

目录
- 专有名词
- 命名风格、常量定义
- 代码格式
- OOP规约
- 集合处理、并发处理
- 控制语句、其他
- 日志规约、单元测试
- MySQL数据库
- 应用分层、设计规约
专有名词
-
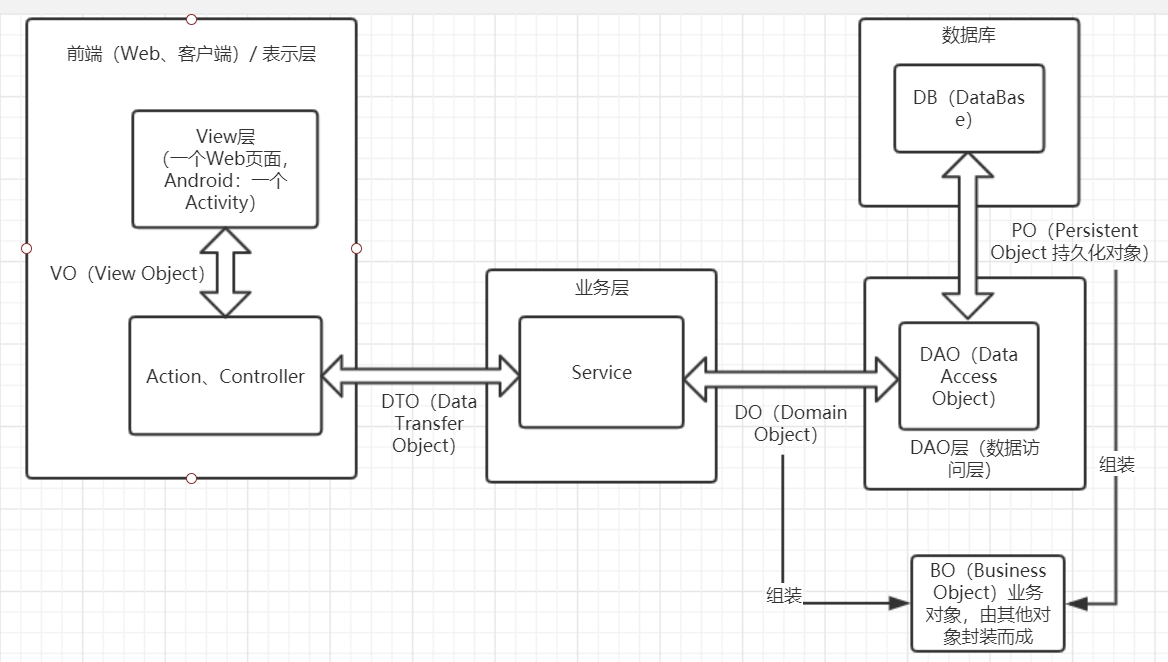
POJO( Plain Ordinary Java Object ): 在下文中,POJO 专指只有 setter / getter /toString 的简单类,包括 DO/DTO/BO/VO 等。
-
DO(Domain Object):(领域对象,作用于业务层与dao层之间)service使用接收到的DTO数据传输对象构造或者重构DO对象,传递到dao层
-
DTO(Data Transfer Object):(数据传输对象,作用于表示层与业务层之间)Action/Controller将接收到的VO对象进行业务逻辑处理,转化或者构造成DTO对象将其传递给service层
-
VO(View Object):(视图对象,作用于前台页面与表示层之间,将所有的数据封装到一起,比如:表单数据)VO一般用于封装前端页面传递到Action/Controller的所有参数,这些参数并不一定完全与数据库中表的所有字段均匹配
-
PO:Persistent Object(持久化对象,作用于dao层与数据库交互)PO对象一般对应着表结构,由DO对象进过持久化得到PO对象(比如,通过orm将其持久化)。转化为持久化对象PO后则可以与数据库进行交互。
-
BO(Business Object) 业务对象。封装对象、复杂对象,里面可能包含多个类。主要作用是把业务逻辑封装为一个对象。这个对象可以包括一个或多个其它的对象。
-
ORM:(Object/Relational Mapping)对象/关系映射
命名风格
-
类名使用 UpperCamelCase 风格,但以下情形例外:DO / BO / DTO / VO / AO/ PO / UID 等。
正例:
UserDO / TcpUdpDeal。 -
常量命名全部大写,单词间用下划线隔开,力求语义表达完整清楚,不要嫌名字长。
正例:
MAX_STOCK_COUNT / CACHE_EXPIRED_TIME。 -
抽象类命名使用 Abstract 或 Base 开头;异常类命名使用 Exception 结尾;测试类命名以它要测试的类的名称开始,以 Test 结尾。
-
POJO 类中布尔类型变量都不要加is前缀,否则部分框架解析会引起序列化错误。
说明:在本文 MySQL 规约中的建表约定第一条, 表达是与否的值采用 is_xxx 的命名方式, 所以,需要在<resultMap>设置从 is_xxx 到 xxx 的映射关系。 反例:定义为基本数据类型 Boolean isDeleted 的属性, 它的方法也是 isDeleted(),RPC (Remote Procedure Call 远程调用过程)框架在反向解析的时候, “误以为”对应的属性名称是 deleted,导致属性获取不到,进而抛出异常。 -
包名统一使用单数形式,但是类名如果有复数含义,类名可以使用复数形式。
正例:应用工具类包名为
com.alibaba.ai.util、类名为MessageUtils(此规则参考 spring 的框架结构) -
在常量与变量的命名时,表示类型的名词放在词尾,以提升辨识度。
正例:
startTime / workQueue / nameList / TERMINATED_THREAD_COUNT反例:
startedAt / QueueOfWork / listName / COUNT_TERMINATED_THREAD
常量定义
在 long 或者 Long 赋值时,数值后使用大写的 L,不能是小写的 l,小写容易跟数字 1 混淆,造成误解。
代码格式
-
if/for/while/switch/do 等保留字与括号之间都必须加空格。
-
注释的双斜线与注释内容之间有且仅有一个空格。

-
在进行类型强制转换时,右括号与强制转换值之间不需要任何空格隔开。

-
单行字符数限制不超过 120 个,超出需要换行。

-
不同逻辑、不同语义、不同业务的代码之间插入一个空行分隔开来以提升可读性。
说明:任何情形,没有必要插入多个空行进行隔开。
OOP规约
-
所有整型包装类对象之间值的比较,全部使用 equals 方法比较。
说明:对于 Integer var = ? 在-128 至 127 范围内的赋值,Integer 对象是在 IntegerCache.cache 产生,会复用已有对象,这个区间内的 Integer 值可以直接使用==进行判断,但是这个区间之外的所有数 据,都会在堆上产生,并不会复用已有对象,这是一个大坑,推荐使用 equals 方法进行判断。
-
浮点数之间的等值判断,基本数据类型不能用==来比较,包装数据类型不能用equals 来判断。
说明:浮点数采用“尾数+阶码”的编码方式,类似于科学计数法的“有效数字+指数”的表示方式。二进制无法精确表示大部分的十进制小数,具体原理参考《码出高效》。


-
为了防止精度损失,禁止使用构造方法 BigDecimal(double) 的方式把 double 值转化为 BigDecimal 对象。
说明:BigDecimal(double)存在精度损失风险,在精确计算或值比较的场景中可能会导致业务逻辑异常。如:BigDecimal g = new BigDecimal(0.1f); 实际的存储值为:0.10000000149
正例:优先推荐入参为 String 的构造方法,或使用 BigDecimal 的 valueOf 方法,此方法内部其实执行了Double 的 toString,而 Double 的 toString 按 double 的实际能表达的精度对尾数进行了截断。

-
所有的 POJO 类属性必须使用包装数据类型
-
RPC 方法的返回值和参数必须使用包装数据类型。
-
(推荐)所有的局部变量使用基本数据类型。
说明:比如显示成交总额涨跌情况,即正负 x%,x 为基本数据类型,调用的 RPC 服务,调用不成功时, 返回的是默认值,页面显示为 0%,这是不合理的,应该显示成中划线。所以包装数据类型的 null 值,能 够表示额外的信息,如:远程调用失败,异常退出。
-
定义 DO/DTO/VO 等 POJO 类时,不要设定任何属性默认值。
-
序列化类新增属性时,请不要修改 serialVersionUID 字段,避免反序列失败;如果完全不兼容升级,避免反序列化混乱,那么请修改 serialVersionUID 值。
-
构造方法里面禁止加入任何业务逻辑,如果有初始化逻辑,请放在 init 方法中。
-
POJO 类必须写 toString 方法。使用 IDE 中的工具:source> generate toString时,如果继承了另一个 POJO 类,注意在前面加一下 super.toString。
-
? 禁止在 POJO 类中,同时存在对应属性 xxx 的 isXxx()和 getXxx()方法。
-
使用索引访问用String的split方法得到的数组时,需做最后一个分隔符后有无内容的检查,否则会有抛 IndexOutOfBoundsException 的风险。

- 慎用 Object 的 clone 方法来拷贝对象。
说明:对象 clone 方法默认是浅拷贝,若想实现深拷贝需覆写 clone方法实现域对象的深度遍历式拷贝。
集合处理
-
关于 hashCode 和 equals 的处理,遵循如下规则:
1) 只要覆写 equals,就必须覆写 hashCode。
2) 因为 Set 存储的是不重复的对象,依据 hashCode 和 equals 进行判断,所以 Set 存储的对象必须覆 写这两个方法。
3) 如果自定义对象作为 Map 的键,那么必须覆写 hashCode 和 equals。
说明:String 已覆写 hashCode 和 equals 方法,所以我们可以愉快地使用 String 对象作为 key 来使用。
-
使用集合转数组的方法,必须使用集合的 toArray(T[] array),传入的是类型完全一致、长度为 0 的空数组。
反例:直接使用 toArray 无参方法存在问题,此方法返回值只能是 Object[]类,若强转其它类型数组将出现 ClassCastException 错误。
正例:
List<String> list = new ArrayList<>(2);
list.add("guan");
list.add("bao");
String[] array = list.toArray(new String[0]);
说明:使用 toArray 带参方法,数组空间大小的 length:
1) 等于 0,动态创建与 size 相同的数组,性能最好。
2) 大于 0 但小于 size,重新创建大小等于 size 的数组,增加 GC 负担。
3) 等于 size,在高并发情况下,数组创建完成之后,size 正在变大的情况下,负面影响与上相同。
4) 大于 size,空间浪费,且在 size 处插入 null 值,存在 NPE 隐患。
-
使用 entrySet 遍历 Map 类集合 KV ,而不是 keySet 方式进行遍历。
说明:keySet 其实是遍历了 2 次,一次是转为 Iterator 对象,另一次是从 hashMap 中取出 key 所对应的 value。而 entrySet 只是遍历了一次就把 key 和 value 都放到了 entry 中,效率更高。如果是 JDK8,使用 Map.forEach 方法。

- 利用 Set 元素唯一的特性,可以快速对一个集合进行去重操作,避免使用 List 的contains 方法进行遍历、对比、去重操作。
并发处理
-
线程资源必须通过线程池提供,不允许在应用中自行显式创建线程。
说明:线程池的好处是减少在创建和销毁线程上所消耗的时间以及系统资源的开销,解决资源不足的问题。如果不使用线程池,有可能造成系统创建大量同类线程而导致消耗完内存或者“过度切换”的问题。
-
SimpleDateFormat 是线程不安全的类,一般不要定义为 static 变量,如果定义为static ,必须加锁,或者使用 DateUtils 工具类。

-
避免 Random 实例被多线程使用,虽然共享该实例是线程安全的,但会因竞争同一seed 导致的性能下降。

控制语句
-
当 switch 括号内的变量类型为 String 并且此变量为外部参数时,必须先进行 null判断。
-
在高并发场景中,避免使用”等于”判断作为中断或退出的条件。
说明:如果并发控制没有处理好,容易产生等值判断被“击穿”的情况,使用大于或小于的区间判断条件来代替。
反例:判断剩余奖品数量等于 0 时,终止发放奖品,但因为并发处理错误导致奖品数量瞬间变成了负数,这样的话,活动无法终止。
-
下列情形,需要进行参数校验:
1) 调用频次低的方法。
2) 执行时间开销很大的方法。此情形中,参数校验时间几乎可以忽略不计,但如果因为参数错误导致 中间执行回退,或者错误,那得不偿失。
3) 需要极高稳定性和可用性的方法。
4) 对外提供的开放接口,不管是 RPC/API/HTTP 接口。
5) 敏感权限入口。
-
下列情形,不需要进行参数校验:
1) 极有可能被循环调用的方法。但在方法说明里必须注明外部参数检查要求。
2) 底层调用频度比较高的方法。毕竟是像纯净水过滤的最后一道,参数错误不太可能到底层才会暴露问题。一般DAO层与Service层都在同一个应用中,部署在同一台服务器中,所以DAO的参数校验,可以省略。
3) 被声明成 private只会被自己代码所调用的方法,如果能够确定调用方法的代码传入参数已经做过检查或者肯定不会有问题,此时可以不校验参数。
其他
- 在使用正则表达式时,利用好其预编译功能,可以有效加快正则匹配速度。
- 后台输送给页面的变量必须加 $!{var} ——中间的感叹号。
说明:如果 var 等于 null 或者不存在,那么${var}会直接显示在页面上。
- 获取当前毫秒数
System . currentTimeMillis(); 而不是new Date().getTime();
说明:如果想获取更加精确的纳秒级时间值,使用 System.nanoTime()的方式。在 JDK8 中,针对统计时 间等场景,推荐使用 Instant 类。
- 日期格式化时, yyyy 表示当天所在的年,而大写的 YYYY 代表是 week in which year(JDK7 之后引入的概念),意思是当天所在的周属于的年份,一周从周日开始,周六结束,只要本周跨年,返回的 YYYY 就是下一年。另外需要注意:
- 表示月份的是大写的M
- 表示分钟的是小写的m
- 24小时制的是大写的H
- 12小时制的是小写的h
正例:表示日期和时间的格式如下所示:
new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
日志规约
- 应用中不可直接使用日志系统(Log4j、Logback)中的API,而应依赖使用日志框架SLF4J中的API,使用门面模式的日志框架,有利于维护和各个类的日志处理方式统一。
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
private static final Logger logger = LoggerFactory.getLogger(Test.class);
-
应用中的扩展日志 ( 如打点、临时监控、访问日志等 ) 命名方式:appName_logType_logName.log。
-
logType:日志类型,如 stats/monitor/access 等;
-
logName:日志描述。这种命名的好处:通过文件名就可知道日志文件属于什么应用,什么类型,什么目的,也有利于归类查找。
-
-
在日志输出时,字符串变量之间的拼接使用占位符的方式。
说明:因为 String 字符串的拼接会使用 StringBuilder 的 append()方式,有一定的性能损耗。使用占位符仅是替换动作,可以有效提升性能。

单元测试
-
好的单元测试必须遵守 AIR 原则。
说明:单元测试在线上运行时,感觉像空气(AIR)一样并不存在,但在测试质量的保障上,却是非常关 键的。好的单元测试宏观上来说,具有自动化(Automatic)、独立性(Independent)、可重复执行(Repeatable)的特点。
-
单元测试代码必须写在如下工程目录: src/test/java ,不允许写在业务代码目录下。
说明:源码编译时会跳过此目录,而单元测试框架默认是扫描此目录。
-
编写单元测试代码遵守 BCDE 原则,以保证被测试模块的交付质量。
- B:Border,边界值测试,包括循环边界、特殊取值、特殊时间点、数据顺序等。
- C:Correct,正确的输入,并得到预期的结果。
- D:Design,与设计文档相结合,来编写单元测试。
- E:Error,强制错误信息输入(如:非法数据、异常流程、业务允许外等),并得到预期的结果。
- 用户输入的 SQL 参数严格使用参数绑定或者 METADATA 字段值限定,防止 SQL 注入,禁止字符串拼接 SQL 访问数据库
MySQL数据库
-
表达是与否概念的字段,必须使用 is_xxx 的方式命名,数据类型是 unsigned tinyint(1 表示是,0 表示否)。
-
表名、字段名必须使用小写字母或数字 , 禁止出现数字开头,禁止两个下划线中间只出现数字。数据库字段名的修改代价很大,因为无法进行预发布,所以字段名称需要慎重考虑。
说明:MySQL 在 Windows 下不区分大小写,但在 Linux 下默认是区分大小写。因此,数据库名、表 名、字段名,都不允许出现任何大写字母,避免节外生枝。
-
禁用保留字,如 desc 、 range 、 match 、 delayed 等,请参考 MySQL 官方保留字。
-
主键索引名为 pk_ 字段名;唯一索引名为 uk _字段名 ; 普通索引名则为 idx _字段名。
说明:pk_ 即 primary key;uk_ 即 unique key;idx_ 即 index 的简称。
应用分层
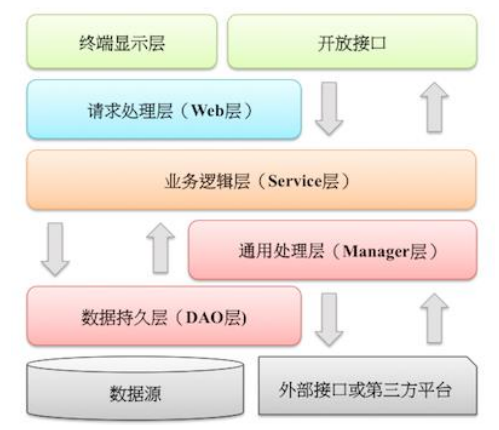
- 图中默认上层依赖于下层,箭头关系表示可直接依赖,如:开放接口层可以依赖于Web 层,也可以直接依赖于 Service 层,依此类推:
设计规约
- 存储方案和底层数据结构的设计获得评审一致通过,并沉淀成为文档。
说明:有缺陷的底层数据结构容易导致系统风险上升,可扩展性下降,重构成本也会因历史数据迁移和系 统平滑过渡而陡然增加,所以,存储方案和数据结构需要认真地进行设计和评审,生产环境提交执行后, 需要进行 double check。
-
如果某个业务对象的状态超过3个,使用状态图来表达并且明确状态变化的各个触发条件。
说明:状态图的核心是对象状态,首先明确对象有多少种状态,然后明确两两状态之间是否存在直接转换 关系,再明确触发状态转换的条件是什么。
正例:淘宝订单状态有已下单、待付款、已付款、待发货、已发货、已收货等。比如已下单与已收货这两 种状态之间是不可能有直接转换关系的
-
设计的本质就是识别和表达系统难点,找到系统的变化点,并隔离变化点。
-
系统架构设计的目的:
- 确定系统边界。确定系统在技术层面上的做与不做。
- 确定系统内模块之间的关系。确定模块之间的依赖关系及模块的宏观输入与输出。
- 确定指导后续设计与演化的原则。使后续的子系统或模块设计在规定的框架内继续演化。
- 确定非功能性需求。非功能性需求是指安全性、可用性、可扩展性等。
