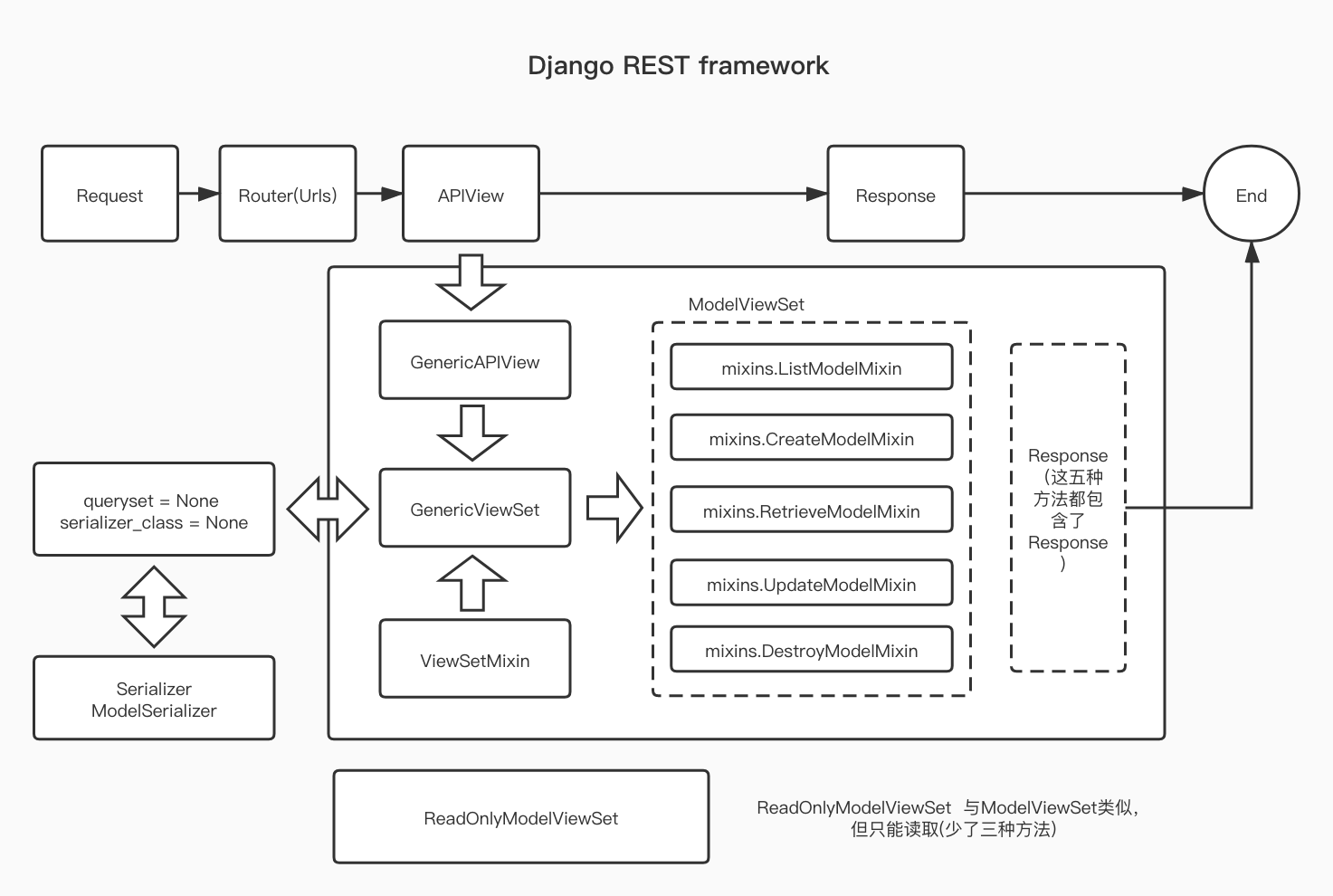
serializer笔记
本文前提,你已经学习Django,并了解restful的基本概念
序列化的定义:
- 在数据储存与发送的部分是指将一个对象存储至一个存储介质,例如文件或是存储器缓冲等,或者透过网络发送数据时进行编码的过程,可以是字节或是XML等格式。而字节的或XML编码格式可以还原完全相等的对象。这程序被应用在不同应用程序之间发送对象,以及服务器将对象存储到文件或数据库。相反的过程又称为反序列化。(维基百科)
- 序列化 (Serialization)是将对象的状态信息转换为可以存储或传输的形式的过程。(百度百科)
在Python的Django框架中,解释就很明显了。将ORM对象(queryset)等转化为JSON或者XML编码格式的数据。反序列化与之相反。
同样,为什么需要序列化?
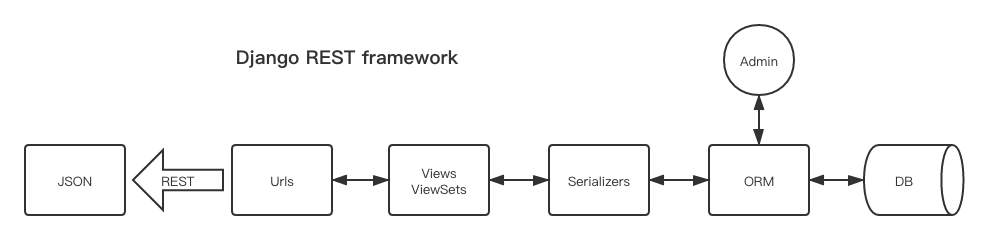
restful,请求进来(经过视图层),获取数据库中需要的数据,然后转为json格式,那样可以给前端,或者其他程序调用。或者请求数据以JSON格式进来,转化为数据库能接收的形式,存到数据库(反序列化)。
Serializers
Serializers
官方快速入门示例
准备数据库
from django.db import models
from pygments.lexers import get_all_lexers
from pygments.styles import get_all_styles
LEXERS = [item for item in get_all_lexers() if item[1]]
LANGUAGE_CHOICES = sorted([(item[1][0], item[0]) for item in LEXERS])
STYLE_CHOICES = sorted([(item, item) for item in get_all_styles()])
class Snippet(models.Model):
created = models.DateTimeField(auto_now_add=True)
title = models.CharField(max_length=100, blank=True, default='')
code = models.TextField()
linenos = models.BooleanField(default=False)
language = models.CharField(choices=LANGUAGE_CHOICES, default='python', max_length=100)
style = models.CharField(choices=STYLE_CHOICES, default='friendly', max_length=100)
class Meta:
ordering = ['created']
数据库的migrate
python manage.py makemigrations snippets
python manage.py migrate
Creating a Serializer class 创建序列化类
from rest_framework import serializers
from snippets.models import Snippet, LANGUAGE_CHOICES, STYLE_CHOICES
class SnippetSerializer(serializers.Serializer):
id = serializers.IntegerField(read_only=True)
title = serializers.CharField(required=False, allow_blank=True, max_length=100)
code = serializers.CharField(style={'base_template': 'textarea.html'})
linenos = serializers.BooleanField(required=False)
language = serializers.ChoiceField(choices=LANGUAGE_CHOICES, default='python')
style = serializers.ChoiceField(choices=STYLE_CHOICES, default='friendly')
def create(self, validated_data):
"""
Create and return a new `Snippet` instance, given the validated data.
"""
return Snippet.objects.create(**validated_data)
def update(self, instance, validated_data):
"""
Update and return an existing `Snippet` instance, given the validated data.
"""
instance.title = validated_data.get('title', instance.title)
instance.code = validated_data.get('code', instance.code)
instance.linenos = validated_data.get('linenos', instance.linenos)
instance.language = validated_data.get('language', instance.language)
instance.style = validated_data.get('style', instance.style)
instance.save()
return instance
Declaring Serializers
序列化是将Class转换为Python原生的数据类型(例如: dict,list),下面先创建一个叫Comment的Class,再创建comment对象
from datetime import datetime
class Comment(object):
def __init__(self, email, content, created=None):
self.email = email
self.content = content
self.created = created or datetime.now()
comment = Comment(email='leila@example.com', content='foo bar')
Serializing objects
创建序列化类(序列化器),继承serializer就可以了,然后写入需要序列化的字段。这里的字段一般直接对应数据库的字段。如果加上属性配置,则可以在反序列化是进行条件约束。
from rest_framework import serializers
class CommentSerializer(serializers.Serializer):
email = serializers.EmailField()
content = serializers.CharField(max_length=200)
created = serializers.DateTimeField()
序列化的参数是一个对象,例如上面生成的comment对象。序列化的类跟Django的Form类用法相似,serializer对象中有很多属性跟Form一样。其中serializer.data中保存的就是序列化后的python普通数据类型,下面的例子中是一个字典。
serializer = CommentSerializer(comment)
serializer.data
# {'email': 'leila@example.com', 'content': 'foo bar', 'created': '2016-01-27T15:17:10.375877'}
序列化后的数据放在serializer.data中,此时的结果serializer.data已经被转化为Python原生数据类型,再将数据渲染为JSON
from rest_framework.renderers import JSONRenderer
json = JSONRenderer().render(serializer.data)
json
# b'{"email":"leila@example.com","content":"foo bar","created":"2016-01-27T15:17:10.375877"}'
这里,我们已经包得到一个标准的json数据了,然后就是返回请求结果了。这就是一个最简答的序列化过程了。如果需要对应我们的一些特殊需求,restful也提供了一些方法。通过覆盖默认方法来实现我们的需求。
Deserializing objects
反序列化跟序列化类似,不过一般都是通过网络传输。所以传给我们的数据都是一个二进制流形式的数据(我也不知道这么描述对不对)
import io
from rest_framework.parsers import JSONParser
stream = io.BytesIO(json)
data = JSONParser().parse(stream)
这里的data已经是一个python的默认数据格式了(字典)。
这里的JSONParser暂且叫JSON解析器吧。在看restful源码中,会发现有这个。就是这个道理(废话)。需要将流数据需要处理为python能处理的JSON数据类型。转换为JSON类型就好办了,转为Python默认类型
serializer = CommentSerializer(data=data)
serializer.is_valid()
# True
serializer.validated_data
# {'content': 'foo bar', 'email': 'leila@example.com', 'created': datetime.datetime(2012, 08, 22, 16, 20, 09, 822243)}
Saving instances
这个标题是saving instance,翻译保存实例,其实说白了就是反序列化把数据存入数据库里。如果我们希望能够返回基于验证数据的完整对象实例,我们需要实现其中一个或全部实现.create()和update()方法。例如:
class CommentSerializer(serializers.Serializer):
email = serializers.EmailField()
content = serializers.CharField(max_length=200)
created = serializers.DateTimeField()
def create(self, validated_data):
return Comment(**validated_data)
def update(self, instance, validated_data):
instance.email = validated_data.get('email', instance.email)
instance.content = validated_data.get('content', instance.content)
instance.created = validated_data.get('created', instance.created)
return instance
涉及两个方法,.create() 和 .update(),这两个方法是表示对应的http方法,post => create, put => update,根据传给serializer的参数对象(instance)是否为真做判断。简单讲,就是post方法最后就会走到create方法。create就等于是把数据存入数据库了,前提是数据校验好了。具体的校验看下面Validation
.create()和.update()方法都是可选的。你可以根据你序列化器类的用例不实现、实现它们之一或都实现。
comment = serializer.save()
serializer已经是反序列化类CommentSerializer生成的对象,调用了save方法。
在BaseSerializer基类中,说明要定义这两个方法create update,并且save方法说明调用这两种方法的情况
class BaseSerializer(Field):
#...
def save(self, **kwargs):
#...
if self.instance is not None:
self.instance = self.update(self.instance, validated_data)
assert self.instance is not None, (
'`update()` did not return an object instance.'
)
else:
self.instance = self.create(validated_data)
assert self.instance is not None, (
'`create()` did not return an object instance.'
)
#...
你可以通过在调用.save()时添加其他关键字参数来执行此操作。例如:
serializer.save(owner=request.user)
另外一个save强大的功能,例如在我们可能不会创建新的实例,而是发送电子邮件或其他消息。
在这些情况下,你可以选择直接重写.save()方法,因为那样更可读和有意义。
例如:
class ContactForm(serializers.Serializer):
email = serializers.EmailField()
message = serializers.CharField()
def save(self):
email = self.validated_data['email']
message = self.validated_data['message']
send_email(from=email, message=message)
在上述情况下,我们现在不得不直接访问serializer的.validated_data属性。为了拿到数据进行操作。
Validation
做过form表单都知道数据验证,在拿到表单数据后,都会进行数据验证。
在尝试访问经过验证的数据或保存对象实例之前,总是需要调用 is_valid()。如果发生任何验证错误,.errors 属性将包含表示结果错误消息的字典。例如:
serializer = CommentSerializer(data={'email': 'foobar', 'content': 'baz'})
serializer.is_valid()
# False
serializer.errors
# {'email': [u'Enter a valid e-mail address.'], 'created': [u'This field is required.']}
当数据验证失败,使用is_valid()结果显示false
- 引发无效数据的异常 (Raising an exception on invalid data)
.is_valid() 方法使用可选的 raise_exception 标志,如果存在验证错误,将会抛出 serializers.ValidationError 异常。
这些异常由 REST framework 提供的默认异常处理程序自动处理,默认情况下将返回 HTTP 400 Bad Request 响应。
# Return a 400 response if the data was invalid.
serializer.is_valid(raise_exception=True)
- 字段级别验证 (
Field-level validation)
您可以通过向您的 Serializer 子类中添加 .validate_<field_name> 方法来指定自定义字段级的验证。这些类似于 Django 表单中的 .clean_<field_name>方法。
这些方法采用单个参数,即需要验证的字段值。
您的 validate_<field_name>方法应该返回已验证的值或者抛出 serializers.ValidationError 异常。例如:
from rest_framework import serializers
class BlogPostSerializer(serializers.Serializer):
title = serializers.CharField(max_length=100)
content = serializers.CharField()
def validate_title(self, value):
"""
Check that the blog post is about Django.
"""
if 'django' not in value.lower():
raise serializers.ValidationError("Blog post is not about Django")
return value
注意:如果在您的序列化器上声明了 <field_name> 的参数为 required=False,那么如果不包含该字段,则此验证步骤不会发生。
- 对象级别验证 (Object-level validation),对多个字段关联比较
要执行需要访问多个字段的任何其他验证,请添加名为
.validate()的方法到您的Serializer子类中。此方法采用单个参数,该参数是字段值的字典。如果需要,它应该抛出ValidationError异常,或者只返回经过验证的值。例如:
from rest_framework import serializers
class EventSerializer(serializers.Serializer):
description = serializers.CharField(max_length=100)
start = serializers.DateTimeField()
finish = serializers.DateTimeField()
def validate(self, data):
"""
Check that the start is before the stop.
"""
if data['start'] > data['finish']:
raise serializers.ValidationError("finish must occur after start")
return data
- 验证器 (Validators) 需要自定义字段的验证逻辑,(与指定字段验证),例如:
def multiple_of_ten(value):
if value % 10 != 0:
raise serializers.ValidationError('Not a multiple of ten')
class GameRecord(serializers.Serializer):
score = IntegerField(validators=[multiple_of_ten])
...
- 序列化器类还可以包括应用于完整字段数据集的可重用验证器。
组合字段唯一。将两个关联字段绑定。宾馆,同一天同一个房间只能给一个用户。通过在内部 Meta 类上声明来包含这些验证器,如下所示:
class EventSerializer(serializers.Serializer):
name = serializers.CharField()
room_number = serializers.IntegerField(choices=[101, 102, 103, 201])
date = serializers.DateField()
class Meta:
# Each room only has one event per day.
validators = UniqueTogetherValidator(
queryset=Event.objects.all(),
fields=['room_number', 'date']
)
Dealing with multiple objects
- 序列化多个对象 (Serializing multiple objects)
ORM查询后的queryset是多条记录。需要在实例化序列化器时传递 many = True 标志。
queryset = Book.objects.all()
serializer = BookSerializer(queryset, many=True)
serializer.data
# [
# {'id': 0, 'title': 'The electric kool-aid acid test', 'author': 'Tom Wolfe'},
# {'id': 1, 'title': 'If this is a man', 'author': 'Primo Levi'},
# {'id': 2, 'title': 'The wind-up bird chronicle', 'author': 'Haruki Murakami'}
# ]
Including extra context
ModelSerializer
ModelSerializer 类提供了一个快捷方式,可以自动创建具有与模型字段对应的字段的 Serializer 类。
ModelSerializer 类与常规 Serializer 类相同,不同之处在于:
- 它将根据模型自动为您生成一组字段。
- 它将自动为序列化器生成验证器,例如
unique_together验证器。 - 它包含默认简单实现的
.create()和.update()方法。
ModelSerializer 例子如下所示:
class AccountSerializer(serializers.ModelSerializer):
class Meta:
model = Account
fields = ('id', 'account_name', 'users', 'created')
最下面的 fields 表示指定要包含的字段 (Specifying which fields to include)
Inspecting a ModelSerializer
因为 ModelSerializer 是自动生成的 Serializer ,所以我们不确定生成了哪些字段和验证器。
可以通过 python manage.py shell 打开 Django shell 的方式,然后导入序列化器类,实例化它,打印出来。
>>> from myapp.serializers import AccountSerializer
>>> serializer = AccountSerializer()
>>> print(repr(serializer))
AccountSerializer():
id = IntegerField(label='ID', read_only=True)
name = CharField(allow_blank=True, max_length=100, required=False)
owner = PrimaryKeyRelatedField(queryset=User.objects.all())
Specifying which fields to include
除了上面说的方式,可以使用 '__all__' 的方式制定所有字段
class AccountSerializer(serializers.ModelSerializer):
class Meta:
model = Account
fields = '__all__'
反选,排除的方式 exclude
class AccountSerializer(serializers.ModelSerializer):
class Meta:
model = Account
exclude = ('users',)
Specifying nested serialization
当有外键的时候,可以使用下面的depth方式。
class AccountSerializer(serializers.ModelSerializer):
class Meta:
model = Account
fields = ('id', 'account_name', 'users', 'created')
depth = 1
这种方式有缺点,就是比较死板。假设你有个字段是通过外键的形式。那指定 depth = 1 则就能显示关联外键字段的具体内容了。要是你外键还有外键。那就 depth = 2。不过也确实看出来这种方式很死板,除非很简单,一般还是不用这种方式。
Specifying fields explicitly
可以通过重写字段的方式,将需要修改的字段,重新修改。不用 ModelSerializer 提供的字段方式。就像写 Serializer 的字段。
class AccountSerializer(serializers.ModelSerializer):
url = serializers.CharField(source='get_absolute_url', read_only=True)
groups = serializers.PrimaryKeyRelatedField(many=True)
class Meta:
model = Account
Specifying read only fields
通过指定 read_only_fields 的方式指定多个字段,而不需要在每个字段里写属性 read_only=True
class AccountSerializer(serializers.ModelSerializer):
class Meta:
model = Account
fields = ('id', 'account_name', 'users', 'created')
read_only_fields = ('account_name',)
Additional keyword arguments
额外的属性。例如指定字段的属性,或者报错内容等
class CreateUserSerializer(serializers.ModelSerializer):
class Meta:
model = User
fields = ('email', 'username', 'password')
extra_kwargs = {'password': {'write_only': True}}
BaseSerializer
BaseSerializer 是 Serializer 继承的基类。可以很简单的用来替代序列化和反序列化的样式。而 BaseSerializer 继承 Field 类
该类实现与Serializer类相同的基本API:
.data - 返回传出的原始数据。
.is_valid() - 反序列化并验证传入的数据。
.validated_data - 返回经过验证后的传入数据。
.errors - 返回验证期间的错误。
.save() - 将验证的数据保留到对象实例中。
它还有可以覆写(重写覆盖)的四种方法,具体取决于你想要序列化类支持的功能:
.to_representation() - 重写此方法来改变读取操作的序列化结果。
.to_internal_value() - 重写此方法来改变写入操作的序列化结果。
.create() 和 .update() - 重写其中一个或两个来改变保存实例时的动作。
同样 Serializer或ModelSerializer 这两个也有这些接口可以用来覆盖。
- 序列化转为
JSON前的最后一步to_representation,看下面的例子:
class CabinetSerializer(serializers.Serializer):
idc = serializers.PrimaryKeyRelatedField(many=False, queryset=Idc.objects.all())
name = serializers.CharField(required=True)
def to_representation(self, instance):
idc_obj = instance.idc
ret = super(CabinetSerializer, self).to_representation(instance)
ret["idc"] = {
"id": idc_obj.id,
"name": idc_obj.name
}
return ret
- 反序列化前的第一步
to_internal_value,如下例子:
class CabinetSerializer(serializers.Serializer):
idc = serializers.PrimaryKeyRelatedField(many=False, queryset=Idc.objects.all())
name = serializers.CharField(required=True)
def to_internal_value(self, data):
"""
反序列化第一步:拿到的是提交过来的原始数据: QueryDict => request.GET, request.POST
"""
print(data)
return super(CabinetSerializer, self).to_internal_value(data)
小结
- 序列化
- 拿到
queryset - 将
queryset给序列化类
serializer = IdcSerializer(idc)
serializer = IdcSerializer(queryset, many=True)
- 转
JSON
JSONRenderer().render(serializer.data)
- 反序列化
data = JSONParser().parse(BytesIO(content))
serializer = IdcSerializer(data=data)
serializer.is_valid()
serializer.save()
与之相对应的对应的view视图伪代码
class something_list(APIView):
def get(self, request, *args, **kwargs):
"""返回所有数据"""
pass
def post(self, request, *args, **kwargs):
"""创建一条数据"""
pass
class something_detail(APIView):
def get(self, request, *args, **kwargs):
"""返回指定数据"""
pass
def put(self, request, *args, **kwargs):
"""修改指定记录"""
pass
def delete(self, request, *args, **kwargs):
"""删除这条记录"""
pass