

正则表达式要么匹配字符,要么匹配位置。
1 正则表达式字符匹配攻略
1.1 两种模糊匹配
1.1.1 横向模糊匹配
概念:一个正则可匹配的字符串的长度不是固定的,可以是多种情况。
例如:/ab{2,4}c/,表示'abbc'或'abbbc'或'abbbbc'。
1.1.2 纵向模糊匹配
概念:一个正则匹配的字符串,具体到某一个字符时,它可以不是某个确定的字符,可以有多种可能。
例如:/a[bcd]e/,表示'abe'或'ace'或'ade'。
1.2 字符组
需要强调的是,虽然叫字符组,但只是其中一个字符。
例如:[abc]指的是匹配一个字符,可以是'a'、'b'、'c'其中的一个。
1.2.1 范围表示法
对于数字[0123456789]可以用[0-9]表示
对于小写字母[abcd]可以用[a-d]表示
对于小写字母[ABCD]可以用[A-D]表示
1.2.2 排除字符组
即不可以是字符组中的任一字符
例如:[^abc]表示不能是'a'或'b'或'c',但可以是'a'和'b'和'c'之外的任意字符。
注意:^必须放在字符组的最前面,否则^将会作为字符被匹配。
var reg1 = /[^abc]/;
reg.test('a'); // false
reg.test('d'); // true
var reg2 = /[a^bc]/;
reg.test('a'); // true
reg.test('d'); // false
reg.test('^'); // true
1.2.3 常见的字符组简写形式
了解了上面之后,我们接着对字符组的简写进行了解
| 字符组 | 具体含义 |
|---|---|
| \d | 表示[0-9]。表示0到9其中一位数字。 记忆方式:其英文是digit(数字) |
| \D | 表示[^0-9]。表示除了0到9之外的任意字符 记忆方式:大D是小d的反面 |
| \w | 表示[0-9a-zA-Z_]。表示数字、字母和下划线。 记忆方式:w是word的简写,也称单词字符。 |
| \W | 表示[^0-9a-zA-Z_]。表示单词字符之外的任意字符。 |
| \s | 表示[ \t\b\n\r\f]。表示空白符,包括空格、水平制表符、垂直制表符、换行符、回车符、换页符。 |
| \S | 表示[^ \t\b\n\r\f]。表示非空白字符。 |
| . | 表示[^\n\r\u2028\u2029]。通配符,表示几乎任意字符。换行符、回车符、行分隔符和段分隔符除外。 |
上面的字符组都不能表示任一字符,但通过上面的字符组进行组合就可以得到任一字符。
[\d\D]、[\w\W]、[\s\S]、[^],这其中的一组都可以表示任一字符。
扩展:Javascript中的特殊字符一共有13个,如下
| Unicode字符值 | 转义序列 | 含义 | 类别 |
|---|---|---|---|
| \u0008 | \b | Backspace | |
| \u0009 | \t | Tab | 空白 |
| \u000A | \n | 换行符(换行) | 行结束符 |
| \u000B | \v | 垂直制表符 | 空白 |
| \u000C | \f | 换页 | 空白 |
| \u000D | \r | 回车 | 行结束符 |
| \u0022 | " | 双引号 (") | |
| \u0027 | ' | 单引号 (') | |
| \u005C | \ | 反斜杠 () | |
| \u00A0 | 不间断空格 | 空白 | |
| \u2028 | 行分隔符 | 行结束符 | |
| \u2029 | 段落分隔符 | 行结束符 | |
| \uFEFF | 字节顺序标记 | 空白 |
1.3 量词
量词也称重复。
{m,n}表示重复m到n之间的次数,包括m和n,m和n之前不能有空格。
例如/a{2,4}/表示字符a可重复的次数为2到4次。
1.3.1 简写形式
| 量词 | 具体含义 |
|---|---|
| {m,n} | 表示至少出现m次 |
| {m} | 即{m,m},表示出现m次。 |
| ? | 即{0,1},表示出现0次或1次。记忆方式:问号的意思:有吗? |
| + | 即{1,},表示至少出现1次 |
| * | 即{0,},表示出现任意次,也可能不出现。 |
1.3.2 贪婪匹配和惰性匹配
- 贪婪匹配
贪婪匹配指
尽可能多的匹配。
在下面栗子中,刚开始匹配到两个数字时,没有停下来,而是继续尝试匹配后面的数字。
var reg = /\d{2,4}/g;
var str = '12 123 1234 12345';
console.log(str.match(reg));
// => ["12", "123", "1234", "1234"]
- 惰性匹配
惰性匹配和贪婪匹配则相反,它是尽可能少的匹配。
下面栗子中,当连续匹配到2个数字时,就不再往下尝试了,并进行下一轮匹配。
var reg = /\d{2,4}?/g;
var str = '12 123 1234 12345';
console.log(str.match(reg));
// => ["12", "12", "12", "34", "12", "34"]
贪婪量词和惰性量词的的表示:
记忆:惰性量词就是在贪婪量词后面加个问号
| 贪婪量词 | 惰性量词 |
|---|---|
| {m,n} | {m,n}? |
| {m} | {m}? |
| ? | ?? |
| + | +? |
| * | *? |
判断图片格式是否为jpg或jpeg格式时,可以使用以下正则
var reg = /\.jpe?g$/;
reg.test('jpg'); // true
reg.test('jpeg'); // true
1.4 多选分支
一个模式可以实现横向和纵向匹配。而多选分支可以支持多个子模式任选其一。
具体形式如: (p1|p2|p3),其中p1、p2、p3是子模式,用|分割,表示其中的一个。
var reg = /[a-z]|[A-Z]/;
reg.test('a'); // true
reg.test('A'); // true
reg.test('1'); // false
分支结构也是惰性的,如果匹配到前面的模式,后面就不会再匹配了。
var str = 'hello world';
var reg1 = /hello|hello world/g;
var reg2 = /hello world|world/g;
console.log(str.match(reg1))
// => ["hello"]
console.log(str.match(reg2))
// => ["hello world"]
// 字符串str都可以匹配两种模式中的一个,但当匹前面匹配上了,后面就不会再尝试了,所以说分支结构也是惰性的。
1.5 修饰符
es5中修饰符,共3个
| 符号 | 含义 |
|---|---|
| g | 全局匹配,即在目标字符串中找到满足匹配模式的所有字串 |
| m | 多行匹配 |
| i | 忽略字母大小写 |
1.6 案例分析
匹配字符,无非就是字符组,量词和分支结构的组合使用罢了。
1.6.1 匹配16进制颜色值
要求匹配:
#ff00AA
#f0A
首先,表示一个16进制时,可以用字符组[0-9a-zA-Z]。
其次,字符可以出现3次或6次。
var reg = /#([0-9a-zA-Z]{6}|[0-9a-zA-Z]{3})/g;
console.log(str.match(reg));
// => ["#ff00AA", "f0A"]
// 分支中[0-9a-zA-Z]{6}需要写在[0-9a-zA-Z]{3}的前面,否则对于6位颜色值将匹配不全。
1.6.2 匹配id
要求从
<div id="container" class="container"></div>
提取出id="container"。
可能最先想到的正则是:
var reg = /id=".*"/g;
var str = '<div id="container" class="container"></div>';
console.log(str.match(reg));
// => ["id="container" class="container""]
产生上述的原因是通配符可以匹配";
可以这样改进,把通配符换成除了"之外的任意字符:
var reg = /id="[^"]*"/g;
var str = '<div id="container" class="container"></div>';
console.log(str.match(reg));
// => ["id="container""]
2 正则表达式位置匹配攻略
对匹配位置的理解,可能稍微难一点。
2.1 位置匹配
先了解一下匹配位置的符号有哪些,
在es5中,匹配位置共有6个锚:^、$、\b、\B、(?=p)、(?!p)
| 符号 | 含义 |
|---|---|
| ^ | 匹配开头位置,在多行匹配行开头 |
| $ | 匹配结束位置,在多行匹配中匹配行结尾 |
| \b | 匹配单词边界,具体就是\w和\W之间的位置,也包括\w与^之间的位置,和\w与$之间的位置。 |
| \B | 非单词边界 |
| (?=p) | p是一个子模式,即p前面的位置。换句话,这个位置后面必须匹配p。 |
| (?!p) | 即(?=p)的反面的意思,除了p前面位置的所有位置。换句话,p前面的位置之后不能匹配p。 |
对于位置的理解,我们可以理解成除了字符之外的空字符串""。
比如"hello"字符串中有六个空串位置:

栗子1:把字符串的开头和结尾的空格去掉
var reg = /^\s|\s$/g;
var str = ' hello ';
console.log(str.replace(reg, ''));
// => "hello"
栗子2:单词边界\b
var reg = /\b/g;
var str = 'hello 2020';
console.log(str.replace(reg, '*'));
// => *hello* *2020*"
栗子3:非单词边界\B
var reg = /\B/g;
var str = 'hello 2020';
console.log(str.replace(reg, '*'));
// => "h*e*l*l*o 2*0*2*0"
栗子4:(?=p)
var reg = /(?=2)/g;
var str = 'goodbye 2019';
console.log(str.replace(reg, '*'));
// => "goodbye *2019"
栗子5:(?!p)
var reg = /(?!2)/g;
var str = 'goodbye 2019';
console.log(str.replace(reg, '*'));
// => "*g*o*o*d*b*y*e* 2*0*1*9*"
// 除了2前面这个位置,其他位置都会被替换成*
栗子4和栗子5刚开始学可能会比较难理解,不过多看学写几遍应该就能理解了。
2.2 案例分析
2.2.1 数字的千位分隔符表示法
比如把"12345678"变成"12,345,678"
可见是在每倒数三个数之后的位置上加上","
大概的思路是:
2.2.1.1 弄出最后一个逗号
使用(?=\d{3}\b),找出逗号的位置,该位置之后有三个数字并且以空格符结束
var reg = /(?=\d{3}\b)/g;
var str = '12345678';
console.log(str.replace(reg, ','))
// => "12345,678"
2.2.1.1 弄出所有逗号
使用(?=\d{3}+\b),每三个数字可作为一组
var reg = /(?=(\d{3})+\b)/g;
var str = '12345678';
console.log(str.replace(reg, ','))
// => "12,345,678"
2.2.1.3 匹配其他案例
匹配"123456789"
var reg = /(?=(\d{3})+\b)/g;
var str = '12345678';
console.log(str.replace(reg, ','))
// => ",123,456,789"
如果字符数量为3的倍数时,则第一个位置也符合条件,所以要去掉该位置的匹配,可以用(?!^)。
var reg = /(?!^)(?=(\d{3})+\b)/g;
var str = '123456789';
console.log(str.replace(reg, ','))
// => "123,456,789"
2.2.1.4 支持其他格式
如果要把"12345678 123456789"替换成"12,345,678 123,456,789",应该怎么做呢?
方法是三个数字的前面不能是单词边界,加上限制后,即(\B\d{3})+\b)
var reg = /(?!^)(?=(\B\d{3})+\b)/g;
var str = '12345678 123456789';
console.log(str.replace(reg, ','))
// => "12,345,678 123,456,789"
3 正则表达式括号的作用
对括号的使用是否得心应手,是衡量对正则的掌握水平的一个侧面标准。
3.1 分组和分支结构
// 分组
var reg1 = /(ab)+/;
// 分支结构
var reg2 = /a|b/;
对于以上两个正则表达式,reg1中a和b用括号包起来,表示的是一个分组,reg2中a和b用|分开,表示的是一个分支结构。
3.2 分组引用
这是括号的一个重要作用,有了它,我们就可以进行数据提取,以及更强大的替换操作.
3.2.1 提取数据
var reg1 = /\d{4}-\d{2}-\d{2}/;
var reg2 = /(\d{4})-(\d{2})-(\d{2})/;
上面两个正则唯一不同的是reg2每个子模式中都用()括起来,这使得reg2拥有分组的功能;
var reg1 = /\d{4}-\d{2}-\d{2}/;
console.log('2020-01-01'.match(reg1))
// => ["2020-01-01", index: 0, input: "2020-01-01", groups: undefined]
var reg2 = /(\d{4})-(\d{2})-(\d{2})/;
// => ["2020-01-01", "2020", "01", "01", index: 0, input: "2020-01-01", groups: undefined]
以上都能匹配"2020-01-01"这个日期,但reg2除了整体匹配之外,还对每个分组进行了匹配,即对(\d{4})、(\d{2})、(\d{2})进行了匹配,从而返回了数组里面包含了年、月、日。
另,若在正则后面加上全局修饰符g,则返回的是整体匹配的结果,不再对分组进行匹配。
var reg2 = /(\d{4})-(\d{2})-(\d{2})/g;
// => ["2020-01-01"]
3.2.2 替换
如果想把yyyy-mm-dd格式替换成mm-yy-dd格式,可以在replace里用第二个参数指代相应的分组。
var reg = /(\d{4})-(\d{2})-(\d{2})/;
var result = '2020-01-02'.replace(reg, '$2-$1-$3')
// => 01-2020-02
上面也等价于:
var reg = /(\d{4})-(\d{2})-(\d{2})/;
var result = '2020-01-02'.replace(reg, function () {
return RegExp.$2 + '-' + RegExp.$1 + '-' + RegExp.$3
})
// => 01-2020-02
3.3 反向引用
除了使用相应的api来引用分组,也可以在正则本身里引用分组.但只能引用之前的分组,即反向引用。
栗子:写一个支持以下三个日期的正则
2020-01-02
2020/01/02
2020.01.02
最先想到的是:
var reg = /\d{4}(\/|\.|-)\d{2}(\/|\.|-)\d{2}/;
reg.test('2020-01-02'); // true
reg.test('2020/01/02'); // true
reg.test('2020.01.02'); // true
reg.test('2020/01.02'); // true
上面最后一个结果显然不是我们想要的。处理这类问题时,我们可以使用反向引用。
var reg = /\d{4}(\/|\.|-)\d{2}\1\d{2}/;
reg.test('2020-01-02'); // true
reg.test('2020/01/02'); // true
reg.test('2020.01.02'); // true
reg.test('2020/01.02'); // false
即把第二个分组写成\1,这里的意思是引用之前的第一个分组,如果第一个分组匹配到/,那么这里也必须匹配到/。
了解了\1的意思,那么\2、\3等表示的是引用前面的第二个、第三个分组等。
3.4 非捕获括号
如果只想要括号的最原始功能,但不会去引用它,既不在api里引用,也不在正则里反向引用。
此时可以使用非捕获括号(?:p),例如
var reg = /\d{4}(?:\/|\.|-)\d{2}\1\d{2}/;
reg.test('2020-01-02'); // false
由于使用了非捕获型括号,使得\1不能对之前的分组进行引用,那么此时\1表示的是对1进行转义。
3.5 案例分析
3.5.1 将每个单词的首字母转化为大写
function titleize (str) {
var reg = /(?:^|\s)\w/g;
return str.replace(reg, function(c) {
return c.toUpperCase()
})
}
console.log(titleize('hello world'));
// => "Hello World"
使用了非捕获组,那么replace的第一个参数指的就是匹配的字符串。
3.5.2 驼峰化
function camelize (str) {
var reg = /[-](\w)/g;
return str.replace(reg, function(match, c) {
return c.toUpperCase();
})
}
console.log(camelize('-hello-world'));
// => "HelloWorld"
使用了分组,那么replace的第一个参数指的匹配整体字符串,第二个参数值得是匹配组的内容,即match分别为"-h"和"-w",分别被替换成"H"和"W"。
3.5.3 HTML转义和反转义
3.5.3.1 将HTML特殊字符转化成等值的实体
function escapeHTML (str) {
var escapeChars = {
'<': '<',
'>': '>',
'"': '"',
'&': '&',
'\'': '''
}
var reg = /[<>"&']/g;
return str.replace(reg, function(c) {
return escapeChars[c]
})
}
console.log(escapeHTML('<div class="hello"></div>'));
// => "<div class="hello"></div>"
3.5.3.1 将等值的实体转化成HTML特殊字符
function unEscapeHTML (str) {
var escapeChars = {
'<': '<',
'>': '>',
'"': '"',
'&': '&',
''': '\''
}
var reg = /<|>|"|&|'/g;
return str.replace(reg, function(c) {
return escapeChars[c]
})
}
console.log(unEscapeHTML("<div class="hello"></div>"));
// => "<div class="hello"></div>"
4 正则表达式的拆分
对一门语言的掌握程度怎么样,可以有两个角度来衡量:读和写。
不仅要求自己能解决问题,还要看懂别人的解决方案。
4.1 操作符的优先级
| 操作符描述 | 操作符 | 优先级 |
|---|---|---|
| 转义符 | \ | 1 |
| 括号和方括号 | (···)、(?:···)、(?=···)、(?!···)、[···] | 2 |
| 量词限定符 | {m}、{m,n}、{m,}、?、*、+ | 3 |
| 位置和序列 | ^、$、\、一般字符 | 4 |
| 管道符(竖杠) | | | 5 |
这里,我们可以来分析一个正则:/ab?(c|de*)+|fg/
根据优先级,首先,(c|de*)是一个整体,这个整体又可以分为c和de*,de又可以分为d和e
接着是(c|de*)+
再把ab?(c|de*)+分为ab?和(c|de*)+,ab?又可以分为a和b?
最后再把整体分为ab?(c|de*)+和fg
5 正则表达式回溯法原理
学习正则表达式,是需要懂一点匹配原理的。
而研究匹配原理时,有两个字出现频率比较高:“回溯”。
回溯法(探索与回溯法)是一种
选优搜索法,又称为试探法,按选优条件向前搜索,以达到目标。但当探索到某一步时,发现原先选择并不优或达不到目标,就退回一步重新选择,这种走不通就退回再走的技术为回溯法,而满足回溯条件的某个状态的点称为“回溯点”。百度百科
下面对回溯进行探究
为了减少方便理解,以下所讲的子表示式即正则里的内容,字符则是指目标字符串里的内容。
例如:
正则/ab{1,3}c/包含了子表达式a,子表达式b{1,3}和子表达式b;
字符串'abc'包含了字符"a",字符"b"和字符"c";
5.1 没有回溯的匹配
假设我们的正则是/ab{1,3}c/。
当目标字符串是"abbbc"时,就没有所谓的"回溯"。其匹配过程是:
其中字表达式b{1,3}表示"b"字符连续出现1到3次。

5.2 有回溯的匹配
如果目标字符串是"abbc",中间就有回溯。
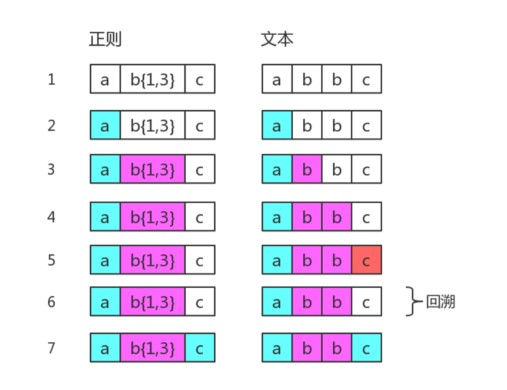
"b",准备尝试第三个字符"b"时,发现接下来的字符是"c",那么认为b{1,3}就已经匹配完毕。然后又回到之前匹配2个字符的状态,即第6步和第4步一样,最后再用子表达式c,去匹配字符"c",此时,整个表达式匹配成功了。第6步,就是“回溯”。
可能大家有个疑问,为什么子表达式b{1,3}匹配了两个字符"b"之后,还要再进行第3个字符匹配呢?
因为b{1,3}属于贪婪匹配,将尽可能多的匹配,当匹配了两个之后,还会进行第三个匹配,这个在后面会讲到。
再一个例子,目标字符串是"abbbc",匹配过程是:
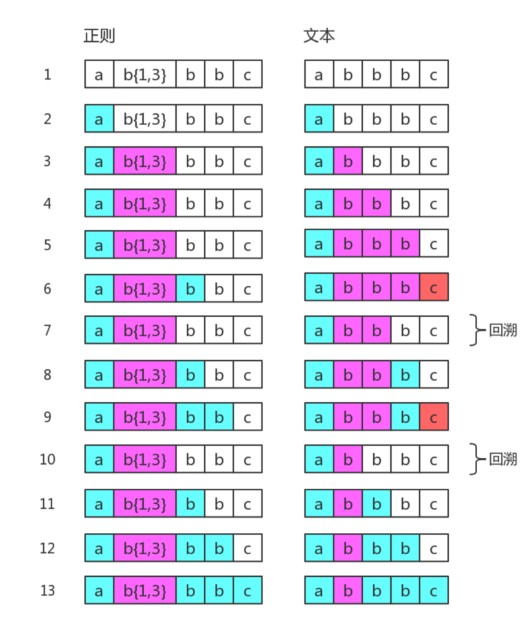
"b",而第10步与第3步一样,此时b{1,3}只匹配了一个"b",这就是b{1,3}的最终匹配结果。
5.3 常见的回溯形式
5.3.1 贪婪量词
之前的栗子都是贪婪量词相关的。比如b{1,3},因为其是贪婪的,尝试可能的顺序是从多往少的方向去尝试。首先会尝试"bbb",然后看整体是否能匹配。不能匹配时,吐出一个"b",即在"bb"的基础上,再继续尝试。如果还不行,再吐出一个,再试。如果还不能行呢?那就匹配失败了。
当多个贪婪量词并存,并有冲突时,将优先匹配前面的,因为深度优先。
栗子:
var str = '12345';
var reg = /(\d{1,3})(\d{1,3})/;
console.log(str.match(reg));
// => ["12345", "123", "45", index: 0, input: "12345", groups: undefined]
5.3.2 惰性量词
惰性量词就是在贪婪量词后面加个问号。表示尽可能少的匹配。
虽然惰性量词不贪,但也有回溯的现象。
比如正则是:/^\d{1,3}?\d{1,3}$/
目标字符串是:"12345"
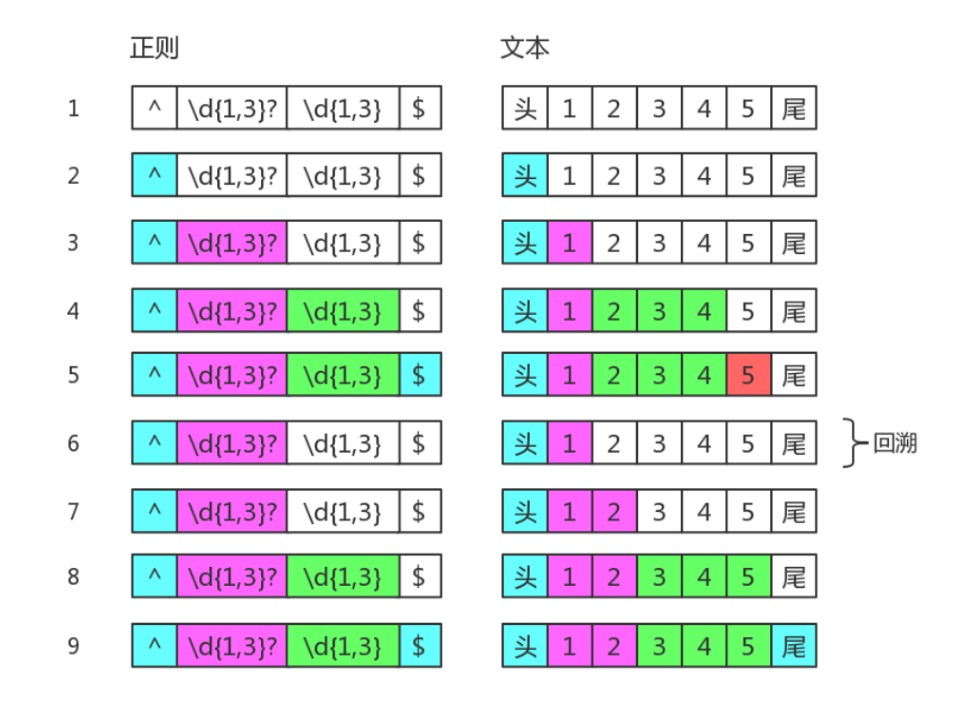
5.3.3 分支结构
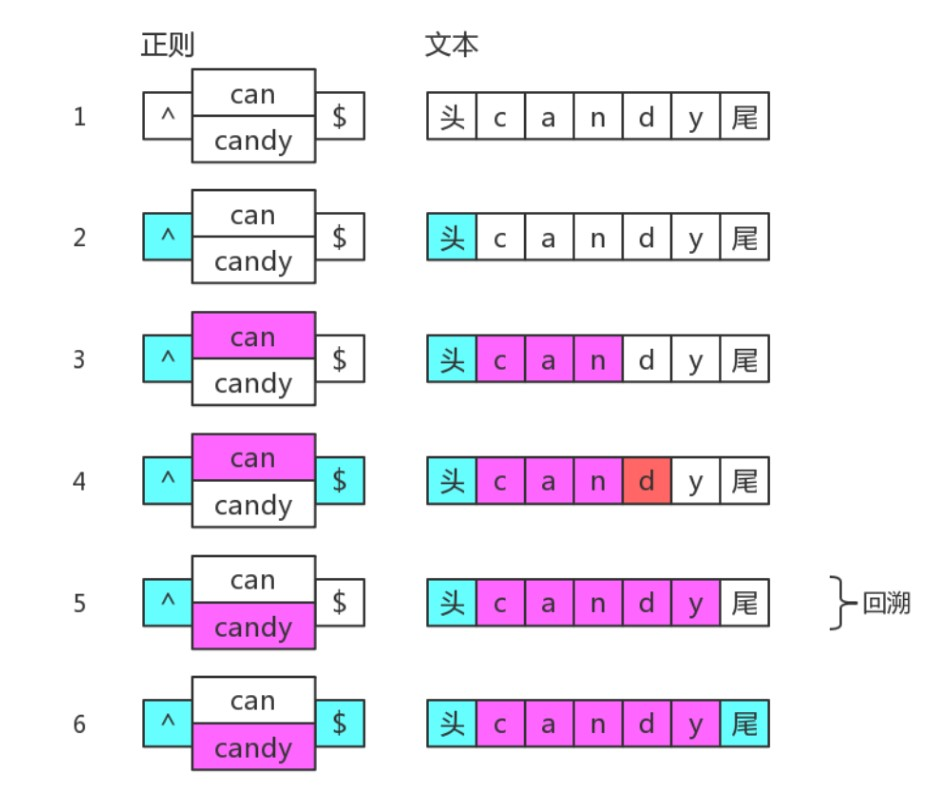
我们知道分支也是惰性的,比如/can|candy/,去匹配字符串"candy",得到的结果是"can",因为分支会一个一个去尝试,如果前面满足了,后面就不再试验了。
分支结构,可能前面的子模式形成了局部匹配,如果接下来表达式整体不匹配时,仍会继续尝试剩下的分支。这种尝试可以看成一种回溯。
比如正则:/^(?:can:candy)$/
目标字符串:"candy",匹配过程是:
6 正则表达式编程
在进行下列文章前,有必要先了解一下正则的6个方法,其中字符串实例4个(search、split、match、replace),正则实例2个(test、exec)。
字符串实例方法参数为正则表达式,正则实例方法参数则为字符串。
6.1 正则表达式的四种操作
验证、切分、提取、替换。
6.1.1 验证
使用search
var reg = /\d/;
var str = 'hello2020';
console.log(!!~str.search(reg));
// => true
// ~是按位取反运算符,当数值为-1时,则~(-1)为0,通过!!~可以判断是否为-1
使用test
var reg = /\d/;
var str = 'hello2020';
console.log(reg.test(str));
// => true
// 直接判断
使用match
var reg = /\d/;
var str = 'hello2020';
console.log(!!str.match(reg));
// => true
// 通过是否返回空串判断
6.1.2 切分
栗子:切分日期
var reg = /\//;
var str = '2020/01/02';
console.log(str.split(reg));
// => ["2020", "01", "02"]
6.1.3 提取
栗子:提取日期 使用match
var reg = /(\d{4})\/(\d{2})\/(\d{2})/;
var str = '2020/01/02';
console.log(str.match(reg));
// => ["2020/01/02", "2020", "01", "02", index: 0, input: "2020/01/02", groups: undefined]
使用exec
var reg = /(\d{4})\/(\d{2})\/(\d{2})/;
var str = '2020/01/02';
console.log(reg.exec(str));
// => ["2020/01/02", "2020", "01", "02", index: 0, input: "2020/01/02", groups: undefined]
使用test
var reg = /(\d{4})\/(\d{2})\/(\d{2})/;
var str = '2020/01/02';
reg.test(str);
console.log(RegExp.$1, RegExp.$2, RegExp.$3)
// => 2020 01 02
使用search
var reg = /(\d{4})\/(\d{2})\/(\d{2})/;
var str = '2020/01/02';
str.search(reg);
console.log(RegExp.$1, RegExp.$2, RegExp.$3);
// => 2020 01 02
6.1.4 替换
栗子:替换日期格式
var reg = /\//g;
var str = '2020/01/02';
console.log(str.replace(reg, '-'));
// => 2020-01-02
6.2 相关api注意要点
6.2.1 search和match的参数问题
字符串实例的4个方法参数都支持正则和字符串。
但search和match,会把字符串转换为正则。
var str = '2020.01.02';
console.log(str.search('.'));
// => 0
这里会把.转化为正则操作符.,则匹配到是第一个字符。
需要把上面改为:
console.log(str.search('\\.'));
console.log(str.search(/\./));
// => 4
// => 4
console.log(str.match('.'));
// => ["2", index: 0, input: "2020.01.02", groups: undefined]
需要改为:
console.log(str.match('\\.'));
console.log(str.match(/\./));
6.2.2 match返回结果的格式问题
match返回格式,与是否有修饰符g有关。
没有g,则是返回标准模式,返回数组第一个是整体匹配内容,接着是捕获组的内容,然后是整体匹配的第一个下标,输入的字符串,捕获组的名称。
有g,则返回所有匹配的内容。
var str = '2020.01.02';
var reg1 = /\b(\d+)\b/;
var reg2 = /\b(\d+)\b/g;
console.log(str.match(reg1));
// => ["2020", "2020", index: 0, input: "2020.01.02", groups: undefined]
console.log(str.match(reg2));
// => ["2020", "01", "02"]
6.2.3 exec比match更强大
当正则没有g时,使用match返回的信息更多。但有了g后,就没有index等信息了。
而使用exec可以解决这个问题,它能接着上一次匹配后继续匹配。
var str = '2020.01.02';
var reg = /\b(\d+)\b/g;
console.log(reg.exec(str));
console.log(reg.lastIndex);
// => ["2020", "2020", index: 0, input: "2020.01.02", groups: undefined]
// => 4
console.log(reg.exec(str));
console.log(reg.lastIndex);
// => ["01", "01", index: 5, input: "2020.01.02", groups: undefined]
// => 7
从上述代码中,使用exec时,经常需要配合使用while循环。
6.2.4 修饰符g,对exec和test的影响
上面用到的lastIndex属性,表示尝试匹配时,从字符串的lastIndex位开始去匹配。
字符串的4个方法,每次匹配时,都是从0开始的,即lastIndex属性始终不变。
而正则实例的两个方法exec、test,如果是全局匹配时,每一次匹配完成后,都会修改lastIndex。
6.2.5 test整体匹配时,需要^和$
6.2.6 split相关注意事项
split可以有第二个参数,表示数组最大长度
var str = 'hello 2020';
console.log(str.split(/\s/, 1));
// => ["hello"]
6.2.7 replace是很强大的
当第二个参数是字符串时,如下字符有特殊含义
| 属性 | 描述 |
|---|---|
| $1,$2,...,$99 | 匹配第1-99个分组里捕获的文本 |
| $& | 匹配到的子串文本 |
| $` | 匹配到子串的左边文本 |
| $' | 匹配到子串的右边文本 |
| ? | 美元符号 |
栗子:
把"2,3,5",变成"5=2+3":
var str = '2,3,5';
var reg = /(\d+),(\d+),(\d+)/;
console.log(str.replace(reg, '$3=$1+$2'));
// => 5=2+3
把"2+3=5",变成"2+3=2+3=5=5":
var str = '2+3=5';
var reg = /=/;
console.log(str.replace(reg, "=$`=$'="));
// => 2+3=2+3=5=5
7 案例分析
7.1 查询url参数
思路:
找出url参数中的key和value
key可以用表达式([^&=?]+)
value可以用表达式([^&#]*)
通过分组形式可以匹配到每个分组的内容,即key和value
var getQueryString = (function(){
var search = location.search;
var query = {};
search.replace(/([^&=?]+)=([^&#]*)/g, function(match, key, value) {query[key] = value})
return function (key) {
return query[key]
}
})();
7.2 密码验证
需要满足以下条件
1、由数字、字母组成
2、密码长度6-16位
3、至少包含两种符号
思路:
第一,满足由数字、字母组成、密码长度6-16位的正则
/^[a-zA-Z0-9]{6,16}$/
var reg = /^[a-zA-Z0-9]{6,16}$/;
var psw = 'ab12AB';
console.log(reg.test(psw));
// => true
第二,满足至少包含一种字符的条件
var reg = /(?=.*[a-z])^[a-zA-Z0-9]{6,16}$/;
var psw1 = 'AB12AB';
var psw2 = 'ab12AB';
console.log(reg.test(psw1));
// => false
console.log(reg.test(psw2));
// => true
第三,满足至少包含两种字符的条件
两两组合共有3种可能。
var reg = /((?=.*[a-z])(?=.*[A-Z])|(?=.*[a-z])(?=.*[0-9])|(?=.*[0-9])(?=.*[A-Z]))^[a-zA-Z0-9]{6,16}$/;
var psw1 = 'ab12ab';
var psw2 = 'abABab';
var psw3 = 'AB12AB';
console.log(reg.test(psw1));
// => true
console.log(reg.test(psw2));
// => true
console.log(reg.test(psw3));
// => true
总结
对正则表达式的理解,首先要知道它能干什么,其实总结起来它只有两个特性,要么匹配位置,要么匹配字符。在学习的过程中,要牢记这两个特性,才不会学的比较混乱。在学习的同时,结合一个栗子深入分析,这样理解起来会比较容易。
如有纰漏,留言区见哦~
参考资料:javascript正则表达式迷你书
