ssl/tls 安全协议
www.ruanyifeng.com/blog/2014/0…
浏览器性能优化
html:语义化 浏览器缓存· 样式表放在头部(防止“白屏”),脚本放在底部(减少页面首屏出现的时) 使用外部的JavaScript和CSS(文件缓存,html 文件变小) 精简js (webpack) 减少DNS查找 当客户端DNS缓存(浏览器和操作系统)缓存为空时,DNS查找的数量与要加载的Web页面中唯一主机名的数量相同,包括页面URL、脚本、样式表、图片、Flash对象等的主机名。减少主机名的 数量就可以减少DNS查找的数量。 减少唯一主机名的数量会潜在减少页面中并行下载的数量(HTTP 1.1规范建议从每个主机名并行下载两个组件,但实际上可以多个),这样减少主机名和并行下载的方案会产生矛盾,需要大家自己权衡。建议将组件放到至少两个但不多于4个主机名下,减少DNS查找的同时也允许高度并行下载。
压缩组件 从HTTP1.1开始,Web客户端可以通过HTTP请求中的Accept-Encoding头来表示对压缩的支持 Accept-Encoding: gzip,deflate 如果Web服务器看到请求中有这个头,就会使用客户端列出来的方法中的一种来进行压缩。Web服务器通过响应中的Content-Encoding来通知 Web客户端。 Content-Encoding: gzip
代理缓存 当浏览器通过代理来发送请求时,情况会不一样。假设针对某个URL发送到代理的第一个请求来自于一个不支持gzip的浏览器。这是代理的第一个请求,缓存为空。代理将请求转发给服务器。此时响应是未压缩的,代理缓存同时发送给浏览器。现在,假设到达代理的请求是同一个url,来自于一个支持gzip的浏览器。代理会使用缓存中未压缩的内容进行响应,从而失去了压缩的机会。相反,如果第一个浏览器支持gzip,第二个不支持,你们代理缓存中的压缩版本将会提供给后续的浏览器,而不管它们是否支持gzip。 解决办法:在web服务器的响应中添加vary头Web服务器可以告诉代理根据一个或多个请求头来改变缓存的响应。因为压缩的决定是基于Accept-Encoding请求头的,因此需要在vary响应头中包含Accept-Encoding。 vary: Accept-Encoding
浏览器的地址栏输入网址
www.cnblogs.com/MarcoHan/p/… 输入地址 —>> 域名解析 —>> 发起TCP三次握手 —>> 建立TCP连接后发起http请求 —>> 服务器响应http请求,浏览器得到html代码 —>> 浏览器解析html代码,并请求代码中的资源(js, css, 图片等) —>> 浏览器进行渲染给呈现给用户 域名解析 --> 浏览器自身的DNS缓存 --> 操作系统自身的DNS缓存 --> 读取hosts文件 --> 本地域名服务器(DNS高速缓存) -- 根域名服务器 -- com服务器 -- baidu.com服务器
tcp连接
(baijiahao.baidu.com/s?id=161811…
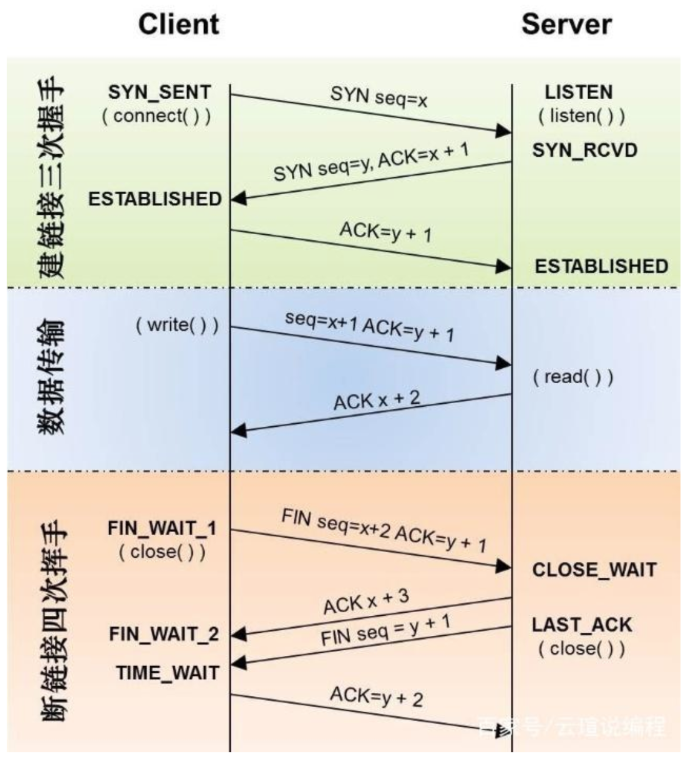
三次握手
(seq序号 -- sequence, ack确认号 -- acknowledge): 客户度发送:seq=x 服务端发送:seq=y,ack=x+1 客户端发送:ack=y+1
tcp连接后可发起数据请求 客户度发送:seq=x+1,ack=y+1 服务端发送:ack=x+2 tcp作用:快速重传,超时重传,流量控制,阻塞控制
四次挥手(关闭tcp连接)
GET与POST请求区别
http状态码
https://www.cnblogs.com/xflonga/p/9368993.html
1xx:通知
100:Continue 客户端应重新发送初始请求
2xx:成功
200:OK
201:created 当服务器依照客户端的请求创建了一个新资源时,发送此响应代码
204:No Content 服务器拒绝对PUT、POST或者DELETE请求返回任何状态信息或表示
3xx:重定向
301:永久重定向
302:暂时重定向
304:用于有主体数据,但客户端已拥有该数据,没必要重复发送的情况
305:使用代理,不能直接访问网站,需要通过某个代理,比如访问外网需要VPN
4xx:客户端错误
400:Bad Request 请求无效,服务器无法理解用户的请求,除非进行修改
401:Unauthorized 客户端试图对一个受保护的资源进行操作,却又没有提供正确的
认证证书
403:Forbidden
禁止访问,服务器拒绝了你的地址请求,可能你没权限访问,
被禁止访问,无法自行解决
404:Not Found 无法找到文件,网页不存在
405:Method Not Allowd 客户端试图使用一个本资源不支持的HTTP方法(get,post),
资源被禁止,可能是文件目录权限不够
408:请求超时,意味着你请求发送到该网站的时间比服务器准备等待的时间要长
5xx:服务端错误
500:Internal Server Error 服务器错误响应
502:Bad Gateway 只有HTTP代理会发送这个响应代码。它表明代理方面出现问题
503:Service Unavailable HTTP服务器正常,只是下层web服务服务不能正常工作。
最可能的原因是资源不足
get,post,put,delete,options
只是一个规范,options是预检调用
https
HTTPS与HTTP的一些区别
HTTPS协议需要到CA申请证书,一般免费证书很少,需要交费。
HTTP协议运行在TCP之上,所有传输的内容都是明文,HTTPS运行在SSL/TLS之上,SSL/TLS运行在TCP之上,所有传输的内容都经过加密的。
HTTP和HTTPS使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
HTTPS可以有效的防止运营商劫持,解决了防劫持的一个大问题。
http1.0 http1.1 http2.0 对比
-
HTTP1.0、HTTP1.1
(1) If-Modified-Since,Expires来做为缓存判断的标准
(2) 加入更多入Entity tag,If-Unmodified-Since, If-Match, If-None-Match
(1) 浪费带宽
(2) range断点续传
(2) 新增了24个错误状态响应码
(1) 每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名
(2) 一台物理服务器上可以存在多个虚拟主机,支持Host头域
(1) 每次请求需要重新连接
(2) 长连接(PersistentConnection)和请求的流水线(Pipelining)处理,Connection: keep-alive
-
HTTP2.0:
降低延迟(多路复用),请求优先级
header压缩(HTTP2.0可以维护一个字典,差量更新HTTP头部,大大降低因头部传输产生的流量)
基于HTTPS的加密协议传输,服务器推送(Nginx或Apache配置,请求link带参)
WebSocket
- 以前的方式:
(1)不管数据有没有变化,客户端轮询服务器 -- 短轮询
(2)客户端请求服务器,服务器挂起有变更返回 -- 长轮询
缺点:(1)浪费资源,不够实时。(2)浪费资源
WebSocket
可以做到全双工通信
ws = new WebSocket('ws://localhost:9000');
请求头:
// 与响应头 Sec-WebSocket-Accept 相对应
Sec-WebSocket-Key: 5fTJ1LTuh3RKjSJxydyifQ==
Sec-WebSocket-Version: 13 // 表示 websocket 协议的版本
Upgrade: websocket // 表示要升级到 websocket 协议
响应头:
Connection: Upgrade
Sec-WebSocket-Accept: ZUip34t+bCjhkvxxwhmdEOyx9hE=
Upgrade: websocket
响应行(General)中可以看到状态码 status code 是 101 Switching Protocols , 表示该连接已经从 HTTP 协议转换为 WebSocket 通信协议。
浏览器缓存机制(简易版)
控制浏览器是读取缓存数据还是重新请求:
Expires(HTTP 1.0)当前资源的有效期
eg: Expires: Fri, 18 Mar 2016 07:41:53 GMT
Cache-Control(HTTP 1.1)
设置max_age,指定组件被缓存多久.
eg: Cache-Control: max-age=12345600
同时制定Cache-Control和Expires,则max-age将覆盖Expires头
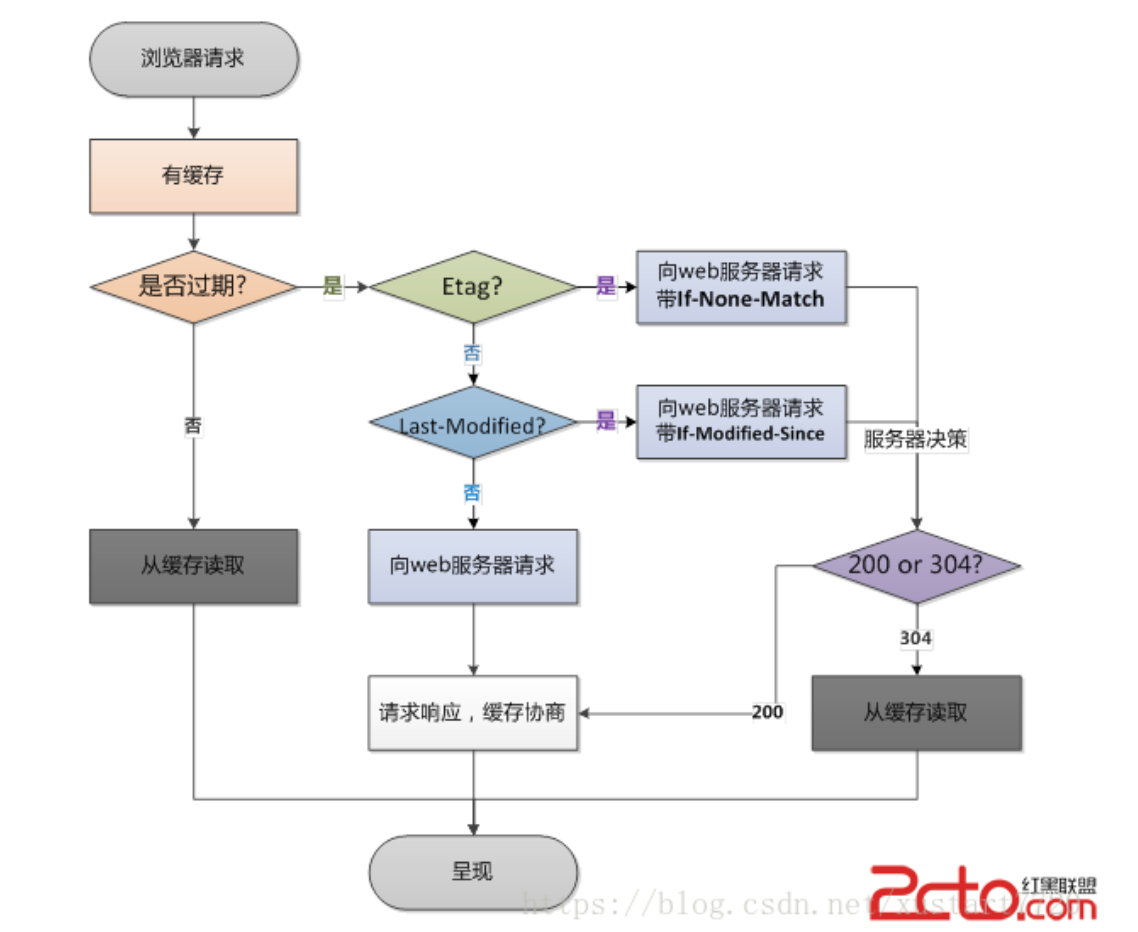
如果Cache-Control / Expires没过期就用缓存,
如果过期了,发现有Last-Modified(响应资源最后修改时间)
get请求加上If-Modified-Since(Get方法)(本地存储文件修改时间--即第一次服务器返回时间),
和被请求资源的最后修改时间对比,
一致就返回内容空,状态304,继续使用本地的,时间不一致返回新文件,状态200
非get请求加If-Unmodified-Since,如果实体在指定时间后,没有任何修改,那么就可以直接执行该请求使用方法的对应行为. 而如果有修改,则返回一个412 Precondition Failed状态码,并且抛弃该方法对应的行为操作(GET方法除外).
Etag(服务器返回)/If-None-Match(客户端请求)
解决一些Last-Modified/If-Modified-Since所不能解决的问题
比如:
1. Last-Modified标注的最后修改只能精确到秒级,
如果某些文件在1秒钟以内,被修改多次的话,它将不能准确标注文件的修改时间
2. 如果某些文件会被定期生成,当有时内容并没有任何变化,
但Last-Modified却改变了,导致文件没法使用缓存
3. 有可能存在服务器没有准确获取文件修改时间,
或者与代理服务器时间不一致等情形
Etag:当前资源在服务器的唯一标识
Last-Modified与ETag是可以一起使用的,服务器会优先验证ETag,
一致的情况下,才会继续比对Last-Modified,最后才决定是否返回304。
ETag带来的问题
ETag的问题在于通常使用某些属性来构造它,有些属性对于特定的部署了网站的服务器来说是唯一的。
当使用集群服务器的时候,浏览器从一台服务器上获取了原始组件,之后又向另外一台不同的服务器发起条件GET请求,ETag就会出现不匹配的状况。
例如:使用inode-size-timestamp来生成ETag,文件系统使用inode存储文件类型、所有者、组和访问模式等信息,在多台服务器上,就算文件大小、权限、时间戳等都相同,inode也是不同的。
最佳实践
1. 如果使用Last-Modified不会出现任何问题,
可以直接移除ETag,google的搜索首页则没有使用ETag。
2. 确定要使用ETag,在配置ETag的值的时候,
移除可能影响到组件集群服务器验证的属性,
例如使用size-timestamp来生成时间戳。
web缓存相关标头(详细版)
https://www.cnblogs.com/zhoulujun/p/9071277.html
https://www.cnblogs.com/_franky/archive/2011/11/23/2260109.html
Expires (实体标头,HTTP 1.0+)
一个GMT时间,试图告知客户端,在此日期内,可以信任并使用对应缓存中的副本,缺点是,一但客户端日期不准确.则可能导致失效.
Pragma : no-cache(常规标头,http1.0+)
对Pragma定义的唯一的伪指令,同http1.1的Cache-Control : no-cache
优先级从高到低是 Pragma -> Cache-Control -> Expires
Last-Modified(实体标头,HTTP1.0+)
一个GMT时间,告知,被请求实体的最后修改时间.用于客户端校验其缓存副本是否仍然可以信任.与其相关的两个条件请求标头:
If-Modified-Since:(此标头,仅对Get方法有意义)
如果实体在指定时间后,没有修改则返回一个304,否则返回一个常规的Get请求的响应(比如200).
另外,如果该标头的值是一个非法的值,那么也同样返回一个常规的Get请求的响应.
PS: 用户代理发起 If-Modified-Since尝试握手的条件,可能会有不同,比如IE系,如果该实体第一次响应头中包含Cache-Control:no-cache.则 IE不会使用If-Modified-Since请求资源.而其他浏览器则会. 但是如果使用Cache-Control:no-store.则所有用户代理的表现一致.都不使用If-Modified-Since(因为no-store的语义十分强烈.不允许任何缓存,这个在后续有专门介绍.)
If-Unmodified-Since:(GET方法除外)
如果实体在指定时间后,没有任何修改,那么就可以直接执行该请求使用方法的对应行为.
而如果有修改,则返回一个412 Precondition Failed状态码,并且抛弃该方法对应的行为操作.
Cache-Control : (常规标头,HTTP1.1)
public: (仅为响应标头)
响应:告知任何途径的缓存者,可以无条件的缓存该响应.
private: (仅为响应标头)
响应:告知缓存者
(据我所知,是指用户代理,常见浏览器的本地缓存.用户也是指,系统用户.但也许,不应排除,某些网关,可以识别每个终端用户的情况),
只针对单个用户缓存响应.且可以具体指定某个字段.
如private–“username”,则响应头中,名为username的标头内容,不会被共享缓存.
no-cache:
请求: 告知缓存者,必须原原本本的转发原始请求,并告知任何缓存者,别直接拿你缓存的副本,糊弄人.你需要去转发我的请求,并验证你的缓存(如果有的话).对应名词:端对端重载.
响应: 允许缓存者缓存副本.那么其实际价值是,总是强制缓存者,校验缓存的新鲜度.一旦确认新鲜,则可以使用缓存副本作为响应. no-cache,还可以指定某个包含字段,比如一个典型应用,no-cache=Set-Cookie. 这样做的结果,就是告知缓存者,对于Set-Cookie字段,你不要使用缓存内容.而是使用新滴.其他内容则可以使用缓存.
no-store:
请求:告知,请求和响应都禁止被缓存(也许是出于隐私考虑)
响应:同上.
max-age:
请求:强制响应缓存者,根据该值,校验新鲜性.即与自身的Age值,与请求时间做比较.如果超出max-age值,则强制去服务器端验证.以确保返回一个新鲜的响应.其功能本质上与传统的Expires类似,但区别在于Expires是根据某个特定日期值做比较.一但缓存者自身的时间不准确.则结果可能就是错误的.而max-age,显然无此问题. Max-age的优先级也是高于Expires的.
响应:同上类似,只不过发出方不一样.
max-stale:
请求:意思是,我允许缓存者,发送一个,过期不超过指定秒数的,陈旧的缓存.
响应:同上.
must-revalidate(仅为响应标头)
响应:意思是,如果缓存过了新鲜期,则必须重新验证.而不是试图返回一个不在新鲜期的缓存.与no-cache的区别在于,no-cache,完全无视新鲜期的概念.总是强制重新验证.理论上,must-revalidate更节省流量,但相比no-cache,可能并不总是那么精准.因为即使缓存者,认为是新鲜的,也不能保证服务器端没有做过更新.如果缓存者是一个缓存代理服务器,如果其试图重新验证时,无法连接上原始服务器,则也不允许返回一个不新鲜的,缓存中的副本.而是必须返回一个504 Gateway timeout.
proxy-revalidate(仅为响应标头)
响应:限制上与must-revalidate类似.区别在于受体的范围.proxy-revalidate,是要排除掉用户代理的缓存的.即,其规则并不应用于用户代理的本地缓存上.
min-fresh(仅为请求标头)
请求:告知缓存者,如果当前时间加上min-fresh的值,超了该缓存的过期时间.则要给我一个新的.其实个人觉得,其功能上有点和max-age类似.但是更大的是语义上的区别.
only-if-cached:(仅为请求标头)
请求:告知缓存者,我希望内容来自缓存,我并不关心被缓存响应,是否是新鲜的.
s-maxage(仅为响应标头)
响应:与max-age的唯一区别是,s-maxage仅仅应用于共享缓存.而不引用于用户代理的本地缓存,等针对单用户的缓存. 另外,s-maxage的优先级要高于max-age.
cache-extension (cache-extension是一个泛化的代称.它指所有自定义,
或者说扩展的,指令,客户端和服务器端都可以自定义扩展Cache-Control相关的指令.)
那么,实际上我们可以这样 Cache-Control:max-age=300, custom-directive = xxx, public.
这样我们就定义了一个被统称为cache-extension的扩展指令.该指令如果对应的客户端或服务器端,不认识,就会忽略掉.
扩展指令中一个常见的东西是 none-check post-check 和 pre-check.
是IE5被加入的.所以如果响应头中有这几个扩展指令,
那么IE就会认得他们, 我经常在一些 为了解决 no-cache + gzip 命中ie6 JSONP 请求,导致脚本不执行bug的方案中见到这几个扩展指令,
其目的是为了让IE放弃使用本地缓存.
我倒是觉得,对IE6放弃使用gzip,是更合理的做法.
当然缺点也很明显, 如果是cdn部署静态资源.显然这样做会很困难.
no-transform:
请求:告知代理,不要更改媒体类型,比如jpg,被你改成png.
响应:同上.
Etag : (实体标头,HTTP1.1)
通过[Mog95],( http://www.research.digital.com/wrl/publications/abstracts/95.4.html
遗憾的是,该地址,现在似乎访问不能.)生成一段可代表实体版本的字串.默认就是一段hash + 时间戳的形式.其实我们是可以使用自己的算法来生成Etag值.比如md5.
PS:Apache的默认Etag包含Inode,Mtime,Size三部分.而且Etag有强弱之分.比如一般的弱Etag,是以W/开头的,如:W/”abcde12”,这部分不是我们关注的焦点.因为弱Etag和强Etag的区别只在于算法.比如某种弱Etag关注的时间精度,为秒.而我们在项目中,最常见的做法是使用MD5.是一种忽略时间维度的,强Etag.为的是保证精确度.以及负载均衡设备的同步.除非我们的项目有特殊需求.但是往往我们可以根据需求,来调整算法.而不是沿用一些传统的弱Etag算法.
这东西,是要和客户端的两个请求标头配合使用的:
If-Match:
语义:如果有匹配,或者值为”*”,才可以能去执行,请求所使用的方法,所对应的行为.
If-Match,可以看做是一个过滤器,主要应用于资源多版本共存的解决方案.比如服务器端对同一实体,有多个版本.那么客户端,即可按照指定版本来获取实体.
If-Match的值就是对应指定版本的Etag值.这个值可以是多选的.典型的应用场景是,客户端使用put方式请求服务器端,并带有多个If-Match的值.服务器端检查所有该实体的版本.找到匹配项,就立刻更新服务器端的对应版本.如果无一匹配,则发送一个412 Precondition Failed状态码.
If-None-Match:
语义:如果有任何匹配,或值是”*”,并且原始服务器存在其请求的实体,则不允许执行该请求所使用放的对应行为,如果此时,该请求使用的get,或head方法.则返回一个304状态码.以及其他一些相关的缓存控制的标头.
与If-Match相反 .但它的典型应用,也是我们要关注的部分.支持http1.1的现代浏览器,以及web server,应用If-None-Match头用于,缓存新鲜度校验.典型应用场景就是,一但原始服务器的某个响应中包含Etag时,如果浏览器本地缓存了该实体.那么在第二次的常规的get或head请求时,就会自动带上 If-None-Match头.当原始服务器上该实体的版本对应的Etag值与之匹配时,则原始服务器会返回304状态码.然后浏览器认为本地缓存是新鲜的.则继续使用缓存的实体. 但,其实Etag的本意是版本管理.而并不是缓存有效性校验.这应该是一个衍生出来的使用方式. 而这种方式相比Last-Modified校验方式的好处是,如果我们消除时间戳部分,仅使用hash作为Etag值. 就可以方便做负载均衡同步.
Age(响应标头,HTTP1.1)
Age标头,对于原始服务器来说,用于指明,当前资源被生成了多久,即存活期.而对于一个缓存代理服务器来说,它表示缓存副本,被缓存了多久.缓存代理服务器,必须生成Age头.其值以秒为单位.且可能为负值.
Vary(响应标头,HTTP1.1)
Vary标头,用于列出一组响应标头,用于缓存者从其缓存副本中筛选合适的变体.举个例子来说,不同的请求方法,导致对同一资源的响应有区别.这就导致缓存者有多份缓存副本.那么Vary所列出的标头项,就是选择副本时的一个重要依据. 比如Vary:Accept-Language.那么如果新的请求中的Accept-Language标头的值,而原始请求(被缓存的那个)中并未包含与之匹配的Accept-Language的标头的话.那就必须放弃该副本.而是把请求转发到原始服务器.
另一个Vary的典型应用是,Vary:Accept-Encoding.这样做的意义在于,某些用户使用的浏览器,可能不支持一些特定的压缩算法.那么当这个用户途径的某个共享的缓存代理服务器,所缓存的使用了某种压缩算法的响应,就不能直接返回给该用户.如果服务器端,并没有配置这个标头,那就可能产生悲剧.即用户的浏览器无法解压缩返回的资源.导致各种异常状况的出现.
范围相关标头.以及缓存的意义.
请求标头:
.Range : 1000- | -1000 | 0 - Content-Length
Range头可以指定像服务器(并不一定总是原始服务器,比如一个缓存代理服务器)端获取范围内的数据,这种格式是很松散的,可以用”,”逗号分割范围的一种表达式.比如1-100,-1 这就表示要获取第一到100个字节,以及最后一个字节的部分.又或者 50-则表示50个字节之后的所有数据搭配可以很灵活.不过,当使用多个范围的Range标头时,假设范围都是合法的(不存在越界的情况,如果越界,则可能返回417 Requested Range Not Satisfiable状态码).则服务器响应时,会修改响应中的Content-Type标头为 如下格式:
Content-Type : multipart/byteranges;boundary=----ROPE----
----ROPE----
Content-Type:image/jpeg
Content-Range:bytes 0-100/2000
此处为0-100的数据
----ROPE----
Content-Type:image/jpeg
Content-Range:xxx-xxx/2000
xxx-xxx范围的数据.
----ROPE----
我们关心的是和缓存有关的情况,其实对于任何客户端(包括用户代理,以及各类缓存服务器)来说.如果它明确的知道自己想要某一部分范围的数据.就可以使用Range标头. 但事实上,比如对于浏览器来说,一般情况下,只有当服务器端的响应中包含Accept-Ranges:bytes标头时,才可能会在有断点续传需求的时候,自动使用Range头去请求实体.而代只有在响应中,明确出现Accept-Ranges:none时.才会完全避免客户端(包括缓存代理服务器),使用Range标头去获取部分数据.这是要区别看待的.
PS:Range头,还可以在GET方式下与If-Unmodified-Since标头配合,进行条件请求.其行为类似于If-Range头中使用日期格式做新鲜度校验.
.If-Range : 实体的Etag值 | date日期值.
配合Range使用的条件请求标头,该标头的值可以是被请求实体的Etag值,又或者是其Last-Modified的日期.客户端所缓存的部分数据,是新鲜的,服务器端才会,以206方式返回这部分数据.否则,以200方式返回全部数据.
响应标头:
.Accept-Ranges : bytes | none
用于说明,服务器是否支持范围请求.一般,我们常常为图片等资源设置Accept-Ranges:bytes标头.以便使客户端,可以使用断点续传功能.当然,这一切的前提是,客户端之前有缓存部分数据.或者换个角度说,如果服务器端明确声明,不允许缓存某个实体.那么断点续传也就无从说起了. 所以正确的服务器端配置.是一切的基础.
Content-Range : bytes 0-xxxx/xxxx
标明当前服务器端返回数据的范围. /xxxx部分是总长度.
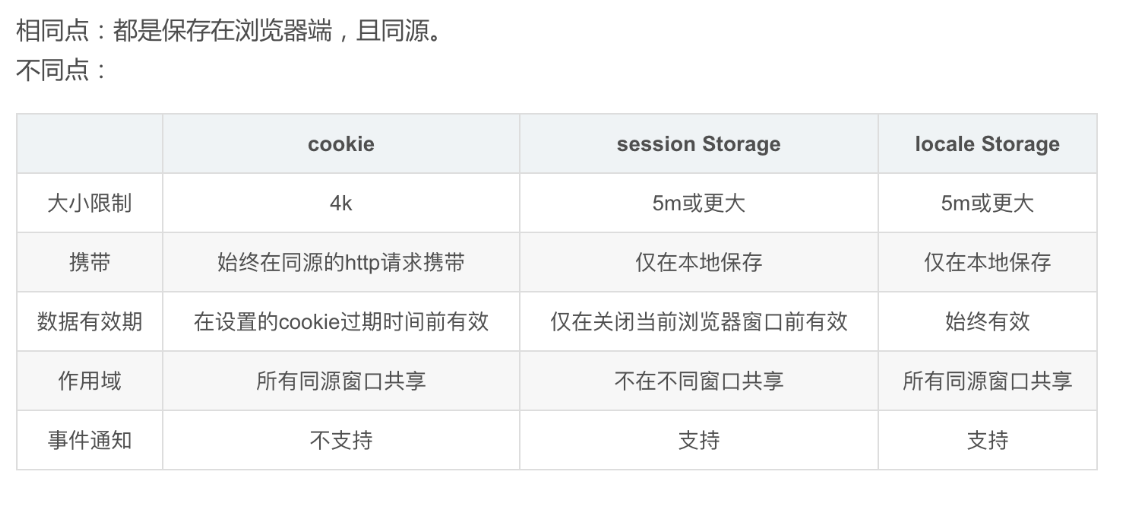
cookie和storage对比