

1. Collection接口的常用方法/公用方法
- 添加
- 删除
- remove
- removeAll(Collection e) (删除交集)将两个集合中的相同元素从调用removeAll方法的集合中删除
- 判断
- 获取
- int size()
- Iterator interator() 取出元素的方法
- 其他
- boolean retainAll(Collection e) 取交集 保留和指定集合中相同的元素,而删除两个集合中不同的元素,和retainAll功能相反
2. 迭代器原理
迭代器: 大白话表述: 能取出集合中元素的对象叫迭代器,怎么取集合中的元素迭代器最清楚。
迭代器的几个常用方法:
- boolean hasNext()
- E next() 返回迭代的下一个元素
- void remove() 从迭代器指向的collection中移除返回的最后一个元素
迭代器原理: 该对象必须依赖具体的容器(集合),因为每一个容器的数据结构都不同,所以该迭代器实在容器中进行内部实现的。
对于使用容器者而言,具体的实现不重要,只要通过容器获取到该实现的迭代器即可(通过集合的iterator()方法获取),使用者通过这个迭代器就能获取容器中元素。
Iterator接口就是对所有的Collection容器进行元素取出的公共接口,不管是List/Set/Vector都可用迭代器来获取集合中的元素。
只要你是Collection容器,我就可以使用Iterator去取你里面的元素。我没有必要去知道每个具体集合容器的迭代对象的内部结构。
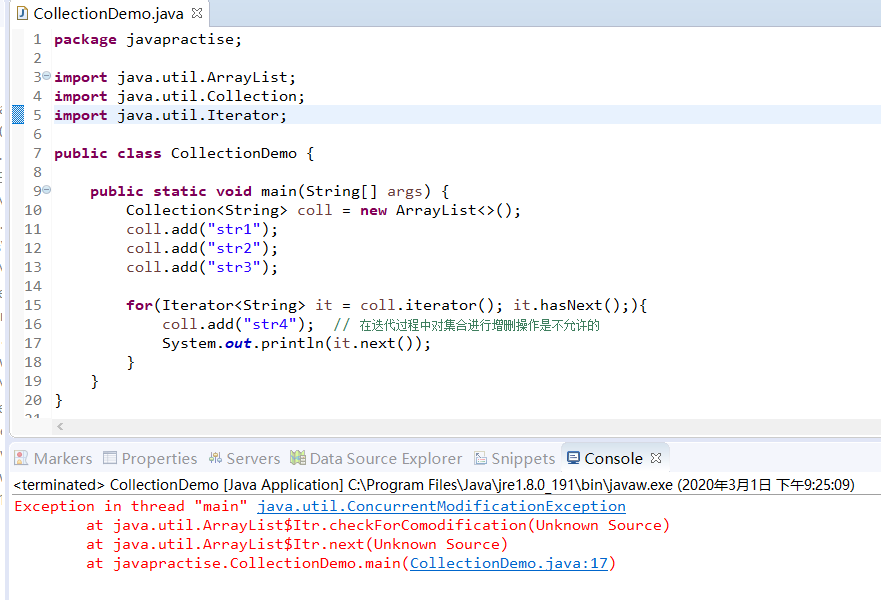
3. 为什么不要在对集合的迭代过程中对集合进行增删等操作?顺便介绍一个异常ConcurrentModificationException。
当方法检测到对象的并发修改,由于不允许这种修改,就会抛出ConcurrentModificationException异常。
例如: 某个线程在Collection上正进行迭代时,是不允许另一个线程修改此Collection的,通常在情况下,迭代器取的结果是不正确的。
package javapractise;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class CollectionDemo {
public static void main(String[] args) {
Collection<String> coll = new ArrayList<>();
coll.add("str1");
coll.add("str2");
coll.add("str3");
for(Iterator<String> it = coll.iterator(); it.hasNext();){
coll.add("str4"); // 在迭代过程中对集合进行增删操作是不允许的
System.out.println(it.next());
}
}
}
运行结果:
4. ListIterator
注意: 只有List集合和Vector还有一个特有的迭代器ListIterator,别的集合都没有。
List list = new ArrayList();
ListIterator listIt = list.listIterator();
Vector ve = new Vector<>();
ListIterator listIterator = ve.listIterator();
// xxx代码
5. List接口下常用的三个子类
- Vector 增删查都很慢
- 内部实现是基于数组结构的,
- 是同步的(线程安全的)
- 效率相对ArrayList要低
- since 1.0
- Arraylist 查询俗速度特别快
- 内部实现也是基于数组结构的,
- 不是同步的(线程不安全的)
- 效率高
它的出现可以说是为了替换Vector的,要线程同步,我们不用Vector,而是给ArrayList加锁。
- LinkedList 适用于非常频繁的对数据进行增删操作的场景
- 内部是链表数据结构
- 不是同步的
- 增删元素特别快、
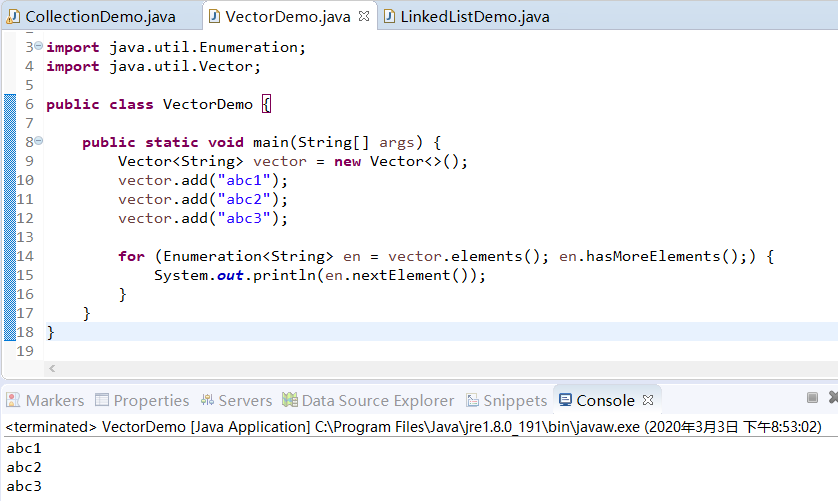
6. Vector简单介绍。Vector在1.0的时候就有(List在1.2的时候才有),他打天下的时候使用的方法一般都含有element单词。
Vector有一个特殊的取元素的接口Enumeration。 此接口的功能与Iterator接口的功能是重复的。区别在于,Iterator增加了一个可选的移除操作,并且方法名名称短。
对于Vector我们优先Iterator接口进行元素迭代,而不是有老的Enumeration接口。
Enumeration:
- hasMoreElements()方法
- nextElement()方法
在具体开发的时候,我们一般如下使用:
-
用ArrayList类替换Vector类
-
用Iterator接口替换Enumeration接口
package javapractise;
import java.util.Enumeration;
import java.util.Vector;
public class VectorDemo {
public static void main(String[] args) {
Vector<String> vector = new Vector<>();
vector.add("abc1");
vector.add("abc2");
vector.add("abc3");
for (Enumeration<String> en = vector.elements(); en.hasMoreElements();) {
System.out.println(en.nextElement());
}
}
}
7. LinkedList的特有方法:
addFirst(Object obj);
removeFirst(Object obj); // 此方法返回第一个元素并移除这个元素
addLast(Object obj);
removeLast(Object obj); // 此方法返回获取最后一个元素并移除这个元素
public static void main(String[] args) {
LinkedList<String> linkedList = new LinkedList<>();
linkedList.add("AAA");
linkedList.add("BBB");
linkedList.add("CCC");
System.out.println(linkedList.removeFirst());
System.out.println(linkedList.removeLast());
}

面试题:使用LinkedList来模拟一个栈和队列数据模型
- 栈: 先进后出 FirstInLastOut FILO (进电梯下电梯)
- 队列: 先进先出 FirstInFirstOut FIFO (一群小样排队过独木桥)
8.Set接口
- Set接口中的方法与Collection接口中的方法一致
- HashSet 内部数据结构是哈希表,是不同步的
- TreeSet 内部数据结构是二叉树,是不同步的
HashSet 内部数据结构是哈希表,所以存储元素的时候使用的元素的hashCode方法是确定存储位置。如果位置相同再通过元素的equals()方法来判定元素是否相同。
9. hashCode方法和equals方法
hashCode方法和equals方法用来判断元素是否相等。
- 先判断两个元素的哈希值(可以认为是对象存储的位置的号码)是否相等(根据两个对象的hashCode()方法的返回值是否相等来判定),如果哈希值相等,再使用equals()方法来判断两个对象的内容是否相等。
- 判断哈希值是否相等,其实就是判断对象的hashCode方法返回值是否相等。而判断对象的内容是否相等使用的是equals方法。
- 注意:如果两个对象的哈希值都不一样,那就不需要再用equals方法判断了。
10. 哈希算法
10.1 先说说使用哈希算法存储元素有什么作用
我们知道Set中元素是不允许存放重复元素的,假如一个set中只有两个元素,在存入第三个元素的时候,需要先判断它和Set中已经有的两个元素是否相同,判断两次就够了。但是如果Set中已经存了1000个元素了,在存第1001个元素的时候就要将这个元素和集合中已有的1000个元素进行比较,这时候效率就很低了。
而如果我们对每一个元素在存入的时候都计算一个存储位置,即使Set中已经存储了10000个元素,在存储第10001个元素的时候,HaseSet先给这个元素计算一个存储位置,计算完位置后在到内存中的这个位置找看是不是已经存了元素就行了。这样就只用找一次就行了,大大提高了存储效率。
我们来进一步介绍哈希算法: 比如果我现在要给字符串"AB"定一个存储位置码,这个位置码就是一个数字。hashCode方法可以表示成如下的逻辑:
function(Element e){
// 一个算法
// 对元素进行运算,并获取一个位置
return 位置index;
}
再举一个比喻:
比如学校校长要给学校里的每个同学算一个宿舍床号,这个座位的位置是根据身高,年龄,肤色,省份,体重这5个属性进行计算的。有一天,公安局的人员问校长,你们学校有没有这么一个学生,并给校长提供了这个学生的身高,年龄,肤色,省份,体重这5个属性,校长拿出计算器根据这5个属性根据特定的算法(哈希算法)喀喀喀一顿计算,算出了一个宿舍床号(哈希值),然后去这个宿舍床号找看有没有人,发现没人在这个床号住,那就说明他们学校没有这个人。
- 对于我们自定义的对象,我们可以重写hashCode方法。
- hash算法提高了查询效率,但是由于其根据元素的特点来决定元素存放的位置的,所以无法存放相同元素。
10.2 自定义哈希算法演示1
function(element) // 【第一个元素】假如 element = "ab";
{
// 自定义哈希算法演示
return (97 + 98)%10; // 算出的哈希码是5
}
【第二个元素】假如 element = "ab";
return (98 + 97)%10; 算出的哈希码也是5,此时第一个元素和第二个元素要存的位置都是5,这就出现了哈希冲突,两个对象不同,但是算出的hash值却一样。
【第三个元素】假如 element = "AB"; return (65 + 66)%10; 算出的哈希码是1,那么"AB"这个元素就应该存储再1的位置。
10.3 自定义哈希算法演示2
直接上代码:
package hashdemo;
public class Person {
private String name;
private String sex;
public String getName() {
return name;
}
public Person(String name, String sex) {
super();
this.name = name;
this.sex = sex;
}
@Override
public String toString() {
return "Person [name=" + name + ", sex=" + sex + "]";
}
public void setName(String name) {
this.name = name;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
// 【重写】hashCode方法
// 让name和age都参与哈希码的计算,这样可以减少算出的哈希码相同的情况
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((name == null) ? 0 : name.hashCode());
result = prime * result + ((sex == null) ? 0 : sex.hashCode());
return result;
}
// 【重写】equals方法
// 注意这个equals方法的逻辑顺序
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Person other = (Person) obj;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
if (sex == null) {
if (other.sex != null)
return false;
} else if (!sex.equals(other.sex))
return false;
return true;
}
}
package hashdemo;
import java.util.HashSet;
public class HashSetDemo {
public static void main(String[] args) {
// 创建三个person对象
Person person1 = new Person("小明", "男");
Person person2 = new Person("小明", "男");
Person person3 = new Person("小红红", "女");
System.out.println("person1的哈希值: " + person1.hashCode());
System.out.println("person2的哈希值: " + person2.hashCode());
System.out.println("person3的哈希值: " + person3.hashCode());
// 创建hashSet,并将三个person对象都存入这个HashSet集合
HashSet<Person> hashSet = new HashSet<>();
hashSet.add(person1);
hashSet.add(person2);
hashSet.add(person3);
// 遍历这个集合,只存了两个元素
for (Person person : hashSet) {
System.out.println(person);
}
}
}
运行结果:

对于以上代码的解读和说明:
创建三个person对象,创建hashSet,并将三个person对象都存入这个HashSet集合,最后遍历这个集合,只存了两个元素。
- 由于HashSet中元素不可重复,那怎么判断元素是否重复呢?这个判断元素是否相同的方法,对于HashSet其实就是hashCode()和equals()方法。
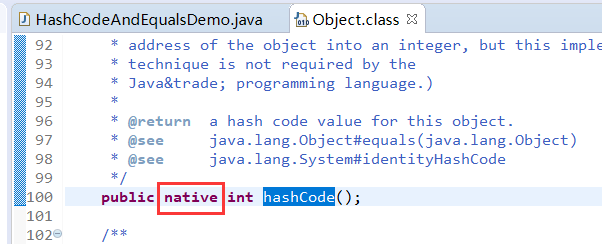
- hashCode()和equals()方法属于Object类中的方法,那为什么还要重写hashCode()和equals()方法呢?
- Object类中的hashCode()方法是用native修饰的,表示使用的不是java语言实现的方法。
- 而Object类中的equals方法直接比较的是不是同一个对象,是同一个对象才返回true。而实际使用中,拿Person类来举例,我们一般认为name,age,sex属性相同就认为是同一个Person对象。Object类中的equals方法显然不满足实际中需要。
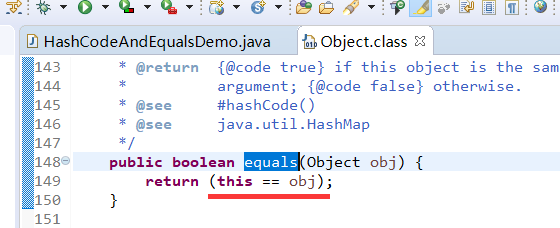
无论是想在集合中删除一个元素,还是想判断集合中是否包含某个元素,这些最终都要落在一个关键问题上:就是这个元素是否和集合中已有的元素相等。对于不同的容器对象判断元素想的的依据不同。
- 对于ArrayList---->使用equals方法判断
- 对于HashSet---->使用hashCode方法和equals方法一块来判断
11. 如何保证一个Set集合中的元素唯一还想有序呢?LinkedHashSet
HashSet接口是无序的,但是他有一个子类LinkedHashSet,它同时使用了hash表和链表,达到了元素有序且唯一的能力。
12. 关于TreeSet至少要知道如下内容
-
TreeSet可以对集合中的元素进行排序,是不同步的。
-
TreeSet也属于Set,也要保证元素的唯一性。
-
判断元素唯一性的方法,就是根据比较方法的返回值是否为0来判断。如果为0,则两个元素相同,如果不为0,则两个元素不相同。
-
如果往TreeSet中添加自定义对象有一个前提,这个自定义类实现了Comprable接口中的compareTo方法,在这个方法中定义如何排序。还有一种方式就是让集合具备排序功能(第一种是让集合中的元素自身具备比较功能)。
-
因为TreeSet判断对象是否相等,不用equals方法,也不用hashCode方法,它只看Comprable接口是怎么实现的。
举例:
// Person类实现Comparable接口
public class Person implements Comparable {
private String name;
private String sex;
//getXxx方法
//setXxx方法
// 重写compareTo方法
@Override
public int compareTo(Object obj) {
if (obj instanceof Person) {
Person person = (Person) obj;
return this.name.compareTo(person.name); //这里的compareTo方法是String类自带的已经重写过的compareTo方法
}
return 0;
}
}
13. TreeSet对元素进行排序的两种方式
- 让元素自身具备排序功能
- 让集合自身具备比较功能
13.1 让元素自身具备排序功能
让元素自身具备比较功能,元素必须实现Comparable接口,重写compareTo方法。
但是如果不想按照对象已有的排序方式排序, 或者这个元素还不具备排序功能的时候, 该怎么办呢?
这就要说到更常用的一种方式,让集合自身具备比较功能,利用比较器。
13.2 让集合自身具备比较功能,利用比较器
定义一个类,让它实现Comparator接口,重写compare方法,将该类对象传递给TreeSet集合的构造器。
方式二更常用。 有时候必须使用比较器。比如,某个元素本身已经具备比较方式了,但是我按照另外一种方式进行排序,就必须使用比较器了。
举例:让集合自身具备比较功能
实现对字符串先按照偿付进行排序,如果长度相同,按照字母顺序排序。
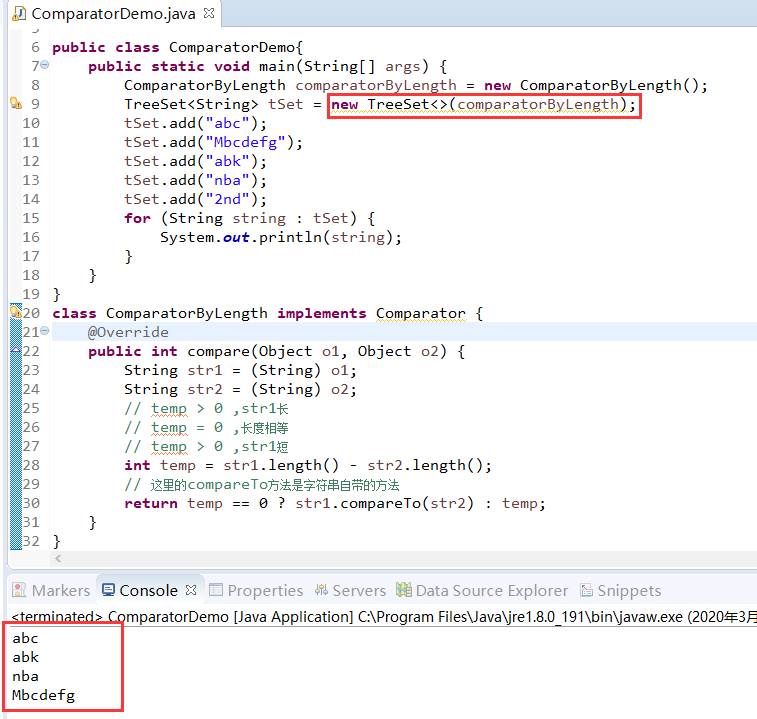
package Comparator;
import java.util.Comparator;
import java.util.TreeSet;
public class ComparatorDemo{
public static void main(String[] args) {
ComparatorByLength comparatorByLength = new ComparatorByLength();
TreeSet<String> tSet = new TreeSet<>(comparatorByLength);
tSet.add("abc");
tSet.add("Mbcdefg");
tSet.add("abk");
tSet.add("nba");
tSet.add("2nd");
for (String string : tSet) {
System.out.println(string);
}
}
}
class ComparatorByLength implements Comparator {
@Override
public int compare(Object o1, Object o2) {
String str1 = (String) o1;
String str2 = (String) o2;
// temp > 0 ,str1长
// temp = 0 ,长度相等
// temp > 0 ,str1短
int temp = str1.length() - str2.length();
// 这里的compareTo方法是字符串自带的方法
return temp == 0 ? str1.compareTo(str2) : temp;
}
}
运行结果:
14. Map集合的特点
- 存储的是键值对
- key不能重复
15.Map获取值示意图
--Map
--Collection
- List
- Set
Map接口和Collection接口是并列的,独立的。 List接口和Set接口是都隶属于Collection接口。
Collection接口下的集合可用迭代器Iterator获取所有的元素。而Map接口就没有迭代器,那怎么获取Map集合中的所有元素呢?
- 思路一: Map----通过keySet方法----获取key的集合Set----再用iterator方法和get(key)方法获取所有键值对。
- 思路二: Map----通过entrySet方法----获取包含键值对的Set<Map.Entry<key,value>>----再用iterator方法和Map.Entry对象的getKey()和getValue()获取所有键值对。
说明:使用思路二的效率更高。
16. Map接口的keySet()方法和values()方法
Map接口有一个keySet()方法可以获取所有键key的set集合(注意是set,所以可以不能重复),那想获取所有的值value的集合Collection怎么有什么方法码?可以使用values()方法获取所有的值。
HashMap<Object,Object> hashMap = new HashMap<>();
Set<Object> keySet = hashMap.keySet();
Collection<Object> values = hashMap.values();
17. Map接口常用的子类
Hashtable: 内部结构是哈希表,同步的,key和value都不能是null。
HashMap: 内部结构是哈希表,不同步的,key和value都可以是null。
TreeMap: 内部结构是二叉树,不同步的,value可以是空,可以对map集合中的key进行排序。
另外:
TreeMap也可以像TreeSet一样,包含new TreeMap(new 比较器()),实现自定义排序。
package map;
import java.util.HashMap;
import java.util.Hashtable;
import java.util.TreeMap;
public class MapDemo {
public static void main(String[] args) {
Hashtable<String, String> hashtable = new Hashtable<>();
// hashtable.put(null, "aaa"); // NullPointerException
// hashtable.put("abc", null); // NullPointerException
HashMap<String, String> hashMap = new HashMap<>();
hashMap.put(null, null); // 正常运行
TreeMap<String, String> treeMap = new TreeMap<>();
treeMap.put("abc", null); // 正常运行
// treeMap.put(null, "aaa"); // NullPointerException
}
}
