

IEEE Transactions on Circuits and Systems for Video Technology 2019
Jia-Li Yin, Yi-Chi Huang, Bo-Hao Chen, Member, IEEE, and Shao-Zhen Ye
简介
该论文提出了一个颜色转换模型进行去雾,即在颜色空间下进行去雾操作。颜色转换模型包含两个子网络,第一个子网络是去雾,第二个子网络是纹理增强。其中第一个自网络负责估计(在
颜色空间下)从有雾图像到无雾图像的映射函数的斜率和偏移。第二个子网络在第一个子网络的基础上,提高图像的纹理细节和对比度。
motivation
先给出大气散射模型的公式:
其中表示大气光值,
。
表示传输图,其中
表示浓度,
表示场景深度。在去雾过程中,
是唯一已知的量,而去雾的目标结果是获得
,即去雾结果,即去雾过程可以表达为:
文章继续做了一次转换:
文章认为可以根据这个公式来得到去雾结果。其中表示自适应的线性系数,
表示自适应的偏置。所谓自适应即为,输入不同的图像,该公式的
和
是不同的。
文章希望可以通过在颜色空间中,执行以下公式来计算
和
的值:
其中,;
和
表示有雾图像和无雾图像的标准差;
和
表示有雾图像和无雾图像的均值。但是在这两个公式中,只有有雾图是已知的,因此文章希望可以通过输入有雾图像,输出自适应的
和
来得到去雾结果
。
model
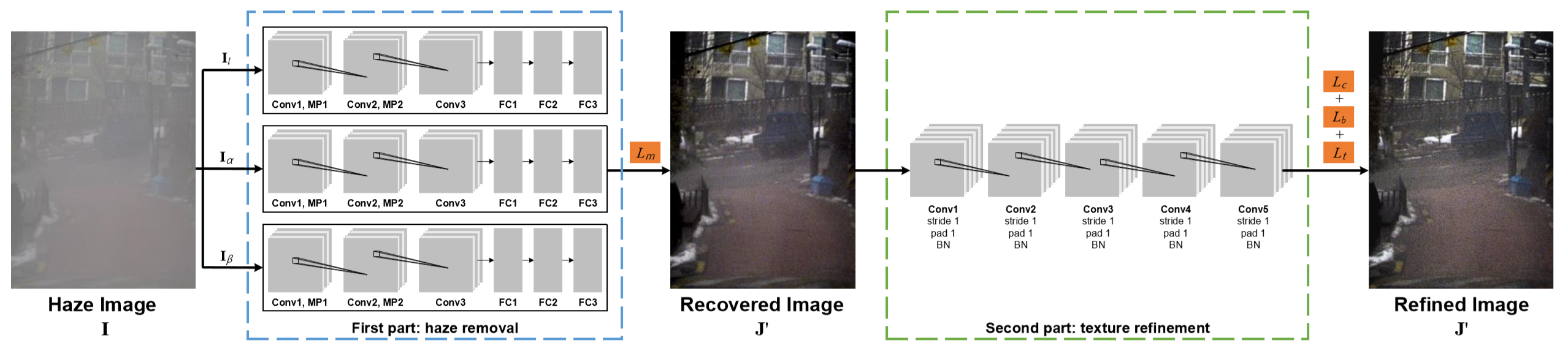
整体网络框架如上图。
分为整个网络分为两个部分:haze removal part(蓝框部分)负责去雾;texture refinement part(绿框部分)负责纹理增强。
Haze Removal
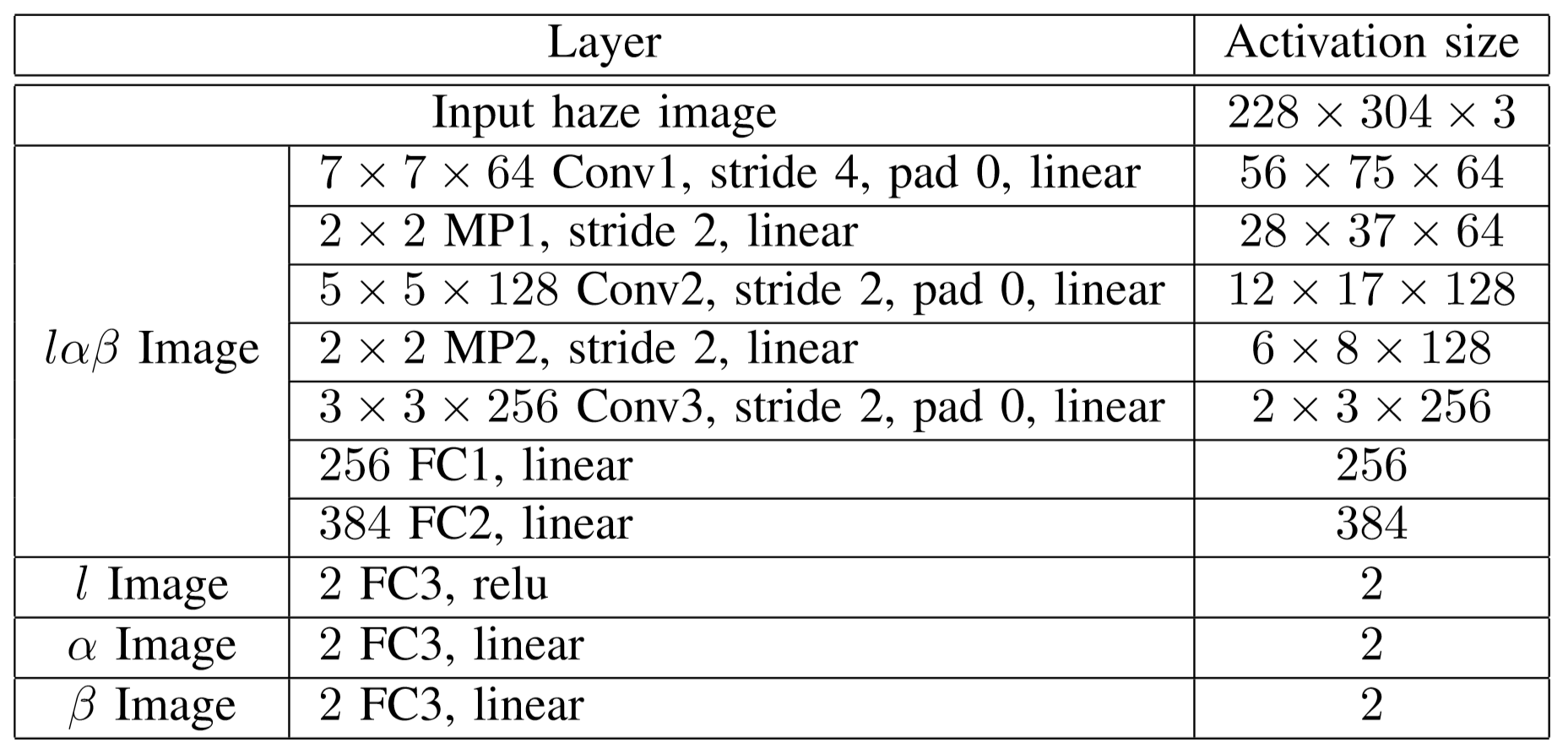
在这个网络部分的损失函数设计为:
和
表示去雾结果和无雾图像的均值和方差。即希望准确的估计
和
的值。

-
(a)输入有雾图像
-
(b)Gth无雾图像
-
(c)去雾结果
Texture Refinement

纹理增强部分网络的具体结构如上图。
重点部分是损失函数:
其中,
,
分别表示内容,纹理,亮度损失。
即为MAE(
)损失。
是一项正则化项,并且其
取负值,即网络会放大
。其公式如下:
其中,;
表示这是batch中的第
张图片;该正则项希望能放大相邻像素之间的值,从而增强纹理细节。
最后,文章在HSV颜色空间中的V通道上计算了最后一项损失,(亮度损失)。这也是一项自监督的损失。
很明显,这个损失的权重也是负的。这一项希望网络能够得到明亮的结果,而不是暗淡的结果。
三个损失函数的权重在实验中分别设置为,
,
。
数据和训练
数据集
使用了NYU Depth数据集,其中636张合成有雾图像作为训练集,它们的(表示浓度)
,另外有720张图像作为测试集,它们的
。
另外使用了:
- Foggy-Image-500
- Foggy-Image-100
- Google Images中的真实雾图像
- RESIDE中的HSTS
- RESIDE中的SOTS
作为测试集来进行定性和定量评价。
训练
- batch-size=8
- Adam优化器训练去雾模块
- 随机梯度下降优化器训练纹理增强模块
- 去雾模块训练50个epoch,学习率为
- 纹理增强模块前20个epoch学习率为
,后30个epoch学习率为
对比和测试
评价指标
- VIF(视觉信息保真度)
- PSNR
- SSIM
- FADE(在文章《Referenceless prediction of perceptual fog density and perceptual image defogging》中提出,其用于评估无Gth的图像中的能见度)
有Gth的数据集的对比结果
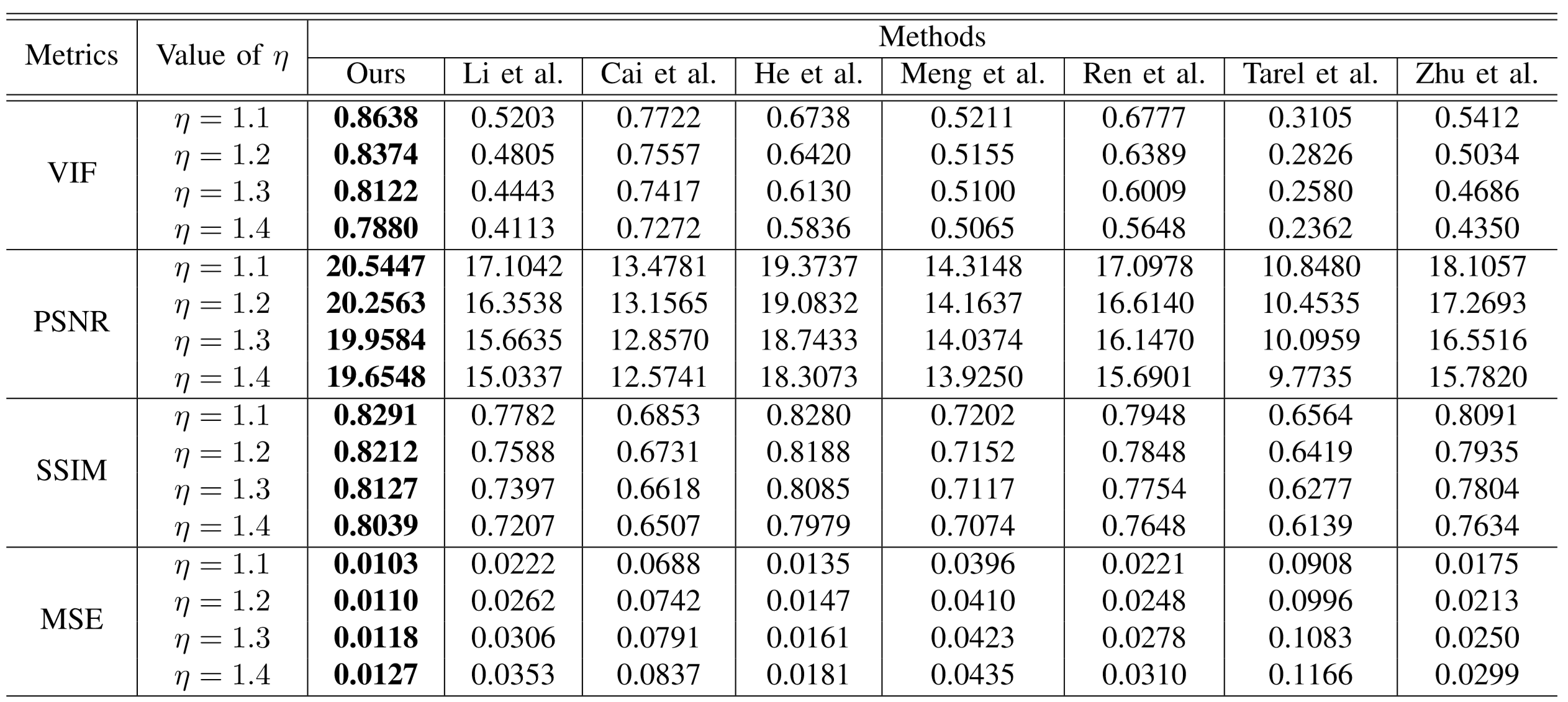
无Gth的数据集的对比结果(FADE)

合成数据集测试对比展示



- (a) 有雾图像
- (b) Gth
- (c) Li等人提出的方法
- (d) Cai等人提出的方法
- (e) DCP
- (f) Meng等人提出的方法
- (g) Ren等人提出的方法
- (h) Tarel等人提出的方法
- (i) Zhu等人提出的方法
- (j) 文章提出的方法
真实数据集测试对比展示


- (a) 有雾图像
- (b) Li等人提出的方法
- (c) Cai等人提出的方法
- (d) DCP
- (e) Meng等人提出的方法
- (f) Ren等人提出的方法
- (g) Tarel等人提出的方法
- (h) Zhu等人提出的方法
- (i) 文章提出的方法
