

此文为学习何晗老师《自然语言处理入门》笔记
分类问题
定义
- 分类(classification):预测样本所属类别的一类问题。
分类问题的目标就是给定输入样本,将其分配给
种类别
中的一种,其中
。
如果$K = 2,则成为二分类(binary classification),否则称为多分类(multiclass classification)。比如性别预测{男,女}属于二分类问题。
正如二进制可以表示任意进制一样,二分类也可以解决任意类别数的多分类问题。具体如下两种方案:
- one-vs-one: 进行多轮二分类,每次区分两种类别
和
。共进行
次二次分类,理想情况下有且仅有一种类别
每次都胜出,则预测结果为
- one-vs-rest:依然是多轮二分类,每次区分类别
次二分类。理想情况下,模型给
可见one-vs-rest成本更低,但正负样本数量不均匀,也会降低分类准确率。
应用
在NLP领域,绝大多数任务可以用分类来解决:
- 文本分类
- 关键词提取时,对文章中的每个单词判断是否属于关键词,转化为二分类
- 指代消解问题中,对每个代词和每个实体判断是否存在指代关系
- 在语言模型中,将词表中每个单词作为一种类别,给定上下文预测接下来要出现的单词
线性分类模型与感知机算法
线性模型(linear model)用一条线性直线或高维平面将数据一分为二,构成:
- 一系列用来提取特征的特征函数
- 权重向量
特征向量与样本空间
- 特征向量:描述样本特征的向量
- 特征提取:构造特征向量的过程
- 特征函数:提取每种特征的函数
- 指示函数(indicator function):在线性模型中,特征函数的输出一般是二进制的1或0,表示样本是否含有该特征,所以特征函数也是指示函数的一个实例
- 样本空间:样本分布的空间
一旦将数据转换为特征向量,那么分类问题就转换为对样本空间的分割。
- 定义特征向量
,第
个样本的特征为
,相应的标签为
。
- 则训练集可以表示为
个二元组
- 测试集则是一系列标签未知的样本点
那么怎样对样本进行分类呢?
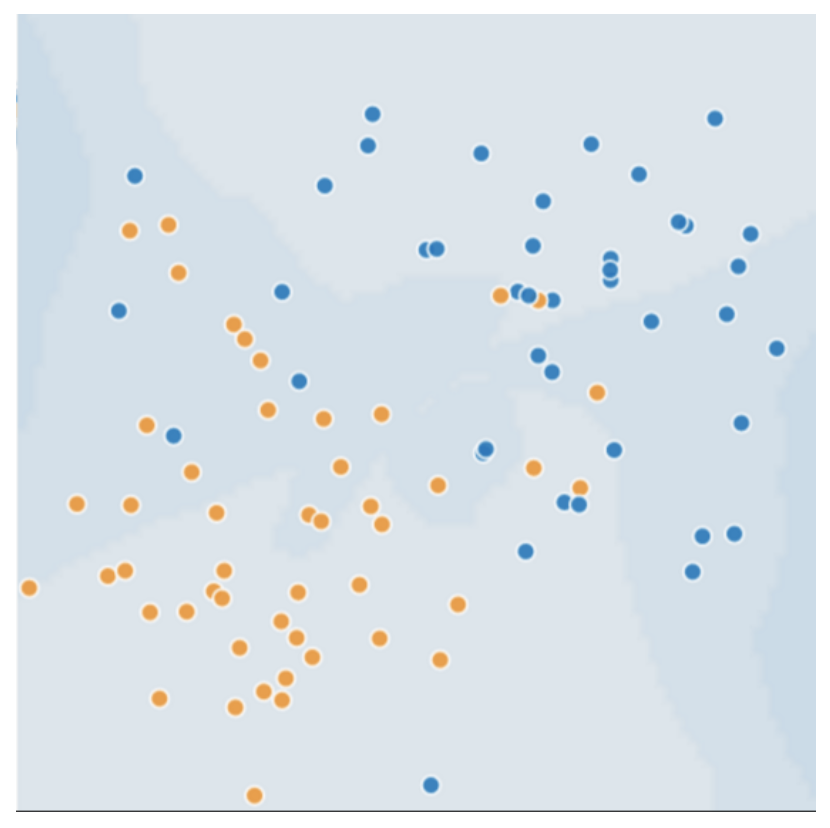
决策边界与分离超平面
- 决策区域(decision region):如上图,一条之间将平面分为两个部分
- 决策边界(decision boundary):决策区域的边界
- 线性分类模型:二维空间中,如果决策边界是直线,产生的决策边界模型
- 分离超平面(separating hyperplane):任意维度空间中的线性决策边界
如维空间分离超平面的方程:
其中,是权重,
是偏置。为了美观,可以将
也堪称一个权重:
则超平面可以简化为权重向量与特征向量的内积:
有了决策边界和方程后,线性模型使用方程左边的符号作为最终决策:
- 线性可分:如果数据集中所有样本都可以被分离超平面分割
感知机算法
即给定训练集,如何训练线性模型
感知机算法(Perceptron Algorithm)是一种迭代算法:
- 读入训练样本
,执行预测
- 如果
,则更新参数
- 在线学习:在训练集的每个样本上执行步骤1、2称为一次在线学习
- 迭代(epoch):把训练集完整学习一遍称为一次迭代
- 超参数(hyperparameter):人工指定的参数
损失函数与随机梯度下降
- 损失函数
:用来衡量模型在训练集上的错误程度
- 学习率:上式中的
- 随机梯度下降(Stochastic Gradient Descent, SGD):如果算法每次迭代随机选取部分样本,计算损失函数的梯度让参数反向移动
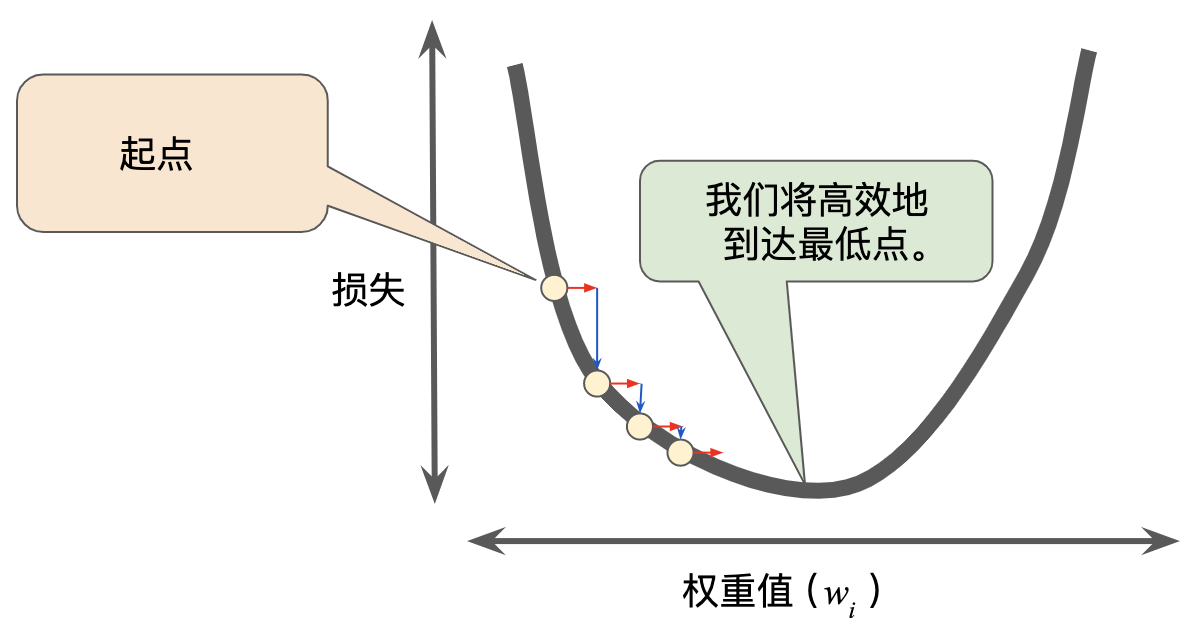
- 随机梯度上升(Stochastic Gradient Ascend):参数更新的方向是梯度的方向
平均感知机
- 当前时刻
,为每个参数
初始化累计量
,上次更新时刻
,读入训练样本
,执行预测
- 如果
,则对所有需更新(
)的
- 更新
- 更新
- 更新
- 更新
- 训练指定迭代次数后计算平均值:
代码实现-> 基于感知机的人名性别识别
人名语料库
于光浦,男
孙爱仙,女
杨莲菊,女
赵东祥,男
特征提取
List<Integer> extractFeature(String text, FeatureMap featureMap) {
List<Integer> featureList = new LinkedList<Integer>();
String givenName = extractGivenName(text);
// 特征模板1:g[0]
addFeature("1" + givenName.substring(0, 1), featureMap, featureList);
// 特征模板2:g[1]
addFeature("2" + givenName.substring(1), featureMap, featureList);
return featureList;
}
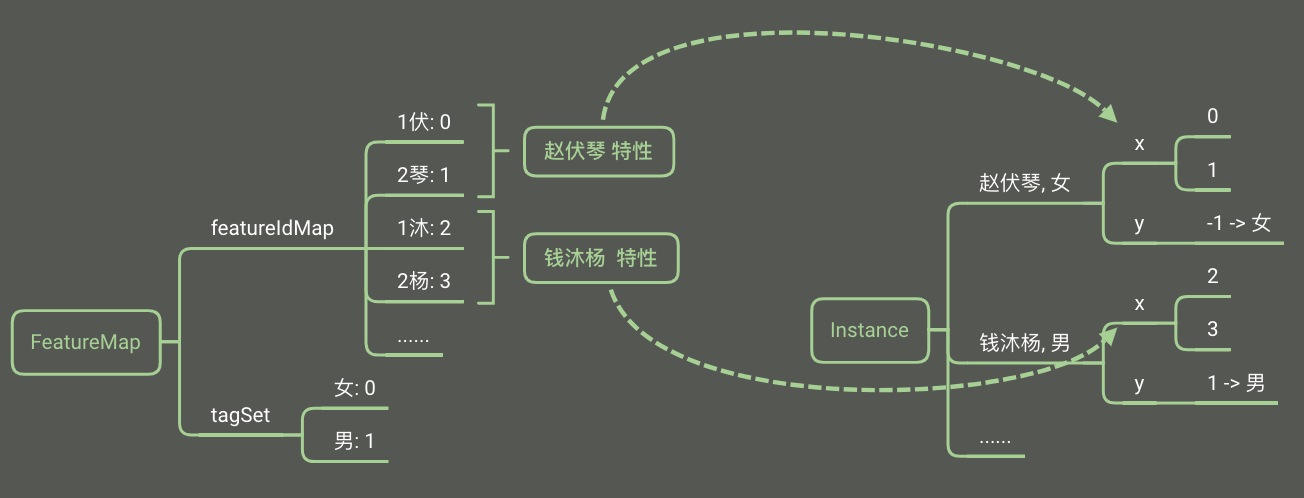
训练
- 迭代训练
/**
* 朴素感知机训练算法
* @param instanceList 训练实例
* @param featureMap 特征函数
* @param maxIteration 训练迭代次数
*/
LinearModel trainNaivePerceptron(Instance[] instanceList, FeatureMap featureMap, int maxIteration) {
LinearModel model = new LinearModel(featureMap, new float[featureMap.size()]);
for (int it = 0; it < maxIteration; ++it) {
Utility.shuffleArray(instanceList);
for (Instance instance : instanceList) {
int y = model.decode(instance.x);
if (y != instance.y) // 误差反馈
model.update(instance.x, instance.y);
}
}
return model;
}
- 预测与更新参数
/**
* 分离超平面解码预测
*
* @param x 特征向量
* @return sign(wx)
*/
int decode(Collection<Integer> x) {
float y = 0;
for (Integer f : x) {
// 更新每个特征的对应参数
y += parameter[f];
}
return y < 0 ? -1 : 1;
}
/**
* 参数更新
*
* @param x 特征向量
* @param y 正确答案
*/
void update(Collection<Integer> x, int y) {
assert y == 1 || y == -1 : "感知机的标签y必须是±1";
for (Integer f : x) {
// 更新每个参数
parameter[f] += y;
}
}
- 根据训练好的模型预测
public String predict(String text) {
// 根据当前字符串提取到特征,执行上面的预测方法
int y = model.decode(extractFeature(text, model.featureMap));
if (y == -1)
y = 0;
// 将预测转换为标签字符
return model.tagSet().stringOf(y);
}
结构化预测问题
- 结构化预测(structured prediction):预测对象结构的一类监督学习问题
预测结果的区别
- 分类问题:一个决策边界
- 回归问题:一个实际标量
- 结构化预测:一个完整的结构
应用:
- 序列化标注:一整个序列
- 句法分析:一棵语法树
- 机器翻译:一段完整的译文
结构化预测与学习流程: 给定一个模型及打分函数
,利用打分函数给一些备选结构打分,选择分数最高的结构作为预测输出:
其中是备选结构的集合
线性模型的结构化感知机算法
线性结构感知机算法
打分函数特征与结构
- 之前线性模型的打分函数
- 将
也作为一种特种,特征函数
,与权重
点积后得到标量作为分数:
- 对应的最大分数:
计算过程:
- 读入样本
- 与正确答案对比,若
- 奖励正确答案:
- 惩罚错误结果:
- 奖惩结合:
- 奖励正确答案:
结构化感知机与序列标注
在线性模型中(不同于隐马尔科夫模型),对序列中的连续标签提取如下转移特征:
其中为序列预测第
个标签,
为标注集第
种标签,
为标注集大小。
为第一个元素之前的虚拟标签,
为转移特征编号,加上
共有
种转移特征
类比隐马尔科夫模型,每个时刻的状态特征:
则结构化感知机特征函数就是转移特征和状态特征的合集:
简化为 ,则整个序列的分数:
得出最高分的方法:维比特解码算法
- 初始化:
时初始优化路径备选由
个状态组成,前驱为空:
- 递推:当
时每条备选路径增长一个单位,找出局部最优解
- 终止:找到最终时刻
数组中最大分数
,以及对应的结尾状态下标
- 回溯:根据前驱数组
回溯前驱状态,取得最后解下标
代码实现 -> 基于结构化感知机的中文分词
特征提取
示例
布什将出任美国总统
布什/nr 将/d 出任/v 美国/ns 总统/n
特征会加上位置信息,下面有示例特征对应的编码:
| 转移特征 | 状态特征 | 示例 |
示例 |
|---|---|---|---|
| 1 -> 5 | 布1 -> 12 | ||
| 布2 -> 6 | 什2 -> 13 | ||
| 什3 -> 7 | 将3 -> 14 | ||
| /4 -> 8 | /布4 -> 15 | ||
| /布5 -> 9 | 布/什5 -> 16 | ||
| 布/什6 -> 10 | 什/将6 -> 17 | ||
| 什/将7 -> 11 | 将/出7 -> 18 |
protected int[] extractFeature(String sentence, FeatureMap featureMap, int position) {
List<Integer> featureVec = new LinkedList<Integer>();
char pre2Char = position >= 2 ? sentence.charAt(position - 2) : CHAR_BEGIN;
char preChar = position >= 1 ? sentence.charAt(position - 1) : CHAR_BEGIN;
char curChar = sentence.charAt(position);
char nextChar = position < sentence.length() - 1 ? sentence.charAt(position + 1) : CHAR_END;
char next2Char = position < sentence.length() - 2 ? sentence.charAt(position + 2) : CHAR_END;
StringBuilder sbFeature = new StringBuilder();
// 一元语法特征
sbFeature.delete(0, sbFeature.length());
sbFeature.append(preChar).append('1');
addFeature(sbFeature, featureVec, featureMap);
.............................
// 二元语法特征
sbFeature.delete(0, sbFeature.length());
sbFeature.append(pre2Char).append("/").append(preChar).append('4');
addFeature(sbFeature, featureVec, featureMap);
.............................
return toFeatureArray(featureVec);
}
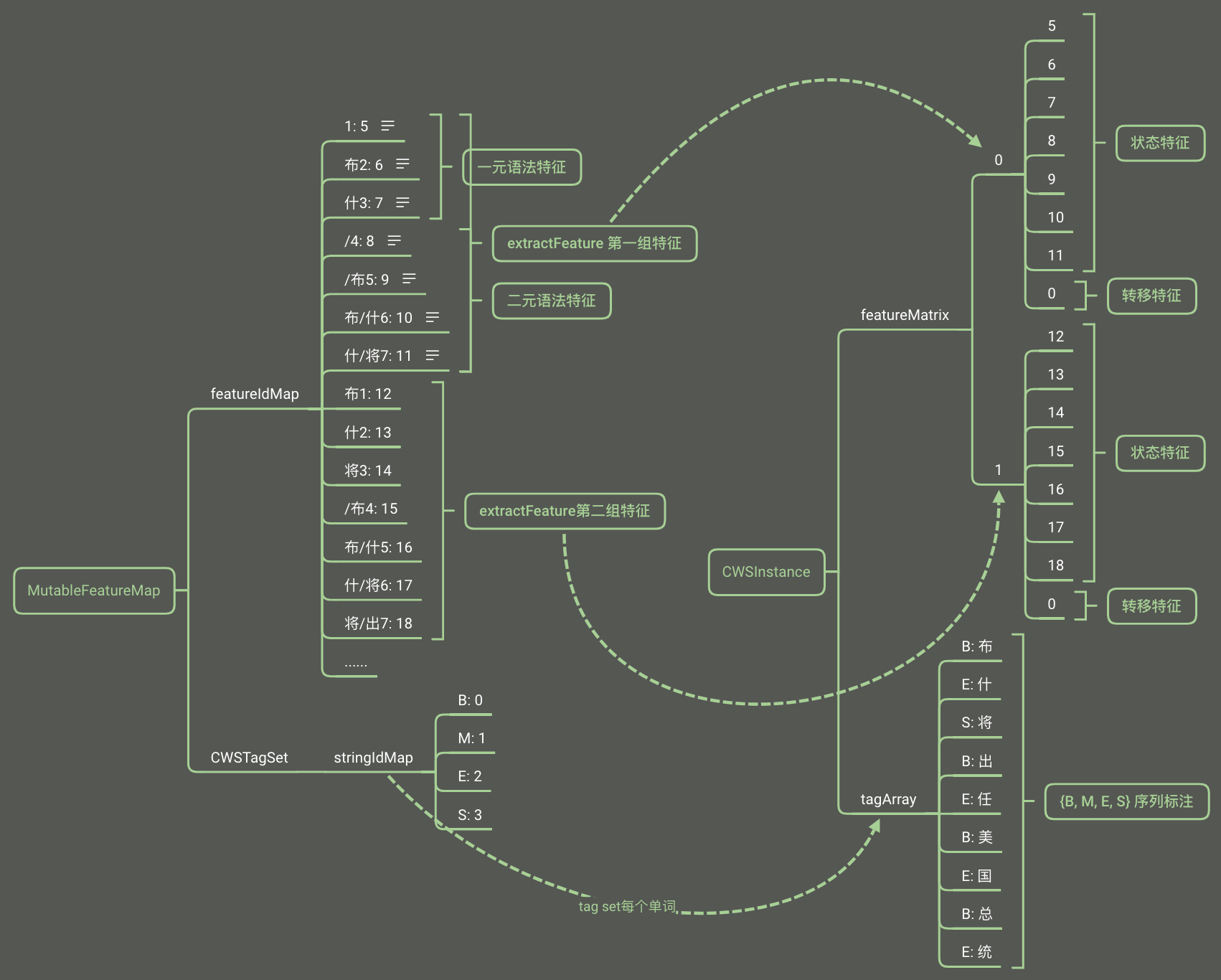
score方法,参数表大小:,可以表示每个特征在每个标签下的权重
/**
* 通过命中的特征函数计算得分
*
* @param featureVector 压缩形式的特征id构成的特征向量
* @param currentTag 当前标签 {B, M, E, S} 之一
* @return 从特性+前一标签 转移到 当前标签的分数
*/
public double score(int[] featureVector, int currentTag) {
double score = 0;
// 遍历extraxtFeature提取的特征(一元+二元语法特征)
for (int index : featureVector) {
// 获取对应的参数下标
index = index * featureMap.tagSet.size() + currentTag;
// 其实就是特征权重的累加
score += parameter[index];
}
return score;
}
特性的参数值
| 特性\状态 | B | M | E | S |
|---|---|---|---|---|
| 特性1 | ||||
| 特性2 | ||||
| 特性N |
示例,第一组训练,“布什将出任美国总统”
如单词“什“性组(特性字符串:索引),标注是B(2),初始预测标签是B(0)
| 单词\特性 | 预测标签 |
|||||||
|---|---|---|---|---|---|---|---|---|
| 布 | 1: 5 | 布2: 6 | 什3: 7 | /4: 8 | /布5: 9 | 布/什6: 10 | 什/将7: 11 | BOS |
| 什 | 布1: 12 | 什2: 13 | 将3: 14 | /布4: 15 | 布/什5: 16 | 什/将6: 17 | 将/出7: 18 | S |
| 将 | 什1: 19 | 将2: 20 | 出3: 21 | 布/什4: 22 | 什/将5: 23 | 将/出6: 24 | 出/任7: 25 | S |
| 出 | 将1: 26 | 出2: 27 | 任3: 28 | 什/将4: 29 | 将/出30: 30 | 出/任6: 31 | 任/美7: 32 | S |
| 任 | 出1: 33 | 任2: 34 | 美3: 35 | 将/出4: 36 | 出/任5: 37 | 任/美6: 38 | 美/国7: 39 | S |
| 美 | 任1: 40 | 美2: 41 | 国3: 42 | 出/任4: 43 | 任/美5: 44 | 美/国6: 45 | 国/总7: 46 | S |
| 国 | 美1: 47 | 国2: 48 | 总3: 49 | 任/美4: 50 | 美/国5: 51 | 国/总6: 52 | 总/统7: 53 | S |
| 总 | 国1: 54 | 总2: 55 | 统3: 56 | 美/国4: 57 | 国/总5: 58 | 总/统6: 59 | 统/27: 60 | S |
| 统 | 总1: 61 | 统2: 62 | 3: 63 | 国/总4: 64 | 总/统5: 65 | 统/ 6: 66 | /7: 67 | S |
训练
- 状态转移概率计算
/**
* 维特比解码
*
* @param instance 实例
* @param guessLabel 输出标签
* @return
*/
public double viterbiDecode(Instance instance, int[] guessLabel) {
final int[] allLabel = featureMap.allLabels();
final int bos = featureMap.bosTag();
final int sentenceLength = instance.tagArray.length;
final int labelSize = allLabel.length;
// 前驱数组 字符长度(单词数) * 标签数 矩阵
int[][] preMatrix = new int[sentenceLength][labelSize];
// 分数数组
double[][] scoreMatrix = new double[2][labelSize];
// 遍历句子的每个单词的特性(一个单词对应七个特性)
for (int i = 0; i < sentenceLength; i++) {
int _i = i & 1;
// 滚动数组,节省存储空间,保存当前跟前一两个状态即可
int _i_1 = 1 - _i;
int[] allFeature = instance.getFeatureAt(i);
final int transitionFeatureIndex = allFeature.length - 1;
// 第一步:初始状态概率矩阵计算
if (0 == i) {
// 第一个元素的虚拟标签BOS
allFeature[transitionFeatureIndex] = bos;
// 遍历标签 {B, M, E, S}
for (int j = 0; j < allLabel.length; j++) {
// 初始前驱矩阵,便于维比特回溯使用
preMatrix[0][j] = j;
// 从BOS标签转移到当前标签的分数
double score = score(allFeature, j);
// 预测标签矩阵
scoreMatrix[0][j] = score;
}
} else {
// 第二步 状态转移矩阵计算,找出新的局部最优路径
// 遍历标签
for (int curLabel = 0; curLabel < allLabel.length; curLabel++) {
double maxScore = Integer.MIN_VALUE;
// 遍历前一标签
for (int preLabel = 0; preLabel < allLabel.length; preLabel++) {
allFeature[transitionFeatureIndex] = preLabel;
// 计算当前特性+前一标签 转移到 当前标签分数
double score = score(allFeature, curLabel);
// 当前分数 = 前一标签分数 + 前一标签转移到当前标签的分数
double curScore = scoreMatrix[_i_1][preLabel] + score;
// 找出局部最优解
if (maxScore < curScore) {
maxScore = curScore;
// 更新前驱矩阵
preMatrix[i][curLabel] = preLabel;
// 更新前一状态的最大分数
scoreMatrix[_i][curLabel] = maxScore;
}
}
}
}
}
// 查找备选路径的最大分数以及其对应的最后状态的下标
int maxIndex = 0;
double maxScore = scoreMatrix[(sentenceLength - 1) & 1][0];
for (int index = 1; index < allLabel.length; index++) {
if (maxScore < scoreMatrix[(sentenceLength - 1) & 1][index]) {
maxIndex = index;
maxScore = scoreMatrix[(sentenceLength - 1) & 1][index];
}
}
// 根据最优路径下标回溯,复原最优路径
for (int i = sentenceLength - 1; i >= 0; --i) {
// 回溯得到最优标签序列
guessLabel[i] = allLabel[maxIndex];
maxIndex = preMatrix[i][maxIndex];
}
return maxScore;
}
单词“什”(标签编码E: 2) 预测与答案
其中
| 预测\特性 | 预测标签 |
|||||||
|---|---|---|---|---|---|---|---|---|
| 维比特预测下标 | 48 | 52 | 56 | 60 | 64 | 68 | 72 | 0 |
| 标注答案下标 | 50 | 54 | 58 | 62 | 66 | 70 | 74 | 2 |
如果预测与标注不一致,则会惩罚预测错误的下标的参数,奖励标注答案标签对应的参数
- 更新参数
/**
* 在线学习
*
* @param instance 样本
*/
public void update(Instance instance) {
int[] guessLabel = new int[instance.length()];
viterbiDecode(instance, guessLabel);
TagSet tagSet = featureMap.tagSet;
// 遍历话术每个单词的特性
for (int i = 0; i < instance.length(); i++) {
int[] featureVector = instance.getFeatureAt(i);
// 根据答案应当被激活的特征
int[] goldFeature = new int[featureVector.length];
// 实际预测时激活的特征
int[] predFeature = new int[featureVector.length];
// 遍历每个特性,更新标注和预测索引
for (int j = 0; j < featureVector.length - 1; j++) {
// 标注答案
goldFeature[j] = featureVector[j] * tagSet.size() + instance.tagArray[i];
// 预测
predFeature[j] = featureVector[j] * tagSet.size() + guessLabel[i];
}
// 设置初始状态BOS
goldFeature[featureVector.length - 1] = (i == 0 ? tagSet.bosId() : instance.tagArray[i - 1]) * tagSet.size() + instance.tagArray[i];
predFeature[featureVector.length - 1] = (i == 0 ? tagSet.bosId() : guessLabel[i - 1]) * tagSet.size() + guessLabel[i];
// 更新模型
update(goldFeature, predFeature);
}
}
/**
* 根据答案和预测更新参数
*
* @param goldIndex 答案的特征函数(非压缩形式)
* @param predictIndex 预测的特征函数(非压缩形式)
*/
public void update(int[] goldIndex, int[] predictIndex) {
for (int i = 0; i < goldIndex.length; ++i) {
if (goldIndex[i] == predictIndex[i]) {
// 与标注答案一致,无需更新参数
continue;
} else {
// 预测与答案不一致
// 奖励正确的特征函数(将它的权值加一)
parameter[goldIndex[i]]++;
// 惩罚招致错误的特征函数(将它的权值减一)
parameter[predictIndex[i]]--;
}
}
}
训练分词
public void segment(String text, Instance instance, List<String> output) {
int[] tagArray = instance.tagArray;
// 通过维比特算法得到预测标签
model.viterbiDecode(instance, tagArray);
StringBuilder result = new StringBuilder();
result.append(text.charAt(0));
// 通过标签,反向拼接处分词
for (int i = 1; i < tagArray.length; i++) {
if (tagArray[i] == CWSTagSet.B || tagArray[i] == CWSTagSet.S) {
// 当前字符为{B, S},得到上一个分词结果
output.add(result.toString());
result.setLength(0);
}
result.append(text.charAt(i));
}
if (result.length() != 0) {
output.add(result.toString());
}
}
