案例一 爬取网页
项目中新建index.js,打开终端,安装package.json文件
npm init -y
安装express,requests包
npm i express requests
通过fs.writeFile将文件保存:
fs.writeFile(file, data[, options], callback)
let requests = require('requests')
let fs = require('fs')
requests('https://www.jsdaima.com/js/demo/1358.html')
.on('data',function(chunk){
fs.writeFile('index.html',chunk,function(){
console.log('save successfully')
})
})
终端执行node index.js,如下为爬出来的index.html
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, minimum-scale=1.0, maximum-scale=1.0">
<title>上下左右无缝滚动jQuery插件_在线演示_广告/滚动_js特效_js代码</title>
<meta name="keywords" content="上下左右,无缝滚动,jQuery插件" />
<meta name="description" content="上下左右无缝滚动jQuery插件下载。实现上下左右自动滚动、无缝滚动。" />
<meta name="author" content="js代码" />
<meta name="copyright" content="js代码" />
<style>
* {
margin: 0px;
padding: 0px;
font-family: "微软雅黑";
}
html,
iframe,
body {
height: 100%
}
.none {
display: none !important
}
@media screen and (max-width: 640px) {
#mobileFrame {
display: none !important;
}
}
#hidemobile {
font-size: 14px;
font-weight: bold;
border: 1px solid silver;
position: absolute;
right: 20px;
top: 8px;
width: 15px;
height: 15px;
text-align: center;
padding: 0;
line-height: 15px;
border-radius: 15px;
cursor: pointer;
}
</style>
<script type="text/javascript" src="/static/js/protect.js"></script>
</head>
<body><iframe src="https://www.jsdaima.com/Uploads/js/201803/1522376449/index.html" frameborder="0" width="100%"
height="100%"></iframe></body>
</html>
可以看出他是通过iframe嵌入了一个页面,所以我们要再次爬取https://www.jsdaima.com/Uploads/js/201803/1522376449/index.html
let requests = require('requests')
let path = require('path')
let fs = require('fs')
requests('https://www.jsdaima.com/Uploads/js/201803/1522376449/index.html')
.on('data',function(chunk){
fs.writeFile('index.html',chunk,function(){
console.log('save successfully')
})
})
最终index.html爬取成功,另外我们通过他的代码看出还需要如下文件,jquery我们可以通过BootCDN得到
<script type="text/javascript" src="/static/js/jquery-1.10.2.mins.js"></script>
<link rel="stylesheet" href="css/demo.css"/>
<script src="js/rollslide.js"></script>
根据文件的路径修改src
let requests = require('requests')
let path = require('path')
let fs = require('fs')
requests('https://www.jsdaima.com/Uploads/js/201803/1522376449/css/demo.css')
.on('data',function(chunk){
fs.writeFile('demo.css',chunk,function(){
console.log('save successfully')
})
})
同理得到js文件
案例二 爬取网页html文件中script中的数据
目的:爬取丁香园上的疫情数据
从丁香园的网页上可以看到,他的数据是放在html的script里面,而不是ajax请求出来的。

每个script上面都有一个单独的id,借助npm的cheerio得到需要的script
//终端安装
npm install cheerio
//使用cheerio
var cheerio = require('cheerio'),
const $ = cheerio.load(chunk)
可以看到疫情数据是放在window对象的getAreaStat属性下的,node是没有window的,所以需要新增一个window对象,这样当取得数据是,保存在window对象上不会报错
let window={}
cheerio爬取出来的是字符串,需要用eval将它转为js执行(eval的作用是将字符串当成js执行)
eval($('#getAreaStat').html())
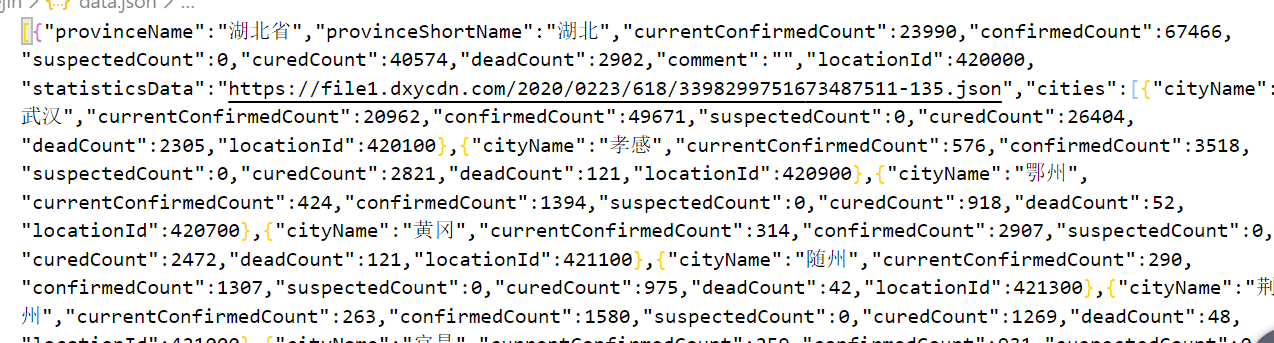
将window下的getAreaStat转为JSON 字符串保存在data.json,如下为全部代码
let requests = require('requests')
let fs = require('fs')
let cheerio = require('cheerio')
requests('https://ncov.dxy.cn/ncovh5/view/pneumonia_peopleapp?from=timeline&isappinstalled=0')
.on('data',function(chunk){
let window={}
const $ = cheerio.load(chunk)
eval($('#getAreaStat').html())
//将window下的getAreaStat转为JSON 字符串保存在data.json
fs.writeFile('data.json',JSON.stringify(window.getAreaStat),function(){
console.log('save successfully')
})
})
获取成功