

应用场景:
小米新品抢购活动,新品实际库存数量30万,页面上显示抢购倒计时,剩余库存数;
目标:
1、支持10万用户同时并发抢购;
2、服务器指标:99.9%的响应时间必需在30ms之内,平均响应时间在20ms左右,100%的请求成功;
运行环境:
服务器:ECS服务器 8核8G
数据库:PolarDB-MYSQL 8.0 4核16GB
KV数据库:REDIS 5.0 8G主从版
语言:Go 1.13
商品goods表结构:
| 字段 | 描述 |
|---|---|
| id | 自增id |
| name | 商品名称 |
| stock | 商品库存 |
| sale | 商品销量 |
| created_at | 创建时间 |
| updated_at | 更新时间 |
| deleted_at | 删除时间 |
订单orders表结构:
| 字段 | 描述 |
|---|---|
| id | 自增id |
| user_id | 用户id |
| goods_id | 商品id |
| number | 用户购买数量 |
| created_at | 创建时间 |
| updated_at | 更新时间 |
| deleted_at | 删除时间 |
CREATE TABLE `goods` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
`name` varchar(255) NOT NULL DEFAULT '' COMMENT '商品名称',
`stock` int(11) NOT NULL DEFAULT '0' COMMENT '库存',
`sale` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '销量',
`created_at` datetime NOT NULL COMMENT '创建时间',
`updated_at` datetime NOT NULL COMMENT '更新时间',
`deleted_at` datetime DEFAULT NULL COMMENT '删除时间',
PRIMARY KEY (`id`) USING BTREE,
KEY `created_at_index` (`created_at`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
CREATE TABLE `orders` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
`user_id` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '用户id',
`goods_id` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '商品id',
`number` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '购买数量',
`created_at` datetime NOT NULL COMMENT '创建时间',
`updated_at` datetime NOT NULL COMMENT '更新时间',
`deleted_at` datetime DEFAULT NULL COMMENT '删除时间',
PRIMARY KEY (`id`) USING BTREE,
KEY `user_id_index` (`user_id`) USING BTREE,
KEY `goods_id_index` (`goods_id`) USING BTREE,
KEY `created_at_index` (`created_at`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci
版本一:mysql事务
先什么都不考虑,只实现下单功能,表类型都为InnoDB:
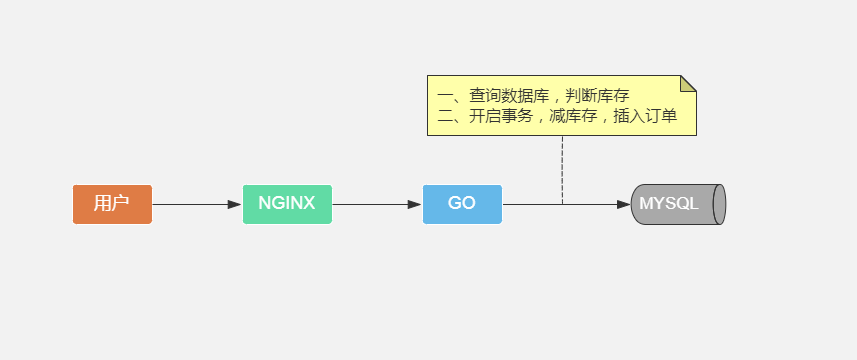
$userId = 用户id;
$number = 用户购买数量;
$goodsId = 用户购买商品id;
$stock = 'select stock from goods where id = $goodsId';
if ($stock < $number) return;
事务开始
update goods set stock = stock - $number where id = $goodsId;
insert into order ($userId, $goodsId,$number);
事务结束
有经验的同学会发现这段代码在高并发时会有超卖问题,利用InnoDB行锁解决超卖问题,修改如下:
$userId = 用户id;
$number = 用户购买数量;
$goodsId = 用户购买商品id;
$stock = 'select stock from goods where id = $goodsId';
if ($stock < $number) return;
事务开始
$affectedRows = update goods set stock = stock - $number where id = $goodsId and stock - $number >= 0;
if ($affectedRows == 0) rollback;
insert into order ($userId, $goodsId,$number);
事务结束
思考:
1、这段代码能支持多少并发?
2、如果并发上不去,并发瓶颈是卡在行锁还是插入还是这个显式事务?
压测脚本
有库存压测:
wrk -t8 -c40 -d10s --latency http://172.16.58.113:8080/orderV1
8 threads and 40 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 22.12ms 86.09ms 1.38s 97.98%
Req/Sec 204.72 106.98 484.00 61.64%
Latency Distribution
50% 9.99ms
75% 12.81ms
90% 17.65ms
99% 507.89ms
12228 requests in 10.01s, 1.62MB read
Socket errors: connect 0, read 0, write 0, timeout 22
Requests/sec: 1221.49
没有库存的时候,只是一条select语句QPS很高,很好理解,重点是有库存的时候:1000QPS;
那么是事务还是行锁影响了QPS?我们设计几种测试场景来验证(数据十万左右):
| 场景 | 有事务 | 无事务 |
|---|---|---|
| 行锁 | 3395 | 3332 |
| 随机行锁 | 21117 | 21034 |
| insert | 14361 | 14392 |
| 下单 | 1388 | 2781 |
| 空事务 | 81604 |
结论:行锁是拖累QPS的绝对因素。
我们的目标10万QPS,现有的代码只能支持1000多QPS,任重而道远,我们先降低目标,先设计个能支持1万QPS的架构。
版本二:redis预减库存+mysql插订单+mq异步库存落库
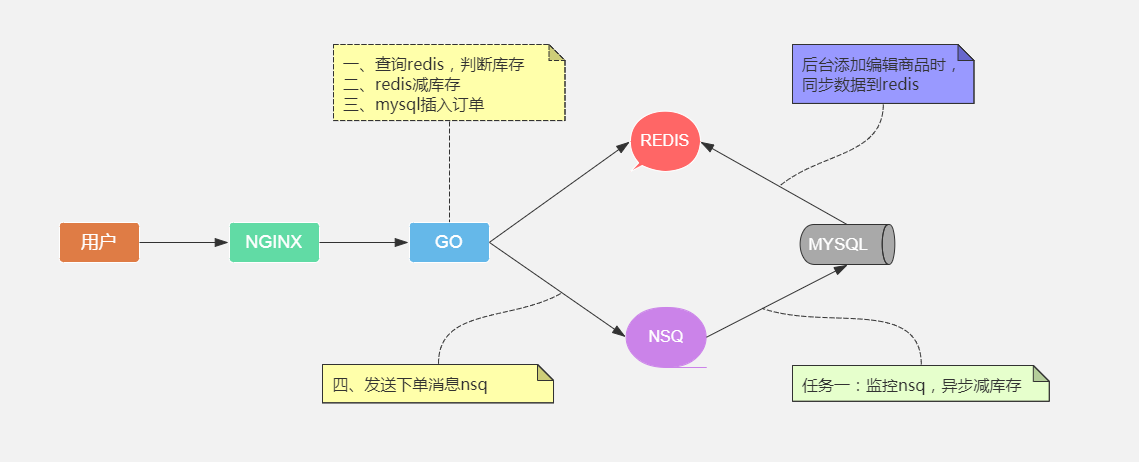
代码实现过程:
步骤一:redis判断库存
步骤二:redis预减库存
步骤三:数据库插入订单记录
步骤四:发送下单消息到mq
任务一:监控下单消息异步库存落库
$userId = 用户id;
$number = 用户购买数量;
$goodsId = 用户购买商品id;
$key = 'goods_' + $goodsId;
$stock = redis.hget($key, 'stock');
if ($stock < $number) return;
redis.hincrby($key, -$number);
$id, $err = insert into order ($userId, $goodsId,$number);
if ($err != null) {
redis.hincrby($key, $number);
return;
}
$msg = [
'orderId' => $id,
'goodsId' => $goodsId,
'number' => $number,
'userId' => $userId
]
mq.send($msg)
上述代码能不能达到1万QPS的目标?我们得先确定步骤一二三四各自的QPS:
| 操作 | QPS |
|---|---|
| hget | 101739 |
| hincrby | 97626 |
| insert | 14392 |
| mq | 50450 |
以上数据验证步骤一二三四性能上不会有瓶颈,满足我们1万QPS的目标;
版本二 压测:
wrk -t8 -c80 -d10s --latency http://172.16.58.113:8080/orderV2
8 threads and 80 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 6.06ms 5.88ms 141.52ms 93.65%
Req/Sec 1.92k 497.16 2.53k 85.75%
Latency Distribution
50% 4.59ms
75% 6.10ms
90% 8.92ms
99% 32.67ms
143122 requests in 10.01s, 20.30MB read
Requests/sec: 14300.71
版本二QPS:14000QPS
对比分步压测的数据,发现主要是insert拖了后腿;
这里的代码还是会有超卖问题,版本一我们使用了行数解决数据库超卖,redis有两种方案:
1、先incrby,返回结果小于0,则没有库存,没有库存的时候要加上刚才减去的数量;这里有个小问题,高并发的时候,有可能库存会是负数,返回前端的时候要做判断,为负置为0;
2、通过redis lua脚本的方式,lua脚本先判断库存再减,利用redis单进程的原理,保证不超卖;
// redis lua脚本
local number = ARGV[2]
local num = redis.call('HGET', KEYS[1], ARGV[1])
if not num or tonumber(num) <= 0 then
return -1
end
redis.call('HINCRBY', KEYS[1], ARGV[1], number)
return 1
两种方式效率对比:
| 有库存 | 无库存 | 备注 | |
|---|---|---|---|
| hincrby | 97626 | 55301 | 无库存要操作两次redis |
| lua脚本 | 69870 | 94645 | 有库存要操作两次redis |
两种方案没有优劣,视情况而定,我们用第一种方案,代码实现过程:
$userId = 用户id;
$number = 用户购买数量;
$goodsId = 用户购买商品id;
$key = 'goods_' + $goodsId;
if(redis.hincrby($key, -$number) < 0) {
redis.hincrby($key, $number);
return;
}
$id, $err = insert into order ($userId, $goodsId,$number);
if ($err != null) {
redis.hincrby($key, $number);
return;
}
$msg = [
'orderId' => $id,
'goodsId' => $goodsId,
'number' => $number,
'userId' => $userId
]
mq.send($msg))
任务一:监控下单消息异步库存落库
mq.listen() {
$goodsId = $msq['goodsId'];
$number = $msq['number'];
$err = update goods set stock = stock - $number where id = $goodsId and stock - $number >= 0;
if ($err != null) return;
}
问题:上述代码如果在更新数据库时出现网络问题或者服务器宕机未更新成功导致redis、mysql库存不一致;
解决方案:取消mq自动应答方式,程序控制应答时机,更新失败,消息重新入队,mq重发消息;
mq.listen() {
$goodsId = $msq['goodsId'];
$number = $msq['number'];
$err = update goods set stock = stock - $number where id = $goodsId and stock - $number >= 0;
if ($err != null) {
$msq.requeue();
return;
}
$msq.commit();
}
消息重新入队又带来两个新的问题(一般线上不requeue,原因等一下解释):
1、当库存更新成功时服务器宕机,消息ack未成功,mq消息重试,导致库存多次扣除;
解决方案:程序消费消息要实现幂等性;这里增加一张商品库存消费日志,注意order_id用的是唯一索引;
2、某些原因例如mysql磁盘满了,任务一直不能完成,不能一直requeue,需要记录最大requeue,超过次数记录日志,报警人工介入;
CREATE TABLE `goods_stock_logs` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
`goods_id` int(11) NOT NULL DEFAULT '0' COMMENT '商品id',
`order_id` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '订单id',
`number` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '购买数量',
`created_at` datetime NOT NULL COMMENT '创建时间',
`updated_at` datetime NOT NULL COMMENT '更新时间',
`deleted_at` datetime DEFAULT NULL COMMENT '删除时间',
PRIMARY KEY (`id`) USING BTREE,
UNIQUE KEY `order_id_index` (`order_id`),
KEY `created_at_index` (`created_at`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci
mq.listen() {
$goodsId = $msq['goodsId'];
$orderId = $msq['orderId'];
$number = $msq['number'];
if (redis.incr("order_" + $orderId) > 3) {
// 记录
$msq.commit();
}
$count = select count(*) from goods_stock_logs where order_id = $orderId;
if (count != 0) {
$msq.commit();
return;
}
事务开始
$err = update goods set stock = stock - $number where id = $goodsId and stock - $number >= 0;
if ($err != null) {
$msq.requeue();
rollback;
return;
}
// 加入ignore防止报错,存在返回0
$affectedRows = insert ignore into goods_stock_logs (goods_id, order_id, number) values ($goodsId, $orderId, $number);
if ($affectedRows == 0 {
$msq.commit();
rollback;
return
}
$msq.commit();
事务结束
}
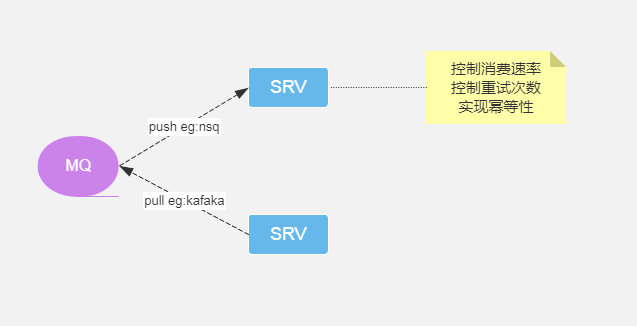
看到这里的代码很有熟悉感,跟刚开始的下单代码很相似,QPS大概1000左右,新的问题又来了,消息投递速率跟消息消费速率不对等,先看一下mq消费消息的两种方式:推和拉;
1、拉的方式:应用服务器自己从mq拉消息,消费成功,再继续拉新的消息处理,这里没啥问题;
2、推的方式:mq主动推送消息到应用服务器,投递速率如果大于消费速率,导致应用服务器处理不过来;
nsq采用的是主动推的方式,需要设置消息出站速率,这里设置出站速率1000,应用消费消息线程或协程数量20;
行锁优化(todo)
select from update
Commit On Success / Rollback On Fail /Target Affect Row
组提交热点事务
版本三:redis预减库存+mysql分表插订单+mq异步库存落库
| 分表数量 | 插入速度 |
|---|---|
| 1 | 14978 |
| 2 | 17665 |
| 3 | 19333 |
| 4 | 19985 |
| 5 | 20183 |
总结:单表插入主要是建数据速度有瓶颈,多表插入的时候主要是磁盘IO有瓶颈,多表保持3-5张比较合适,这个数据后面有用,先记着;
分16张order表,order_1、order_2 、order_3 ... order_16
$userId = 用户id;
$number = 用户购买数量;
$goodsId = 用户购买商品id;
$key = 'goods_' + $goodsId;
if(redis.hincrby($key, -$number) < 0) {
redis.hincrby($key, $number);
return;
}
$tableIndex = $userId / 10 % 16 + 1
$id, $err = insert into order_$tableIndex ($userId, $goodsId,$number);
if ($err != null) {
redis.hincrby($key, $number);
return;
}
$msg = [
'orderId' => $id,
'goodsId' => $goodsId,
'number' => $number,
'userId' => $userId
]
mq.send($msg))
版本三 压测:
wrk -t8 -c80 -d10s --latency http://172.16.58.114:8080/orderV3
8 threads and 80 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 9.38ms 12.96ms 314.39ms 95.54%
Req/Sec 1.33k 370.34 3.50k 86.78%
Latency Distribution
50% 6.68ms
75% 8.99ms
90% 13.60ms
99% 68.30ms
205955 requests in 10.10s, 14.05MB read
Requests/sec: 20490.97;
版本三QPS:20000QPS
版本四:redis预减库存+mysql分库分表插订单+mq异步库存落库
解决思路:当单台mysql插入有瓶颈的时候,我们只能使用多台,每台20000QPS,大概需要5-6台独立的mysql主机支撑10万QPS的并发;
$userId = 用户id;
$number = 用户购买数量;
$goodsId = 用户购买商品id;
$key = 'goods_' + $goodsId;
if(redis.hincrby($key, -$number) < 0) {
redis.hincrby($key, $number);
return;
}
db = dbs[$userId % 5];
$tableIndex = $userId / 10 % 16 + 1;
$id, $err = db(insert into order_$tableIndex ($userId, $goodsId,$number));
if ($err != null) {
redis.hincrby($key, $number);
return;
}
$msg = [
'orderId' => $id,
'goodsId' => $goodsId,
'number' => $number,
'userId' => $userId
]
mq.send($msg))
版本四 双mysql压测
wrk -t8 -c160 -d10s --latency http://172.16.58.113:8080/orderV4
8 threads and 160 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 5.71ms 9.09ms 264.19ms 94.69%
Req/Sec 2.36k 616.28 7.67k 84.14%
Latency Distribution
50% 3.70ms
75% 5.51ms
90% 9.31ms
99% 44.89ms
2073014 requests in 10.10s, 25.35MB read
Requests/sec: 381738.07
版本四 双mysql主机QPS:38000QPS
下面的版本主要讲大概流程了
版本五:redis预减库存+mysql分库分表插订单+mq多主机异步库存落库
这里用的mq是NSQ,每秒发送消息5万左右,要达到10万QPS,大概需要两台NSQ;
$userId = 用户id;
$number = 用户购买数量;
$goodsId = 用户购买商品id;
$key = 'goods_' + $goodsId;
if(redis.hincrby($key, -$number) < 0) {
redis.hincrby($key, $number);
return;
}
db = dbs[$userId % 5];
$tableIndex = $userId / 10 % 16 + 1;
$id, $err = db(insert into order_$tableIndex ($userId, $goodsId,$number));
if ($err != null) {
redis.hincrby($key, $number);
return;
}
$msg = [
'orderId' => $id,
'goodsId' => $goodsId,
'number' => $number,
'userId' => $userId
]
mq = mqs[$userId % 2];
mq.send($msg)
版本六:redis预减库存+mysql分库分表插订单+mq多主机异步库存落库+内存售完标记
这版主要优化,当库存售完,设置一个库存售完标记,之后服务器基本空转,不操作redis;
$userId = 用户id;
$number = 用户购买数量;
$goodsId = 用户购买商品id;
if ($stockOut == true) return;
$key = 'goods_' + $goodsId;
if(redis.hincrby($key, -$number) < 0) {
$stockOut = true;
redis.hincrby($key, $number);
return;
}
db = dbs[$userId % 5];
$tableIndex = $userId / 10 % 16 + 1;
$id, $err = db(insert into order_$tableIndex ($userId, $goodsId,$number));
if ($err != null) {
$stockOut = false;
$stock = redis.hincrby($key, $number);
return;
}
$msg = [
'orderId' => $id,
'goodsId' => $goodsId,
'number' => $number,
'userId' => $userId
]
mq = mqs[$userId % 2];
mq.send($msg)
缓存标记压测:
wrk -t16 -c500 -d10s --latency http://172.26.178.10:8080/orderV6
16 threads and 500 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 4.22ms 3.42ms 41.40ms 81.85%
Req/Sec 8.38k 482.06 11.85k 75.71%
Latency Distribution
50% 3.27ms
75% 5.02ms
90% 8.53ms
99% 17.38ms
1345999 requests in 10.10s, 182.28MB read
Requests/sec: 133274.72
临界问题:服务器多台,库存只剩最后一个,被下图的go1拿到的,go1插入订单时出错,清除本地缓存标记并还原redis库存,但是go2,go3内存标记无法清除,导致抢购界面上还剩1个库存,但是用户下单轮询到go2、go3服务器时,提示没有库存;
解决方案:go1清除本地售完标记,同时通知其他应用服务器清除本地售完标记;
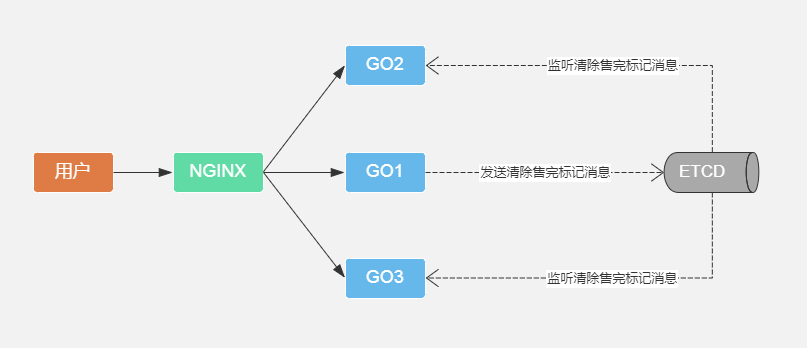
$userId = 用户id;
$number = 用户购买数量;
$goodsId = 用户购买商品id;
if ($stockOut == true) return;
$key = 'goods_' + $goodsId;
if(redis.hincrby($key, -$number) < 0) {
$stockOut = true;
redis.hincrby($key, $number);
return;
}
db = dbs[$userId % 5];
$tableIndex = $userId / 10 % 16 + 1;
$id, $err = db(insert into order_$tableIndex ($userId, $goodsId,$number));
if ($err != null) {
$stockOut = false;
$stock = redis.hincrby($key, $number);
send("清除售完标记消息")
return;
}
$msg = [
'orderId' => $id,
'goodsId' => $goodsId,
'number' => $number,
'userId' => $userId
]
mq = mqs[$userId % 2];
mq.send($msg)
版本七:redis预减库存+mysql二叉树分库分表插订单+mq多主机异步库存落库+内存售完标记
二叉树分库分表:主要解决扩容数据库服务器时避免按行进行数据拆分,以2的倍数扩容数据库主机数量,先按库拆分,再按表拆分,每次只需要转移1/2的数据;
常规拆数据过程:
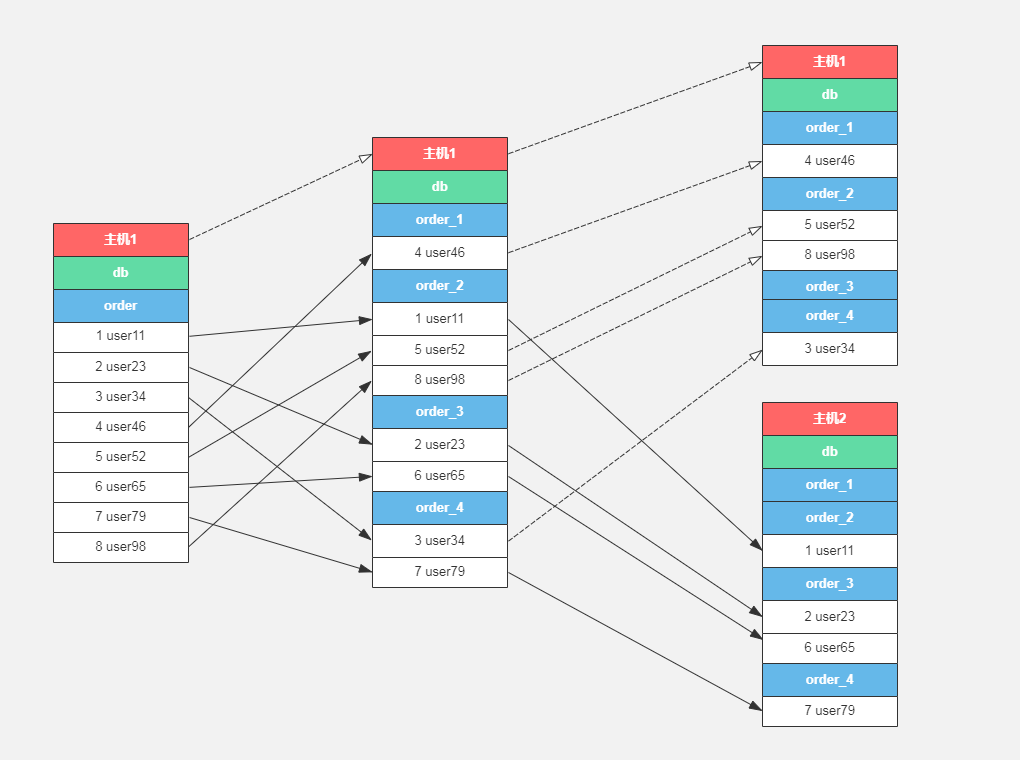
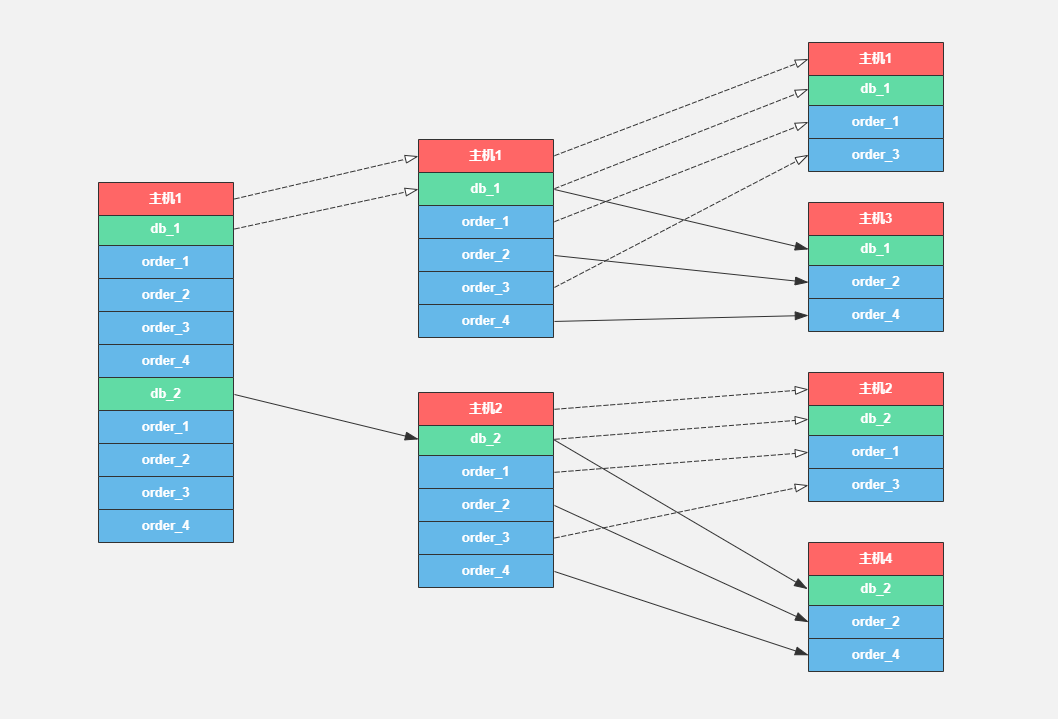
// 用户数据库、表映射关系
$userId = 用户id;
// 一个数据库实例
$conn = 数据库连接;
$conns[0] = $conn;
// 两个数据库实例
$conn1 = 数据库连接1;
$conn2 = 数据库连接2;
$conns[0] = $conn1;
$conns[1] = $conn2;
$dbConn, $dbName, $tableName = getConn($userId, $conns)
func getConn($userId, $conns) {
$dbCount = 8;
$tableCount = 16;
$dbHostCount = len($conns);
$dbIndex = $userId % $dbCount % $dbHostCount;
$tableIndex = $userId / 10 % $tableCount + 1;
$dbConn = $conns[$dbIndex - 1]
$dbName = "db_" + $dbIndex
$tableName = "order_" + $tableIndex
return $dbConn, $dbName, $tableName
}
网上有文章说分到最后可以一库一表,通过我们分表压测的结果来判断,一库一表发挥不出mysql全部的性能,一库四表一个小集群比较合适, 8个库16张表的话,最后可以分到32个小集群,每个集群2万的插入QPS,32*2 = 64万插入QPS;
版本八:openresty(用户限流+库存限流+请求削峰填谷)+(redis预减库存+mysql二叉树分库分表插订单+mq多主机异步库存落库+内存售完标记)
限流的常用算法:
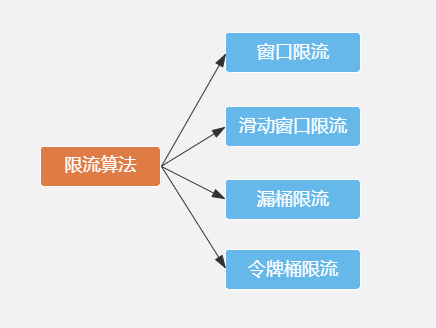
也叫做计数器算法,限流算法中最简单也最容易实现的算法,比如,抢购接口设置每分钟钟访问次数不能超过1000次,递增计算器变量,如果一分钟内超过1000次请求,拒绝服务;
临界问题:0分59秒,并发请求1000,1分00秒并发请求1000,瞬间突破服务器速率限制,服务器崩溃;
滑动窗口算法(舍弃):
固定窗口的升级版,不能彻底解决临界问题,只是减少影响;
漏桶算法:
强行限制请求速率;
令牌桶算法:
漏桶的升级版,强行限制请求速率同时还允许某种程度的突发;
重点看一下openresty如何实现漏桶和令牌桶算法:
小学数学题:银行办理业务,每分钟可以处理2个人的业务,小明前面有16个人排队,请问5分钟后小明排第几位,还需要等待多少时间?
答案:排第7位,还需要等待3分钟
计算公式:
第几位 = 排队人数 - 速率 * 时间 + 1
等待时间 = (第几位 - 1) / 速率
源码路径:/usr/local/openresty/lualib/resty/limit/req.lua incoming函数
function _M.incoming(self, key, commit)
-- 人数、速率*1000处理
-- 第几位 = 排队人数 - 速率 * 时间 + 1
excess = max(tonumber(rec.excess) - rate * abs(elapsed) / 1000 + 1000, 0)
-- burst 突发参数
if excess > self.burst then
return nil, "rejected"
end
-- 返回值 等待时间(第1位在程序里是第0位,所以不用减一),第几位
return excess / rate, excess / 1000
end
// 测试
function limit() {
for i = 0, i < 10, i++ {
delay, ranking = incoming();
print(等待时间 == delay, 第几位 == ranking)
}
}
// 漏桶
限流参数:rate = 5(每秒5个),burst = 5
limit()
sleep(1s)
limit()
sleep(2s)
limit()
等待时间 == 0 第几位 == 0
等待时间 == 0.2 第几位 == 1
等待时间 == 0.4 第几位 == 2
等待时间 == 0.6 第几位 == 3
等待时间 == 0.8 第几位 == 4
等待时间 == 1 第几位 == 5
等待时间 == nil 第几位 == rejected
等待时间 == nil 第几位 == rejected
等待时间 == nil 第几位 == rejected
等待时间 == nil 第几位 == rejected
1s间隔
等待时间 == 0.2 第几位 == 1
等待时间 == 0.4 第几位 == 2
等待时间 == 0.6 第几位 == 3
等待时间 == 0.8 第几位 == 4
等待时间 == 1 第几位 == 5
等待时间 == nil 第几位 == rejected
等待时间 == nil 第几位 == rejected
等待时间 == nil 第几位 == rejected
等待时间 == nil 第几位 == rejected
等待时间 == nil 第几位 == rejected
2s间隔
等待时间 == 0 第几位 == 0
等待时间 == 0.2 第几位 == 1
等待时间 == 0.4 第几位 == 2
等待时间 == 0.6 第几位 == 3
等待时间 == 0.8 第几位 == 4
等待时间 == 1 第几位 == 5
等待时间 == nil 第几位 == rejected
等待时间 == nil 第几位 == rejected
等待时间 == nil 第几位 == rejected
等待时间 == nil 第几位 == rejected
// 令牌桶
限流参数:rate = 5(每秒5个),burst = 8
limit()
sleep(1s)
limit()
sleep(2s)
limit()
等待时间 == 0 第几位 == 0
等待时间 == 0.2 第几位 == 1
等待时间 == 0.4 第几位 == 2
等待时间 == 0.6 第几位 == 3
等待时间 == 0.8 第几位 == 4
等待时间 == 1 第几位 == 5
等待时间 == 1.2 第几位 == 6
等待时间 == 1.4 第几位 == 7
等待时间 == 1.6 第几位 == 8
等待时间 == nil 第几位 == rejected
1s间隔
等待时间 == 0.8 第几位 == 4
等待时间 == 1 第几位 == 5
等待时间 == 1.2 第几位 == 6
等待时间 == 1.4 第几位 == 7
等待时间 == 1.6 第几位 == 8
等待时间 == nil 第几位 == rejected
等待时间 == nil 第几位 == rejected
等待时间 == nil 第几位 == rejected
等待时间 == nil 第几位 == rejected
等待时间 == nil 第几位 == rejected
2s间隔
等待时间 == 0 第几位 == 0
等待时间 == 0.2 第几位 == 1
等待时间 == 0.4 第几位 == 2
等待时间 == 0.6 第几位 == 3
等待时间 == 0.8 第几位 == 4
等待时间 == 1 第几位 == 5
等待时间 == 1.2 第几位 == 6
等待时间 == 1.4 第几位 == 7
等待时间 == 1.6 第几位 == 8
等待时间 == nil 第几位 == rejected
// 算法实现
ranking和delay配合可以实现四种限流效果:
1、固定速率:
限流参数:rate = 5,burst = 5
if ranking == 'rejected' {
return "超速";
}
if delay > 0.001 {
ngx.sleep(delay);
}
2、固定速率+允许突发(突发等待):
限流参数:rate = 5,burst = 8
if ranking == 'rejected' {
return "超速";
}
if delay > 0.001 {
ngx.sleep(delay);
}
3、固定速率+允许突发(突发不等待):
限流参数:rate = 5,burst = 8
if ranking == 'rejected' {
return "超速";
}
if delay > 0.001 && ranking < rate {
ngx.sleep(delay);
}
4、固定速率+允许突发(部分突发等待、突发不等待):
限流参数:rate = 5,burst = 10,nodelay = 3
if ranking == 'rejected' {
return "超速";
}
if delay > 0.001 && (ranking < rate || ranking > rate + nodelay){
ngx.sleep(delay);
}
上面限速效果对应nginx默认支持的参数搭配:
burst:可选参数,设置允许突发请求的数量
nodelay:无延迟排队
delay:分段限速
针对用户的限流:
针对抢购秒杀业务的几种刷单手段:
1、同一个账号,一次性发出多个请求
应对方案:lua_shared_dict add 记录用户请求 或者redis setnx
前端优化:用户点击抢购按钮,发出请求之前,按钮置灰,防止用户连续点击;
后端优化:非法用户提前请求抢购接口,判断抢购时间,如果小于抢购时间,记录用户已抢购,返回抢购未成功;
2、多个账号,一次性发送多个请求
应对方案:检测机器IP请求频率,某个IP请求频率很高(多高才算高?纠结...),弹出验证码;限流配置:固定速率+允许突发(突发不等待)rate = 1,burst = 3
3、多个账号,不同IP发送请求
应对方案:没辙
针对库存的限流:
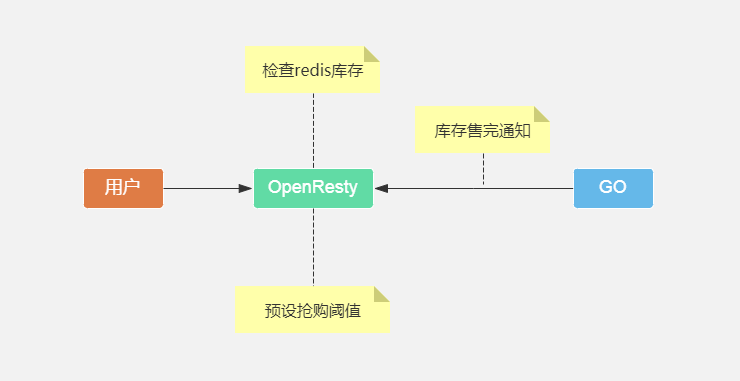
方案二:应用服务器库存为0时,通知openresty设置内存售完标记,缺点无法拦截顺时并发,举例:抢购开始瞬间涌入10万请求,应用服务器售完发消息的时候,10万并发已到应用服务器,openresty拦截时效太低;
方案三:预先设置抢购阈值到openresty,可为库存的1.5-2倍,当请求超过阈值,停止转发请求到后端应用服务器;举例:库存只有1万,并发请求10万,openresty只允许2万请求到达后端应用服务器,减轻应用服务器压力;
三种方案没有优劣,各有优缺点,视业务场景单独或结合而定,以当前小米秒杀场景,第三种比较适合;
针对业务的限流:
抢购接口限流
描述:抢购接口并发数量限制,设置超出并发上限返回用户服务器繁忙(一般并发上限设置为压测数据的70%-80%,超过70%报警);
请求削峰填谷
思考:并发上限1万/s,库存3万,同时5万用户参与抢购
问题:如果设置并发超出时,提示服务器繁忙,这时库存还剩2万,因为并发限制本来可以卖出来的商品没卖出去,影响活动效果,降低用户体验
分析:抢购活动,一般用户的抢购意愿比较高,用户点击抢购愿意接受几秒钟的等待时间或多余的操作
方案1:采取openresty固定速率+允许突发(突发等待)的限流方案,设置rate = 10000,burst = 30000,通过让用户等待一段时间达到削峰填谷的效果;
缺点:占用负载均衡并发连接数
方案2:超过并发上限,弹出验证码,达到削峰填谷的效果;
优点:不占用负载均衡并发连接数
缺点:用户要操作一次验证码
版本九:多级缓存+openresty(用户限流+库存限流+请求削峰填谷)+(redis预减库存+mysql二叉树分库分表插订单+mq多主机异步库存落库+内存售完标记)
常规缓存使用方法:
// 查询抢购商品接口
$key = 'goods_' + $goodsId;
$goods = redis.hgetall($key);
if ($goods != null) {
return $goods;
}
$goods = 'select * from goods where id = $goodsId';
redis.hmset($key, $goods);
redis.expire(key, $timeout);
return $goods;
主要问题:
1、缓存失效风暴,解决:加锁
2、缓存穿透,解决:id加密解密,服务器先对id进行解密,解密失败,返回非法请求,例如youtube的视频id:www.youtube.com/watch?v=HKy…
解决上面的两个问题最彻底的方式就是应用维护缓存数据,没有二次查库步骤;
缓存原则:离用户最近的缓存才是好缓存!
二八定律:80%的业务访问集中在20%的数据上!
缓存方案:
在当前系统架构中,离用户最近的是负载均衡层,把20%的热点数据放在openresty应用缓存中,100%的数据放在redis中,热点数据使用LRU缓存淘汰算法(todo),不存在查redis;
数据脏读问题:
1、热点缓存etcd主动通知实时更新,redis缓存数据更新改变时应用层直接更新;
2、使用开源数据同步神器-alibaba/canal (todo)
应用内存上限问题:
通过商品id哈希到不同的应用层,分摊数据增加内存存储数据空间;
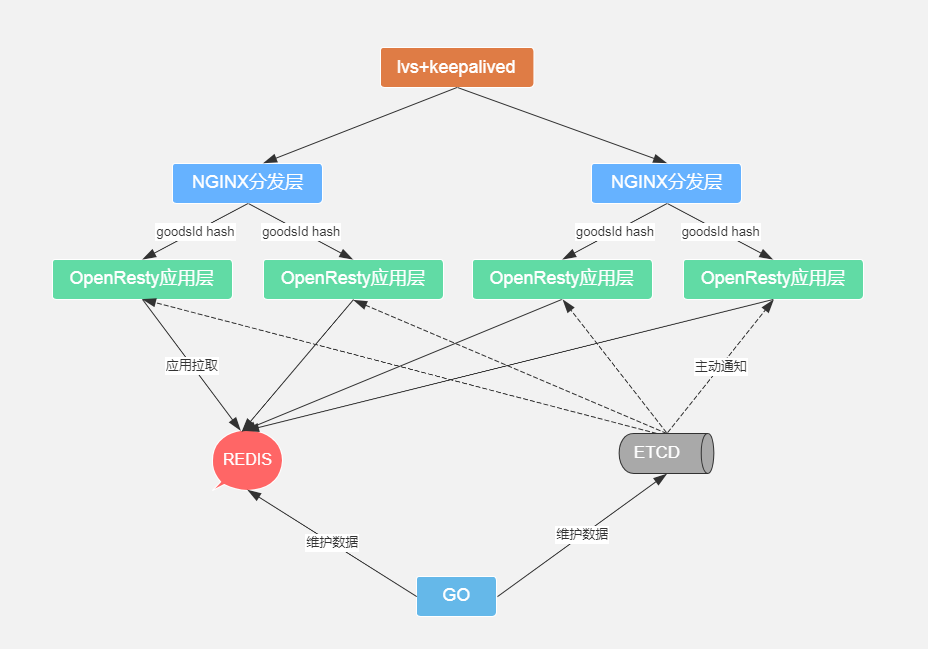
备注:肯定有同学疑问上图中lvs为什么不直接指向openresty应用层做负载均衡,因为要对url中的goodsId参数做hash策略均衡,lvs基于四层做不到,nginx基于七层可以做到;
缓存服务器扩容方案:
场景:商品数据缓存在3台cache主机,goodsId%3 映射规则随机映射到对应的主机上;
需求:3台cache主机压力过大,需要增加到4台;
常规方案:改变映射规则参数,goodsId%4,代码上线;
问题:当上线一瞬间所有缓存全部失效,大量的请求请求落在db层,服务器崩溃;
解决方案:一致性hash 算法实现
当节点数量改变时,能够使失效的缓存数量尽可能少
当前采用没有二次查库步骤的缓存步骤,应用一致性hash方案有点麻烦:
每次增加一台cache主机,全量对比需要缓存的key,对比上一个hash映射的cacheOld和新的hash映射的cacheNew,两者相等,数据不动,两者不相等,新增cacheNew数据,待上线后删除cacheOld数据;
版本十:数据一致性+多级缓存+openresty(用户限流+库存限流+请求削峰填谷)+(redis预减库存+mysql二叉树分库分表插订单+mq多主机异步库存落库+内存售完标记)
分布式架构最头疼的就是数据一致性,我们放在最后解决。
架构目标:最终一致性
业务底线:可以少卖,不能超卖
下单流程分析:
问题一:redis预减库存成功,服务器宕机,商品少卖,redis和mysql数据不一致;
问题二:mysql插入订单成功,服务器宕机,商品正常,redis和mysql数据不一致;
先看第二个问题,成功下单消息未成功投递,如何保证消息的100%投递率?
一、对消息进行状态记录
基于消息队列+定时补偿机制的最终一致性
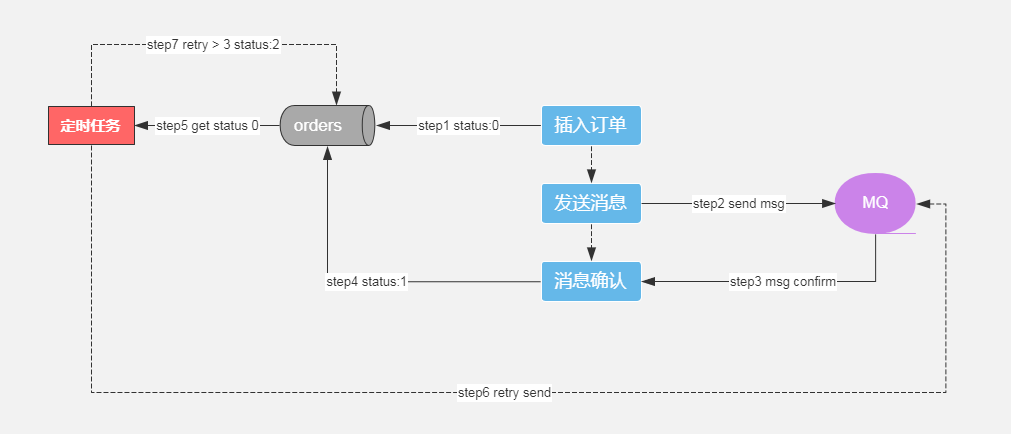
orders表增加字段:
msg_status 消息状态 0 发送中 1 发送成功 2 发送失败(人工介入)
msg_retry 尝试次数
下单流程:
步骤1:订单入库,消息状态msg_status=0
步骤2:发送消息
步骤3:消息确认
步骤4:消息状态msg_status=1
定时任务流程:
步骤5:获取msg_status=0订单
步骤6:重发消息
步骤7:消息重试3次,msg_status=2,人工介入处理
err = mq.send($msg)
if (err != null) {
update order_$tableIndex set msg_status=1 where id=$id;
}
以上下单流程增加了一条update语句,压测对比一下
| 场景 | QPS |
|---|---|
| insert | 14392 |
| insert+update | 6211 |
备注:高并发业务中新增一条sql都要非常小心,多一条sql有可能非常致命;
如何避免这条update语句,来到了第二版
二、消息的延迟投递,做二次确认,回调检查
基于double check确认机制的最终一致性
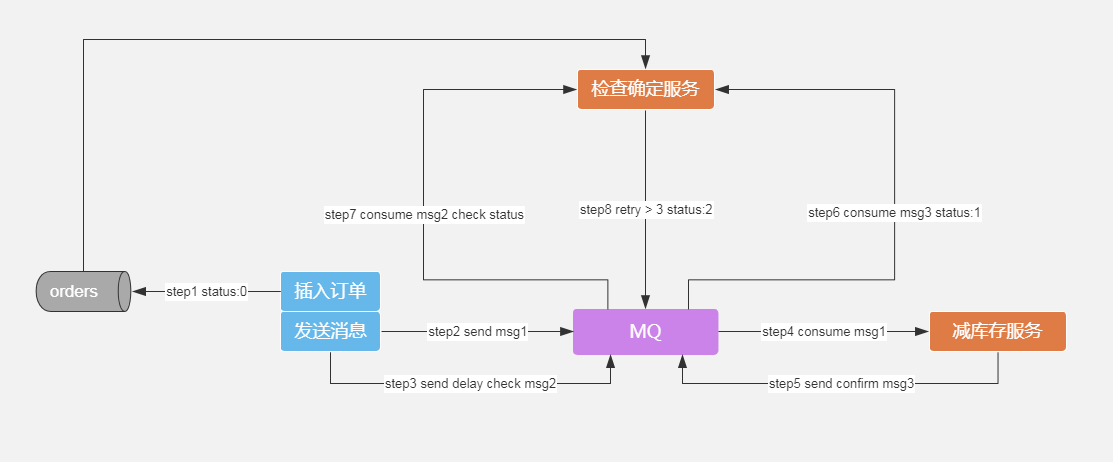
下单流程:
步骤1:订单入库,消息状态msg_status=0
步骤2:发送减库存消息1
步骤3:发送检查库存延迟消息2(延迟时长根据业务来定)
步骤4:减库存服务消费减库存消息1
步骤5:减库存服务发送减库存成功消息3
步骤6:检查确认服务消费减库存成功消息3,msq_status=1
步骤7:检查确认服务消费检查库存延迟消息2,检查msq_status值,msq_status=0重发消息
步骤8:消息重试3次,msg_status=2,人工介入处理
备注:
1、这一版是大部分公司常用的方案,兜兜转转好几圈就是为了避免少写一条sql;
2、网上100%消息投递率的文章都会有一张消息落地表,那是针对多业务的,这里简单来做;
3、怎么保证这条延迟消息的100%投递率,再发一条延迟消息来确认这条延迟消息吗?子子孙孙无穷尽,所以分布式系统中没有绝对的一致性,只有相对的一致性,跟高可用一个道理;
4、遗留问题:线上一般不requeue,因为如果采取保证消息100%投递的方案,两者有冲突,如果没有采取投递方案,可以requeue;
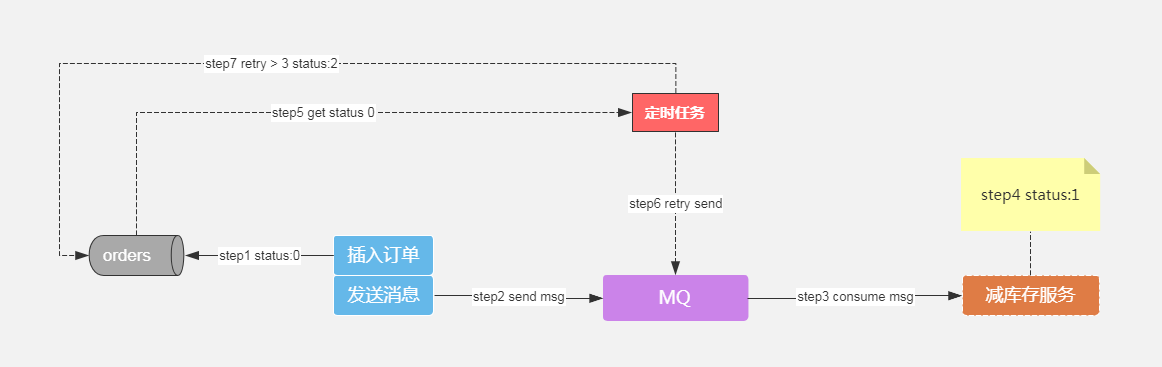
解决少卖问题:
每日凌晨3、4、5对比数据库库存和redis库存,对比数据如果差值不为零并且三次差值一致,以mysql库存为准校队redis库存或者提示人工介入;
延伸阅读:分布式理论
分布式全局唯一id
订单分库分表涉及到的关键问题,订单id唯一性
解决方案:
1、UUID:
缺点:
无法保证趋势递增(InnoDB采用聚簇索引,有序的ID可以保证写入速度);
UUID过长(存储在数据库中,作为主键建立索引效率低)
思考:为什么有序id能保证写入速度?为什么过长建立索引效率低?
2、数据库的自增id+replace_into,来生成全局id;
// 注意表引擎是MyISAM
// 缺点:太多,懒得写了
create table ids (
id bigint(20) unsigned not null auto_increment,
stub char(10) not null default '',
primary key (id),
unique key stub (stub)
) engine=MyISAM;
replace into ids(stub) values('order');
select 1622581;
3、redis中的incr命令来实现原子性的自增与返回
优点:单台主机每秒支持10万级别的id生成速度;
Redis支持RDB和AOF两种持久化的方式。
RDB持久化相当于定时打一个快照进行持久化,如果打完快照后,连续自增了几次,还没来得及做下一次快照持久化,这个时候Redis挂掉了,重启Redis后会出现ID重复。
AOF持久化相当于对每条写命令进行持久化,如果Redis挂掉了,不会出现ID重复的现象,但是会由于incr命令,导致重启恢复数据时间过长。
个人比较喜欢的方案,比较适合订单号的业务,观察京东的订单号规律大概是使用集中id server的方式;
4、雪花算法 (snowflake)

个人比较感兴趣的是算法的实现过程,工作中大部分都是写业务,很少接触原码、反码和补码的知识了,权当复习; 算法实现
maxWorkerId = -1 ^ (-1 << 10)
maxWorkerId = 1023
一起复习一下计算机基础知识
原码:
第一位表示符号, 其余位表示值,以8位二进制举例:
[+1]原 = 0000 0001
[-1]原 = 1000 0001
8位二进制数的取值范围:[1111 1111,0111 1111] => [-127,127]
原码是人脑最直观理解和计算的表示方式。
反码:
正数的反码是其本身;
负数的反码是在其原码的基础上, 符号位不变,其余各个位取反;
[+1] = [00000001]原 = [00000001]反
[-1] = [10000001]原 = [11111110]反
补码:
正数的补码就是其本身;
负数的补码是在其原码的基础上, 符号位不变, 其余各位取反, 最后+1(即在反码的基础上+1);
[+1] = [00000001]原 = [00000001]反 = [00000001]补
[-1] = [10000001]原 = [11111110]反 = [11111111]补
为何要使用原码, 反码和补码?
计算机可以有三种编码方式表示一个数,对于正数三种编码方式的结果都相同:
正数:[+1] = [00000001]原 = [00000001]反 = [00000001]补
复数:[-1] = [10000001]原 = [11111110]反 = [11111111]补
计算:1 - 1 = 1 + (-1) = 0
原码计算:
1 - 1 = 1 + (-1) = [00000001]原 + [10000001]原 = [10000010]原 = -2
反码计算:
1 - 1 = 1 + (-1) = [0000 0001]原 + [1000 0001]原 = [0000 0001]反 + [1111 1110]反 = [1111 1111]反 = [1000 0000]原 = -0
问题:+0、-0问题,既 [0000 0000]原 和 [1000 0000]原 两个编码表示0;
补码计算:
1 - 1 = 1 + (-1) = [0000 0001]原 + [1000 0001]原 = [0000 0001]补 + [1111 1111]补 = [0000 0000]补 = [0000 0000]原
0用[0000 0000]表示, +0、-0问题不存在了,而且可以用[1000 0000]表示-128:
(-1) + (-127) = [1000 0001]原 + [1111 1111]原 = [1111 1111]补 + [1000 0001]补 = [1000 0000]补
8位二进制数补码的取值范围:[1000 0000,0111 1111]补 => [-128, 127]
maxWorkerId = -1 ^ (-1 << 10) // 异或运算符 ^ 两个位相同为0不同为1
-1 11..111111111111111111
-1 << 10 11..111111110000000000
1111111111 = 1023
补充1:抢购成功订单支付时效问题
描述:订单抢购成功,订单超过5分钟未支付,订单失效,还原库存;
解决:最朴素的想法是定时查询订单日志表,缺点大部分操作是无用功,合理的方案是下单成功后发送一条5分钟延迟消息,5分钟后检查订单状态做后续操作;
问题:又怎么保证这条延迟消息的100%投递率?
补充2:库存变更问题
描述:管理后台运营人员增加库存,界面上显示redis实时库存100,某些时候由于减库存消息堆积,数据库还是120的库存;
解决:后台库存功能只能增加库存,不能重置库存;
// 错误做法
redis.hset('goods_' + $goodsId, 'stock', $number)
update goods set stock = $number where id = $goodsId;
// 正确做法
redis.hincr('goods_' + $goodsId, 'stock', $number)
update goods set stock = stock + $number where id = $goodsId;
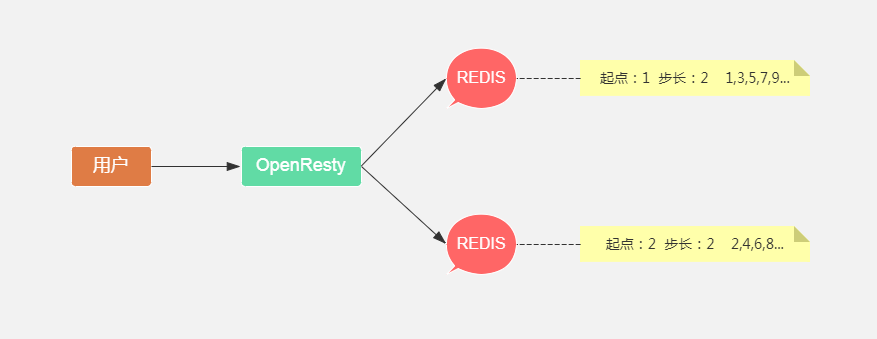
补充3:redis hincr速率限制(每秒并发20万)
两台redis主机,库存平分两份,userId%2操作对应的redis,前端不显示库存或者只显示参与活动库存总数或者库存查询两次redis
思考:京东口罩预约活动
描述:京东提供口罩预约活动,预约成功后晚上8:00准时抢购,预约人数350万;
分析:口罩是疫情稀缺资源,京东可能每天只能准备1万的库存给大家抢购,结果忽悠来350万的用户参加活动,大部分用户只要抢购成功肯定大概率支付,并且预约活动比常见的抢购秒杀活动多了一个预约的流程,可以在这个环节做文章;
解决:预约的时候就已经使用某种规则确定用户已抢到,比如前2万预约的用户已确定抢购资格,当抢购时只放这2万的用户进入应用服务器( redis bitmap实现);
思考:上述解决方案属于特事特办,如果真有350万的库存又怎么办呢?...
