

看本文之前,不妨先看看:
1)MPM 卖场可视化搭建系统 — 要素设计
前言
这是 MPM 分享系列的第二篇,在上一篇 MPM 卖场可视化搭建系统 — 要素设计 中,我们介绍了 MPM 作为一个面向卖场场景的页面可视化搭建系统,最基础的系统要素都有哪些,并给出了系统要素的推导和设计过程。系统要素是一个庞大系统链接各个模块的纽带,也是系统设计的基石,而要素之上,才是系统的架构和流程。
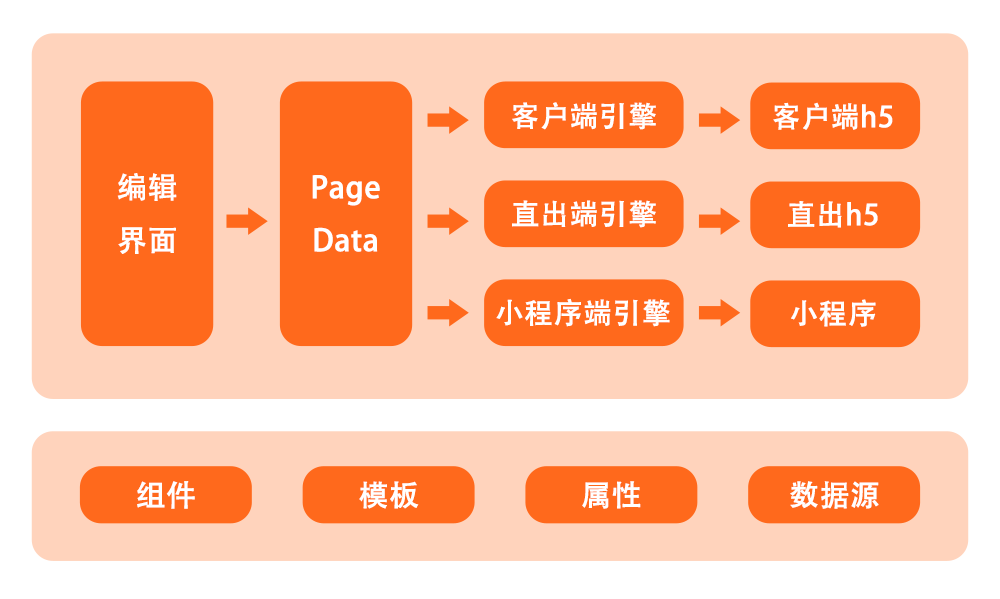
MPM 系统架构
我们所谈到的 MPM,并不单纯只是运营同学直接面对的卖场编辑系统,MPM 生成的卖场页面也是 MPM 一个重要的组成部分,因此,在架构上,MPM 主要由编辑系统和页面解析引擎构成。
编辑系统就是运营直接使用的 MPM 卖场编辑界面,经运营用户编辑配置,编辑系统生成一份页面数据 PageData,在不同端环境下,PageData 经由不同的页面解析引擎解析渲染,生成对应的卖场页面。从 MPM 架构图中我们也可以看到,整个 MPM 的架构流程是基于四大系统要素之上的,也就是说,编辑系统和解析引擎都有对四个系统要素的实现,用于完成对页面的组装呈现。
PageData
在 MPM 架构中,PageData 是链接编辑态(编辑配置)和展示态(用户浏览)的重要介质,它本质上是卖场页面的一层抽象描述,基于 PageData,各端的页面解析引擎能够知道如何生成对应的卖场页面。它除包括主要的页面配置数据外,还将承担页面在解析过程中的一些中间数据产物,比如请求数据缓存等。另一方面,利用 PageData 作为隔离,我们可以方便地实现一份编辑、多端展示。因此,合理设计 PageData 是实现 MPM 架构的关键一步。
在 MPM 中,我们用 JSON 来存放 PageData,这是 PageData 的标准结构:
{
"pageId": "", // 页面ID
"appType": 1, // MPM页面类型:1-活动 | 2-馆区 | 3-小程序
"pageConfig": {
"basic": {
"type": 2, // 业务类型:1-普通页面 | 2-京喜页面
"env": 2, // 渠道类型:1-手Q | 2-微信 | 3-M站
"bgColor": "#fff", // 页面背景色
"createDate": "", // 创建时间
"customCode": null, // 附加代码内容
"customCodeIn": 0, // 其他信息中的附加代码位置:0-插入顶部 | 1-插入底部
"expireTime": "", // 过期时间
"expireUrl": "", // 过期跳转链接
"name": "", // 页面名称
"path": "", // 页面路径
"status": 1, // 页面状态:1-有效 | 0-无效
"floorSortId": "", // 楼层排序id
"floorSortType": "", //排序类型 0-楼层排序 | 1-tab排序
"forceLogin": 0 // 是否强制登录:0-否 | 1-是
},
"search": {
"topShow": 0, // 是否展示顶部搜索框:0-否 | 1-是
"topRuleId": "", // 顶部搜索框金手指参数
"topAd": "", // 顶部搜索框暗文参数
"topBtnRd": "", // 点击搜索按钮rd
"topKeywordShow": 0, // 是否显示底部轮播热搜
"topKeywordRuleId": "", // 底部轮播热搜金手指参数
"bottomShow": 0, // 是否展示底部搜索模块:0-否 | 1-是
"bottomRuleId": "" // 底部搜索金手指参数
},
"share": {
"title": "京东购物", // 分享标题
"desc": "多·快·好·省", // 分享文案
"imgUrl": "//wq.360buyimg.com/img/mpm/defaultShare.jpg" // 分享图片
}
},
"userInfo": {
"checkNewuser": false, // 校验是否新人
"checkVip": false, // 校验是否VIP
"checkPlus": false, // 校验是否plus会员
"checkBind": false, // 校验查询是否绑定
"checkFirstBuy": false // 校验是否全站首购
},
"componentConfig": [], // 组件配置,也就是楼层配置
"template": {
// 模板相关
"vueFnObj": {}, // Record<样式id, 扩展方法>
"vueHook": {}, // Record<样式id, 钩子函数>
"styleTpl": {}, // Record<样式id, 模板渲染函数>
// 直出页用
"header": "", // 页面头部
"footer": "" // 页面底部
},
"dataCache": {
// 要缓存的数据
"userInfo": {}, // 用户身份数据
"floorSortData": {}, // 楼层排序数据
"dsCache": {} // 楼层业务接口数据缓存
}
}
这是一个页面保存生成的一个 PageData,虽然有点复杂但结构还算清晰:
1、pageId
MPM 卖场页面的唯一标识。
2、appType
MPM 的基础页面类型,目前共有三类:使用最多的活动类型(也是默认类型)、馆区固化运营的馆区类型、小程序类型。
3、pageConfig
页面级别的配置。包括:
-
pageConfig.basic:页面的基础配置,包括页面名称、页面状态、页面创建/过期时间、页面业务/渠道类型等; -
pageConfig.search:页面的搜索框配置,包括页面的顶部搜索框和底部搜索模块的详细配置; -
pageConfig.share:页面的分享配置。
4、userInfo
用户级别的配置,这些配置实际上不由运营控制,而是 MPM 编辑系统在保存时自动分析并设置的该页面的用户配置,比如运营使用了一个需要判断「用户是否为 VIP」的组件,则 MPM 将自动设置 userinfo.checkVip 为 true。在页面解析引擎中,用户级别的配置将在预加载(preload)阶段被处理,我们后续会说到。
5、componentConfig
楼层级别的配置,存放了运营详细的楼层配置,也是解析引擎最关注的配置。componentConfig 是一个对象数组,每个对象代表着一个楼层,其中包含了楼层组件的配置数据,包括楼层的公有属性配置和私有属性配置等,解析引擎将遍历这个数组,逐个渲染楼层。
6、template
页面的一些逻辑代码,主要包括一些公共逻辑和页面使用到的 MPM 模板。解析引擎会将模板和配置数据组装成页面内容进行展示,而这里只有 h5 页面才会用到。MPM 模板具体结构可参见 MPM 卖场可视化搭建系统 — 要素设计。
-
template.vueFnObj:map 对象,存放了模板和其对应的扩展函数的关系映射; -
template.vueHook:map 对象,存放了模板和其对应的声明周期钩子函数的关系映射; -
template.styleTpl:map 对象,存放了模板和其对应的 template 的关系映射; -
template.header:直出端使用的页面头,一段不完整的 HTML 代码块,包含了页面的一些公共优先逻辑,同时出于 CSS 优先原则,MPM 模板的样式代码也会在编辑保存阶段被存放到这里; -
template.footer:直出端使用的页面尾,一段不完整的 HTML 代码块,包含了页面的一些公共置底逻辑。
7、dataCache
页面请求接口后的一些数据缓存,主要作用是避免重复请求,尤其是避免直出端数据已完成拉取后,到达客户端再被重复请求一次。
PageData 的生成
PageData 是由编辑系统生成的,并实时维护在一个 SQL 数据表中。当页面被创建时,MPM 会初始化这个页面的 PageData,并新增一条 SQL 记录;当保存编辑内容时,编辑系统会将 PageData 实时同步到 SQL 数据库;而在发布页面时,PageData 会被处理成标准 JSON 结构,提供给各端解析引擎处理。
PageData 的数据库模型
在编辑系统,运营人员创建一个卖场页面时,系统将生成一个默认的页面 id,来唯一标识这个页面,同时生成一份初始化的 PageData,与之一并写入到 SQL 数据库中。SQL 数据库专门设计了一张数据表来存放运营创建的页面,它除作为唯一标识的 page_id 外,还包括了页面名称 page_name、页面路径 page_path、页面类型 page_type、创建人 page_creator、创建时间 page_create_date、页面内容 page_content 等表字段,其中页面内容 page_content 就是 PageData 中的组件配置 componentConfig,是一个序列化的 JSON 字符串。
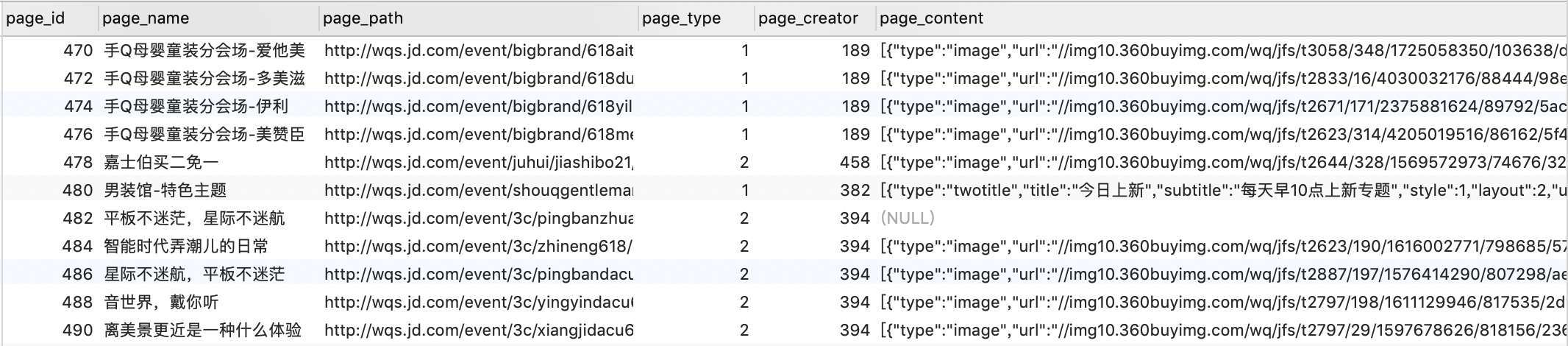
PageData 在数据表中的结构模型和其标准结构稍微有所不同,这里可能有些人会产生疑问:为什么要改动 PageData 的结构模型呢?页面名称、页面类型、创建时间等等这些,不都是属于 PageData 中的数据属性吗,为什么要单独拎出来,开设一个表字段来存放,直接序列化整个 PageData 进行存放不行吗?之所以这么设计,是因为无论是对于运营人员还是 MPM 管理人员而言,MPM 都需要提供一些必要的检索功能,譬如「搜索 XX 时间之前创建的所有页面」,这个时候,独立的表字段存放可以让我们十分方便地完成检索,甚至更复杂的多表连接查询。
那问题又来了,既然这样,page_content 为什么就是序列化成 JSON 字符串,而不展开存储呢?这是因为 page_content 的内部结构多变且难以保持一致(新增模板就会出现新的属性字段组合),且目前的检索需求少有涉及深入到组件配置中的苛刻检索,所以 page_content 展开存储的话,维护成本大且收益小,因此我们直接简单地将它序列化后,存放在一个表字段中。
如何生成 PageData
在 MPM 编辑系统中,一个卖场页面的编辑一般会经历加载、编辑、保存、发布四个阶段,这也是 PageData 生成的过程。
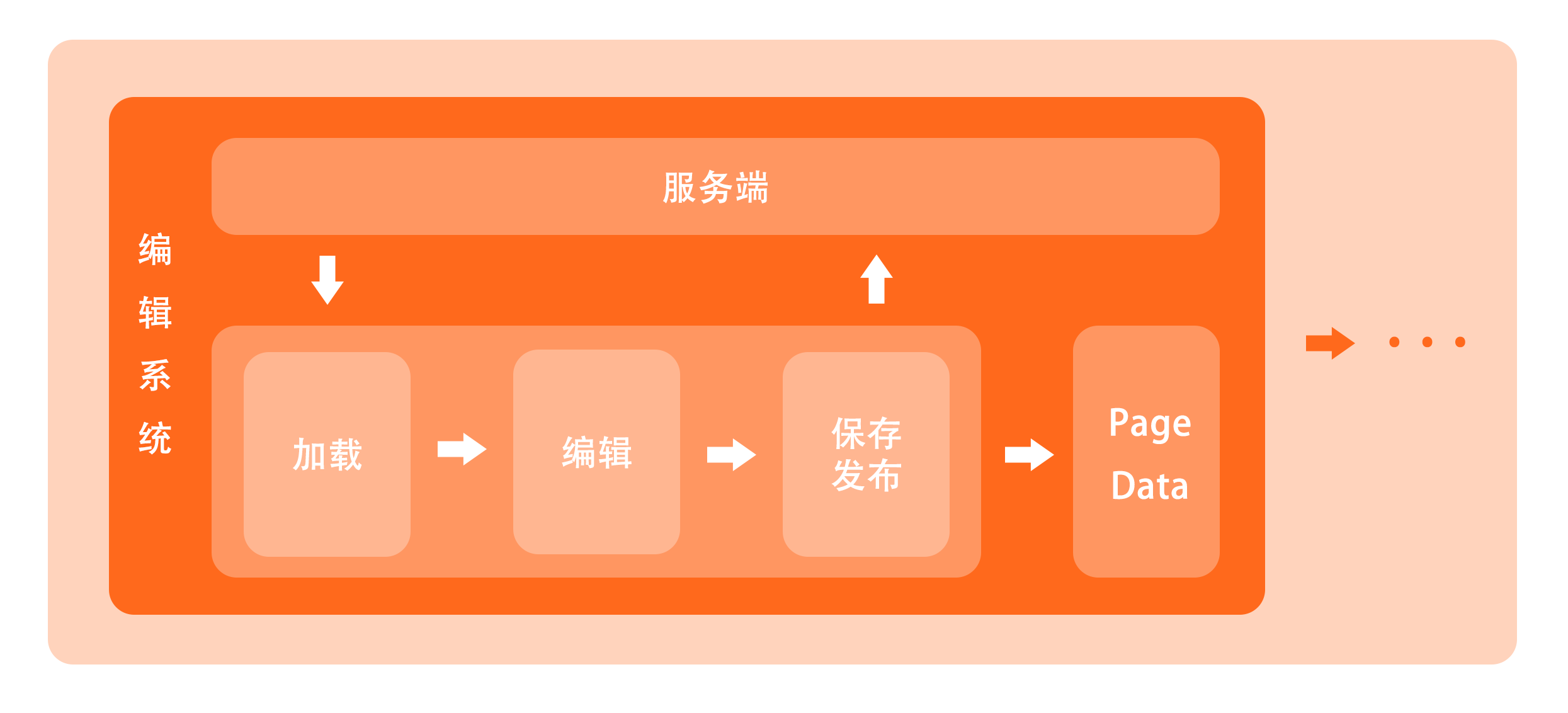
加载
加载也是编辑系统的初始化环节。在这个环节里,MPM 会从服务端拉取当前要编辑的 MPM 页面的 PageData,它包括了原先所有的配置数据。这里需要注意的是,服务端吐出的 PageData 还不是标准结构,这在前边也提到了。
当然,加载环节所做的事情远不止这些,包括用户鉴权、系统配置、新建页面等等的判断执行操作,都将在这个环节完成。
编辑
在这个环节,PageData 会随着用户的编辑配置而实时变化。同时,借助于 Vue 的监听能力(watch),我们实现了一个高效方便的编辑预览,用户每一次编辑的效果都能实时展示到预览区。
保存
编辑中途对页面进行保存操作时,MPM 会将最新的 PageData 再度提交到服务端,并更新到数据库。
同时,保存操作也将生成一个预览页面的链接,便于在终端上真实浏览,因此在提交数据库的同时,我们也会把 PageData 转化成标准的 JSON 结构,供给页面解析引擎进行解析。对于不同端环境的页面,保存过程也会有些区别,更具体的细节我们会在后续各端解析过程讲到。
发布
保存操作并不会将编辑结果更新到线上,仅仅只是生成一个替代的预览链接,要变更线上结果,需要对页面进行发布。发布的时候会默认进行一次保存操作,并根据不同页面类型(不同的端环境),执行不同的发布流程,更详细的我们将在接下来的 PageData 解析中分情况说明。
除此之外,在发布前、我们会进行页面诊断、RD 生成等前置操作,发布后,我们也会执行页面可访问性检测、自动化测试等后置操作。
PageData 的解析
MPM 在不同端环境下,提供了不同的页面解析引擎,解析流程基本相似但也有些不同。MPM 支持 H5 和小程序两种页面类型,其中 H5 页面默认支持直出访问和静态访问两种访问形态,所以 MPM 涉及的端环境一共有静态 H5、直出 H5、小程序三类环境。
静态 H5 的解析
静态 H5 提供了一个静态链接,页面其实是一个包含了必要 JS(如 H5 端解析引擎)的静态 HTML 文件,所以,静态 H5 解析实际上是一种基于 Vue 的客户端渲染。此前,静态访问曾作为线上 MPM 页面的主要访问形态,后来 MPM 逐步推广直出服务,才让静态链接退化为容灾链接,仅作为容灾访问和预览访问。
保存发布时
在保存阶段,我们做了一个页面组装,来生成静态页面。
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8" />
<title>{{title}}</title>
<!-- 头部 JS/CSS -->
<script></script>
<style>{{topCss}}</style>
</head>
<body>
<!-- 应用容器 -->
<div class="mpm-app"></div>
<script>
// page data
window.__PAGE_DATA__ = {{pageData}}
// 渲染模板
window.__COM_TPL__ = {{template}}
// 模板扩展方法
window.__COM_FNOBJ__ = {{fnObj}}
// 组件钩子函数
window.__COM_VUEHOOK__ = {{vueHook}}
</script>
<!-- 引擎 -->
{{engineCore}}
<!-- 底部 JS -->
<script></script>
</body>
</html>
这是一个简化的组装模板,它是一个字符串,我们可以看到里边有很多的双花括号写法,这其实是个简单的占位符。通过这个组装模板,我们把标准化后的 PageData,连同这个页面依赖到的 MPM 模板元素,包括 template、fnObj、vueHook,一并替换到对应占位符上,挂载在生成页面的 window 对象上。而依赖到的 CSS 代码,其实已经被合并到 topCss 中,放在页面的最顶部了。
除此之外,MPM 还将通过接口获取当前版本的解析引擎 engineCore,一并组装在页面底部。engineCore 其实是一段外部 JS 的引用代码:
<script src="//wq.360buyimg.com/martpagemakerv3/web/src/wq.vue2.engine.simplified.acf4f576ed9c5cb9f76d.js" crossorigin="true"></script>
发布时,我们把这个组装完成的 HTML 字符串(其实也就是生成的整个页面),提交到服务端,服务端存为一个 .html 静态文件,让线上可访问。
引擎解析时
当客户端加载页面,引擎代码得以执行。由于代码执行顺序,此时 window 已经挂载了 PageData(也就是页面数据)以及相关的渲染模板,引擎可以直接用于构建页面。
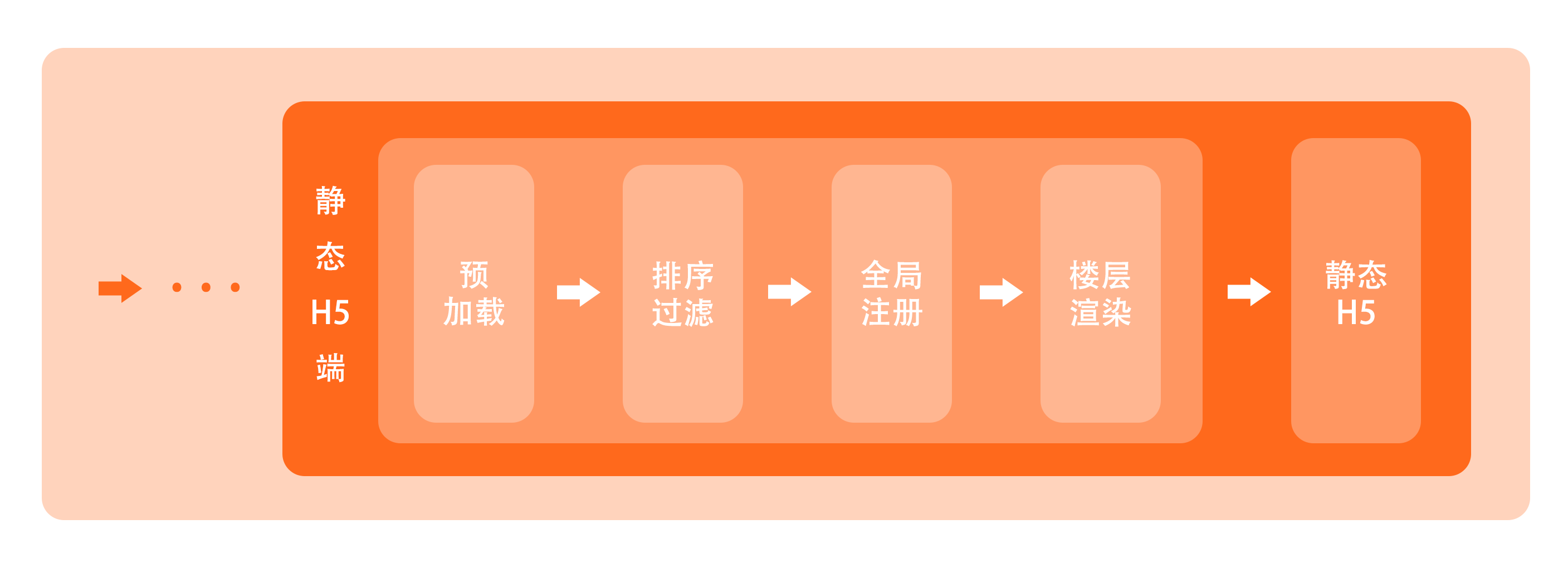
1、预加载
在构建页面之前,引擎其实还有一个预加载(preload)环节。这个阶段,引擎会根据用户身份配置 __PAGE_DATA__.userInfo 和楼层排序配置 __PAGE_DATA__.pageConfig.basic.floorSortId 提前通过接口获取用户身份信息和页面楼层排序信息。显而易见,预加载环节主要处理一些非楼层级别的数据依赖。
2、排序 & 过滤
当预加载接口请求全部到位后,引擎开始执行楼层排序。根据获取到的楼层 BI 数据,对原有的页面楼层配置 __PAGE_DATA__.componentConfig 做排序。紧接着,引擎的过滤管道(FilterPipe),再进一步对一些不需要展示的楼层进行排除,包括不在有效时间内的、不满足用户身份的、不满足渠道类型的,最后,基于新的 __PAGE_DATA__.componentConfig,引擎组装了一个楼层骨架,添加到 mpm-app 节点中,作为后续楼层渲染的容器。
<div class="mpm-app">
<div id="com_1001_con"><div com-root></div></div>
<div id="com_1002_con"><div com-root></div></div>
<div id="com_1003_con"><div com-root></div></div>
<div id="com_1004_con"><div com-root></div></div>
</div>
3、Vue 组件/指令的注册
之后,引擎会对 Vue 组件和 Vue 指令进行统一的全局注册,保证在后续页面渲染的时候,模板中可以正常使用。这里值得一提的是,为了减少引擎 JS 的体积,我们创造性地将引擎拆分为两个版本 —— 全量版和简化版,全量版引擎包含了所有的 Vue 组件/指令,而简化版引擎只包含一些常用的 Vue 组件/指令,其大小比全量版引擎少了近 150 kb。而一个页面到底是使用全量版引擎还是简化版引擎,我们会在编辑系统保存页面的时候进行代码静态分析,来判断这个页面是否使用了简化版引擎未囊括的 Vue 组件/指令,如果是,就改用全量版引擎。通过定期的统计维护,我们让 85% 以上的页面都能使用到简化版引擎。
当然这样依然存在不少的无用代码(unused code),那为什么我们不在页面保存的时候,根据依赖分析,动态打包出属于页面自身的引擎包呢?这主要是考虑到动态打包的 JS 代码没有经过严谨测试直接上线,存在一定风险,因此我们才选用了保守的打包方式,在未有完善的测试方案之前,双版本引擎依然是比较合理的实践方案。
4、楼层渲染
完成这些前置步骤之后,只需要遍历 __PAGE_DATA__.componentConfig,利用 Vue 逐步实例节点并挂载,就能完成渲染了。
// 页面渲染入口
function renderPage () {
__PAGE_DATA__.componentConfig.forEach(createComponent);
// ...
}
function createComponent (com) {
const comId = com.id;
// el 是在步骤 2 中生成的页面节点,是楼层容器
const el = document.querySelector(`#${comId}_con>[com-root]`);
const data = utils.copy(__PAGE_DATA__[comId]); // 深拷贝一份配置数据
data.fnObj = __COM_FNOBJ__[comId]; // 渲染函数
new Vue({
el, // 容器
data, // 配置数据
render: __COM_TPL__[comId], // 渲染函数
mounted () {
__COM_VUEHOOK__[comId]['mounted'](); // 钩子函数
}
});
}
至于楼层自身的业务接口数据,此前在 MPM 卖场可视化搭建系统 — 要素设计 中已经讲过,是通过一个 ds 组件完成的。ds 存在于模板中,会在上边楼层实例化时被执行到,进而发起请求,接收数据,并再次触发渲染。
直出 H5 的解析
针对静态 H5 首屏体验差的问题,MPM 打造了一个高可用的 Node 服务,为所有 H5 页面提供直出能力。在直出端,MPM 页面解析引擎只负责渲染首屏内容,页面余下内容会等到页面到达客户端后,再由客户端进行渲染补充。
保存发布时
H5 在保存发布时,一方面会组装生成静态 H5 作为直出容灾用,另一方面则将 PageData(其中包括了配置数据、MPM 模板、页面头尾等未组装的代码块)提交到 Node 服务端,写入到 Redis 中。
引擎解析时
MPM 的 Node 直出端基于 Express 框架设计,承载着 MPM 的直出解析引擎。同样地,MPM 直出端引擎也内置了和静态 H5 引擎逻辑相同的一套 Vue 组件。
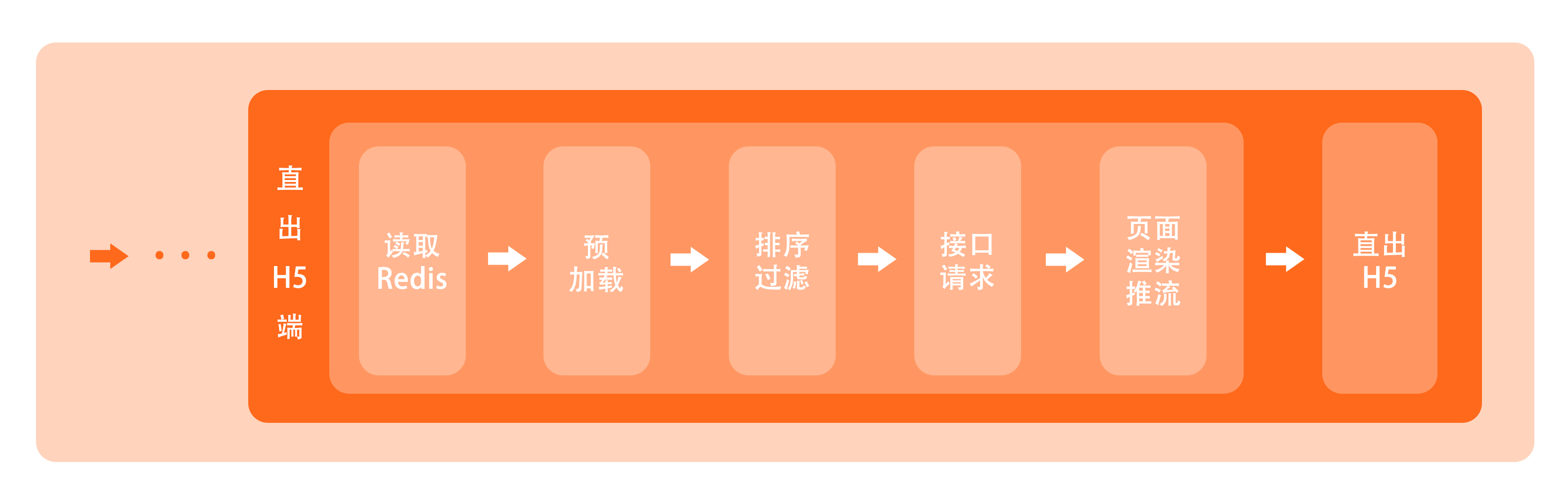
1、读取 Redis
直出端以访问为单元,每趟访问都有一个独立的上下文。当用户访问某个直出页面时,通过 Express 中间件,MPM 直出端首先会初始化一个访问上下文,它包含了页面的 URL 参数、请求 Cookie、User-Agent 等信息,同时,我们也将根据请求参数 pageid,从 Redis 中获取到页面数据,并入访问上下文,用于后续页面组装。
2、预加载、排序 & 过滤
预加载、排序过滤环节在直出端同样存在,与静态 H5 端没有太大差异,这里不再赘述。
3、页面数据请求
这个环节是直出端模型和客户端模型最大的区别之一。在客户端我们可以有多次渲染,所以我们利用 Vue 的响应式更新,让数据请求滞后处理,但在直出端,我们实现的是流式渲染,有且只有一趟渲染,渲染前要求渲染数据必须全部到位,因此在直出端,我们必须提前进行页面数据请求。
所以在这个环节里,我们其实是提前完成了 ds 组件所做的事情。我们收集了每个楼层即将发起的业务接口请求,统一处理并存入缓存对象,等到渲染执行到 ds 组件时,ds 会先去检查缓存对象中是否有缓存数据,如果有,则直接使用。当然了,这里我们只考虑前二十个楼层,以此作为页面首屏,其余楼层的渲染由客户端负责。
实际上,这里边具体的实现方案并非最佳,相反存在着诸多不合理,所以我不在这里作细致讲解。目前我们也正准备对此进行改造,在后续文章我们会针对 MPM 数据模型的演化再跟大家深入探讨,什么样的数据模型能够更好地契合 MPM 的前后端渲染。
4、页面渲染
数据就位后,我们利用 vue-server-renderer 来完成 Vue 的服务端渲染:
import { createRenderer } from 'vue-server-renderer';
const renderer = createRenderer();
// 页面渲染入口
async renderPage () {
// 输出页面头
await context.res.write(pageTop);
// 输出页面楼层内容
await renderApp();
// 输出页面尾
await context.res.write(pageBottom);
}
// 渲染页面主体
renderApp () {
return Promise((resolve, reject) => {
// 创建 app 的 Vue 实例
let app = new Vue({
data: rootData,
methods: rootMethods,
render: renderFn
});
// 创建渲染流
const stream = renderer.renderToStream(app);
// 分段输出
stream.on('data', chunk => {
// ...
context.res.write(chunk);
});
stream.on('end', () => {
// ...
app.$destroy();
resolve();
});
})
}
在这一步,我们不再是每个楼层各自创建一个 Vue 实例,而是将 PageData 和模板全部合并,只用一个根 Vue 实例来渲染,这样我们才能使用 renderToStream 来创建一个渲染流(render stream),完成向客户端的分段输出。
小程序的解析
MPM 事先在业务小程序中打造了一套与系统组件/模板一一对应、UI 百分百还原的小程序组件,小程序渲染其实就是根据 PageData,把这些已经备好的小程序组件拿出来组合成期望的页面。
保存发布时
MPM 的小程序页面是和 H5 页面区分开来的两种不同页面类型,编辑流程也是独立的。MPM 小程序页面在保存发布时,仅仅只是将标准化后的 PageData 提交给服务端,生成了一份 JSON 文件。
引擎解析时
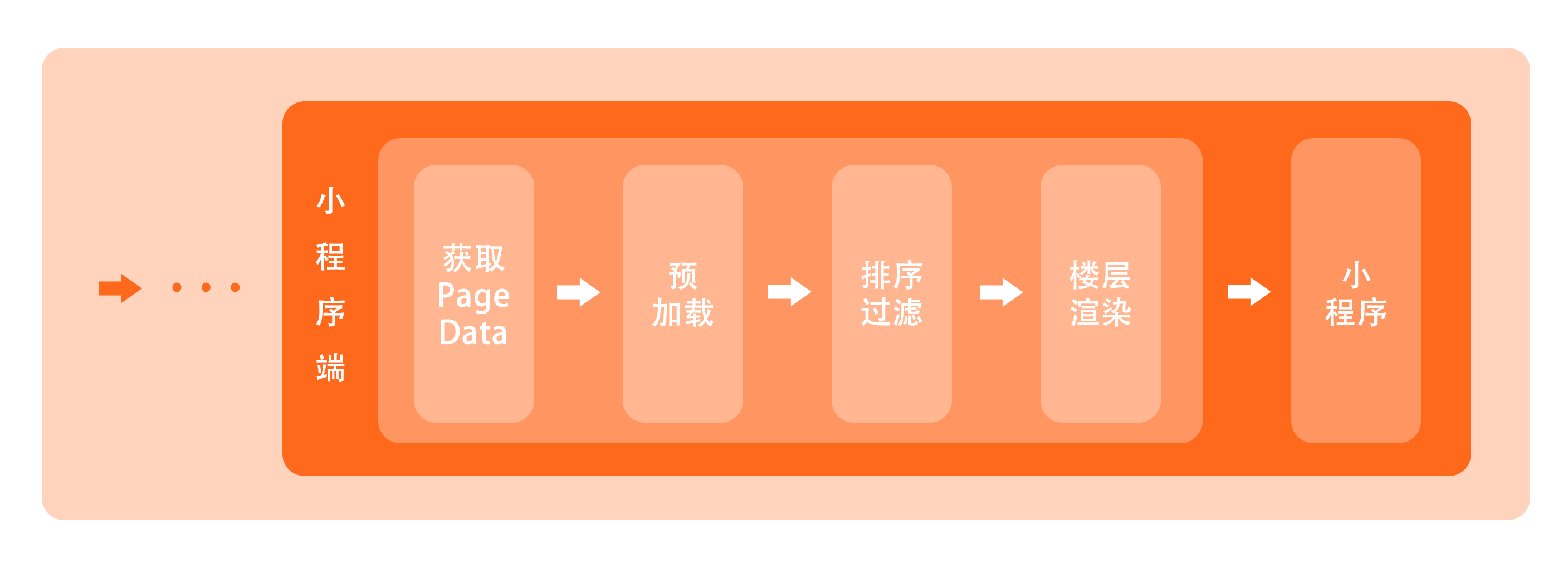
1、获取 PageData
在小程序中打开 MPM 搭建的页面时,引擎首先会请求获取该页面对应的 PageData。
2、渲染页面
小程序页面的解析,本质上也是一种客户端渲染,因此这一步其实跟静态 H5 渲染没什么不同了,同样地,先进行预加载和楼层排序,然后根据 PageData 的楼层配置,选择渲染对应的小程序组件,最终渲染出整个页面。
末尾
了解完整个 MPM 的流程机制之后,其实很容易发现一个问题:不同端引擎的实现逻辑存在太多类似的了!每一次有需求迭代的时候,总是要同时改动静态端、直出端、小程序端多处代码,重复测验,这给我们造成了极大的人力损耗,也十分难维护(你真的很难保证写在三个地方的同一份代码不会出现差异)。在这种情况下,三端同构,作为一个有效的解决方案出现在我们面前,「一处编写,三端运行」无疑是一个美好的愿景。但是,除了三端同构的技术难度外,MPM 发展至今已经十分庞大,其内部逻辑十分复杂,要完成这种体量的重构,在如何实现同构编译、如何完成系统兼容过渡等等问题上,还需要投入更多的思考。
如果你觉得这篇内容对你有价值,欢迎点赞并关注我们前端团队的 官网 和我们的微信公众号 WecTeam,每周都有优质文章推送~

