

Spark的shuffle系统很复杂,同时我认为这也是比MR快的最重要原因。MR是早期产物,Spark必然取其精华,弃其糟粕
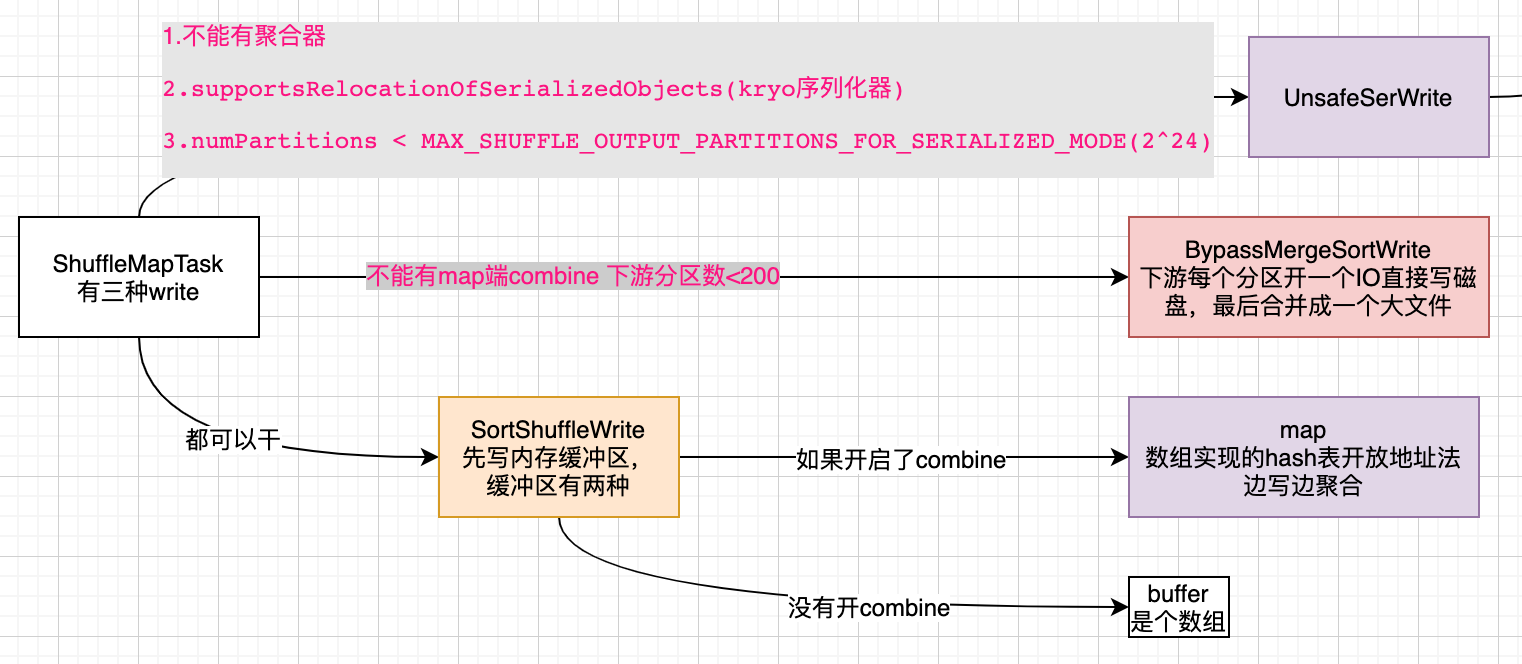
三种writer
// 通过shuffleHandle来决定是哪一种ShuffleWrite
handle match {
case unsafeShuffleHandle: SerializedShuffleHandle[K @unchecked, V @unchecked] =>
new UnsafeShuffleWriter(
env.blockManager,
shuffleBlockResolver.asInstanceOf[IndexShuffleBlockResolver],
context.taskMemoryManager(),
unsafeShuffleHandle,
mapId,
context,
env.conf)
case bypassMergeSortHandle: BypassMergeSortShuffleHandle[K @unchecked, V @unchecked] =>
new BypassMergeSortShuffleWriter(
env.blockManager,
shuffleBlockResolver.asInstanceOf[IndexShuffleBlockResolver],
bypassMergeSortHandle,
mapId,
context,
env.conf)
case other: BaseShuffleHandle[K @unchecked, V @unchecked, _] =>
new SortShuffleWriter(shuffleBlockResolver, other, mapId, context)
}
UnsafeShuffleWriter
源码中说这种方式是序列化的形式,非常高效。看看走他的条件:
// try to buffer map outputs in a serialized form, since this is more efficient
def canUseSerializedShuffle(dependency: ShuffleDependency[_, _, _]): Boolean = {
val shufId = dependency.shuffleId
val numPartitions = dependency.partitioner.numPartitions
if (!dependency.serializer.supportsRelocationOfSerializedObjects) {
// 得支持序列化后寻址
log.debug(s"Can't use serialized shuffle for shuffle $shufId because the serializer, " +
s"${dependency.serializer.getClass.getName}, does not support object relocation")
false
} else if (dependency.aggregator.isDefined) {
// 不能有聚合逻辑!
log.debug(
s"Can't use serialized shuffle for shuffle $shufId because an aggregator is defined")
false
} else if (numPartitions > MAX_SHUFFLE_OUTPUT_PARTITIONS_FOR_SERIALIZED_MODE) {
// 下游分区数有限制。
log.debug(s"Can't use serialized shuffle for shuffle $shufId because it has more than " +
s"$MAX_SHUFFLE_OUTPUT_PARTITIONS_FOR_SERIALIZED_MODE partitions")
false
} else {
log.debug(s"Can use serialized shuffle for shuffle $shufId")
true
}
}
这有一个条件dependency.serializer.supportsRelocationOfSerializedObjects
# 这是源码中的伪代码,即说明了什么是supportsRelocationOfSerializedObjects
serOut.open()
position = 0
serOut.write(obj1)
serOut.flush()
position = # of bytes written to stream so far
obj1Bytes = output[0:position-1]
serOut.write(obj2)
serOut.flush()
position2 = # of bytes written to stream so far
obj2Bytes = output[position:position2-1]
serIn.open([obj2bytes] concatenate [obj1bytes]) should return (obj2, obj1)
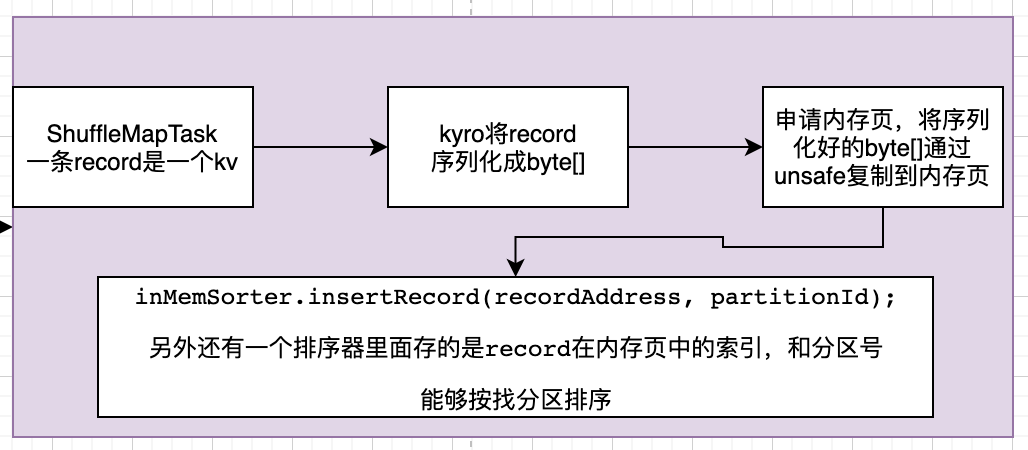
这个不知道面试有没有人问这个,用到了很多unsafe操作。记录一下细节
// 这是UnsafeShuffleWriter的write方法。
// 方法签名为:write(scala.collection.Iterator<Product2<K, V>> records)
// 这个迭代器就是stage最后一个rdd身上的迭代器
while (records.hasNext()) {
// 有调用了另一个方法,把一个kv穿了进去。从方法名看就是把数据传入了缓冲区
insertRecordIntoSorter(records.next());
}
把一条数据record也就是kv写到字节数组中。这个字节数组默认1MB。
void insertRecordIntoSorter(Product2<K, V> record) throws IOException {
assert(sorter != null);
// 我们数据的key
final K key = record._1();
// 分区号
final int partitionId = partitioner.getPartition(key);
// 这是个byteArrayOutputStream,把里面的字节数组置空
serBuffer.reset();
// serOutputStream是能序列化写的流。把key序列化写进字节数组
serOutputStream.writeKey(key, OBJECT_CLASS_TAG);
// 写value
serOutputStream.writeValue(record._2(), OBJECT_CLASS_TAG);
serOutputStream.flush();
// kv一共序列化完有多大
final int serializedRecordSize = serBuffer.size();
assert (serializedRecordSize > 0);
// 还有一个东西是sorter,Platform.BYTE_ARRAY_OFFSET是字节数组第一个元素的偏移量,因为java对象有对象头。
sorter.insertRecord(
serBuffer.getBuf(), Platform.BYTE_ARRAY_OFFSET, serializedRecordSize, partitionId);
}
把字节数组的数据copy到内存页中。如果是第一次,需要申请内存页。
/**
* Write a record to the shuffle sorter.
*/
public void insertRecord(Object recordBase, long recordOffset, int length, int partitionId)
throws IOException {
growPointerArrayIfNecessary();
// Need 4 bytes to store the record length.
// 这加4个字节也就是1个int,来存字节数组的长度
final int required = length + 4;
// 申请内存页。这里要跟taskManager打交道
acquireNewPageIfNecessary(required);
// 已经申请到了内存页,肯定!=null。内存页可以是堆也可以是堆外
assert(currentPage != null);
// 申请的内存页里面其实就是一个long[],这个base就是里面的long[]
// 如果是堆外的话 这里base是null
final Object base = currentPage.getBaseObject();
// 这是用一个long 64位存了两个信息,一个是当前是哪个内存页,一个是内存页里要写入的偏移量
final long recordAddress = taskMemoryManager.encodePageNumberAndOffset(currentPage, pageCursor);
// Platform就是unsafe,先放了一个4字节 代表record序列化后的长度
Platform.putInt(base, pageCursor, length);
// 因为放了4个字节,所以游标+4
pageCursor += 4;
// 从序列化完的那个字节数组copy到内存页中。
Platform.copyMemory(recordBase, recordOffset, base, pageCursor, length);
pageCursor += length;
// inMemSorter里存了索引,记录record在内存页中的信息。分区号是用来排序的
inMemSorter.insertRecord(recordAddress, partitionId);
}
申请内存页过程
// required从上面看,就是record序列化完的长度+4
// taskMemoryManager是每个task都有一个。
MemoryBlock page = taskMemoryManager.allocatePage(Math.max(pageSize,required), this);
// 默认没配置的话 是用的堆内内存
final val tungstenMemoryMode: MemoryMode = {
if (conf.get(MEMORY_OFFHEAP_ENABLED)) {
require(conf.get(MEMORY_OFFHEAP_SIZE) > 0,
"spark.memory.offHeap.size must be > 0 when spark.memory.offHeap.enabled == true")
require(Platform.unaligned(),
"No support for unaligned Unsafe. Set spark.memory.offHeap.enabled to false.")
MemoryMode.OFF_HEAP
} else {
MemoryMode.ON_HEAP
}
}
// 这能看出来默认内存页是多大
val pageSizeBytes: Long = {
val minPageSize = 1L * 1024 * 1024 // 1MB
val maxPageSize = 64L * minPageSize // 64MB
val cores = if (numCores > 0) numCores else Runtime.getRuntime.availableProcessors()
// Because of rounding to next power of 2, we may have safetyFactor as 8 in worst case
val safetyFactor = 16
// 这里默认是使用堆内存
val maxTungstenMemory: Long = tungstenMemoryMode match {
case MemoryMode.ON_HEAP => onHeapExecutionMemoryPool.poolSize
case MemoryMode.OFF_HEAP => offHeapExecutionMemoryPool.poolSize
}
val size = ByteArrayMethods.nextPowerOf2(maxTungstenMemory / cores / safetyFactor)
val default = math.min(maxPageSize, math.max(minPageSize, size))
conf.getSizeAsBytes("spark.buffer.pageSize", default)
}
注意
这种writer要求shuffle不能带聚合器,像reduceByKey,groupByKey是不能用的。sortByKey可以,repartition也可以。
ByPassMergeSortWriter
先看这个类的名字,跳过了MergeSort,我理解的是跳过归并排序。走这个Writer的条件是没有开启combine并且下游分区数<200。这个的核心逻辑就是下游有n个分区就开辟n个IO,然后写出n个临时文件,之后把这些临时文件拼接成一个大文件,并且生成一个索引文件记录其中每个分区的offset。下游reduce直接拉取。
这个做法适用于groupByKey sortByKey 且下游分区数不能超过阈值(默认200)如果下游分区数太多那么产生的临时文件就太多了。
和MR对比
MR的MapTask每次输出的时候必然会做一次排序(分区有序且分区内key有序)。Spark提出这个writer,在数据量不大的情况下,不进行排序,直接向磁盘写文件。
SortShuffleWriter
这种writer是写入内存缓冲区。一旦使用内存缓冲区buffer必然要进行排序的操作,因为一个Task里面有多个分区的数据,所以buffer在spill的时候要进行排序。这样spill出的多个小文件最后走一个归并排序,就是一个整体分区有序的文件,并且同时生成一个索引文件标识这个文件中每个分区的offset。这样下游reduce端进行拉取的时候非常快。这里其实和MR处理套路基本一致
他的缓冲区有两种形式map和array
array
如果没有开启mapSideCombine,使用array作为缓冲区。这种方式是解决ByPass不满足的时候,即下游分区数过多的时候。
// Stick values into our buffer
while (records.hasNext) {
addElementsRead()
val kv = records.next()
// 这里是 p k v
buffer.insert(getPartition(kv._1), kv._1, kv._2.asInstanceOf[C])
maybeSpillCollection(usingMap = false)
}
spill的时候会依据partition排序
map
如果开启了mapSideCombine,使用一个数组实现的HashMap来作为缓冲区。如果是map做缓冲区,由于本身就是kv的,所以很容易做聚合。
数组实现的HashMap比jdk的省空间。对象是有成本的,并且引用也是有大小的
// Combine values in-memory first using our AppendOnlyMap
// 这就是aggregator的三个函数
val mergeValue = aggregator.get.mergeValue
val createCombiner = aggregator.get.createCombiner
var kv: Product2[K, V] = null
// 这是一个函数。如果是同一个key,则走聚合逻辑。这就是所谓的mapSideCombine
val update = (hadValue: Boolean, oldValue: C) => {
if (hadValue) mergeValue(oldValue, kv._2) else createCombiner(kv._2)
}
while (records.hasNext) {
addElementsRead()
kv = records.next()
map.changeValue((getPartition(kv._1), kv._1), update)
maybeSpillCollection(usingMap = true)
}
spill的时候同样对partition排序。
这里提一下面试常问的Hash冲突的解决办法,挂链表解决(jdk HashMap)开放地址法(Spark这个缓冲区用的就是这个)
和MR对比
MR中默认没有combine,得人为开启。并且combine是发生在环形缓冲区spill的时候。而Spark这个是往buffer写的时候就进行了聚合,并且Spark的一些算子默认就开启了combine。所以spill的次数必然会比MR小,从而减少了IO。
