


《面试查漏——Http篇》
你知道的越多,你不知道的越多
本文 GitHub JavaStudy 欢迎Star和完善,里面放了学习的一些资料,希望我们一起学习冲进大厂。
Http出现背景
设计HTTP最初的目的是为了提供一种发布和接收HTML页面的方法。
HTTP0.9
最初的http版本为0.9 单行文本协议,没有听说过吧 举个例子
GET /mypage.html
响应也十分简单
<HTML>
这是一个非常简单的HTML页面
</HTML>
单行文本协议只有get请求方法 且没有方法头,只有目标资源路径,返回的内容也只有html文本文件。
HTTP1.0
那我打错了一个字母没找到这个文件该咋办呢 又不给我响应,像极了课上给女神写信的我,却被室友错投给了如花。

于是1.0版本诞生了!1.0版本是对0.9版本进行拓展 主要提升在以下四个方面
- 版本协议添加在请求头中
- 响应添加响应状态码
- 引入了HTTP头的概念,无论是对于请求还是响应,允许传输元数据,使协议变得非常灵活,更具扩展性。
- 在新HTTP头的帮助下,具备了传输除纯文本HTML文件以外其他类型文档的能力(感谢
Content-Type头)。
GET /mypage.html HTTP/1.0
User-Agent: NCSA_Mosaic/2.0 (Windows 3.1)
200 OK
Date: Tue, 15 Nov 1994 08:12:31 GMT
Server: CERN/3.0 libwww/2.17
Content-Type: text/html
<HTML>
一个包含图片的页面
<IMG SRC="/myimage.gif">
</HTML>
面试官:小伙子理论知识可以鸭,你给我大白话翻译翻译!
嘿,你这还想难倒我。简单的说1.0版本 请求头中可以添加使用的http协议版本号,来区别0.9还是1.0,其次对于响应,报文返回请求方一个响应码来让你了解请求的状态是成功还是失败(失败的原因是啥)。你还可以在请求中添加你想要添加的数据,除此之外返回的文件类型也不止html一种了。
HTTP1.1
1.0版本发布后, 多种不同的实现方式在实际运用中显得有些混乱,自1995年开始,即HTTP/1.0文档发布的下一年,就开始修订HTTP的第一个标准化版本。1.1版本出现!
1.1是对1.0版本进行标准化,消除了歧义的内容并添加了多项改进。
- 连接可以复用,节省了多次打开TCP连接加载网页文档资源的时间。
- 增加管线化技术,允许在第一个应答被完全发送之前就发送第二个请求,以降低通信延迟。
- 支持响应分块。
- 引入额外的缓存控制机制。
- 引入内容协商机制,包括语言,编码,类型等,并允许客户端和服务器之间约定以最合适的内容进行交换。
- 感谢
Host头,能够使不同域名配置在同一个IP地址的服务器上。
好吧这就是是一个Http1.1版本的请求,密密麻麻的信息。别怕一条条分析就好
GET /en-US/docs/Glossary/Simple_header HTTP/1.1 #采用get请求 使用的协议版本为1.1 中间的就是url
Host: developer.mozilla.org #host头部信息
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:50.0) Gecko/20100101 Firefox/50.0 #用户代理的信息 mac ox 操作系统,火狐浏览器
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 #接收的文件类型
Accept-Language: en-US,en;q=0.5 #接收的文件语言
Accept-Encoding: gzip, deflate, br #接收的编码方式
Referer: https://developer.mozilla.org/en-US/docs/Glossary/Simple_header
200 OK #响应码200 ok表示成功获取到了
Connection: Keep-Alive #连接方式使用长连接 即连接可以复用
Content-Encoding: gzip #内容编码方式 验证一下是否在 Accept-Encoding中呢
Content-Type: text/html; charset=utf-8 #内容的类型 以及编码方式
Date: Wed, 20 Jul 2016 10:55:30 GMT
Keep-Alive: timeout=5, max=1000 #保持长连接时间
Last-Modified: Tue, 19 Jul 2016 00:59:33 GMT
Server: Apache #服务器的类型
(content)
面试官:让你给我讲讲大白话,你咋有给我说了一串理论的知识,小伙子你理解能力是不是不行。
 是这样的,Http1.0中用户每发出一个请求,服务器和浏览器就是建立**一次Tcp连接**,Http1.1中服务器和浏览器只只要建立一次连接,在一个TCP连接上可以传送**多个HTTP请求和响应**,减少了建立和关闭连接的消耗和延迟,这便是复用。因为只需要建立一次Tcp连接所以后面的请求等待前面请求的返回才能获得执行机会,一旦有某请求超时等,后续请求只能被阻塞,毫无办法,也就是人们常说的**线头阻塞**,也就是**管线化**技术。除此之外HTTP1.1则引入了更多的缓存控制策略例如Entity tag,If-Unmodified-Since, If-Match, If-None-Match等更多可供选择的缓存头来控制缓存策略。缓存就是保存资源副本在下次使用时直接使用的资源。
是这样的,Http1.0中用户每发出一个请求,服务器和浏览器就是建立**一次Tcp连接**,Http1.1中服务器和浏览器只只要建立一次连接,在一个TCP连接上可以传送**多个HTTP请求和响应**,减少了建立和关闭连接的消耗和延迟,这便是复用。因为只需要建立一次Tcp连接所以后面的请求等待前面请求的返回才能获得执行机会,一旦有某请求超时等,后续请求只能被阻塞,毫无办法,也就是人们常说的**线头阻塞**,也就是**管线化**技术。除此之外HTTP1.1则引入了更多的缓存控制策略例如Entity tag,If-Unmodified-Since, If-Match, If-None-Match等更多可供选择的缓存头来控制缓存策略。缓存就是保存资源副本在下次使用时直接使用的资源。
HTTP2.0
http1.1的稳定使用15中,网页愈渐变得的复杂,甚至演变成了独有的应用,可见媒体的播放量,增进交互的脚本大小也增加了许多:更多的数据通过HTTP请求被传输。HTTP/1.1链接需要请求以正确的顺序发送,理论上可以用一些并行的链接(尤其是5到8个),带来的成本和复杂性堪忧。比如,HTTP管线化(pipelining)就成为了Web开发的负担。于是2.0版本 诞生了
你问我为啥叫2.0版本,1.2,1.3哪去了,哎呦你就想华为都出到p40了,你见过华为p14吗?厂家命名呗,想叫啥叫啥。
HTTP/2在HTTP/1.1有几处基本的不同:
- HTTP/2是二进制协议而不是文本协议。不再可读,也不可无障碍的手动创建,改善的优化技术现在可被实施。
- 这是一个复用协议。并行的请求能在同一个链接中处理,移除了HTTP/1.x中顺序和阻塞的约束。
- 压缩了headers。因为headers在一系列请求中常常是相似的,其移除了重复和传输重复数据的成本。
- 其允许服务器在客户端缓存中填充数据,通过一个叫服务器推送的机制来提前请求。
面试官,这回不用你问了,我用大白话来解释一遍。
复用协议
复用协议是多个请求可同时在一个连接上并行执行。某个请求任务耗时严重,不会影响到其它连接的正常执行;
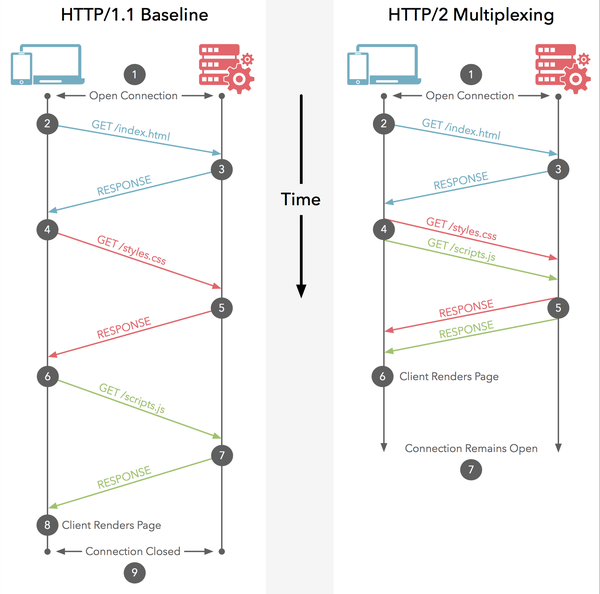
HTTP 性能优化的关键并不在于高带宽,而是低延迟。TCP 连接会随着时间进行自我「调谐」,起初会限制连接的最大速度,如果数据成功传输,会随着时间的推移提高传输的速度。这种调谐则被称为 TCP 慢启动。由于这种原因,让原本就具有突发性和短时性的 HTTP 连接变的十分低效。 HTTP2 通过让所有数据流共用同一个连接,可以更有效地使用 TCP 连接,让高带宽也能真正的服务于 HTTP 的性能提升。这也就是多路复用的好处。
服务器推送
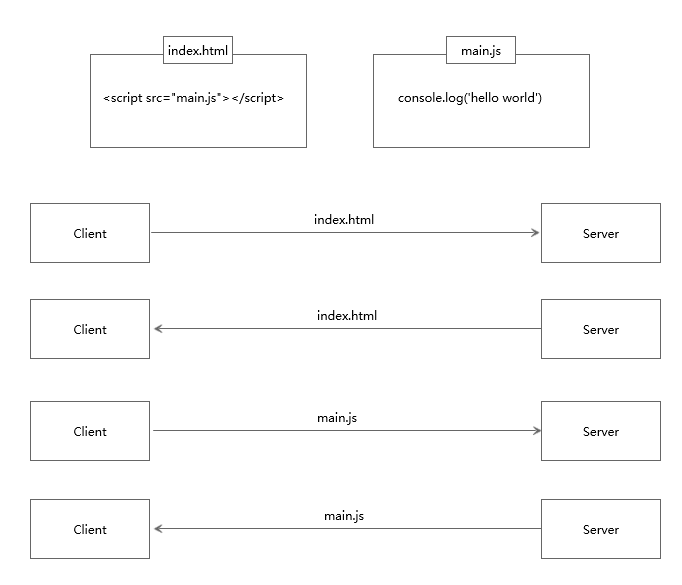
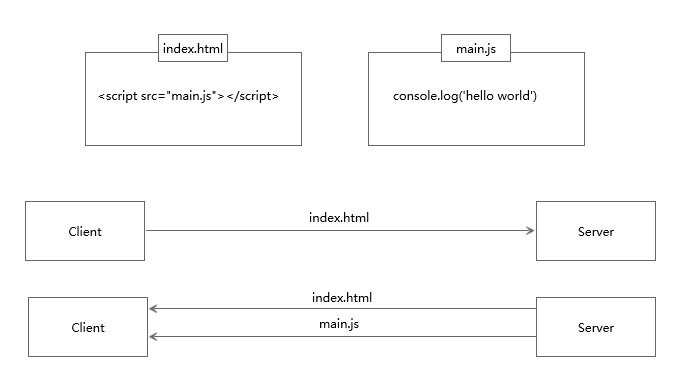
服务器推送是指:服务端推送能把客户端所需要的资源伴随着index.html一起发送到客户端,省去了客户端重复请求的步骤。正因为没有发起请求,建立连接等操作,所以静态资源通过服务端推送的方式可以极大地提升速度。具体如下:
普通模式
服务器推送
头部压缩
假定一个页面有100个资源需要加载(这个数量对于今天的Web而言还是挺保守的), 而每一次请求都有1kb的消息头(这同样也并不少见,因为Cookie和引用等东西的存在), 则至少需要多消耗100kb来获取这些消息头。HTTP2.0可以维护一个字典,差量更新HTTP头部,大大降低因头部传输产生的流量。
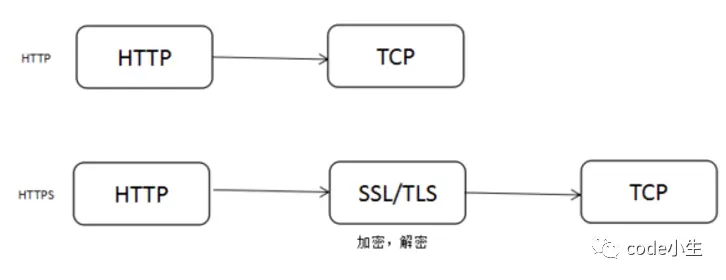
HTTPS拓展
-
HTTPS协议需要到CA申请证书,一般免费证书很少,需要交费。
-
HTTP协议运行在TCP之上,所有传输的内容都是明文,HTTPS运行在SSL/TLS之上,SSL/TLS运行在TCP之上,所有传输的内容都经过加密的。
-
HTTP和HTTPS使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
-
HTTPS可以有效的防止运营商劫持,解决了防劫持的一个大问题。
点关注,不迷路
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是人才。
如果本篇博客有任何错误,请批评指教,不胜感激 !
文章每周持续更新,你的关注就是我的动力,本文 GitHub JavaStudy 欢迎Star和完善,里面放了学习的一些资料,希望我们一起学习冲进大厂。争取一个礼拜两篇博客,每日一道算法题!
