

IEEE Transactions on Multimedia 2019
Chongyi Li, Chunle Guo, Jichang Guo, Ping Han, Huazhu Fu, Senior Member, IEEE, and Runmin Cong Member, IEEE
简介
文章提出了PDR-net,其包含两个子网络,分别为Haze Removal子网和Refinement子网。Haze Removal子网负责对输入的有雾图像进行去雾,而Refinement子网负责对去雾结果进一步细化,以提高其对比度和饱和度等。由于文章认为室内RGB-D数据集合成的去雾数据会使网络产生低对比度和单调色彩的结果,室外数据能够弥补这个问题,以及室外去雾数据集雾浓度变化较小,不利于网络去不同浓度的雾,室内数据集可以弥补这个缺点,因此该网络的训练使用了室内室外两个数据集,分别利用了其优点。文章使用了多个损失函数,包括感知损失(VGG)、颜色损失、对抗损失等。
问题
文章认为以往的文章存在以下问题:
- 估计大气散射模型中的A和t后,合并这些变量会放大估计步骤中的误差。
- 使用室内RGB-D数据集合成的训练数据会使网络产生低对比度和单调色彩的结果。
- 室外有雾数据集的雾浓度较低,限制了去雾网络在浓雾上的去雾能力。
网络框架
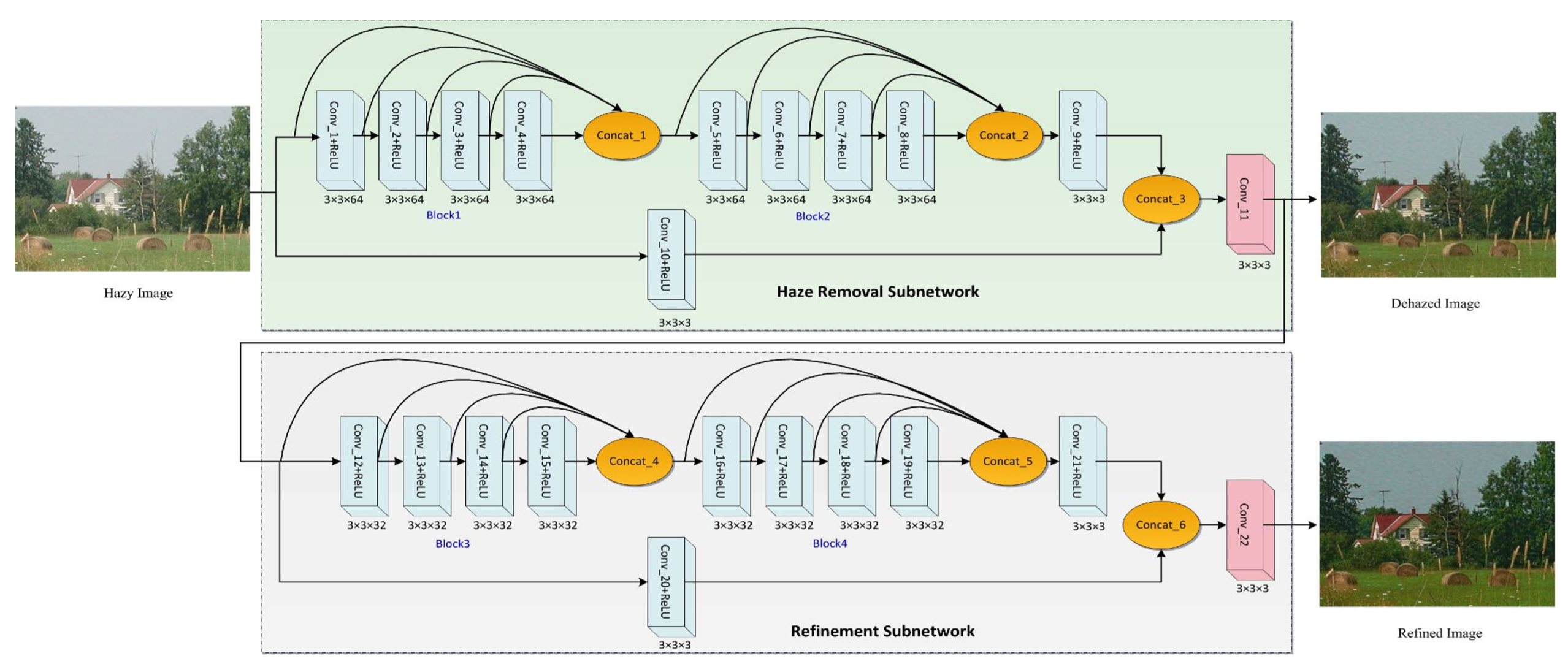
其中Conv_10+ReLU模块是为了应对有雾图像直接传输到输出结果处而导致去雾结果存在噪声和伪像。
整个网络包含22个卷积层,即认为其使一个轻量级的CNN。此外,为了减少边界伪像,文章不使用任何池化层,卷积为0填充。
损失函数
文章在两个子网中使用了三种不同的损失。perceptual loss(感知损失)、color loss(颜色损失)、contrast loss(对比度损失)。其中去雾子网仅使用感知损失。
perceptual loss(感知损失)
感知损失在去雾子网和细化子网中均使用到。 先介绍在去雾子网中的感知损失:
其中表示使用Imagenet预训练的VGG19网络,
表示第
层卷积层(在ReLU层后),
和
分别表示表示去雾结果和Ground Truth,
、
、
表示通道数、高、宽,
表示批大小。
在细化子网中的公式相同,只有和
变为去雾结果图(中间结果)和细化目标图。
color loss(颜色损失)
颜色损失仅在细化子网中使用。颜色损失使用了2D高斯核对输出细化结果图和目标细化图进行模糊,并求取它们的损失。
和
表示输出细化结果图和目标细化图的模糊结果。
contrast loss(对比度损失)
将输出细化结果图和目标细化图转为灰度图,文章表示,这样可以让鉴别器网络()关注对比度而不是颜色信息。
同样的,和
使细化结果图和目标细化图的灰度图。生成器
(细化子网)负责生成细化结果,使
尽可能的与
相似,而鉴别器
负责区分
和
。另外,鉴别器
的网络结构在文章中未展示。
综上所述,总损失函数如下:
其中,
,
表示权重,分别为10,0.5,1。
数据集和训练
室内图像数据集使用了NYU-V2数据集,根据大气散射模型合成有雾图像。其中,
。 将NYU-V2数据集分为1000张(训练集)和449张(验证和测试集),对于每张照片随机选择
和
各五个,生成5张有雾图像,一共得到5000张(训练集)和449张(验证测试集)。文章还将图像缩小到207×154×3。
室外图像数据集使用了RESIDE下的SOTS数据集,其包含500张户外图像,将其分为400张(训练集)和100张(验证测试集),并将其不重叠的裁剪为100×100×3的尺寸,最终得到8000张(训练集)和1000张(验证测试集)。
NYU-V2数据集用于训练去雾子网,SOTS数据集用于训练细化子网。具体的说,NYU-V2数据集合成的有雾图作为Hazy Image输入到Haze Removal Subnetwork中,其得到结果Dehazed Image与NYU-V2数据集的Ground Truth计算损失。SOTS数据集也作为Hazy Image输入到Haze Removel Subnetwork中,得到Dehazed Image,但这一步不参与训练,再将Dehazed Image输入到Refinement Subnetwork中得到细化后的最终结果,并与SOTS数据集的Ground Truth计算损失。
其他设置
- 除雾子网batch size=16
- 细化子网batch size=64
- 感知损失计算VGG19的ReLU5_4层
- 高斯模糊卷积核的幅值、均值、方差分别设为0.053、0、1
结果展示和对比

文章使用前文提到的验证测试集进行测试,测试集1为NYU数据集中的测试集,测试集2为SOTS数据集中的测试集。测试指标为PSNR和SSIM。
测试集1测试结果
| Metrics | DCP | CAP | DehazeNet | MSCNN | All-in-One | ProximalNet | cGAN-based | PDR-Net |
|---|---|---|---|---|---|---|---|---|
| PSNR | 16.71 | 16.38 | 17.35 | 16.66 | 16.83 | 17.03 | 17.79 | 17.89 |
| SSIM | 0.7813 | 0.7622 | 0.7812 | 0.7755 | 0.7829 | 0.7711 | 0.7993 | 0.8227 |
测试集2测试结果
| Metrics | DCP | CAP | DehazeNet | MSCNN | All-in-One | ProximalNet | cGAN-based | PDR-Net |
|---|---|---|---|---|---|---|---|---|
| PSNR | 17.34 | 22.08 | 22.62 | 19.47 | 20.47 | 19.16 | 22.01 | 21.70 |
| SSIM | 0.7359 | 0.8812 | 0.8677 | 0.8381 | 0.9121 | 0.8515 | 0.8477 | 0.8847 |
文章认为,其获得最佳评分的原因是:
- 除雾子网将重建损失降到最低,从而产生更好的逐像素相似性(即PSNR)
- 改进子网进一步提高了对比度和细节,从而产生更好的结构相似性(即SSIM)
室外真实场景测试图像

室内合成场景测试图像

对比研究
文章重新使用了和
损失来研究,得到以下图与表:

| Loss | PSNR (dB) | SSIM |
|---|---|---|
| PD-Net1 | 21.47 | 0.7013 |
| PD-Net2 | 19.72 | 0.6579 |
| PD-Net | 18.09 | 0.7997 |
文章表示,会惩罚较大的错误,但是它更能够容忍较小的错误。而
不会惩罚大错误,也会优化小错误。相比之下,感知损失鼓励输出在感知上更加愉悦的输出而适当牺牲了PSNR。其在实验上证明了感知损失的有效性。
