加权
-
Label prediction
对于ACNet的每个叶子节点,用标签预测模块来预测目标
的类别,
为目标
从根节点到k层第i个节点的累计概率,预测模块由
卷积层、max pooling层、L2归一化层、全连接层和softmax层组成,通过求和所有的叶子节点的预测结果和路径累计概率的乘积得到最终的预测
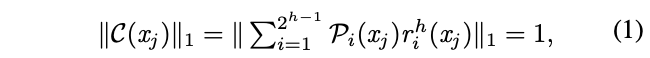
最终的预测结果的各项和为1,论文对其进行了证明,有兴趣的可以去看看,主要基于叶子节点的累计概率和为1,各叶子节点的预测结果和也为1
Training
-
Data augmentation
在训练阶段,使用裁剪和翻转操作进行数据增强,首先将图片缩放至短边512像素,然后随机裁剪到,随机进行翻转
-
Loss function
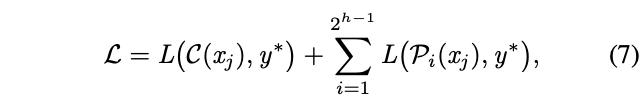
ACNet的损失函数由两部分组成,分别为叶子节点预测产生的损失以及最终结果产生的损失。为树高,
为GT,
为最终预测结果的负对数似然损失,
为第
个叶子预测结果的负对数似然损失
-
Optimization
主干网络使用在ILSVRC上预训练的模型,使用"xavier"进行所有卷积层的随机初始化,整个训练过程包含两阶段,第一阶段固定主干网络训练60周期,第二阶段则使用小学习率对整个网络进行200周期的fine-tune
Experiments
训练共需要512G内存,8张V100,下面的实验主要跟弱监督的细粒度算法进行对比,即不需要额外的标注的细粒度算法
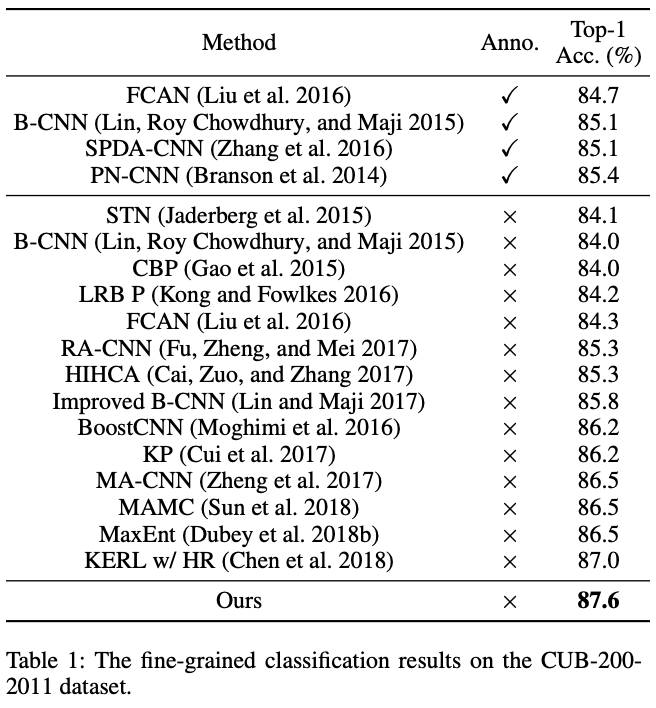
CUB-200-2011 Dataset
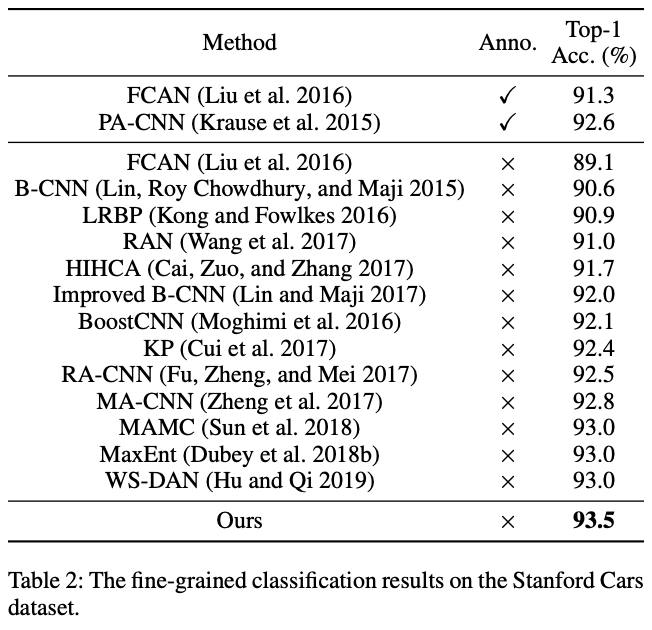
Stanford Cars Dataset
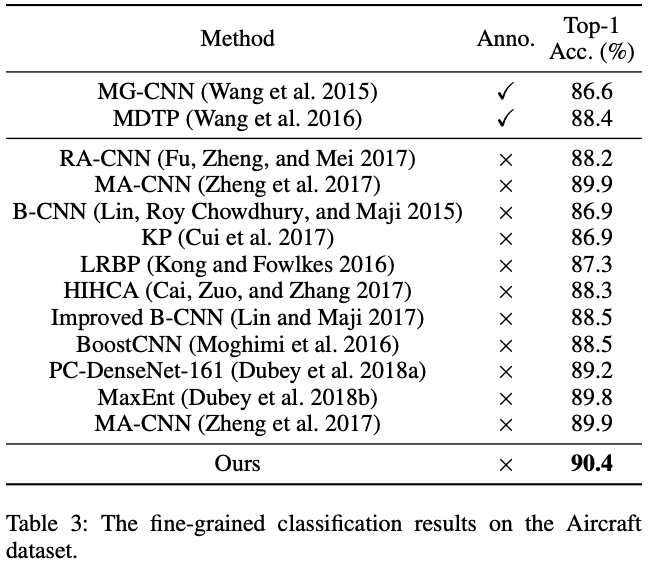
Aircraft Dataset
Ablation Study
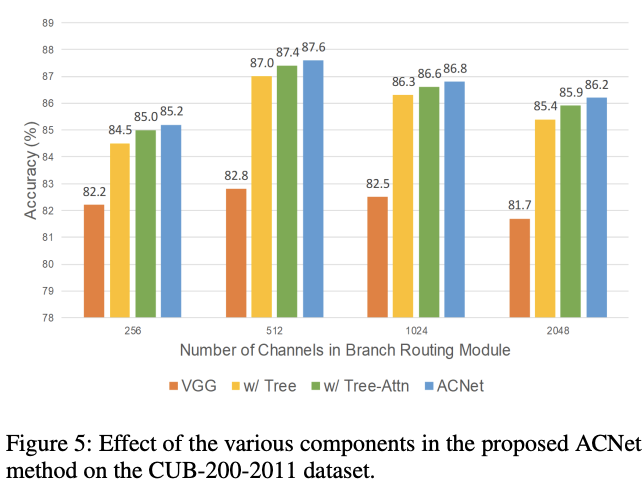
-
Effectiveness of the tree architecture

如图5所示,使用树状结构能够显著提升准确率,使用Grad-CAM产生heatmap来对叶子节点对应的响应区域进行可视化,发现不同的叶子节点关注的特征区域各不一样
-
Height of the tree
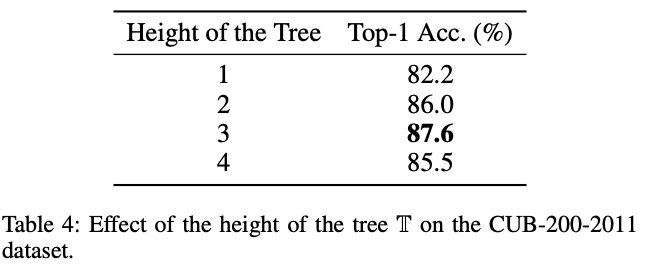
-
Asymmetrical architecture of the tree

论文对比左右路径的attention transformer数的对称性对识别的影响
-
Effectiveness of the attention transformer module
如图5所示,attention transformer模块能够有效地提升模型的准确率
-
Components in the branch routing module


论文发现不同的分支路由模块关注的特征区域也不一样,图6的可视化结果分别为图2的R1、R2和R3节点使用Grad-CAM得到的响应区域
CONCLUSION
论文提出了结合注意力卷积的二叉神经树进行弱监督的细粒度分类,在树结构的边上结合了注意力卷积操作,在每个节点使用路由函数来定义从根节点到叶子节点的计算路径,结合所有叶子节点的预测值进行最终的预测,论文的创意和效果来看都十分不错
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

