

概述:和StringBuilder特性差不多,动态长度,可以放不同类型
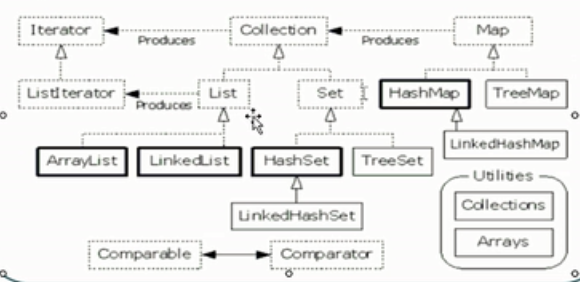
最顶层:Collection接口,下面两个 List和 Set接口,下面有着自己的实现类
集合里面存储对象在内存里面是以地址值的方式来进行的。
ArrayList 增删判断查(好像没有改的方法)
retainAll()取交集,然后回改变原来的集合内容。
removeALL() 去掉交集。
元素的取出:
迭代器:Iterator it=数组列表对象.iterator()
LIst特点:有序,可重复,
Set特点:无序,不可重复
List的坑:
1. 迭代器不能和集合方法混着用会造成并发程序安全问题
for(iterator i=a.iterator();i.hasNext();)
{
a.remove()//这样会报错的
}
如果在迭代器当中删除了某个元素,虽然集合的引用删除了,但是内存当中还是有这个对象。你可以把obj打印出来,但是集合里面增加和删除都会对应的变化
迭代器只有三个动作:
1.删除2.判断3.下一个
ListIterator() ,Iterator 的子接口,然后方法多了很多
比如迭代器里面里面的增删改查方法,对前面元素的操作等,
List 的三个子类
1.Arraylist: 底层数组增删很慢,改查很快
2.LinkedList 底层链表改查很慢,增删很快
3.Vector:地层是数组
1和3的区别:1不同步,效率高,1.2版本后出现,初始大小都是10,1增加之后比较节约空间
查找很慢,修改很快
linkedList 特有方法: 最前最后的元素的增加,获取,删除
removeFirst()删除元素,可以返回被删除的元素,get()只是返回,不删除(get对应不会报错的方法,peekFirst(),获取但是不返回也不报错的那种)
这个的增强方法,popFirst(),返回并且删除,但是如果为空的话就不会报错只会返回为空
判断集合总是否包含集合,可以用COntains方法。
判断元素是否相同。重写equals方法
contains 和 remove方法底层会自动调用equals()方法。
Set这一类:
Set功能和Collection功能差不多,取出也是用的迭代器。无序,不重复
子类:
- HashSet
- TreeSet
HashSet类别,底层是Hash表,先判断容器类不的对象的Hash值是否相同,不相同的话就找个位置重新放下。相同的话需要在用euqals方法判断是否是同一个对象。
判断是否存在和remove()依赖于 Hashcode() 在依赖 contains()方法
TreeSet;类别:增删改查4
特点:可以对Set里面进行排序
测试,自定义的。
Camparable接口:实现这个类可以使自定义类具有比较的功能。重写compareTo()方法(注返回值为0的话,则说明是同一对象,存不进去)
第二种排序方式:当元素不具有或者具备的比较性不适用,可以让集合自身具有比较性
一初始化就有比较方式,在构造函数放比较器Comparator接口
覆盖compare方法()
当两种比较方式都有的话,比较器的优先级较高
底层结构:二叉树结构。比较,删除,判断对treeSet方法来说都是依据compareTo()的方法
泛型概述:编译时期确定参数的类型,把运行时期的错误能够在编译期间解决
注意集合标注了之后,迭代器也要标注(感觉容器都需要标注出来)
像数组的框一样,在后面写个<String/其他类型>左边和右边都需要写,用来接收数据类型的。可用于容器,比较器。
Comparator接口也可以加上泛型,
class a implements Comparator<String>
{
compare(String o1,String o2)
}
euquals()没泛型,别乱写
自定义泛型类:
由调用方设定参数类型。可以放在类上,方法上,成员变量上
类的定义 上写定义,调用的时候,具体写清楚是哪个类型就可以。
泛型定义在类上,该类型的成员函数,成员变量变量类型都已经确定
方法的返回值前面不用写
泛型定义在方法上:该泛型类型只对该方法有效
格式
eg: public <T> void show <T t>
{
}
第三种类型:
泛型类上,泛型方法重置了新的泛型参数类型
静态方法不可以访问类上定义的泛型,如果静态函数的变量类型不确定,可以把变量类型定义泛型在函数上
泛型定义在接口上
interface I<T>
{
void show(T t)}
子类实现的话,可以确定参数,也可以不指定
class Interclass <T> implements I<T>
<T>把T换成?表示通配符,表示可以传任意一种对象,但是不能够将这个对象赋值给某一变量(<?>T= i<T>.next()),也不能使用特定方法。(比如.length()不确定某个参数会不会有该方法)
继承当中的泛型:
原函数假如定义 <People>类型的函数,你传一<Student>类型的参数进去,容器都不匹配,肯定不行呀。理解就是这里不能适用于多态形式
《? extends Person》泛型限定,接受Person及其子类
泛型的通配符:? 未知类型。
泛型的限定: ? extends E: 接收E类型或者E的子类型对象。
上限 一般存储对象的时候用。比如 添加元素 addAll. ? super E: 接收E类型或者E的父类型对象。
下限。 一般取出对象的时候用。比如比较器。
问题:class,接口什么时候可以不用写泛型
eg: Map.Entry<String,String> me=i.next(); 感觉之前Iterator<Map.Entry<String,String>都写了,取出来应该不用了吧。 不写又报错,头皮发麻
Map集合 特点,没有迭代器
Map<K,V>接口
Map:一次添加一对元素。Collection 一次添加一个元素。 Map也称为双列集合,Collection集合称为单列集合。 其实map集合中存储的就是键值对。 map集合中必须保证键的唯一性。 常用方法: 1,添加 put2.删除3.判断4.获取
1,添加。 value put(key,value):返回前一个和key关联的值,如果没有返回null. 对于同一个键。后添加的值会覆盖前一个的值,并且返回前一个结果的值
2,删除。 186 void clear():清空map集合。 value remove(key):根据指定的key翻出这个键值对。
3,判断。
boolean containsKey(key):
boolean containsValue(value):
boolean isEmpty();
4,获取。
value get(key):通过键获取值,如果没有该键返回null。
当然可以通过返回null,来判断是否包含指定键。
int size(): 获取键值对的个数。
一次性获取所有元素的方法:
1.使用KeySet()方法,将Map所有键存入Set集合中,因为他有迭代器。再迭代用get()取出
2. entrySet()方法,存放关系到Set集合里面(Key-value),Map.Entry表示这种关系的数据类型是Map.Entry(步骤,获取装Map.Entry的Set集合,用迭代器,得到Map.Entry,循环里面获得键和值(getKey,和getValue()获取键和值))
Set<Map.Entry>
Map.Entry的方法,获取键,获取值(其实Entry是Map接口的子接口)
类比:结婚证书,而不是丈夫和妻子单独列出来
Map常用的子类:
|--Hashtable :内部结构是哈希表,是同步的。不允许null作为键,null作为值。无序的
|--Properties:用来存储键值对型的配置文件的信息,可以和IO技术相结合。
|--HashMap : 内部结构是哈希表,不是同步的。允许null作为键,null作为值效率高。
|--TreeMap : 内部结构是二叉树,不是同步的。可以对Map集合中的键进行排序。
Set底层是就是使用了Map
remove(key)删除会吧对应的value返回
values() 返回集合类型。Collections
自定义类的创建,
1.需要重写hashCode和equals()方法(对于HashSet和HashMap),这样能够去除掉重复元素,产生的Item很多的话,最好再重写compareTo()
Collections的辅助方法:
集合操作,大多数是Static,可以对
例如,sort(),可对List进行排序
如果对于没有排序规则的集合,可以自定义完比较器之后再去把比较器作为参数传入静态方法里面()
fill(List,"pp")方法,将集合中的所有元素替换成指定元素
replaceAll(list,老值,新值)
reverse(list)反转
Collections.reverseOrder()返回目前比较器的反序列比较器,这里没有参数;如果是自定义比较器,可以把自定义比较器放在这个参数里面。
可以返回线程同步的集合。
swap(list,1,2)一和二位置置换
shuffel(list)随机打乱
集合的Arrays,用于操作数组进行操作的工具类
静态类 toString(),把数组变成字符串
asList() 把数组变成List集合
数组变集合的特点:
1.集合方法操作数组元素,比如contains()方法。
2.变成集合之后,不能增删,增删会报异常
3.* 如果数组中的元素是对象,那么转成集合时,直接将数组中的元素作为集合中的元素进行集合存储。 * * 如果数组中的元素是基本类型数值,那么会将该数组作为集合中的元素进行存储。
集合变数组: 各个集合类的toArray(里面放需要类型的数组(数组大小太小的话会重新分配,太大的话会多的null,最好放一个list.size()空间分配最优))方法
Collections.toArray()方法
List list = new ArrayList();
list.add("abc1");
list.add("abc2");
list.add("abc3");
/* * toArray方法需要传入一个指定类型的数组。
* 长度该如何定义呢? * 如果长度小于集合的size,那么该方法会创建一个同类型并和集合相同size的数组。
* 如果长度大于集合的size,那么该方法就会使用指定的数组,存储集合中的元素,其他位置默认为 * null。
* 所以建议,最后长度就指定为,集合的size。
*/
String[] arr = list.toArray(new String[list.size()]);
System.out.println(Arrays.toString(arr));
为何集合要变数组的原因:
1.限定对元素的操作,数组的长度固定,不需增删
增强的for循环:
foreach语句: * 格式: * for(类型 变量 :Collection集合|数组) (其中,类型表示的是容器里面元素的类型)
支持迭代器的操作都支持高级for循环
* { * * } * * 传统for和高级for的区别?
* 传统for可以完成对语句执行很多次,因为可以定义控制循环的增量和条件。
* * 高级for是一种简化形式。
* 它必须有被遍历的目标。该目标要是数组,要么是Collection单列集合。
* 对数数组的遍历如果仅仅是获取数组中的元素,可以使用高级for。
如果要对数组的角标进行操作建议使用传统for。
list.add("abc1");
list.add("abc2");
list.add("abc3");
for(String s : list)
{
//简化书写。 System.out.println(s);
}
局限性:只能对集合中的元素进行取出,不能修改,因为变量只是表示的一种引用,指向虽然变了,但是集合中的元素没有发生变化。迭代器除了遍历还有remove集合中的元素,如果用listIterator().还能对集合进行增删功能
静态导入:
import static java.util.Collections.*;//静态导入,其实到入的是类中的静态成员。
//import static java.util.Collections.max;//静态导入,其实到入的是类中的静态成员。
