

分布式缓存服务中,提供缓存服务的节点可能有很多个。在单机缓存服务中,数据被缓存的流程是这样的:
第一次查询数据时首先从源数据查询(比如数据库),找到之后,同时放入缓存服务器中,下次查询同样的数据时会直接从缓存服务器上查找。
但是缓存服务器一般不太可能是单机的,往往有多个节点。转换为分布式之后,会出现一些问题。
问题一数据冗余
考虑一下,单机服务的时候,利用LRU算法实现缓存的存取,一个key对应一个数据value。分布式条件下,如果只是单纯的增加节点,这次查找key对应的数据在A节点上,下次查找的时候却在B服务器上。同一个key有多个缓存,完全没必要嘛,这样就是数据冗余了。
怎么解决?
利用哈希。首先对key值hash,然后利用节点数取余。
h = hash(key) %len(node)
这样同一个key的数据只会被一个节点缓存。很awesome有没有。
But,我不可能一直是这几个节点呀,万一有的节点挂了呢,或者我要添加节点呢?
问题二容错性和扩展性
如果有节点挂了或者新增节点,都会导致len(node) 的变化,那么利用hash计算出来的值跟之前的就不一样。这样导致新增或者删除一个节点,之前的所有缓存都失效了!我的天哪!!!
这种问题就是 缓存雪崩 。
怎么办呢?利用一致性hash算法。
一致性哈希算法(Consistent Hashing)最早在论文《Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web》中被提出。
它的原理是,把所有的hash值空间(就是上面公式计算出来的h)看成是一个环,取值范围从0到2^32-1。将每个服务器节点通过hash映射到环上,同时将数据key通过hash函数也映射到环上,按顺时针方向,数据key跟哪个节点近就属于哪个节点。
举个例子,现在有三个缓存服务器节点2,4,6,假设这个hash算法就是原样输出,我们将节点和数据(1,3,7,9)经过hash之后到环上:
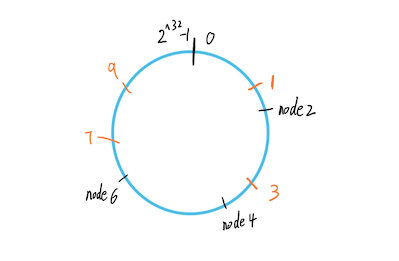
按顺时针方向,数据1属于node2,数据3属于node4,数据7、9输入node6。
貌似看起来不错,但是还有个问题。在节点较少的情况上,会发生 数据倾斜 的问题。比如上图所示,数据可能大量的堆积在node6和node2之间。
解决办法是添加虚拟节点,利用虚拟节点负载均衡每个数据。虚拟节点的做法是,对一个真实节点计算多个hash,放到环上,所有这些虚拟节点的数据都属于真实节点。
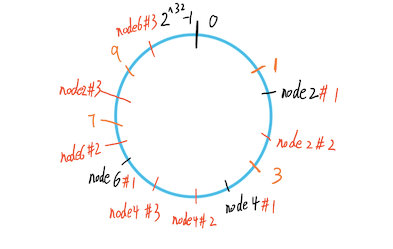
这样所有的数据都均匀的分布在环上了。
算法实现
了解了原理,来动手实现一下一致性hash算法。整个算法模仿go语言的分布式缓存服务groupcache 实现,groupcache可以说是memcached 的go语言实现。
首先定义一致性hash环结构体:
type Hash func(data []byte) uint32
// ConHash 一致性hash
type ConHash struct {
hash Hash // hash算法
replicas int // 虚拟节点数
nodes []int // hash环节点数
hashMap map[int]string // 虚拟节点-真实节点
}
可以看到,类型Hash就是个回调函数,用户可以自定义hash算法。
然后需要往hash环上添加节点,根据指定的虚拟节点数用hash算法放到环上。
// Add 添加节点到hash环上
func (m *ConHash) Add(nodes ...string) {
for _, node := range nodes {
// 将节点值根据指定的虚拟节点数利用hash算法放置到环中
for i := 0; i < m.replicas; i++ {
h := int(m.hash([]byte(strconv.Itoa(i) + node)))
m.nodes = append(m.nodes, h)
// 映射虚拟节点到真实节点
m.hashMap[h] = node
}
}
sort.Ints(m.nodes)
}
同样还需要根据key值从环上获取对应的节点,获取到节点之后从该节点查找数据。
// Get 从hash环上获取key对应的节点
func (m *ConHash) Get(key string) string {
if len(m.nodes) == 0 {
return ""
}
// 计算key的hash值
h := int(m.hash([]byte(key)))
// 顺时针找到第一个匹配的虚拟节点
idx := sort.Search(len(m.nodes), func(i int) bool {
return m.nodes[i] >= h
})
// 从hash环查找
// 返回hash映射的真实节点
return m.hashMap[m.nodes[idx%len(m.nodes)]]
}
有的人说不对啊,为啥添加的都是服务器节点,数据不是也放在环上吗?
其实是因为groupcache将数据划分出一个group的概念,数据在内部存储上利用hash+双向链表实现,缓存的数据被放在链表中。
整个流程是这样的,查找key值对应的数据时,根据url链接中的group和key值确定节点,如何确定的?上面的代码已经解释了,计算key值的hash,看它属于哪个节点。
然后从该节点的双向链表中查找。如果节点不存在这个key,从用户定义的数据源查找(比如数据库),找到之后将数据存入该group中。
以上,希望有帮助。
参考文章:
我的blog:blog.shiniao.fun/
