

关键函数,当使用自定义的Comparator时,调用siftUpUsingComparator函数,如下
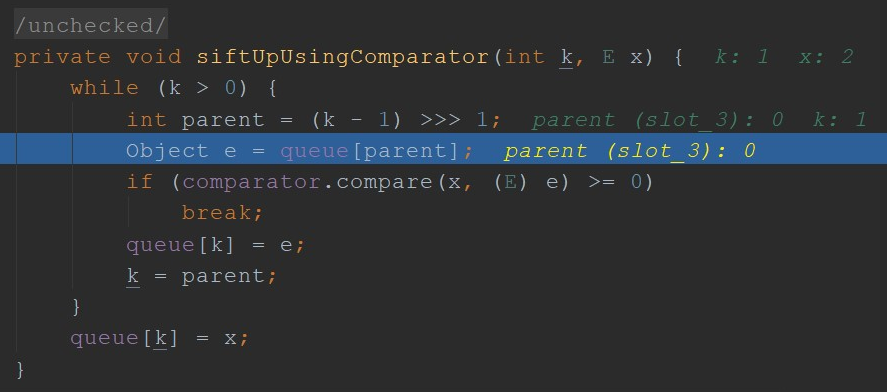
由此可见:
-
初始化K,K为heap的尾部(这里和堆排序方向相反)
-
While:循环一直寻找K的父母元素,和待插入元素进行比较;不满足break条件的时候,就将父母的元素赋值给自己;
-
break:当Comparator.compare()函数调用返回结果大于零的时候停止k的赋值(即寻找k的父母:(k - 1 >>> 1)),并在的K的位置插入待添加的元素
这里可以看出Comparator.compare()方法的返回值,决定了插入元素的位置和升序还是降序 以一个例子作为参考:
PriorityQueue<Integer> heap = new PriorityQueue<>((n1, n2) -> n2 - n1);
heap.add(1);
heap.add(2);
System.out.println(heap.poll());
这是一个构建最大堆的代码,在add(2)的时候,compare(2, 1) 返回结果小于0,所以最终元素2被插入堆顶,换句话说就是compare函数比较出的结果小(返回-1,则待插入元素较小)的在堆顶。这里就要明确一个概念,compare(arg1, arg2)函数返回-1,表示arg1较小,此时arg1就更靠近堆顶。
现在来仔细看compare函数,以上述代码为例:
-
n1为待插入元素,即arg1
-
返回 n2 - n1
此时,n1 较n2大的时候,compare返回-1,即对于compare函数,n1此时是较小;
总结:
-
compare(arg1, arg2)返回-1,表明arg1较小
-
compare函数判定为较小的则更加靠近栈顶
