

变量类型
JS 的数据类型分类
ECMAScript 中定义了 6 种原始类型:
booleanstringnumbernullundefinedsymbol(ES6 新定义)
类型判断用到哪些方法?
-
typeof:得到的值有以下几种类型:undefined、boolean、number、string、object、function、symbol,对于原始数据类型,要注意typeof null = 'object'。对于引用数据类型的判断,除typeof function的值为function,其余均为objcet -
instanceof:用于实例和构造函数的对应。例如判断一个变量是否是数组,使用typeof无法判断,但可以使用[1, 2] instanceof Array来判断。因为,[1, 2]是数组,它的构造函数就是Array。
原始类型和对象类型的区别
- 在 JS 中,除了原始类型那么其他的都是对象类型了。对象类型和原始类型不同的是,我们在创建一个变量的时候,如果是原始类型,那JS引擎会直接在内存的栈中初始化一个原始类型并返回;如果是对象类型,那么JS引擎会先在内存堆中初始化并创建一个对象,然后在栈中存储这个对象的指针。所以对于引用类型,变量存储的是一个指针,原始类型存储的是值。
- 在参数传递方式上,首先JS中所有函数参数都是按值传递的,值传递的本质是复制,不管是原始数据类型的变量还是对象类型的变量,都会复制一个副本到函数内部。但由于对象类型变量存储的是一个指向堆内存的指针,所以函数内部复制到的也是这样一个指针,复制一个完整的对象。所以通过这个内部变量对对象做的任何修改,都会同步影响到其他持有这个对象指针的变量。这样做兼顾了内存占用与访问效率。
作用域和闭包
执行上下文
JS在编译一段代码的过程中,会为其生成一个对应的执行环境,这个执行环境就是执行上下文,在执行上下文环境中,保存着代码块的变量环境、词法环境、外层作用域链指针,以及this指针等。
JS的执行上下文环境分为以下三种:
全局执行上下文:当 JavaScript 执行全局代码的时候,会编译全局代码并创建全局执行上下文,而且在 整个页面的生存周期内,全局执行上下文只有一份。函数执行上下文:当调用一个函数的时候,函数体内的代码会被编译,并创建函数执行上下文,一般情况 下,函数执行结束之后,创建的函数执行上下文会被销毁。eval执行上下文:当使用eval函数的时候,·eval·的代码也会被编译,并创建执行上下文。
执行上下文是JS代码编译的产物之一,里面存放了代码块里的各种变量,后续对代码执行时对变量的各种操作,都是基于这个执行上下文环境的。
调用栈
JavaScript 引擎正是利用栈来管理执行上下文的。在执行上下文创建好后,JavaScript引擎会将执行上下文压入栈中,通常把这种用来管理执行上下文的栈称为执行上下文栈,又称调用栈。
执行上下文主要有全局执行上下文与函数执行上下文,JS在执行一段代码的时候,最开始会初始化一个全局执行上下文,并将这个全局执行上下文压到调用栈中,当执行到某个函数时,又会为这个函数创建执行上下文,并将函数的执行上下文入栈,如果函数里面调用了其他函数,则会继续为调用的函数创建新的执行上下文并且入栈,函数执行完后,函数执行上下文出栈。
变量提升
所谓的变量提升,是指在JS代码执行过程中,JS引擎把变量的声明部分和函数的声明部分提升到代码开头的“行为”。
不过这也只是一个比较形象的解释,实质上变量和函数声明在代码里的位置是不会改变的,而是引擎在编译阶段将变量与函数的声明放入当前代码块执行上下文环境的变量环境中去,并且对于变量会默认设置为undefined。在代码执行阶段,JS引擎会从变量环境中去查找自定义的变量和函数。
具体有以下几点需要注意:
- 如果存在两个同名函数,后者声明会覆盖前者的声明
- 如果变量与函数同名,那么JS引擎会忽略变量声明
此外,变量提升存在变量覆盖、变量污染等设计缺陷
作用域
作用域就是变量和函数的可使用范围,在ES6之前,JS的作用域只有两种:全局作用域和函数作用域。
全局作用域:中的对象在代码中的任何地方都能访问,其生命周期伴随着页面的生命周期。函数作用域:就是在函数内部定义的变量或者函数,并且定义的变量或者函数只能在函数内部被访问。函数执行结束之后,函数内部定义的变量会被销毁。
es6通过引入let与const关键字支持了块级作用域,用let或const声明的变量存放在当前执行上下文环境的词法环境中。
在词法环境内部,维护了一个小型栈结构,栈底是函数最外层通过let或者const声明的变量,进入一个作用域块后,就会把该作用域块内部通过let或者const声明的变量压到栈顶;当作用域执行完成之后,该作用域的信息就会从栈顶弹出,这就是词法环境的结构。
当JS需要查询某个变量时,会先在词法环境这个变量栈中从栈顶往栈底一层层查找,查到了就直接返回,如果都查不到,再会到变量环境中去找。这就是JS变量在当前执行上下文内变量查找的步骤。
作用域链
每个执行上下文环境中,都保存着一个称为outer外部引用,来指向外部的上下执行文环境。当一段代码使用了某个变量的时候,JS引擎会先在当前的执行上下文环境中查询,查到就返回,查不到就会沿着outer指向的上下文环境继续查找。这个通过outer串起来的查询链我们就称之为作用域链。
JS的词法作用域是作用域链的基础,词法作用域是在代码编译阶段就确定的,同样的作用域链在代码编译阶段就确定了,与函数的执行阶段如何调用无关。
闭包
在JS中,根据词法作用域的规则,内部函数总是可以访问其外部函数中声明的变量,当通过调用一个外部函数返回他的一个内部函数后,即使该外部函数已经执行结束了,但是内部函数引用外部函数的变量依然保存在内存中,我们就把这些变量的集合称为闭包。
如何正确判断this?箭头函数的this是什么?
this是和执行上下文绑定的,每个执行上下文中都有一个this,this指向与运行时的调用状态相关。
function foo() {
console.log(this.a)
}
var a = 1
foo()
const obj = {
a: 2,
foo: foo
}
obj.foo()
const c = new foo()
- 对于直接调用
foo来说,不管foo函数被放在了什么地方,this一定是window - 对于
obj.foo()来说,我们只需要记住,谁调用了函数,谁就是this,所以在这个场景下foo函数中的this就是 obj 对象 - 对于
new的方式来说,this被永远绑定在了c上面,不会被任何方式改变this - 箭头函数是没有
this的,箭头函数中的this只取决包裹箭头函数的第一个普通函数的this。
如何改变this指向
可以通过调用函数的call()、apply()、bind() 来改变this的指向。
var obj = {
name:'小鹿',
age:'22',
adress:'小鹿动画学编程'
}
function print(){
console.log(this); // 打印 this 的指向
console.log(arguments); // 打印传递的参数
}
// 通过 call 改变 this 指向
print.call(obj,1,2,3);
// 通过 apply 改变 this 指向
print.apply(obj,[1,2,3]);
// 通过 bind 改变 this 的指向
let fn = print.bind(obj,1,2,3);
fn();
-
共同点:三者都能改变this指向,且第一个传递的参数都是this指向的对象,三者都采用的后续传参的形式。 -
不同点:call的传参是单个传递的(试了下数组,也是可以的),而apply后续传递的参数是数组形式(传单个值会报错),而bind没有规定,传递值和数组都可以。call和apply函数的执行是直接执行的,而bind函数会返回一个函数,然后我们想要调用的时候才会执行。
关于this有几点需注意:
- 如果多次调用bind改变this指向,只有第一次会起作用。
- 如果同时出现多种this规则,这时候不同的规则之间会根据优先级最高的来决定 this 最终指向哪里。具体优先级为:
new>call(),apply(),bind()>obj.foo()>foo() - 箭头函数this一旦被绑定就不会再改变。
由于箭头函数没有自己的
this指针,通过call()或apply()方法调用一个函数时,只能传递参数(不能绑定this),他们的第一个参数会被忽略。
对象
new操作符具体干了什么?
- 创建一个新对象。
- 这个新对象的
__proto__属性指向原函数的prototype属性。(即继承原函数的原型)。 - 将构造函数的
this绑定到新创建的对象上去,并使用apply执行构造器函数,这样构造函数的属性和方法就被添加到新创建的对象中去了。 - 返回新对象,如果构造函数有返回对象就将此对象返回,否则,直接返回第一步创建的对象。
// 1、Con: 接收一个构造函数
// 2、args:传入构造函数的参数
function create(Con, ...args){
let obj = {};
obj._proto_ = Con.prototype;
let result = Con.apply(obj,args)
return result instanceof Object ? result : obj;
}
// 构造函数
function Test(name, age) {
this.name = name
this.age = age
}
Test.prototype.sayName = function () {
console.log(this.name)
}
// 实现一个 new 操作符
const a = create(Test,'小鹿','23')
console.log(a.age)
对象数据属性与访问器属性的区别
- 数据属性
Configurable:表示能否通过 delete 删除属性从而重新定义属性,能否修改属性的特性,或者能否把属性修改为访问器属性。Enumerable:表示能否通过 for-in 循环返回属性。Writable:表示能否修改属性的值。Value:包含这个属性的值。读取属性值的时候,从这个位置读;写入属性值的时候,把新值保存在这个位置。这个特性的默认值为 undefined。
数据属性可以直接定义,如 var p = {name:'xxx'} 这个 name 就是数据属性,直接定义下,相关属性值都是 true ,如果要修改默认的定义值,那么使用 Object.defineProperty() 方法,如下面这个例子
var p = {
name:'dage'
}
Object.defineProperty(p,'name',{
value:'xxx'
})
p.name = '4rrr'
console.log(p.name) // 4rrr
Object.defineProperty(p,'name',{
writable:false,
value:'again'
})
p.name = '4rrr'
console.log(p.name) // again
- 调用Object.defineProperty()方法时,如果不显示指定configurable,enumerable,writable的值,就默认为false
- 如果writable为false,但是configurable为true,还是可以对属性重新赋值的。
- 访问器属性
访问器属性不包含数据值,没有value属性,有get、set属性,通过这两个属性来对值进行自定义的读和写,可以理解为取值和赋值前的拦截器,相关属性如下:
Configurable:表示能否通过 delete 删除属性从而重新定义属性,能否修改属性的特性,或者能否把属性修改为数据属性,默认 falseEnumerable:表示能否通过 for-in 循环返回属性,默认 falseGet:在读取属性时调用的函数。默认值为 undefinedSet:在写入属性时调用的函数。默认值为 undefined
访器属性不能直接定义,必须使用 Object.defineProperty() 来定义。根据 get set 的特性,可以实现对象的代理, vue 就是通过这个实现数据的劫持。
什么是浅拷贝?什么是深拷贝?
深浅拷贝主要针对引用类型来说,浅拷贝只拷贝对象的地址,深拷贝拷贝对象的值。
Object.assign()只能实现一维对象的深拷贝JSON.parse(JSON.stringify(obj))的问题:
undefined、任意的函数以及symbol值,在序列化过程中会被忽略(出现在非数组对象的属性值中时)或者被转换成null(出现在数组中时)。函数、undefined被单独转换时,会返回undefined,如JSON.stringify(function(){}) or JSON.stringify(undefined)。- 对包含循环引用的对象(对象之间相互引用,形成无限循环)执行此方法,会抛出错误。
什么是包装对象
包装对象,主要是为了便于基本类型调用对象的方法。包装对象有三种:String、Number、Boolean。这三种原始类型可以与实例对象进行自动转换,可把原始类型的值变成(包装成)对象,比如在字符串调用函数时,引擎会将原始类型的值转换成只读的包装对象,执行完函数后就销毁。
map和weekMap的区别
map 的 key 可以是任意类型,而 weekMap 的 key 只能是对象类型,是弱引用,因为在 map 中有两个数组,分别存放 key 和对应的 value ,在对 map 操作是,内部会遍历数组,时间复杂度O(n),其次,可能会导致内存泄露,因为数组会一直引用键和值。
相比之下,原生的 WeakMap 持有的是每个键名对象的“弱引用”,这意味着在没有其他引用存在时垃圾回收能正确进行。原生 WeakMap 的结构是特殊且有效的,其用于映射的 key 只有在其没有被回收时才是有效的。
String 和 Array 有哪些常用函数
- String
- split(): 使用指定的分隔符字符串将一个String对象分割成子字符串数组
- slice(): 提取某个字符串的一部分,并返回一个新的字符串,且不会改动原字符串
- substring(): 返回一个字符串在开始索引到结束索引之间的一个子集, 或从开始索引直到字符串的末尾的一个子集
- Array
- slice(): 方法返回一个新的数组对象,这一对象是一个由begin 和end决定的原数组的浅拷贝(包括begin,不包括end)。原始数组不会被改变。
- splice(): 方法通过删除或替换现有元素或者原地添加新的元素来修改数组,并以数组形式返回被修改的内容。此方法会改变原数组。
- push(): 方法将一个或多个元素添加到数组的末尾,并返回该数组的新长度。
- pop(): 方法从数组中删除最后一个元素,并返回该元素的值。此方法更改数组的长度。
- shift():方法从数组中删除第一个元素,并返回该元素的值。此方法更改数组的长度。
- unshift(): 方法将一个或多个元素添加到数组的开头,并返回该数组的新长度(该方法修改原有数组)。
判断数组的几种方法
Array.isArray()ES6 apiobj instanceof Array原型链查找obj.constructor === Array构造函数类型判断Object.prototype.toString.call(obj) === '[object Array]'toString 返回表示该对象的字符串,若这个方法没有被覆盖,那么默认返回 "[object type]",其中type是对象的类型。需要准确判断类型的话,建议使用这种方法
原型与原型链
什么是原型?什么是原型链?
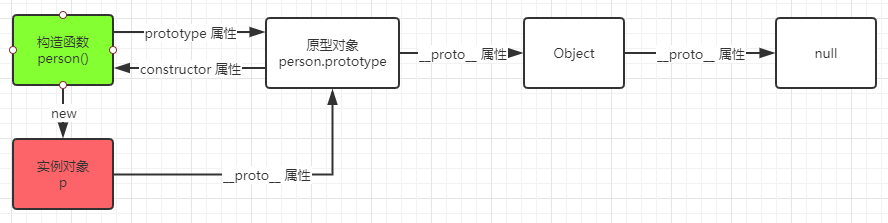
- 实现继承:如果没有原型链,每个对象就都是孤立的,对象间就没有关联,所以原型链就像一颗树干,从而可以实现面对对象中的继承
- 属性查找:首先在当前实例对象上查找,要是没找到,那么沿着
__proto__往上查找 - 实例类型判断:判断这个实例是否属于某类对象
我们创建的每个函数都默认有一个prototype(原型)属性,这个属性指向一个对象,这个对象就是函数的原型对象,在默认情况下,所有原型对象都会自动获得一个constructor(构造函数)属性,这个属性指向原函数,原型对象与函数行程一个相互引用关系。
如果将这个函数作为构造函数,用new关键字创建了一个新实例对象,那么这个新对象默认有一个内部属性__proto__的属性,这个属性也是一个指针,指向创建对象的构造函数的原型对象。我们要读取新对象的某个属性时候,会先在这个对象实例本身查找,找到了就直接返回,找不到则会继续沿着实例的__proto__属性指向的原型对象继续查找,如果有则直接返回,没有则继续沿着原型对象的__proto__指针继续查找 ,这个由__proto__属性串起来的链就是我们说的原型链。
再补充一点就是我们刚才说的沿着原型链往上查找,所有函数的原型对象,本身都是object的实例对象,所以构造函数的原型对象的
__proto__指针是指向object函数的原型对象的,object原型对象上默认实现了一系列方法比如toString(),valueOf(),这也是为何我们创建的对象无需自定义可直接调用一些方法,是因为这些方法其实是在object的原型对象上默认定义好的,我们创建对象后,顺着对象的原型链指针就可以找到这些方法。而object原型对象再往上查找,就是null,原型链遍历终止于null,或者说终止于object的原型对象。
创造对象的几种方式及各自优缺点
1. Object构造函数或对象字面量
// object构造函数
var person = new Object();
person.name = "Nicholas";
person.age = 29;
person.job = "Software Engineer";
person.sayName = function(){
alert(this.name);
};
// 对象字面量
var person = {
name: "Nicholas",
age: 29,
job: "Software Engineer",
sayName: function(){
alert(this.name);
}
};
创建单个对象非常简洁,这两种对象创建方式特别是对象字面量的方式是平时写业务代码中最常见的对象创建方式,不过如果要创建多个对象会产生大量重复代码。
2. 工厂模式
function createPerson(name, age, job){
var o = new Object();
o.name = name;
o.age = age;
o.job = job;
o.sayName = function(){
alert(this.name);
};
return o;
}
var person1 = createPerson("Nicholas", 29, "Software Engineer");
var person2 = createPerson("Greg", 27, "Doctor");
工厂模式解决了创建多个对象产生重复代码的问题,但由于所有的实例都是有
object实例化而来,没有解决对象识别的问题,所有实例都是object类型。
3. 构造函数模式
为了解决类型识别问题,我们引入了构造函数模式,即先定义好一个构造函数,在函数里定义好属性与方法,然后通过new关键字用该构造函数实例化一个对象。
function Person(name, age, job){
this.name = name;
this.age = age;
this.job = job;
this.sayName = function(){
alert(this.name);
};
}
var person1 = new Person("Nicholas", 29, "Software Engineer");
var person2 = new Person("Greg", 27, "Doctor");
由于不同类型的对象可以定义不同的构造函数,所以这种模式解决了对象类型识别的问题,但这种模式还是存在一些问题,即一个构造函数多次实例化的时候,它定义的方法是不能复用的,还是存在重复代码的问题。
4. 原型模式
为了解决构造函数模式中方法重复定义的问题,我们引入了原型模式,与构造函数模式相比,原型模式将构造函数的属性和方法全部定义到到构造函数的原型对象上去。这样通过构造函数实例化的所有实例,共用一套构造函数原型对象上的属性与方法。通过某个实例对构造函数原型对象上任何属性的修改,都会影响到其他的实例对象。
function Person(){
}
Person.prototype.name = "Nicholas";
Person.prototype.age = 29;
Person.prototype.job = "Software Engineer";
Person.prototype.sayName = function(){
alert(this.name);
};
var person1 = new Person();
person1.sayName(); //"Nicholas"
var person2 = new Person();
person2.sayName(); //"Nicholas"
alert(person1.sayName == person2.sayName); //true
原型模式实现了属性与方法的公用,但我们其实想要的只是方法的共用,对象属性我们希望也应该是各个实例对象私有的,在一个实例对象上对其属性的任何修改,不应该对其他实例对象有影响。这是原型模式的一个缺点。
5. 组合使用构造函数模式和原型模式
为了解决原型模式中属性共用的问题,同时保持原型模式的其他优点。我们试着将构造函数模式和原型模式组合起来,具体方式为以构造函数为基础,对象属性还是在构造函数中定义,但是将方法移到构造函数外部,并将其定义到构造函数的原型对象上去。这样我们每次在通过new关键字实例化一个对象的时候,都会重新创建一份实例的属性,不同的实例拥有各自的属性副本,彼此无任何关联。同时,由于在构造函数外部将对象方法定义到了构造函数的实例对象上去,所以这些方法只在函数的原型对象上定义一次,就可以让由这个构造函数实例化的所有实例对象共用。
function Person(name, age, job){
this.name = name;
this.age = age;
this.job = job;
this.friends = ["Shelby", "Court"];
}
Person.prototype = {
constructor : Person,
sayName : function(){
alert(this.name);
}
}
var person1 = new Person("Nicholas", 29, "Software Engineer");
var person2 = new Person("Greg", 27, "Doctor");
组合使用构造函数与原型模式,既解决了原型模式中方法公用问题又让每个实例对象拥有自己独立的属性,是现在对象创建最常见的方式。
6. 动态原型模式
另外还有一种动态原型模式,它是在组合使用构造函数与原型模式的基础上,再次做了一点改进,即将构造函数方法的定义移到函数里面去,还是在够到函数的原型对象上定义方法,同时为了防止每次调用构造函数都执行重新定义方法的问题,会在定义方法前先判断下构造函数的原型对象上是否已经存在该方法,如果存在就不会重复定义。
function Person(name, age, job){
//属性
this.name = name;
this.age = age;
this.job = job;
//方法
if (typeof this.sayName != "function"){
Person.prototype.sayName = function(){
alert(this.name);
}
}
}
var friend = new Person("Nicholas", 29, "Software Engineer");
friend.sayName();
相较于组合模式,动态原型模式在更加简洁,所有代码全部封装在构造函数里,风格很优雅。
js继承方式
1. 原型链模式
原型链是实现js继承的主要方法,它的基本思想是利用原型让一个引用类型继承另一个引用类型的属性和方法。实现的本质是重写原型对象,代之以一个新类型的实例。
function SuperType(){
this.property = true;
}
SuperType.prototype.getSuperValue = function(){
return this.property;
};
function SubType(){
this.subproperty = false;
}
// 继承了 SuperType
SubType.prototype = new SuperType();
// 下面方法必须放在SubType.prototype = new SuperType()之后,且不能用对象字面量形式新增方法,因为会切断原型链
SubType.prototype.getSubValue = function (){
return this.subproperty;
};
var instance = new SubType();
alert(instance.getSuperValue()); //true
原型链的第一个问题是包含引用类型值的原型属性会被所有实例共享,这是不应该的;第二个问题是在创建子类型的实例时,没有办法在不影响所有对象实例的情况下,给超类型的构造函数传递参数。
2. 借用构造函数
为了解决原型链模式的原型中包含引用类型值所带来问题,我们引入另一种继承方式,借用构造函数。具体思路是在子类型构造函数的内部调用超类构造函数,具体方法是在子类构造函数中调对超类构造函数调用apply()或call()方法,并传入子类构造函数的上下文this,可实现在子类上下文环境下执行超类中定义的对象初始化代码。如此,可以在子类的每个实例中都具有一份超类的属性与方法副本。
function SuperType(name){
this.name = name;
this.sayName = function(){
alert(this.name);
};
}
function SubType(){
//继承了 SuperType,同时还传递了参数
SuperType.call(this, "Nicholas");
//实例属性
this.age = 29;
this.sayAge = function(){
alert(this.age);
};
}
var instance = new SubType();
alert(instance.name); //"Nicholas";
alert(instance.age); //29
问题:优点是可以在子类型构造函数中向超类型构造函数传递参数。缺点是方法都在构造函数中定义,无法实现函数复用;在超类型的原型中定义的方法,对子类型而言也是不可见,相当于这种方式没有继承到父类的方法。
3. 组合继承
为了克服以上借用构造函数方式的问题,我们引入了原型链与借用构造函数组合的继承方式,叫组合继承。具体思路是使用原型链实现对原型属性和方法的继承,而通过借用构造函数来实现对实例属性的继承。这样,既通过在原型上定义方法实现了函数复用,又能够保证每个实例都有它自己的属性。这样,既通过在原型上定义方法实现了函数复用,又能够保证每个实例都有它自己的属性。
function SuperType(name){
this.name = name;
this.colors = ["red", "blue", "green"];
}
SuperType.prototype.sayName = function(){
alert(this.name);
};
function SubType(name, age){
//继承属性
SuperType.call(this, name);
this.age = age;
}
//继承方法
SubType.prototype = new SuperType();
SubType.prototype.constructor = SubType;
SubType.prototype.sayAge = function(){
alert(this.age);
};
var instance1 = new SubType("Nicholas", 29);
instance1.colors.push("black");
alert(instance1.colors); //"red,blue,green,black"
instance1.sayName(); //"Nicholas";
instance1.sayAge(); //29
var instance2 = new SubType("Greg", 27);
alert(instance2.colors); //"red,blue,green"
instance2.sayName(); //"Greg";
instance2.sayAge(); //27
组合继承避免了原型链和借用构造函数的缺陷,融合了它们的优点,成为 JavaScript中最常用的继承模式。而且,instanceof 和 isPrototypeOf()也能够用于识别基于组合继承创建的对象。
缺点:组合继承最大的 问题就是无论什么情况下,都会调用两次超类型构造函数:一次是在创建子类型原型的时候,另一次是 在子类型构造函数内部。没错,子类型最终会包含超类型对象的全部实例属性,但我们不得不在调用子 类型构造函数时重写这些属性。再
4. 原型式继承
在子类构造函数内部,先创建了一个临时性的构造函数,然后将传入的对象作为这个构造函数的原型,最后返回了这个临时类型的一个新实例。原型式继承无需调用new关键字,直接调用构造方法即可。
function object(o){
function F(){}
F.prototype = o;
return new F();
}
ES5 通过新增 Object.create()方法规范化了原型式继承。这个方法接收两个参数:一 个用作新对象原型的对象和(可选的)一个为新对象定义额外属性的对象。在传入一个参数的情况下, Object.create()与 object()方法的行为相同
var person = {
name: "Nicholas",
friends: ["Shelby", "Court", "Van"]
};
// 第二个参数可选
var anotherPerson = Object.create(person);
//var anotherPerson = Object.create(person, {
// name: {
// value: "Greg"
// }
// });
anotherPerson.name = "Greg";
anotherPerson.friends.push("Rob");
如果只是简单得想让一个对象与另一个对象保持一致,可以用原型式继承,不过需特别注意,由于原型式继承本质上是将新对象的原型属性的指针指向被复制对象,所以即使在复制完后,任何对被复制对象的修改,都会反应到新对象上。
5. 寄生式继承
function createAnother(original){
var clone = object(original); //通过调用函数创建一个新对象
clone.sayHi = function(){ //以某种方式来增强这个对象
alert("hi");
};
return clone; //返回这个对象
}
函数不能复用
6. 寄生组合式继承
通过借用构造函数来继承属性,通过原型链的混成形式来继承方法。其背后的基本思路是:不必为了指定子类型的原型而调用超类型的构造函数,我们所需要的无非就是超类型原型的一个副本而已。本质上,就是使用寄生式继承来继承超类型的原型,然后再将结果指定给子类型的原型。
function inheritPrototype(subType, superType){
var prototype = object(superType.prototype); //创建对象
prototype.constructor = subType; //增强对象
subType.prototype = prototype; //指定对象
}
function SuperType(name){
this.name = name;
this.colors = ["red", "blue", "green"];
}
SuperType.prototype.sayName = function(){
alert(this.name);
};
function SubType(name, age){
SuperType.call(this, name);
this.age = age;
}
inheritPrototype(SubType, SuperType);
SubType.prototype.sayAge = function(){
alert(this.age);
};
这个例子的高效率体现在它只调用了一次
SuperType构造函数,并且因此避免了在SubType.prototype上面创建不必要的、多余的属性。与此同时,原型链还能保持不变;因此,还能够正常使用instanceof和isPrototypeOf()。
异步编程
什么是回调函数?回调函数有什么缺点?如何解决回调地狱问题?
将一个函数作为参数传递给另外一个函数,那作为参数的这个函数就是回调函数。回调函数分为同步回调与异步回调,在主函数返回前执行的函数为同步回调函数,在主函数返回后执行的为异步回调函数。
异步回调函数的缺点有不能使用try catch捕获错误,不能直接return,除此之外,回调函数还有个很大的问题是如果回调函数嵌套层次过多的话容易造成回调地狱。
回调地狱的根本问题就是:
嵌套调用:下面的任务依赖上个任务的请求结果,并在上个任务的回调函数内部执行新的业务逻辑,这样当嵌套层次多了之后,代码的可读性就变得非常差了。任务的不确定性:执行每个任务都有两种可能的结果(成功或者失败),所以体现代码中就需要对每个任务的执行结果做两次判断,这种对每个任务都要进行一次额外的错误处理的方式,明显增加了代码的混乱程度。
所以要解决回调地狱也主要是解决这两个问题
- 消灭嵌套调用
- 合并多个任务的错误处理
消息队列与事件循环机制
消息队列是浏览器在单线程架构上实现异步编程的基础,而事件循环机制是浏览器基于消息队列的对异步编程的具体实现,他的内容为每个渲染进程全局执行上下文内部维护一个消息队列,用于存储从其他线程或进程发送过来的消息任务,主线程每次从消息队列的头部取出一个任务,执行完毕后,再取下一个任务,如此循环。
以上消息队列中的任务为宏任务,主要包括:
- 渲染事件(如解析 DOM、计算布局、绘制)
- 用户交互事件(如鼠标点击、滚动页面、放大缩小等)
- JavaScript 脚本执行事件
- 网络请求完成、文件读写完成事件
除宏任务以外,还有一类任务我们称之为微任务,微任务是对宏任务的一项补充,主要是因为宏任务每次新增时都会被添加到消息队列的末尾,由引擎按顺序从消息队列中取出执行,所以执行的时间间在js代码层面是不能精确控制的,对一些高实时性的需求就不太符合,比如监听DOM变化的需求,可能不能及时响应,所以引入了微任务。
微任务和宏任务是绑定的,每个宏任务在执行时,会创建自己的微任务队列。在宏任务执行过程中,程序中产生的所有微任务都会被添加到当前宏任务创建的微任务队列中,在当前宏任务执行完成后,JS引擎会检查微任务队列,按照顺序从微任务队列中取出执行。如果在微任务执行过程中产生了新的微任务,也会被添加到当前微任务队列尾部执行。
微任务就是一个需要异步执行的函数,执行时机是当前宏任务结束之前。微任务和宏任务是绑定的,每个宏任务在执行时,会创建自己的微任务队列,产生的主要方式为:
- 使用 MutationObserver 监控某个DOM节点,然后再通过JavaScript来修改这个节点,或者为这个节点添加、删除部分子节点,当 DOM 节点发生变化时,就会产生 DOM 变化记录的微任务。
- 使用 Promise,当调用 Promise.resolve() 或者 Promise.reject() 的时候,也会产生微任务。
通常情况下,在当前宏任务中的JavaScript快执行完成时,也就在JavaScript引擎准备退出全局执行上下文并清空调用栈的时候,JavaScript 引擎会检查全局执行上下文中的微任务队列,然后按照顺序执行队列中的微任务。如果在执行微任务过程中产生的新的微任务并不会推迟到下个宏任务中执行,而是在当前的宏任务中继续执行。
setTimeout实现原理及存在的问题
在浏览器中除了正常使用的消息队列之外,同时还有另外一个消息队列,这个队列中维护了需要延迟执行的任务列表,包括了定时器和Chromium内部一些需要延迟执行的任务。当我们通过调用setTimeout创建一个定时器时,渲染进程会创建一个回调任务,主要包含了回调函数、当前发起时间、延迟执行时间,然后将该任务添加到延迟队列中去。
主线程每处理完一个消息队列中的任务后,就会遍历这个延迟队列,根据发起时间与延迟执行时间计算是否到期,执行到期任务,等到期任务执行完后,再执行消息队列中的下一个任务。
我们调用setTimeout创建一个定时器时,JS引擎会返回一个id,在定时器还没有被执行的时候,定时任务是可以被取消的,具体方法就是根据这个id去延迟队列里找,找到后删除该任务。
setTimeout存在的问题
- 如果当前任务执行时间过久,会影延迟到期定时器任务的执行
- 如果
setTimeout存在嵌套调用超过5次,那么系统会设置最短时间间隔为4毫秒 - 未激活的页面,
setTimeout执行最小间隔是1000毫秒 - 延时执行时间有最大值
requestAnimationFrame
使用 requestAnimationFrame 不需要设置具体的时间,由系统来决定回调函数的执行时间,每次刷新的间隔中会执行一次回调函数,它跟着屏幕的刷新频率走,保证每个刷新间隔只执行一次,另外如果页面未激活的话,requestAnimationFrame也会停止渲染,这样既可以保证页面的流畅性,又能节省主线程执行函数的开销。
Promise 的特点是什么,分别有什么优缺点?什么是 Promise 链?Promise 构造函数执行和 hen函数执行有什么区别?
- 一个 Promise 的当前状态必须为以下三种状态中的一种:等待态(Pending)、执行态(Fulfilled)和拒绝态(Rejected),状态的改变只能是单向的,且变化后不可在改变。
- 一个 Promise 必须提供一个 then 方法以访问其当前值、终值和据因。 promise.then(onFulfilled, onRejected) 回调函数只能执行一次,且返回 promise 对象
promise的每个操作返回的都是promise对象,可支持链式调用。通过then方法执行回调函数,Promise的回调函数是放在事件循环中的微队列。
传统的异步回调会导致代码逻辑不连续,如果存在多层回调嵌套的话容易导致回调地狱,造成回调地狱的主要原因有两点:
- 嵌套调用,下面的任务依赖上个任务的请求结果,并在上个任务的回调函数内部执行新的业务逻辑,这样当嵌套层次多了之后,代码的可读性就变得非常差了。
- 任务的不确定性,执行每个任务都有两种可能的结果(成功或者失败),所以体现在代码中就需要对每个任务的执行结果做两次判断,这种对每个任务都要进行一次额外的错误处理的方式,明显增加了代码的混乱程度。
promise的提出也也主要是为了解决这两个问题,第一是消灭嵌套调用;第二是合并多个任务的错误处理。
首先,Promise 实现了回调函数的延时绑定,体现在我们可以先新建promise对象,然后再设置回调函数。其次,需要将回调函数onResolve的返回值穿透到最外层。这样就可以摆脱嵌套循环了。
其次是因为 Promise 对象的错误具有“冒泡”性质,会一直向后传递,直到被onReject函数处理或catch语句捕获为止。具备了这样“冒泡”的特性后,就不需要在每个Promise对象中单独捕获异常了。
- Promise 中为什么要引入微任务?
由于promise采用.then延时绑定回调机制,而newPromise时又需要直接执行promise中的方法,即发生了先执行方法后添加回调的过程,此时需等待then方法绑定两个回调后才能继续执行方法回调,便可将回调添加到当前js调用栈中执行结束后的任务队列中,由于宏任务较多容易堵塞,则采用了微任务
- Promise 中是如何实现回调函数返回值穿透的?
首先Promise的执行结果保存在promise的data变量中,然后是.then方法返回值为使用resolved或rejected回调方法新建的一个promise对象,即例如成功则返回new Promise(resolved),将前一个promise的data值赋给新建的promise
- Promise 出错后,是怎么通过“冒泡”传递给最后那个捕获异常的函数?
promise内部有resolved_和rejected_变量保存成功和失败的回调,进入.then(resolved,rejected)时会判断rejected参数是否为函数,若是函数,错误时使用rejected处理错误;若不是,则错误时直接throw错误,一直传递到最后的捕获,若最后没有被捕获,则会报错。
协程
协程是一种比线程更加轻量级的存在,你可以把协程看成是跑在线程上的任务,一个线程上可以存在多个协程,但是在线程上同时只能执行一个协程。如果从A协程启动B协程,我们就把A协程称为B协程的父协程。
- 父协程和子协程是在主线程上交互执行的,并不是并发执行的,它们之前的切换是通过
yield和gen.next来配合完成的。 - 当在子协程中调用了
yield方法时,JavaScript引擎会保存子协程当前的调用栈信息,并恢复父协程的调用栈信息。同样,当在父协程中执行gen.next时,JavaScript 引擎会保存父协程的调用栈信息,并恢复子协程的调用栈信息。
简单介绍Generator
Generator 函数就是一个封装的异步任务,或者说是异步任务的容器。 Generator 的核心是可以暂停函数执行,然后再从上一次暂停的位置继续执行,关键字 yield 标识暂停的位置。 Generator 函数返回一个迭代器对象,并不会立即执行函数里面的方法,对象中有 next() 函数,函数返回 value 和 done 属性,value 属性表示当前的内部状态的值,done 属性标识是否结束的标志位。
Generator 的每一步执行是通过调用 next() 函数,next 方法可以带一个参数,该参数就会被当作上一个yield表达式的返回值。 执行的步骤如下:
- 遇到 yield 表达式,就暂停执行后面的操作,并将紧跟在 yield 后面的那个表达式的值,作为返回的对象的 value 属性的值。
- 下一次调用 next 方法时,再继续往下执行,直到遇到下一个 yield 表达式。
- 如果没有再遇到新的 yield 表达式,就一直运行到函数结束,直到 return 语句为止,并将 return 语句后面的表达式的值,作为返回的对象的value属性值。
- 如果该函数没有 return 语句,则返回的对象的 value 属性值为 undefined。 注意: yield 表达式,本身是没有值的,需要通过 next() 函数的参数将值传进去。
let go = function* (x) {
console.log('one', x)
let a = yield x * 2
console.log('two', a)
let b = yield x + 1
sum = a + b
return sum
}
let g = go(10)
let val = g.next()
while (!val.done) {
val = g.next(val.value)
}
console.log(val)
async&await原理解析
ES7引入的async/await提供了在不阻塞主线程的情况下使用同步代码实现异步访问资源的能力,并且使得代码逻辑更加清晰。
Promise的编程模型依然充斥着大量的then方法,虽然解决了回调地狱的问题,但是在语义方面依然存在缺陷,代码中充斥着大量的then函数,这就是async/await出现的原因。
使用async/await可以实现用同步代码的风格来编写异步代码,这是因为async/await的基础技术使用了生成器和Promise,生成器是协程的实现,利用生成器能实现生成器函数的暂停和恢复。
JS基础
let var const 的区别
- var: 解析器在对js解析时,会将脚本扫描一遍,将变量的声明提前到代码块的顶部,赋值还是在原先的位置,若在赋值前调用,就会出现
暂时性死区,值为undefined - let const:不存在在变量提升,且作用域是存在于块级作用域下,所以这两个的出现解决了变量提升的问题,同时引用块级作用域。 注:变量提升的原因是为了解决函数互相调用的问题。
==和===有什么区别?
对于==来说,如果对比双方的类型不一样的话,就会进行类型转换,而===不会进行类型转换,如果类型不一致,直接返回false
toString 和 valueOf 有什么区别
在Object中存在这个两个方法,继承Object的对象可以重写方法。这两个方法主要用于隐式转换,比如
1 + '1' // 11 :整型 1 被转换成字符串 '1',变成了 '1' + '1' = '11'
2 * '3' // 6 :字符串 '3' 被转换成整型 3 ,变成了 2 * 3 = 6
那么我们也可以对自定义的对象重写这两个函数,以便进行隐式转换
let o = function () {
this.toString = () => {
return 'my is o,'
}
this.valueOf = () => {
return 99
}
}
let n = new o()
console.log(n + 'abc') // 99abc
console.log(n * 10) // 990
// 有没有很酷炫
当这两个函数同时存在时候,会先调用valueOf,若返回的不是原始类型,那么会调用toString方法,如果这时候 toString方法返回的也不是原始数据类型,那么就会报错TypeError: Cannot convert object to primitive value ,如下
let o = function () {
this.toString = () => {
console.log('into toString')
return { 'string': 'ssss' }
}
this.valueOf = () => {
console.log('into valueOf')
return { 'val': 99 }
}
}
let n = new o()
console.log(n + 'xx')
//into valueOf
//into toString
// VM1904:12 Uncaught TypeError: Cannot convert object to primitive value
箭头函数有没有 arguments 对象
arguments是一个类数组对象,可以获取到参数个数和参数列表数组,对于不定参数的函数,可以用 arguments 获取参数。
在浏览器中箭头函数没有 arguments, 在 nodejs 中,有 arguments
js精度丢失问题
浮点数的精度丢失不仅仅是js的问题,java也会出现精度丢失的问题,主要是因为数值在内存是由二进制存储的,而某些值在转换成二进制的时候会出现无限循环,由于位数限制,无限循环的值就会采用“四舍五入法”截取,成为一个计算机内部很接近数字,即使很接近,但是误差已经出现了。
0.1 + 0.2 = 0.30000000000000004
// 0.1 转成二进制会无限循环
// "0.000110011001100110011001100110011001100110011001100..."
那么如何避免这问题呢?解决办法:可在操作前,放大一定的倍数,然后再除以相同的倍数
(0.1 * 100 + 0.2 * 100) / 100 = 0.3
js 的 number 采用 64位双精度存储 JS 中能精准表示的最大整数是 Math.pow(2, 53)
toFixed 可以做到四舍五入吗
可以
0.4.toFiexd(0)=0
0.5.toFiexd(0)=1
js中不同进制怎么转换
- 10进制转其他进制:
Number(val).toString(2/8/10/16) - 其他进制转成10进制:
Number.parseInt("1101110",2/8/10/16) - 其他进制互转:先将其他进制转成 10 进制,在把 10 进制转成其他进制
对js处理二进制有了解吗
ArrayBuffer:用来表示通用的、固定长度的原始二进制数据缓冲区,作为内存区域,可以存放多种类型的数据,它不能直接读写,只能通过视图来读写。 同一段内存,不同数据有不同的解读方式,这就叫做“视图”(view),视图的作用是以指定格式解读二进制数据。目前有两种视图,一种是TypedArray视图,另一种是DataView视图,两者的区别主要是字节序,前者的数组成员都是同一个数据类型,后者的数组成员可以是不同的数据类型。Blob:也是存放二进制的容器,通过 FileReader 进行转换。
描述NaN指的是什么
NaN属性是代表非数字值的特殊值,该属性用于表示某个值不是数字。NaN是Number对象中的静态属性
typeof(NaN) // "number"
NaN == NaN // false
那怎么判断一个值是否是NAN呢? 若支持 es6 ,可直接使用Number.isNaN(),若不支持,可根据NAN !== NAN的特性
function isReallyNaN(val) {
let x = Number(val);
return x !== x;
}
什么是严格模式
通过在脚本的最顶端放上一个特定语句 "use strict"; 整个脚本就可开启严格模式语法。 严格模式下有以下好处:
- 消除Javascript语法的一些不合理、不严谨之处,减少一些怪异行为;
- 消除代码运行的一些不安全之处,保证代码运行的安全;
- 提高编译器效率,增加运行速度;
- 为未来新版本的Javascript做好铺垫。
如以下具体的场景:
- 严格模式会使引起静默失败(silently fail,注:不报错也没有任何效果)的赋值操作抛出异常
- 严格模式下的 eval 不再为上层范围(surrounding scope,注:包围eval代码块的范围)引入新变量
- 严格模式禁止删除声明变量
- 在严格模式中一部分字符变成了保留的关键字。这些字符包括implements, interface, let, package, private, protected, public, static和yield。在严格模式下,你不能再用这些名字作为变量名或者形参名。
- 严格模式下 arguments 和参数值是完全独立的,非严格下修改是会相互影响的
循环有几种方式,是否支持中断和默认情况下是否支持async/await
for支持中断、支持异步事件for of支持中断、支持异步事件for in支持中断、支持异步事件forEach不支持中断、不支持异步事件map不支持中断、不支持异步事件,支持异步处理方法:map 返回promise数组,在使用 Promise.all 一起处理异步事件数组reduce不支持中断、不支持异步事件,支持异步处理方法:返回值返回 promise 对象
