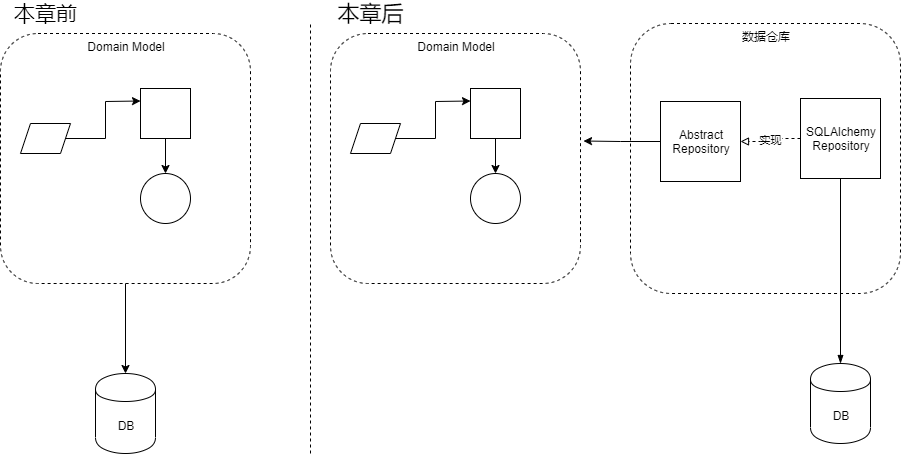
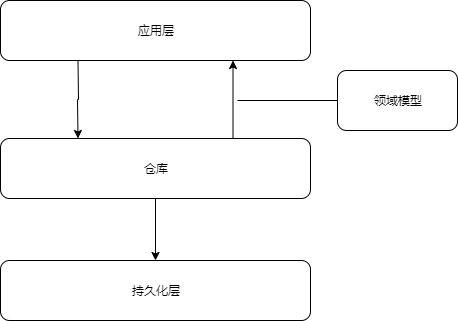
是时候将我们的模型进行持久化了,我们要以依赖反转的原则将我们的核心逻辑与像数据库这样的基础设施问题中分离出来。
我们将介绍Repository(仓库模式),他是对数据存储的抽象,允许我们将模型和数据层解耦。我们也将介绍仓库模式如何通过隐藏数据库的复杂性,让我们的系统更容易测试。
维护存粹的领域模型
在第一章中,我们建立了一个简单的领域模型,我们可以将订单分配给采购批次。我们和容易对他们进行测试,因为我们没有任何外部基础设施的依赖。但是我们需要运行数据库或API并创建测试数据,那我们的测试就非常难以编写和维护。
不辛的是,在现实世界中,我们需要将我们这么漂亮的小模型交到用户手上。他们必须与浏览器,电子表格交互。在接下来的文章中,我们将讨论如何将我们完美的小模型连接到外部系统中。
我们希望以敏捷开发的方式工作,所以我们的首要任务是尽快得到最小可行的产品。在我们的例子中,这将是一个web接口,我们会进行一些端到端测试,然后再用一个web框架在外部进行测试。
现在我们知道,我们无论如何都需要某种形式的持久化存储。现在我们可以一点一点的自下而上的进行开发,并开始考虑如何存入数据库。
我们需要什么?
当我们开始构建一个API时,我们知道会有一些代码看起来像这样
@flask.route.gubbins
def allocate_endpoint():
# 从表单中获取OrderLine
line = OrderLine(request.params, ...)
# 从数据库中找到我们想要的采购批次
batches = ...
# 我们调用我们的服务函数
allocate(line, batches)
# 将我们的模型保存回数据库
return 201
OK,也就是说我们需要一种从数据库检索我们采购批次的信息并实例化我们的领域模型的方法,还需要一种将它们保存回数据库的方法。
将依赖倒置原则应用于数据访问
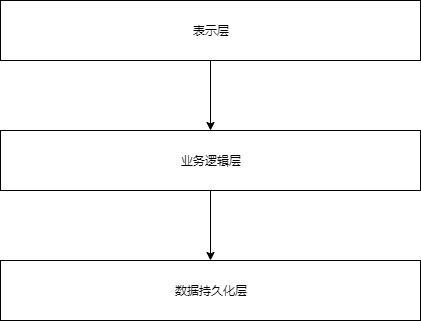
正如我们再序章中所提到的,我们所谓的MVC分层,比如Django的MVC结构,每一层仅仅只依赖于下一层,
但是我们希望我们的领域模型跟基础设施没有任何依赖关系,我们希望他能够保持存粹。我们不希望基础设施上的问题渗透到我们的领域模型中,从而破坏我们单元测试或者我们对其更改的能力。而是向我们开头讨论的,我们认为我们的模型应该位于我们服务层的"内部",数据层的依赖应该逆向的流向模型。这种我们一般称之为“洋葱架构”
如果你一听?什么?洋葱架构?这是一个接口和适配器吗?好像有人叫六边形架构?为什么你们会有这么多听起来酷炫的名词?我们虽然这里介绍DDD,但我们也在这里不讨论什么架构模式。其实这些酷炫的名词都只有一个--依赖倒置:高级模块(领域)不应依赖于低级模块(基础设施)。
我们的模型
让我们看看我们之前的模型,我们有一个_allocations的字段,它是一个set来保存我们所有分配好的订单行
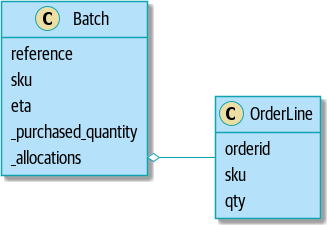
我们先想一下,这东西用Mysql这样的关系型数据库去表达,emm,这很简单,我们再熟悉不过了,不就是个一对多。
普通基于ORM的模型
有很多团队已经不需要自己去手动使用SQL进行查询了。他们使用了某种框架提供模型对象来帮你写SQL,这就是我们大名鼎鼎的ORM。它们就是为弥合对象与关系型数据库之间的鸿沟。ORM给我们带来好处就是,我们的模型不需要知道数据是如何加载和持久化的。这清除了我们模型和某种数据库的直接依赖。很多ORM支持至少一种数据库。比如我们大名鼎鼎的Sqlalchemy。如果你是根据某些经典的Sqlalchemy教程,你一定会这么写你的模型
from sqlalchemy import Column, ForeignKey, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import relationship
Base = declarative_base()
class Order(Base):
id = Column(Integer, primary_key=True)
class OrderLine(Base):
id = Column(Integer, primary_key=True)
sku = Column(String(250))
qty = Integer(String(250))
order_id = Column(Integer, ForeignKey('order.id'))
order = relationship(Order)
class Allocation(Base):
...
如果你并不了解Sqlalchemy,其实也没有关系,但是你一样能看出,我们的模型已经被ORM的依赖填的满满的。这真的我们的模型真的忽略了数据库吗?我们每个字段都耦合了数据库的列。那我们如何将它与存储分离开?
当然如果你习惯使用Django,本质也是一样的。而且限制更多,大概像这样的
class Order(models.Model):
pass
class OrderLine(models.Model):
sku = models.CharField(max_length=255)
qty = models.IntegerField()
order = models.ForeignKey(Order)
class Allocation(models.Model):
不管是什么,都有一个共同的特点,我们的模型直接继承自ORM,而我们并不希望如此。
反转依赖关系:ORM应该依赖于模型
其实Sqlalchemy不止这一种使用方法。还有一种显式的映射器,将我们的数据库表与我们的模型进行转换。可以看这里的文档
from sqlalchemy.orm import mapper, relationship
import model #(1)
metadata = MetaData()
order_lines = Table( #(2)
'order_lines', metadata,
Column('id', Integer, primary_key=True, autoincrement=True),
Column('sku', String(255)),
Column('qty', Integer, nullable=False),
Column('orderid', String(255)),
)
...
def start_mappers():
lines_mapper = mapper(model.OrderLine, order_lines) #(3)
我们看到这样做我们做到了
-
ORM导入了我们的领域模型,而不是领域模型继承ORM
-
我们使用Sqlalchemy的方法定义了数据库表和列
-
当我们调用了
start_mappers时,Sqlalchemy会将我们的领域模型绑定到定义好的数据库表
那么,如果我们调用了start_mappers,我们能够轻松的从数据库中加载和保存领域模型实例。但是如果我们从来不调用这个函数,我们的领域模型也从来不知道有数据库的存在。
同样的,我们一样能享受到Sqlalchemy的所有好处,包括Sqlalchemy的迁移能力,以及简洁的查询能力。
当我们尝试构建ORM时,也许写个测试比较重要。
def test_orderline_mapper_can_load_lines(session): #(1)
session.execute(
'INSERT INTO order_lines (orderid, sku, qty) VALUES '
'("order1", "RED-CHAIR", 12),'
'("order1", "RED-TABLE", 13),'
'("order2", "BLUE-LIPSTICK", 14)'
)
expected = [
model.OrderLine("order1", "RED-CHAIR", 12),
model.OrderLine("order1", "RED-TABLE", 13),
model.OrderLine("order2", "BLUE-LIPSTICK", 14),
]
assert session.query(model.OrderLine).all() == expected
def test_orderline_mapper_can_save_lines(session):
new_line = model.OrderLine("order1", "DECORATIVE-WIDGET", 12)
session.add(new_line)
session.commit()
rows = list(session.execute('SELECT orderid, sku, qty FROM "order_lines"'))
assert rows == [("order1", "DECORATIVE-WIDGET", 12)]
当然这些测试其实没什么用,也没有保留的必要,接下来我们会看到,一旦采取了反转依赖的ORM和领域模型。我们到时候去实现一个仓库模式时,我们仅仅只需要小小的步骤,就会更容易编写测试。我们的数据也更容易被伪造。
到此为止呢,我们达到了颠覆传统ORM依赖性的目的,我们领域模型不再受到基础设施的影响。我们可以抛弃Sqlalchemy,使用一个不同的ORM,或者一个完全不同的数据库也是可以的。
那么现在,我们的API可能像下面这样
@flask.route.gubbins
def allocate_endpoint():
session = start_session()
# extract order line from request
line = OrderLine(
request.json['orderid'],
request.json['sku'],
request.json['qty'],
)
# load all batches from the DB
batches = session.query(Batch).all()
# call our domain service
allocate(line, batches)
# save the allocation back to the database
session.commit()
return 201
仓库模式
仓库模式是的持久化存储的抽象。它隐藏了数据访问的细节。就好像我们数据都在内存中一样。
比如我们的笔记本有无限的内存,我们就不需要数据库了,我们可以随时随地的使用我们的数据。就好下下面这个样子
import all_my_data
def create_a_batch():
batch = Batch(...)
all_my_data.batches.add(batch)
def modify_a_batch(batch_id, new_quantity):
batch = all_my_data.batches.get(batch_id)
batch.change_initial_quantity(new_quantity)
你看,我们取数据时,就像内存中查找一样,我们往里面加数据时,也像对待一个列表或者集合一样。我们不需要调用save方法,我们只需要获取我们关心的对象,也可以像内存中一样修改它。
抽象的仓库
一个最简单的仓库只有两个方法add():将新的数据存入数据库, get()查找我们之前存入的数据。我们一定要坚持在我们的领域服务层使用这些方法进行数据访问。这种简单的组织,防止了我们领域模型与数据库进行耦合。
class AbstractRepository(abc.ABC):
@abc.abstractmethod #(1)
def add(self, batch: model.Batch):
raise NotImplementedError #(2)
@abc.abstractmethod
def get(self, reference) -> model.Batch:
raise NotImplementedError
提示:
-
这里我们使用@abc,这是一个标准的抽象基类的方法,这个东西可以帮助你在程序运行时不能被实例化。
-
增加了
raise NotImplementedError是一个好办法,虽然也没什么必要。但至少可以一眼看出这是一个抽象的基类。 -
其实你可以直接用鸭子类型来表达抽象基类,这完全没有问题。我更建议用鸭子类型去表达这种事。这里这么写是希望能够明确的说明,一个仓库的抽象接口是什么。
权衡利弊
小孩子才谈对错,成年人只谈利弊
我们每次看到新的架构或者新的框架时,甚至我们向同事们讲解架构的时候,大家都会问:我们得到了多少好处?我们又为这种好处付出了什么样的代价?
每当我们引入一个抽象层,我们可能希望它总体上降低了复杂度,但也一定会增加局部的复杂度。比如我们的模型,本来我们使用传统的ORM,我们只需要修改一次模型就可以完成映射,现在可能需要在模型和Table定义那里都进行修改。所以,从维护的角度看,这么做其实是有成本的。当然做任何事都是有成本的。
如果您已经再遵循DDD和依赖倒置原则的话,仓库模式会是我整个专栏中最简单的选择之一。从代码层面上来讲,我们实际上只是将Sqlalchemy抽象方法(session.query(Batch))变成了仓库的不同的抽象方法。每次想要添加查找新的领域对象时,我们都必须在仓库类中编写几行代码,作为回报,我们在存储层上得到了一个完全由我们控制的抽象。这样使得我们在单元测试中很容易进行伪造。
此外,仓库模式在DDD中非常常见,如果你跟Java程序员有过交流的话,他们很快就能认出来。
还像以前一样,我们先从测试开始。这可能被归类为集成测试。因为我们正在检查我们的代码与数据库是否正确继承。这里的测试倾向将原始SQL与我们的代码调用混在一起
与之前的ORM测试不同,这里的测试适合和代码库长期保留。因为这里意味着我们的模型是否正确与数据库映射
def test_repository_can_save_a_batch(session):
batch = model.Batch("batch1", "RUSTY-SOAPDISH", 100, eta=None)
repo = repository.SqlAlchemyRepository(session)
repo.add(batch) #(1)
session.commit() #(2)
rows = list(session.execute(
'SELECT reference, sku, _purchased_quantity, eta FROM "batches"' #(3)
))
assert rows == [("batch1", "RUSTY-SOAPDISH", 100, None)]
-
repo.add()在这里时测试方法。 -
我们在仓库外进行
commit(),并使之成为调用方的责任。这样有利也有弊;之后我们会对这个问题进行讨论。 -
我们用原始SQL来验证实在保存了正确的数据。
接下来的测试我们涉及到了查询采购批次和分配方法,所以它更加复杂
def insert_order_line(session):
session.execute( #(1)
'INSERT INTO order_lines (orderid, sku, qty)'
' VALUES ("order1", "GENERIC-SOFA", 12)'
)
[[orderline_id]] = session.execute(
'SELECT id FROM order_lines WHERE orderid=:orderid AND sku=:sku',
dict(orderid="order1", sku="GENERIC-SOFA")
)
return orderline_id
def insert_batch(session, batch_id): #(2)
...
def test_repository_can_retrieve_a_batch_with_allocations(session):
orderline_id = insert_order_line(session)
batch1_id = insert_batch(session, "batch1")
insert_batch(session, "batch2")
insert_allocation(session, orderline_id, batch1_id) #(3)
repo = repository.SqlAlchemyRepository(session)
retrieved = repo.get("batch1")
expected = model.Batch("batch1", "GENERIC-SOFA", 100, eta=None)
assert retrieved == expected # Batch.__eq__ only compares reference #(3)
assert retrieved.sku == expected.sku #(4)
assert retrieved._purchased_quantity == expected._purchased_quantity
assert retrieved._allocations == {
model.OrderLine("order1", "GENERIC-SOFA", 12),
} #(4)
是否要为每个模型编写测试是一个权衡利弊的过程。如果你的大部分类都遵循类似的过程。那么只需要做一些最小测试也可以不写测试。我们这里因为_allocations方法有点复杂,所以还是需要一些特定的测试
现在我们继续编写我们的仓库,大概像这样
class SqlAlchemyRepository(AbstractRepository):
def __init__(self, session):
self.session = session
def add(self, batch):
self.session.add(batch)
def get(self, reference):
return self.session.query(model.Batch).filter_by(reference=reference).one()
def list(self):
return self.session.query(model.Batch).all()
我们的WEB接口应该时像这样
@flask.route.gubbins
def allocate_endpoint():
batches = SqlAlchemyRepository.list()
lines = [
OrderLine(l['orderid'], l['sku'], l['qty'])
for l in request.params...
]
allocate(lines, batches)
session.commit()
return 201
这里我们可能会问,已经抽象到这个地步了,我们似乎不需要ORM了,因为ORM和仓库模式都充当了抽象角色,因此在有了一个抽象之后使用另一个并不是真正必要的。为什么不使用ORM的情况下实现仓库模式呢?
其实只要我们离开了仓库,至于怎么编写SQL不是那么重要,有可能使用ORM更容易,也有可能使用SQL更容易,这并不是绝对的。因为,应用程序的其他部分并不在乎这些。我们只是需要模型罢了。
创建一个假仓库用来测试
下面我们介绍一下仓库模式最大优点
class FakeRepository(AbstractRepository):
def __init__(self, batches):
self._batches = set(batches)
def add(self, batch):
self._batches.add(batch)
def get(self, reference):
return next(b for b in self._batches if b.reference == reference)
def list(self):
return list(self._batches)
在测试中使用假仓库会使测试非常简单,我们有一个简单的抽象,让它易于使用
fake_repo = FakeRepository([batch1, batch2, batch3])
下一章我们就会使用到它了。到时候我们再看看有什么用。
这里还是要简单说一下,为抽象构建假对象是用来测试是帮助快速反馈的绝佳设计,如果你的抽象非常难以伪造,那么抽象过于复杂。应该重构。
在Python中的接口是什么?什么是抽象基类?什么是适配器
可能没有接触过类似Java或者Go这样语言的人,并不知道接口究竟什么。毕竟这个概念来自于OOP概念。我这里不想讨论太多关于OOP的理论术语或者设计模式。我们关注的还是依赖倒置。而使用技术的具体细节并不太重要。我们这里只是简单介绍一下
适配器是一个设计模式,这里不讲太多也没必要。
接口概念是来自OOP的世界,我们坚持定义接口是我们程序和我们抽象出来的东西之间有一个约定。对于调用方并不关心一个方法究竟是怎么实现的。我们只想知道这个方法能给我们带来什么。因为Python中没有接口的定义,所以定义接口可能会有些奇怪,如果我们使用的抽象基类,那它就是接口。如果不是,那么接口遵循鸭子类型--函数名和正在使用的方法名,以及他们的参数签名及类型。简单说,AbstractRepository就是我们的接口,而SqlAlchemyRepository 和FakeRepository是我们适配器。
总结
小孩才分对错,成年人只谈利弊,我们介绍的每种模式都会有成本和收益。我也不是说我们每个程序都必须像这样搭建。只是有时候程序的复杂性使得投入时间和精力去添加这些额外的间接层是非常值得的。这里我们来谈谈使用仓库模式的优缺点
| 优点 | 缺点 |
|---|---|
| - 在持久化层和领域模型层之间有一个简单的接口 | 一个ORM已经为你带来了一些解耦的方法, |
| 为单元测试制作一个假的仓库非常容易,或者换出不同的数据库方案也很容易,因为我们已经将模型与基础设施问完全分离 | 手动维护表与对象的映射很麻烦 |
| 在考虑到持久化之前编写领域模型有助于我们关注于业务问题而不是表。如果我们想要改变什么,我们可以直接在模型上做,而不需要担心数据库的事情 | 任何额外的间接层都会增加额外的维护成本,也会让那些没见过仓库模式的程序员说一句”卧槽“ |
| 我们的数据库表可以非常简单,因为我们可以完全控制如何将对象映射到表 |
这里虽然有些重复,但我还是想强调,究竟是使用ORM还是使用仓库模式,没有一个绝对的概念,从某种意义上说,即使使用ORM也是符合依赖倒置原则的。这与直接依赖硬编码SQL有本质的不同,我们本来就依赖一个抽象,这个抽象就是ORM本身。但是很多时候ORM不够用。但无论用什么都不应该依赖一个硬编码的SQL!依赖一个硬编码的SQL,你的复杂度会成倍升高,而你的易测性几乎没有。如果你的应用程序仅仅只是简单的CRUD,没有特别复杂的领域概念,那么你完全不需要一个仓库模式,反之,则需要,比如说你的模型可能来自不同的表,也可能你的模型来自于一个垂直拆分的表。仓库模式就是用来做这些ORM无法或难以屏蔽数据库复杂性的事情的。 简单说,如果你的领域越复杂,那么从基础设施中解放出来的投资越就越值得。
现在我们的的架构应该是这样的了