

以往认知的最左侧匹配是这样的:如果表有3个字段作为联合索引(a,b,c)
我们会认为以下几种会使用到索引,其他情况是不会使用到的:
where a=1
where a=1 and b=2
where a=1 and b=2 and c=3
那事实是不是这样呢?我们验证一下。
我们新建一张表:
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`age` int(11) NOT NULL DEFAULT '0',
`height` int(11) NOT NULL,
`weight` int(11) NOT NULL DEFAULT '0',
`name` varchar(32) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `idx_obj` (`age`,`height`,`weight`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;总共5个字段,(`age`,`height`,`weight`)建了个联合索引。
第一种情况 where age = 1
EXPLAIN SELECT * FROM `user` WHERE age = 1;结果如图:
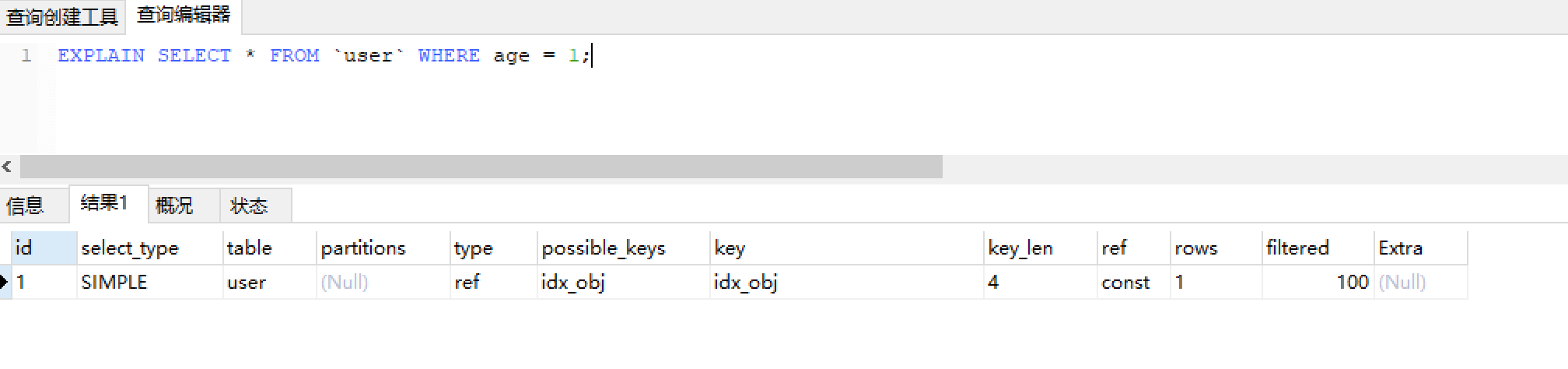
我们看到这种情况使用到索引了,这个没有问题。
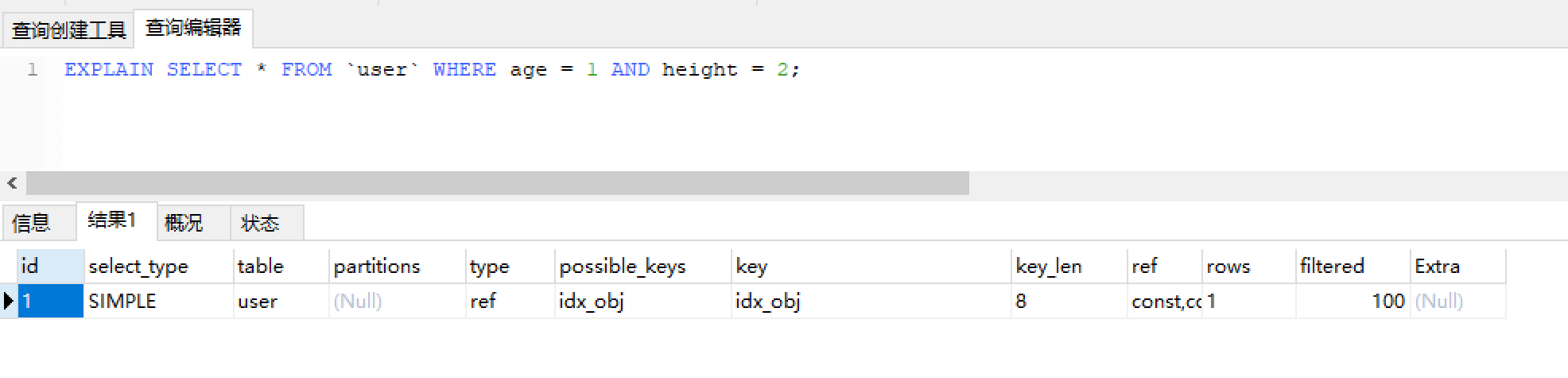
第二种情况WHERE age = 1 AND height = 2
EXPLAIN SELECT * FROM `user` WHERE age = 1 AND height = 2;结果如图:
第三种情况WHERE age = 1 AND height = 2 AND weight = 3
EXPLAIN SELECT * FROM `user` WHERE age = 1 AND height = 2 AND weight = 3;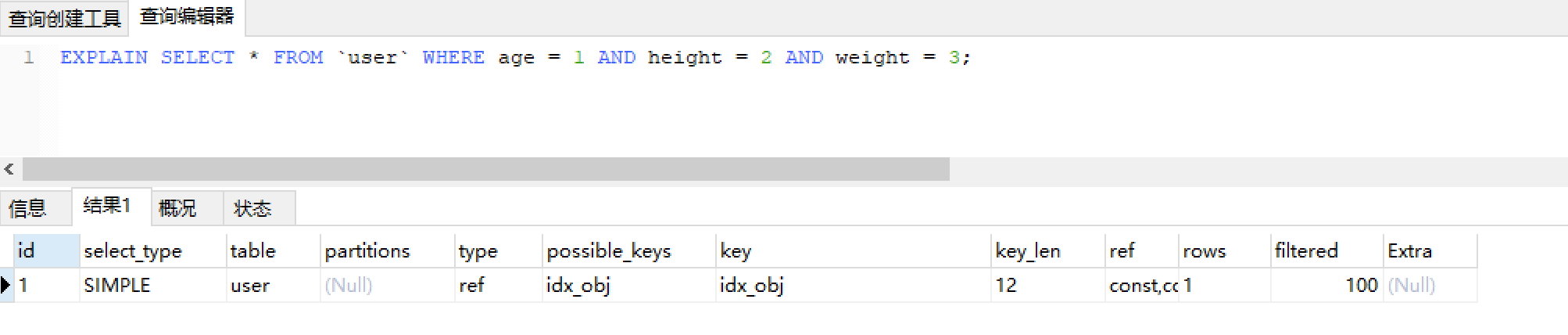
第四种情况WHERE age = 1 AND weight = 3
EXPLAIN SELECT * FROM `user` WHERE age = 1 AND weight = 3;
这种情况居然也是走索引的,要解释这个情况,需要通过B+树,具体可以参考这篇文章
假如我们数据表里面的数据是下图所示:
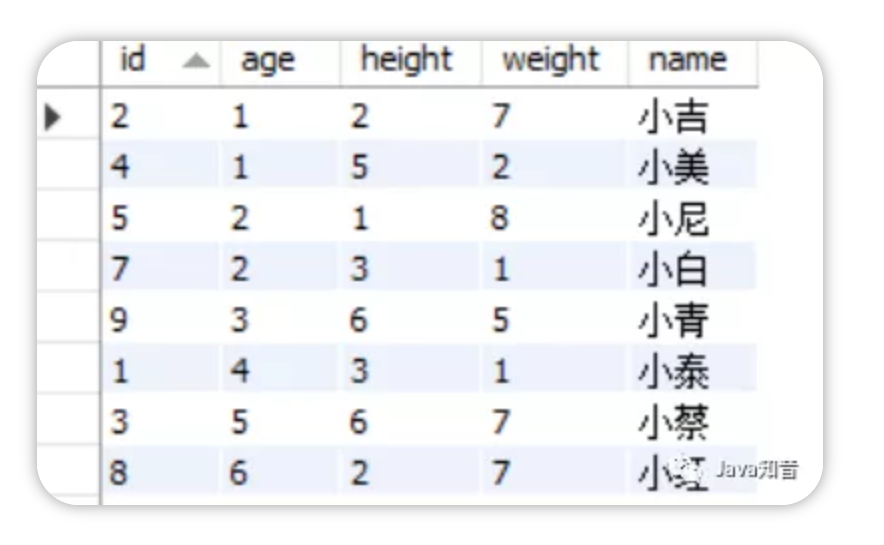
那么B+树是这样的:
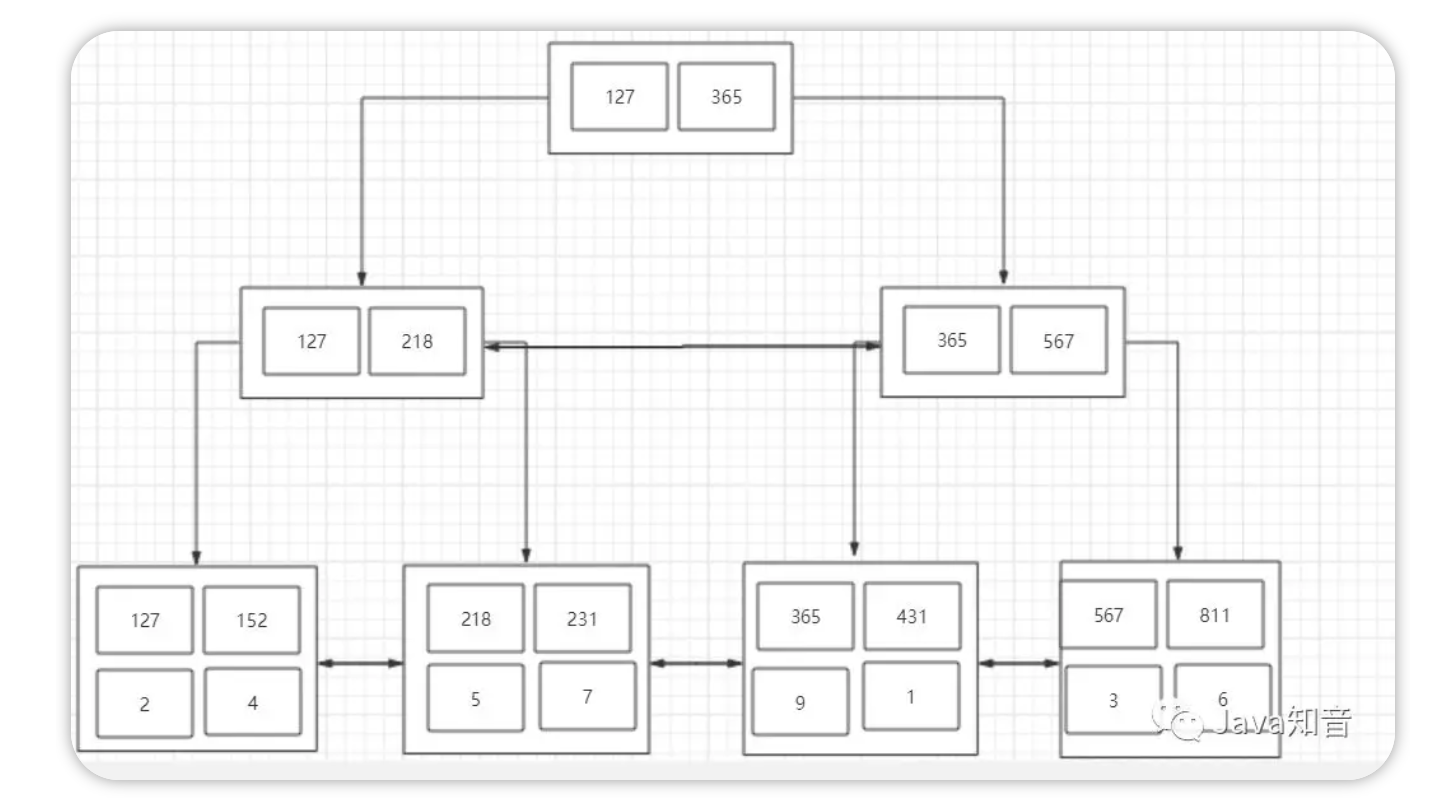
所以这条语句也是可以走ind_obj索引的,因为它也可以通过比较(1?7<365),走左子树,但是实际上weight并没有用到索引,因为根据最左匹配原则,如果有两页的age都等于1,那么会去比较height,但是height在这里并不作为查询条件,所以MySQL会将这两页全都加载到内存中进行最后的weight字段的比较,进行扫描查询
第四种情况WHERE age=1 and height>2 and weight=7
EXPLAIN SELECT * FROM user WHERE age=1 and height>2 and weight=7;
这条语句是可以走索引的,因为它可以通过age进行比较,但是weight不会用到索引,因为height是范围查找,与第二条语句类似,如果有两页的height都大于2,那么MySQL会将两页的数据都加载进内存,然后再来通过weight匹配正确的数据。
第五种情况WHERE height=2 and weight = 7
EXPLAIN SELECT * FROM user WHERE height=2 and weight = 7
我们都知道这种情况是不走索引的,使用B+树解释是这样的:
上文中我们提到了一个多列的排序原则,是从左到右进行比较然后排序的,而我们的idx_obj这个索引从左到右依次是age,height,weight,所以当我们使用height和weight来作为查询条件时,由于age的缺失,那么就无法从age来进行比较了。
看到这里可能有小伙伴会有疑问,那如果直接用height和weight来进行比较不可以吗?
显然是不可以的,可以举个例子
我们把缺失的这一列写作一个问号,那么这条语句的查询条件就变成了?27,那么我们从这课B+树的根节点开始,根节点上有127和365,那么以height和weight来进行比较的话,走的一定是127这一边,但是如果缺失的列数字是大于3的呢?比如427,527,627,那么如果走索引来查询数据,将会丢失数据,错误查询。所以这种情况下是绝对不会走索引进行查询的。这就是最左前缀匹配原则的成因。
所以得出:
最左前缀匹配原则,MySQL会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配
=和in可以乱序,比如 a=1 and b=2 and c=3 建立(a,b,c)索引可以任意顺序,MySQL的查询优化器会帮你优化成索引可以识别的形式。
根据我们了解的可以得出结论:
只要无法进行排序比较大小的,就无法走联合索引。
- WHERE height=2 and weight //不走索引,因为缺失第一个age,最左侧原则,前面的字段有序了,后面才可以有序,现在第一个没有了自然后面无序了
- WHERE height=2 and weight = 7 AND age = 9 //走索引 虽然和(`age`,`height`,`weight`)顺序不一样,但是MySQL的查询优化器会帮你优化成索引可以识别的形式。
- WHERE age=1 //走索引 age是第一个【联合索引第一个字段肯定是有序的】 可以比较大小
- WHERE height = 2 ///不走索引,因为缺失第一个age,最左侧原则,前面的字段有序了,后面才可以有序,现在第一个没有了自然后面无序了
- WHERE weight = 6 ///不走索引,因为缺失第一个age,最左侧原则,前面的字段有序了,后面才可以有序,现在第一个没有了自然后面无序了
以上是一个小小的总结,其实还有一种特殊情况,就是表的字段都在联合索引里面除主键之外。比如:
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`age` int(11) NOT NULL DEFAULT '0',
`height` int(11) NOT NULL,
`weight` int(11) NOT NULL DEFAULT '0',
PRIMARY KEY (`id`),
KEY `idx_obj` (`age`,`height`,`weight`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;区别第一张表就是少了name字段
EXPLAIN SELECT * FROM `user` WHERE weight = 9; //走索引
EXPLAIN SELECT * FROM `user` WHERE height = 9; //走索引
参考文章:
