

一:环境搭建
环境搭建流程图
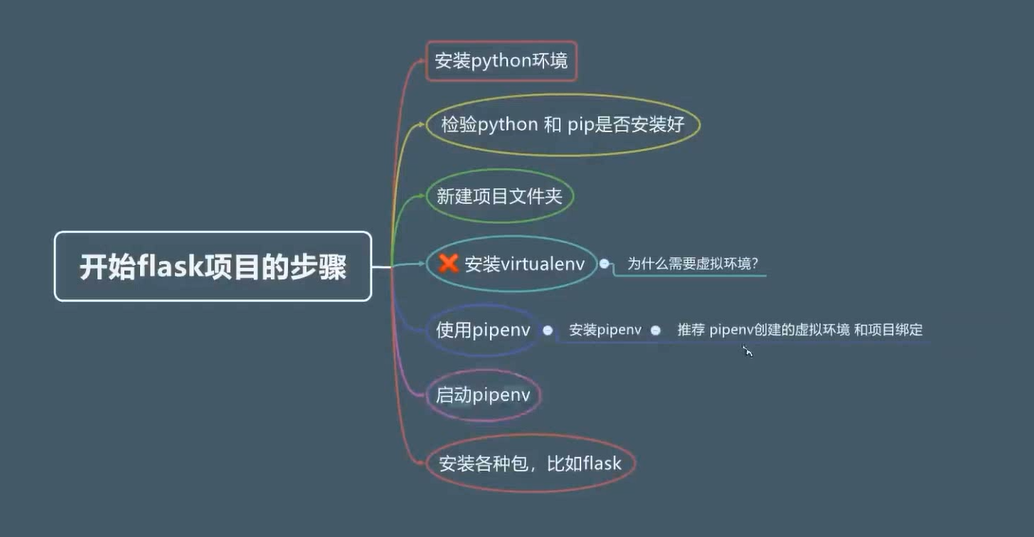
安装pipenv
pip install pipenv
切换到项目目录中
# 切换目录
cd /d E:\home\鱼书\fisher
# 安装虚拟环境
pipenv install
# 激活虚拟环境
pipenv shell
pipenv一些基本的命令
# 安装包
pipenv install flask
# 退出虚拟环境
exit
# 进入虚拟环境
pipenv shell
# 卸载包
pipenv uninstall flask
# 查看虚拟环境的安装路径
pipenv --venv
# 查看安装包的依赖关系
pipenv graph
二:初窥Flask
1 flask基本用法
from flask import Flask
__author__ = '欧阳'
app = Flask(__name__)
@app.route('/test', methods=['GET'])
def test():
return 'this is test'
if __name__ == '__main__':
app.run()
中间还有一个小的概念,就是我们在输入URL的时候可以输入localhost:5000/test/,也可以输入localhost:5000/test
我们只需要在创建视图的时候在路由的后面添加一个斜杠('/'),这就涉及到重定向的问题
2 路由的另一种注册方法
debug
开启debug模式之后我们就不需要在改动代码之后在重启服务了
但是上线之后就不能开启我们的调试模式了,因为调试模式的性能比较差,而且详细的错误堆栈信息就会被显示出来
# debug模式,只需要在app.run()中添加
app.run(debug=True)
使用add_url_rule方法修改路由注册方法
# @app.route('/test')
def test():
return 'this is test'
# 我们只需要使用下面的方法来实现路由的注册
app.add_url_rule('/test',view_func=test)
3 app.run相关参数与flask配置文件
1 # flask配置任意客户端访问并指定端口号
# 在host中配置ip地址,和端口
app.run(host='0.0.0.0',debug=True,port=8001)
2 # 在启动文件同阶文件夹下创建一个文件config.py,创建
DEBUG = True
# 在启动文件下面创建,'config'为配置文件路径
app.config.from_object('config')
# 使用配置文件中的数据
app.run(host='0.0.0.0',debug=app.config['DEBUG'],port=8001)
# 使用字典的取值方式来获取配置文件中的数据,要是配置文件中没有要取的数据,值为False
4 响应对象Response
# status code 200 404 301
# content-type http headers
# content-type=text/html是flask里面的请求方式
# 视图函数返回数据response的设置
1 # 使用make_response
from flask import make_response,Flask
app = Flask(__name__)
@app.route('/test')
def test():
params='<html></html>'
headers = {
'content-type':'application/json',
# 'content-type':'text/html',
'location':'https://cn.bing.com/'
}
response = make_response(params,301)
response.headers = headers
return response
2 # 直接return
@app.route('/test')
def test():
params='<html></html>'
headers = {
'content-type':'application/json',
# 'content-type':'text/html',
'location':'https://cn.bing.com/'
}
return params,301,headers
# 上面的content-type可以为
application/json # json格式字符串
text/html # 网页html
text/plain # 字符串
5 图书搜索数据来源
数据来源api
# 图书数据
1 关键字搜索
http://t.yushu.im/v2/book/search?q={}&start={}&count={}
2 isbn搜索
http://t.yushu.im/v2/book/isbn/{isbn}
3 豆瓣API
https://api.doubanio.com/v2/book
搜索关键字
# 路由中<>里面的数据就是视图中的参数
# q.isdigit是判断q是都为数字
# q.replace('-','')是将字符串q中的‘-’ 替换成空
@app.route('/book/search/<q>/<page>')
def search(q, page):
isbn_or_key = 'key'
if len(q) == 13 and q.isdigit():
isbn_or_key = 'isbn'
short_q = q.replace('-', '')
if '-' in q and len(short_q) == 10 and short_q.isdigit():
isbn_or_key = 'isbn'
6 试图函数简单的重构
# fisher.py
from helper import is_isbn_or_key
@app.route('book.search/<p>/<page>')
def search(p,page):
# 导入一个函数
isbn_or_key = is_isbn_or_key(q)
pass
# helper.py
def is_isbn_or_key(work):
isbn_or_key = 'key'
if len(work) == 13 and work.isdigit():
isbn_or_key = 'isbn'
short_work = work.replace('-','')
if '-' in work and len(short_work) == 10 and short_work.isdigit():
isbn_or_key = 'isbn'
return isbn_or_key
# 我们实现了在视图函数中调用其他文件中方法的操作,这样我们就只在视图中实现大的逻辑,而不用管具体的代码,使逻辑更加清晰
7 requests发送http请求及代码的重构
创建一个py文件http.py
# http.py
import requests
class HTTP:
def get(self, url, return_json=True):
r = requests.get(url)
if r.status_code != 200:
return {} if return_json else ''
return r.json if return_json else r.text
# 对于过多的判断条件的代码,我么可以使用三元表达式来简化代码
8 从api获取图书数据
# httpp.py
# 作用就是获取url的数据
import requests
class HTTP:
@staticmethod
def get(url, return_json=True):
r = requests.get(url)
if r.status_code != 200:
return {} if return_json else ''
return r.json if return_json else r.text
# helper.py
# 作用就是判断传过来的参数是关键字参数还是isbn
def is_isbn_or_key(work):
isbn_or_key = 'key'
if len(work) == 13 and work.isdigit():
isbn_or_key = 'isbn'
short_work = work.replace('-', '')
if '-' in work and len(short_work) == 10 and short_work.isdigit():
isbn_or_key = 'isbn'
return isbn_or_key
# yushu_book.py
# 作用就是在类中实现搜索的调度
from httpp import HTTP
class YuShuBook:
isbn_url = 'http://t.yushu.im/v2/book/isbn/{}'
keyword = 'http://t.yushu.im/v2/book/search?q={}&start={}&count={}'
@classmethod
def search_by_isbn(cls, isbn):
url = cls.isbn_url.format(isbn)
result = HTTP.get(url)
return result
@classmethod
def search_bu_keyword(cls, keyword):
url = keyword.format(keyword)
result = HTTP.get(url)
return result
# fisher.py
# 作用就是实现在函数视图中实现以上方法的调度,从而实现需求
@app.route('/book/search/<q>')
def search(q):
print(q)
isbn_or_key = is_isbn_or_key(q)
if isbn_or_key is 'isbn':
result = YuShuBook.search_by_isbn(q)
else:
result = YuShuBook.search_bu_keyword(q)
print(result())
return jsonify(result())
# 访问的路由---localhost:8001/book/search/9787510421242/1
三:蓝图,参数,数据验证,上下文和with
1 蓝图的简单实现
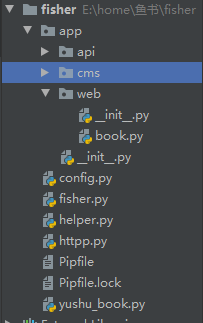
# 蓝图是一种很很好的解决分文件夹视图调用的方法,下面是flask蓝图的使用方法
# fisher.py 启动文件
from app import create_app
app = create_app()
if __main__ == '__name__':
app.run(host='0.0.0.0',port=8001,debug=app.config['DEBUG'])
# app/__init__.py
from flask import Flask
def create_app():
"""创建app"""
app = Flask(__name__)
app.config.from_object('config') # 注册配置文件
register_blueprint(app)
return app
def register_blueprint(app):
"""注册蓝图"""
from app.web.book import web # 导入视图中的蓝图
app.register_blueprint(web) # 在app中注册蓝图
# book.py
from flask import Buleprint
web = Blueprint('web',__name__) # 在视图函数中生成蓝图对象
@web.route('/book/search/<p>/<page>')
def search():
pass
2 单蓝图多模块拆分视图函数
# 上面的方法中实现的是每一个文件都是一个单独的蓝图对象,现在要实现的是每一个模块是一个蓝图,这个模块下面有很多的文件,比如user.py,book.py等
# web.py/__init__.py
from flask import Blueprint
web = Blueprint('web', __name__)
from app.web import web # 导入web,从而使蓝图生效
# web/book.py
from . import web # 导入蓝图对象
@web.route('url')
def book():
pass
3 request对象
request是flask中的请求,跟response一样是很重要的
# 导入request
from flask import
# 在视图函数中
q = request.args['q'] # 这里是一个不可变的字典取值的对象
a = request.args.to_dict() # 这里将不可变的字典转换成了可变的字典,所有的数据都在字典a里面
j = request.json() # 取json格式字符串参数
4 WTForms参数验证
在flask参数校验过程中,我们不要直接在接收到参数之后将参数之后在视图函数中写条件语句进行校验
我们开辟一个校验层来校验参数,使用flask的wtform模块来对我们http请求的参数
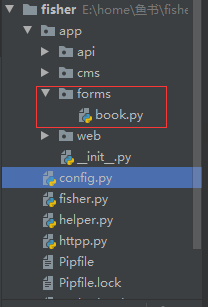
# forms/book.py
from wtforms import Form,IntegerField,StringField
from wtforms.validators import length,NumberRange
class SearchForm(Form):
# StringField就是校验字符串类型,validators后面的参数是对参数一系列状态的校验,比如长度
q = StringField(validators=[length(min=1,max=30)])
# IntegerField 就是校验数字类型的字段,字段都可以设置默认值,不传参的时候默认值才生效
page = IntegerField(validators=[NumberRange(min=1,max=90)],default=1)
# 在视图函数中 web/book.py
from app.forms.book import SearchForm
from . import web
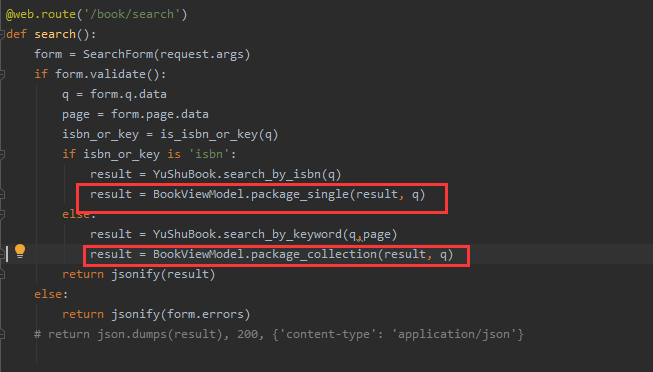
@web.route('/book/search')
def search():
form = SearchForm(request.args) # 参数直接传
if form.validate():
return jsonify({"code":200,'msg':"参数校验成功"})
else:
return jsonify(form.errors) # 这里的form.errors就是校验过程中不通过的字段会存在form.errors中
1 # 其实我们还可以定制每一个字段验证不通过的错误信息,加上一个message
q = StringField(validators=[length(min=1, max=30,message='参数错误')])
2 # 为了过滤传过来的字段为空,我们可以使用DataRequired来过滤字段
q = StringField(validators=[DataRequired(),length(min=1, max=30,message='参数错误')])
5 编写规范和配置文件改写
我们在编写代码的过程中,一定要秉承简洁性,易懂性
比如
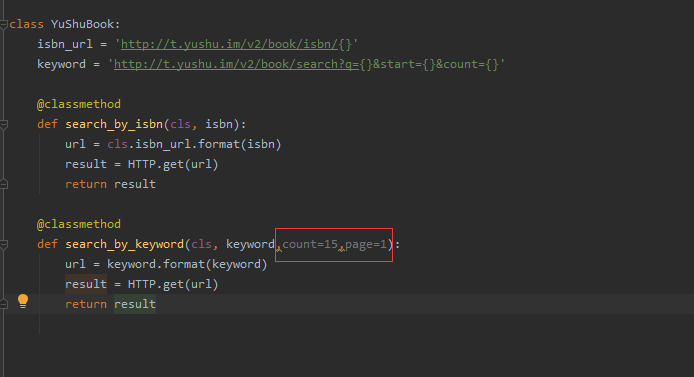
# 上面图片的代码中的传参这样不好,应该变成下面这样
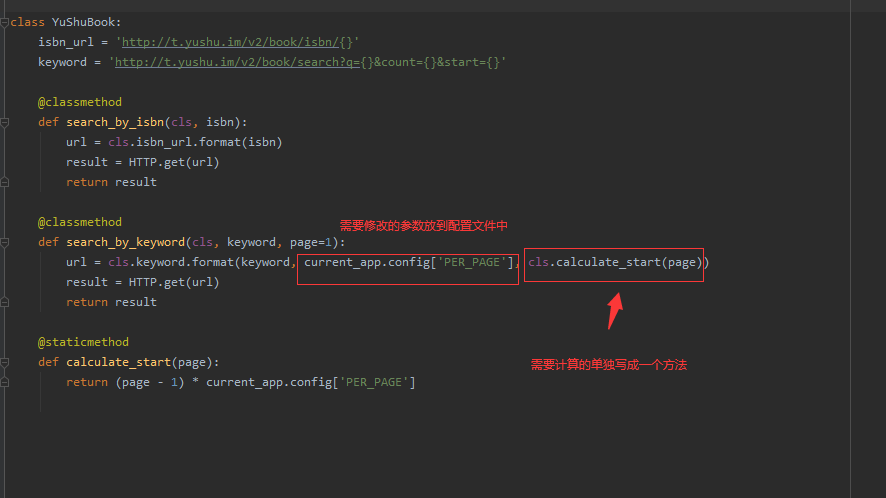
在这里我们说一个概念,有关于配置文件的,我们在flask框架编程过程中,为什么不将重要的配置文件和不怎么重要的配置文件分开呢
所以,我创建了两个配置文件
# secure.py
DEBUG = True
# setting.py
PER_PAGE = 15
# 注册配置文件
from flask import Flask
def create_app():
app = Flask(__name__)
app.config.from_object('app.setting') # 需要在app中注册
app.config.from_object('app.secure')
register_blueprint(app)
return app
def register_blueprint(app):
from app.web.book import web
app.register_blueprint(web)
# 使用配置文件
app.run(host='0.0.0.0', debug=app.config['DEBUG'], port=8001) # 在启动文件中
# 在普通的文件中
from flask import current_app
current_app.config['PER_PAGE']
6 定义第一个模型类
from sqlalchemy import Column, String
from sqlalchemy import Integer
class Book():
# Integer--数字 primary_key=True--主键 autoincrement=True--自增
id = Column(Integer, primary_key=True, autoincrement=True)
# String(50)--字符串,50个字节 nullable=False--False表示可以为空,True表示不为空
title = Column(String(50), nullable=False)
author = Column(String(30), default='未名')
binding = Column(String(20))
publisher = Column(String(50))
price = Column(String(20))
pages = Column(Integer)
pubdate = Column(String(20))
# unique表示唯一
isbn = Column(String(15), nullable=False, unique=True)
summary = Column(String(1000))
image = Column(String(50))
定义sqlalchemy的核心对象
# 在模型层中 models/book.py
from flask_sqlalchemy import SQLALchemy
db = SQLALchemy()
# 在模型类中继承db.Model
class Book(db.Model):
# 在app对象中注册
from app.model.book import db
db.init_app(app)
db.create_app(app=app)
在配置文件中编写数据库连接代码
# SQLALCHEMY_DATABASE_URI = '数据库+数据库驱动://用户名:密码@服务器地址:端口/数据库'
SQLALCHEMY_DATABASE_URI = 'mysql+cymysql://root:admin@122.51.91.103:3306/fisher'
# 然后在create_app下面写
db.init_app(app) #
db.create_all() # 把所有的数据模型映射到数据库
ORM和CodeFirst的区别
CodeFirst
1 专注于业务模型的设计,而不是专注于数据库的设计
2 数据库知识用来存储数据的,他的表关系应该由我们的业务来决定
3 在MVC模式中,业务逻辑应该卸载M层中
ORM:
对象关系映射
包含数据如何创建,还包括数据怎么查询,更新
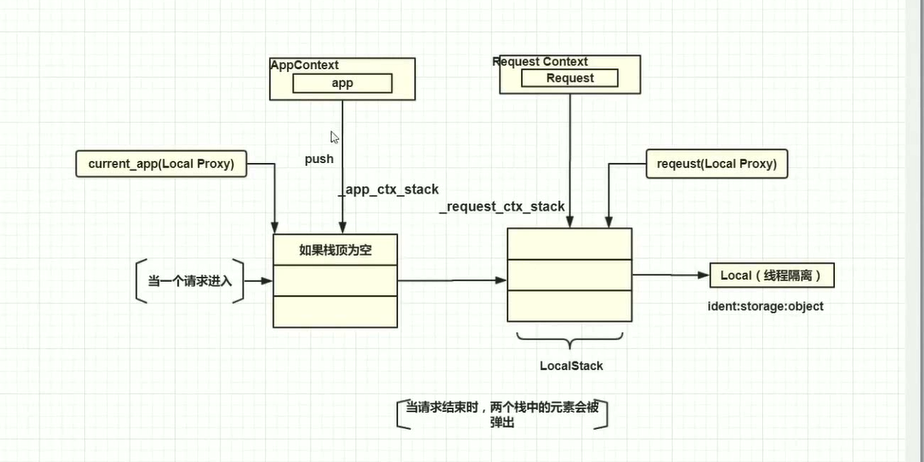
7 flask中的上下文以及with
flask中分为应用上下文和请求上下文
Flask AppContext
Request RequestContext
简书上有关于flask上下文的介绍
四个对象的区别
# Flask
核心对象,核心对象承载着各种各样的功能,比如保存了我们配置文件的信息,提供了注册路由,视图函数等等
# AppContext
把核心对象Flask做了封装,加了一些额外的参数
# Request
保存了我们的请求信息,比如我们相关url的参数,我们完整的url等
# RequestContext
是对我们Request的封装
# 我们在框架中使用我们的flask核心对象和Request的时候,并不是直接导入使用的,而是使用上下文来管理,比如
# 下面是flask框架里面的部分源码
# context locals
_request_ctx_stack = LocalStack()
_app_ctx_stack = LocalStack()
current_app = LocalProxy(_find_app)
request = LocalProxy(partial(_lookup_req_object, "request"))
session = LocalProxy(partial(_lookup_req_object, "session"))
g = LocalProxy(partial(_lookup_app_object, "g"))
# 使用---我们导入应用上下文或者请求上下文来操作我们的Flask和Reuqest
from flask import current_app
from flask import request
详解flask上下文与出入栈
栈:后进先出
队列:先进先出
with 语句
1 # 使用with实现手动推入栈,实现在应用上下文上绑定当前上下文
with app.app_context():
a = current_app
d = current_app.config['DEBUG']
print(a, d)
2 # with对象的特点
"""
1实现了上下文协议的对象
2上下文管理器
3含__enter__和__exit__
4with
"""
3 # with语句就是实现了开启,操作,释放的过程
# 比如我们操作数据库,就是
"""
1 连接数据库
2 操作sql语句
3 释放资源,防止资源占用过多造成的压力过大
"""
4 # 举一个文件操作的例子
try:
f=open(r'D:\test.txt')
print(f.read())
finally:
f.close()
# 使用我们的with实现的时候,就是在里面实现了一个上下文管理的操作
with open(r'D:\text.txt') as f:
print(f.read())
5 # with语句以及上下文管理的核心概念
"""
说一千道一万就是说,在with中,有__enter__和__exit__方法,有这两个方法就可以实现资源的开启和释放
我们在其中操作,在外部我们的操作就会实现,我们在写方法函数的时候,也可以采用这种方式
在with中也是这样的原理
在总结一句话就是,我这个圈里面符合我的规则,圈外失效,外面太乱,圈里面躲躲:)
"""
8手撸一个自己的with方法
class MyResource:
def __enter__(self):
print('connection to resource')
return self # __enter__返回的是类本身
def __exit__(self, exc_type, exc_val, exc_tb):
# with内部没有错误,就是能正常关闭的时候,__exit__后面的三个参数是为None的
print(exc_type,exc_val,exc_tb)
if exc_tb: # 当exc_tb有值的时候,代表with内部出错了
print('process exception')
else:
print('no exception')
print('close resource connection')
def query(self):
print('query data')
with MyResource() as resource:
# 1/0
resource.query()
# with使用说明
"""
在with这种python中的高级用法中,还是要强调的一点就是,我们先执行__enter__方法,返回类本身,目的是开始
然后执行with下面的代码
最后执行__exit__方法,当with下面代码出现问题的时候,__exit__后面的参数会被赋值,我们通过判断参数的值来判断是否发生错误,从而达到捕捉错误的目的
__exit__返回True表示上下文中没有错误,返回False表示有错误
"""
在看过了with上下文管理之后,我们可以来更改db.create_all()的编码方式
# 之前的写法
db.init_app(app)
db.create_all(app=app)
# 现在我们使用上下文管理
with app.app_context(): # 这里面有app,下面方法就不用调用了
db.create_all()
四:Flask中的多线程与线程隔离技术
1 进程
进程是计算机上的资源单位,是用来分配,管理资源的
因为计算机上的资源是非常的稀缺,所以我们的应用程序在开启过程中都是不断地取抢夺计算机的资源(我们的每一个应用程序至少是一个进程),进程是竞争计算机资源的基本单位
单核的CPU永远只能执行一个应用程序吗?
这个问题问的不严谨,应该说单核的CPU同一时刻只能运行一个应用程序,但是我们的cpu是在不用的应用程序之前切换运转的,也就是我么说的并发,看起来是同时运行 的,但结果确实切换的速度快,所以我们不好察觉出来
这就牵扯到一个概念,叫做进程调度,里面使用某种算法实现进程的切换,但是在切换进程的过程中我们的开销也是很大的,也就是使用我们的上下文来进行调度
2 线程
上下文切换是为了保存当前程序相关的状态
线程是CPU上的执行单元,那么线程间的切换的资源消耗也是远小于进程间上下文之间的切换的
我们线程负责将指令交给CPU执行
线程属于进程,访问进程资源
3 多线程
一个进程可以开多个线程,就更能提升计算机的CPU的性能优势
import threading
def worker():
print('i am a thread')
print(get_current_thread_name())
def get_current_thread_name():
t = threading.current_thread()
return t.getName()
print(get_current_thread_name())
new_t = threading.Thread(target=worker)
new_t.start()
# 还可以更改线程的名字
new_t = threading.Thread(target=worker,name='andy_thread')
new_t.start()
多线程的好处
可以更充分利用cpu的资源,这些都是建立在单核CPU的基础上
多线程的其他特性
一般我们的cpu都是多核,但是Cpython无法利用多核优势。
4GIL
GIL 全局解释器锁
在多线程中,为了保证线程安全,就是说线程之间的资源安全,我们要加锁
锁:
细粒度锁 开发人员主动添加的
粗粒度锁 GIL Cpython解释器保证就是不管多少核,同一时刻也只有一个线程执行,一定程度保证线程安全
python解释器
Cpython,jpython
多线程
线程通信技术
5 IO/CPU密集型
由于Cpython解释器,我们的线程无法利用多核优势,那么我们的多线程是不是就没有意义了呢?
其实不是的,还要分两种情况
1 CPU密集型
cpu密集型又叫计算密集型,非常依赖CPU的计算,
一段时间内计算的部分比较多,这个时候我们Cpython的解释器显得捉襟见肘了
2 IO密集型
IO密集型,就是我们常见的查询数据库,查询网络资源,读写文件
因为这些操作中间都会出现等待时间,Cpython解释器就是跳到下一个线程去执行操作
这样我们的多线程的优势就会显示出来了,效率就会高
所以,对于一段时间内IO操作较多的程序代码,我们可以取使用多线程来提高效率
flask开启多线程和多进程
app.run(threaded=True,processes=3) # 表示开启多线程,多进程数为3
6 线程隔离
# 概念
使用线程隔离的目的是使当前线程能够正确的引用到自己所创建的对象
而不是引用到其他线程所创建的对象
# 原理
就像我们的字典保存数据
{thread_id1:value1, thread_id2:value2,...}
每一个字典的value之间的数据是隔离的
用werkzeug演示flask线程隔离
import time
__author__ = '欧阳'
from werkzeug.local import Local
from threading import Thread
obj = Local()
obj.b = 1
def work_obj():
obj.b = 2
print(f'this new thread is {obj.b}')
t = Thread(target=work_obj)
t.start()
time.sleep(1)
print(f'main thread is {obj.b}')
# 总结:Local中有__setattr__实现线程隔离,也就解释了为什么多用户操作不会出现问题的原因
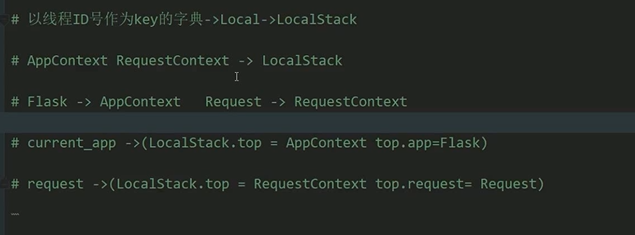
localstack,local,字典的区别
local:使用字典的方式实现的线程隔离
localstack:封装local的线程隔离的栈结构
localstack的用法
from werkzeug.local import LocalStack
s = LocalStack()
"""
栈的读写数据的规则是后进先出
s.push(1) 往栈中写入数据
s.top 取栈顶的数据
s.pop pop掉栈顶的数据
"""
s.push(1)
print(s.top)
print(s.top)
print(s.pop())
print(s.top)
s.push(2)
s.push(3)
print(s.top)
localstack中使用多线程
import time
__author__ = '欧阳'
from werkzeug.local import LocalStack
from threading import Thread
my_stack = LocalStack()
my_stack.push(1)
print(f'in main thread after push,value is {str(my_stack.top)}')
def worker():
print(f'in new thread after push,value is {str(my_stack.top)}')
my_stack.push(2)
print(f'in new thread after push,value is {str(my_stack.top)}')
t = Thread(target=worker)
t.start()
time.sleep(1)
print(f'finally,in main thread after push,value is {str(my_stack.top)}')
# 打印结果是
"""
in main thread after push,value is 1
in new thread after push,value is None
in new thread after push,value is 2
finally,in main thread after push,value is 1
"""
五:ViewModel、面向对象与重构
1 ViewModel简介
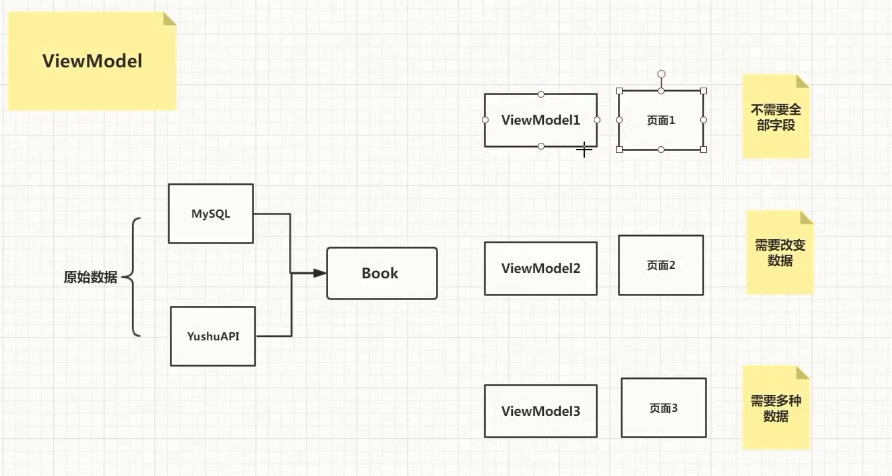
#ViewModel概念
"""
ViewModel不是原始数据,可能会根据我们的页面的业务需求,
对这些原始数据做一系列的改变,让我们最终传向页面的数据符合我们页面的数据要求
"""
# ViewModel的作用
"""
1 裁剪
2 修饰
3 合并
"""
2 使用ViewModel处理数据
新建一个view_models文件夹,创建一个book.py文件
# view_models/book.py
class BookViewModel:
@classmethod
def package_single(cls, data, keyword):
"""处理使用isbn查询的数据"""
returned = {
'book': [],
'total': 0,
'keyword': keyword
}
if data:
returned['total'] = 1
returned['book'] = [cls.__cut_book_data(data)]
return returned
@classmethod
def package_collection(cls, data, keyword):
"""处理使用关键字参数查询的数据"""
returned = {
'book': [],
'total': 0,
'keyword': keyword
}
if data:
returned['book'] = [cls.__cut_book_data(book) for book in data['books']]
returned['total'] = data['total']
return returned
@classmethod
def __cut_book_data(cls, data):
"""处理查询的数据"""
book = {
'title': data['title'],
'publisher': data['publisher'],
'pages': data['pages'] or '',
'author': '、'.join(data['author']),
'price': data['price'],
'summary': data['summary'] or '',
'image': data['image']
}
return book
在视图函数中,把两种api传过来的数据传给BookViewModel过滤之后,返回的数据就一致了
3 真实的面向对象
我们就拿上面的四个文件来展开说明
code 1
# models/book.py
from wtforms import Form,StringField,IntegerField
from wtforms.validators import length,NumberRange,DataRequired
class SearchForm(Form):
q = StringField(validators=[DataRequired(),length=(min=2.max=40,message='参数错误')])
page = IntegerField(validators = [NumberRange(min=3,max=90)],default=1)
code 2
# spider/yushu_book.py
from app.lib.http import HTTP
from flask import current_app
class YuShuBook:
isbn_url = 'http://t.yushu.im/v2/book/isbn/{}'
keyword = 'http://t.yushu.im/v2/book/search?q={}&count={}&start={}'
def __init__(self):
self.total = 0
self.book = []
def search_by_isbn(self, isbn):
url = self.isbn_url.format(isbn)
result = HTTP.get(url)
self.__fill_single(result)
def search_by_keyword(self, keyword, page=1):
url = self.keyword.format(keyword, current_app.config['PER_PAGE'], self.calculate_start(page))
result = HTTP.get(url)
self.__fill_collection(result)
def __fill_single(self, data):
"""isdn搜索,data是一个字典"""
self.total = 1
self.book.append(data)
def __fill_collection(self, data):
"""关键字搜索,是{‘books’:[]},取books"""
self.total = data['total']
self.book = data['books']
def calculate_start(self, page):
return (page - 1) * current_app.config['PER_PAGE']
code 3
# view_models/book.py
class BookViewModel:
def __init__(self, book):
self.title = book['title'],
self.publisher = book['publisher'],
self.pages = book['pages'] or '',
self.author = '、'.join(book['author']),
self.price = book['price'],
self.summary = book['summary'] or '',
self.image = book['image']
class BookCollection:
def __init__(self):
self.total = 0
self.keyword = ''
self.books = []
def fill(self, yushu_book, keyword):
self.total = yushu_book.total
self.keyword = keyword
self.books = [BookViewModel(book) for book in yushu_book.book]
code 4
import json
from flask import jsonify, request
from app.forms.book import SearchForm
from app.libs.helper import is_isbn_or_key
from app.spider.yushu_book import YuShuBook
from . import web
from app.view_models.book import BookViewModel, BookCollection
@web.route('/book/search')
def search():
form = SearchForm(request.args)
if form.validate():
q = form.q.data.strip()
page = form.page.data
books = BookCollection() # ViewModels对象
isbn_or_key = is_isbn_or_key(q) # 判断参数是isbn还是关键字
yushu_book = YuShuBook() # 实例化从鱼书API拿过来的数据
if isbn_or_key is 'isbn':
yushu_book.search_by_isbn(q)
else:
yushu_book.search_by_keyword(q, page)
books.fill(yushu_book, q)
# 使用__dict__可以把对象中的方法转化成json格式的,采用下面的方法无论是属性,还是对象都可以序列化
return json.dumps(books, default=lambda x: x.__dict__)
# return jsonify(books)
else:
return jsonify(form.errors)
# return json.dumps(result), 200, {'content-type': 'application/json'}
六:静态文件、模板、消息闪现与Jinja2
1 静态文件访问原理
(1)使用默认的static设置
我们使用flask静态文件的时候,直接再flask核心对象的根目录下创建一个叫做static的文件夹
这样,我们再浏览器上直接输入 http://localhost:8001/static/test.jpg就可以访问我们的静态文件
(2) 在flask核心对象上设置我们自己的静态文件目录
在我们的app核心对象上
def create_app():
app = Flask(__name__,static_folder='spider/statics',static_url_path='/statics')
app.config.from_object('app.secure')
app.config.from_object('app.settings')
# 注:static_folder就是我们静态文件存放的文件夹,static_url_path就是我们在访问静态文件的时候路由上的关键字
# 比如根据上面设置的我们应该访问 http://localhost:8001/statics/test.jpg
(3)在蓝图上设置我们的静态文件目录
在蓝图文件上
from flask import Blueprint
web = Blueprint('web', __name__,static_folder='spider/statics',static_url_path='/statics')
from app.web import web # 导入web,从而使蓝图生效
# 注:static_folder就是我们静态文件存放的文件夹,static_url_path就是我们在访问静态文件的时候路由上的关键字
# 比如根据上面设置的我们应该访问 http://localhost:8001/statics/test.jpg
2 模板文件的位置与修改方案
# 我们可以使用flask默认的模板文件夹路基,就是在app的核心对象同级文件夹下创建templates文件夹
# 还可以在flask核心对象上修改模板的路径
app = Flask(__name__,template_folder='web/templates')
# 同样还可以在蓝图上卖弄修改模板的路径
web = BluePrint('web',__name__,template_folder='templates')
# 在蓝图对象中因为模板文件夹跟蓝图同级,所以只需要添加相对路径即可
# 如何使用模板文件
from flask import render_template
@web.route('/test')
def test():
r = {
"name": "andy",
"age": 18
}
return render_template('test.html', data=r)
3 在jinjia2中读取字典和对象
@web.route('/test')
def test():
r = {
"name": "andy",
"age": 18
}
class A:
addr = '同住地球村'
# 将字典肯对象传到模板文件中
return render_template('test.html', data=r, data1=A)
jinjia2语法既可以读取字典数据,也可以读取对象中的数据
不管是字典还是对象,都可以用点的方式读取,也可以用中括号的方式读取
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1>this is andy html</h1>
{#字典#}
{{ data.name }}
{{ data['age'] }}
{#对象#}
{{ data1.addr }}
{{ data1['phone_number'] }}
</body>
</html>
注: 在html文件,jinjia2语法中,{# #}是注释的意思
4 流程控制语句
if
{% if data.age < 18 %}
{{ data.name }}
{% elif data.age == 18 %}
年龄是{{ data.age }}
{% else %}
{{ data.age }}
{% endif %}
for in 循环
循环一个列表
{% for foo in [1,2,3] %}
{{ foo }}
{% endfor %}
循环一个字典
{% for key,value in data.items() %}
{{ key }}
{{ value }}
{% endfor %}
5 使用模板继承
母版
使用block
{#layout.html #}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
{% block head %}
<div>this is head</div>
{% endblock %}
{% block content %}
<div>this is content</div>
{% endblock %}
{% block foot %}
<div>this is foot</div>
{% endblock %}
</body>
</html>
子板(类似于python面向对象的继承)
{#test.html #}
{% extends 'layout.html' %}
{% block content %}
{{ super() }}
<h1>this is andy html</h1>
{#字典#}
{{ data.name }}
{{ data['age'] }}
{# 对象#}
{{ data1.addr }}
{{ data1['phone_number'] }}
{% if data.age < 18 %}
{{ data.name }}
{% elif data.age == 18 %}
年龄是{{ data.age }}
{% else %}
{{ data.age }}
{% endif %}
{% endblock %}
注意:加上{{super()}}会继承母版的特性,不加会覆盖
6 过滤器与管道命令
过滤器
default
{% extends 'layout.html' %}
{% block content %}
{{ super() }}
{{ data.age }}
{{ data['age'] }}
{% if data.age < 18 %}
{{ data.name }}
{% elif data.age == 18 %}
{{ data.school | default('不存在') }} {# 访问不存在的变量,default才会生效 #}
{% else %}
{{ data.age }}
{% endif %}
{% endblock %}
如果想data.school=None时,default也生效, 使用default('不存在', true) (加上一个true参数)
length
{% extends 'layout.html' %}
{% block content %}
{{ super() }}
{{ data.age }}
{{ data['age'] }}
{% if data.age < 18 %}
{{ data.name }}
{% elif data.age == 18 %}
{{ data | length() }} {# 得到data的长度 #}
{% else %}
{{ data.age }}
{% endif %}
{% endblock %}
更多的过滤使用方法,可以去
jinja.palletsprojects.com/en/2.10.x/t…
7 反向构建URL
以前注册视图函数的时候, 有个endpoint参数,我们并没有说它的作用。endpoint其实是用来反向获取url的。
新建app/static/test.css, 现在我想让app/templates/layout.html去加载test.css:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<link rel="stylesheet" href="{{ url_for('static', filename='test.css') }}">
{# url_for的使用方法 第一个参数是endpoint #}
{# <link rel="stylesheet" href="/static/test.css">#}
</head>
<body>
{% block head %}
<div>this is head</div>
{% endblock %}
{% block content %}
<div>this is content</div>
{% endblock %}
{% block foot %}
<div>this is foot</div>
{% endblock %}
</body>
</html>
flask中能用url_for的, 尽量都用url_for
8 消息闪现、SecretKey与变量作用域with
消息闪现 Messageing Flash
我们在app/web/book.py修改test视图函数:
from flask import flash
@web.route('/test')
def test():
r = {
'name': None,
'age': 18
}
flash('hello, cannon') # 使用flash
return render_template('test.html', data=r)
对app/templats/test.html做修改:
{% extends 'layout.html' %}
{% block content %}
{{ super() }}
{% if data.age < 18 %}
{{ data.name }}
{% elif data.age == 18 %}
{{ data | length() }}
{% set messages = get_flashed_messages() %} {# 对应的使用get_flashed_messages #}
{{ messages }}
{% else %}
{{ data.age }}
{% endif %}
{% endblock %}
消息闪现使用到了 session, 我们需要在配置文件secure.py添加secretkey:
在secure.py文件下配置
SECRET_KEY = 'wjdiajsjkskcnndijqwiodjieijqijwiwqijfbryguhtrvwpqwqdnxjj'
category参数的使用
修改app/web/book.py的test视图函数, 加入category参数:
@web.route('/test')
def test():
r = {
"name": "andy",
"age": 18
}
class A:
addr = '同住地球村'
phone_number = '11111111'
flash('hi andy',category='error')
flash('hi xiaohui',category='worning')
return render_template('test.html', data=r, data1=A)
在模板中
{% set messages = get_flashed_messages(category_filter=['error']) %}
{# category参数对应使用category_filter #}
{{ messages }}
这样 只会显示 category为error的flash传递的数据
with缩小变量的作用域
在jinjia2中使用with,如上段代码,将set替换成with
{% with messages = get_flashed_messages(category_filter='error') %}
{{ messages }}
{% endwith %}
这样的话,messages的作用域在with 和endwith里面,出去就是就会找不到
七:用户登录注册
1 viewmodel意义的体现与filter函数的巧妙应用
在搜索书籍页面里,需要将每一条结果的作者,出版社,价格在一行展示,并以”/“分割。由于这三个属性还有可能为空,所以在html模板里处理不太方便。我们选择将这些数据处理的工作放在viewmodel中。
简单粗暴一点的方法是写一段 if-else 代码,将这三个属性以及可能为空的情况全都穷举出来,但是python给我们提供了更优雅的解决方式,就是使用filter过滤器+lambda表达式
class BookViewModel:
def __init__(self, book):
self.title = book['title']
self.publisher = book['publisher']
self.pages = book['pages'] or ''
self.author = '、'.join(book['author'])
self.price = book['price']
self.summary = book['summary'] or ''
self.image = book['image']
# @property可以将一个函数当作属性来使用
@property
def intro(self):
intro = filter(lambda x: True if x else False, [self.author, self.publisher, self.price])
return '/'.join(intro)
2 书籍详情页面
业务逻辑梳理
1 书籍详情页面,首先应该展示数据详情信息
2 数据详情页面应该有加入心愿清单和赠送此书功能
3 书籍详情页面默认展示想要赠送此书的人,并且可以向他们索要图书
4 如果用户点击了赠送此书,它就成为了一个赠书人,书记详情页面就会展示想要此书的人
编写思路
-
书籍详情页面接受一个isbn作为参数,直接访问我们之前编写的yushu_book的search_by_isbn函数即可。这需要我们在之前的BookViewModel中加入isbn属性
-
search_by_isbn返回的原始数据不应该直接返回,而应该经过裁剪加工,这里也可以复用我们之前写的BookViewModel。
-
BookViewModel需要接受一个book对象,由于search_by_isbn只会返回只有一个对象的列表,所以我们返回结果的第一个元素即可
-
但是yushu_book.books[0]的写法并不是很好的编程规范,我们之所以可以这么写是因为我们清楚的内部结构,但是我们写的代码不一定是给我们自己用,给被人用的时候要让被人清晰易懂,所以这里,我们在yushu_book加入一个first函数返回第一个对象。
实现代码
# web/book.py
@web.route('/book/<isbn>/detail')
def book_detail(isbn):
yushu_book = YuShuBook()
yushu_book.search_by_isbn(isbn)
book = BookViewModel(yushu_book.first)
return render_template('book_detail.html', book=book, wishes=[], gifts=[])
# view_models/book.py
class BookViewModel:
def __init__(self, data):
self.title = data['title']
self.author = '、'.join(data['author'])
self.binding = data['binding']
self.publisher = data['publisher']
self.image = data['image']
self.price = '¥' + data['price'] if data['price'] else data['price']
self.isbn = data['isbn'] # 添加了self.isbn属性
self.pubdate = data['pubdate']
self.summary = data['summary']
self.pages = data['pages']
@property
def intro(self):
intro = filter(lambda x: True if x else False, [self.author, self.publisher, self.price])
return '/'.join(intro)
# yushu_book.py
@property
def first(self):
return self.book[0] if self.total >= 1 else None
分析业务逻辑,用户赠送书籍,需要将用户赠送书籍的数据保存到数据库中。为此我们需要建立业务模型,并通过codeFirst的原则,反向生成数据库表
3 模型与模型关系
-
首先我们需要一个用户User模型,来存储用户信息
-
其次我们需要一个Book模型,来存储书籍的信息
-
我们还需要一个Gift模型,来存储哪个用户想要赠送哪本书。从数据库的角度来看,用户和书籍是多对多的关系,多对多的关系需要第三章表。
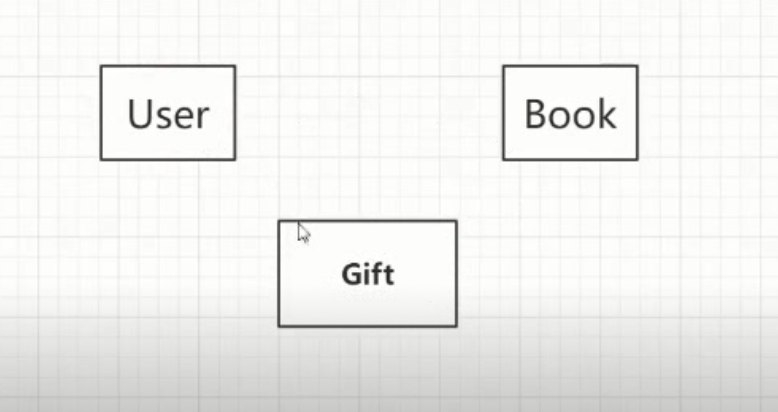
编写建立模型代码
# models/user.py
from sqlalchemy import Column
from sqlalchemy import Integer, Float
from sqlalchemy import String, Boolean
from app.models.base import db
class User(db.Model):
id = Column(Integer, primary_key=True)
nickname = Column(String(24), nullable=False)
phone_number = Column(String(18), unique=True)
email = Column(String(50), unique=True, nullable=False)
confirmed = Column(Boolean, default=False)
beans = Column(Float, default=0)
send_counter = Column(Integer, default=0)
receive_counter = Column(Integer, default=0)
wx_open_id = Column(String(50))
wx_name = Column(String(32))
# models/gift.py
from app.models.base import db
from sqlalchemy import Column, String, Integer, ForeignKey, Boolean
from sqlalchemy.orm import relationships
__author__ = "gaowenfeng"
class Gift(db.Model):
id = Column(Integer, primary_key=True, autoincrement=True)
# relationships表示管理关系
user = relationships('User')
# ForeignKey定义外键约束
uid = Column(Integer, ForeignKey('user.id'))
# 书籍我们记录isbn编号,因为书籍信息是从网络获取的
isbn = Column(String(15),nullable=True)
# 是否已经赠送出去
launched = Column(Boolean, default=False)
自定义基类模型
- 每个表的信息,在删除的时候都不应该物理的从数据库里删除,而应该设置一个标志位,默认为0,如果删除了则置为1,这样可以搜索到历史的用户记录。
- 像标志位这样的参数,每个表里都有同样的属性,我们应该建立一个基类,来存储这些共有属性
# models/base.py
from flask_sqlalchemy import SQLAlchemy
from sqlalchemy import SmallInteger, Column
__author__ = "gaowenfeng"
db = SQLAlchemy()
class Base(db.Model):
__abstract__ = True
status = Column(SmallInteger, default=1)
奔腾T77
奇瑞瑞虎8
4 用户注册
- 视图函数中,兼容get请求和post请求
- 做表单验证的时候,将验证后的数据赋值到User模型里,由于User继承Base,再Base中写一个set_attrs方法,统一将属性拷贝复制,动态赋值
- 验证器中还应该加入业务逻辑的判断,如邮箱,昵称不能重复等,都已‘validate_’开头,跟上要验证的字段
- 查询数据库的时候使用filter_by
- 再涉及到数据库密码操作的时候,我们要使用到@property,就是属性方法来进行操作
- 使用db.session.add(user),和db.session.commit()来想数据库提交数据
- 如果登录成功,页面将重定向到登录页面
视图函数,可以接受get请求和post请求,只需要再methods中添加请求
再向数据库中写入数据的时候,使用db.session的方法来实现
# web\auth.py
from app.models.base import db
from . import web
from app.forms.auth import RegisterForm
from flask import request, render_template
from app.models.user import User
@web.route('/register', methods=['GET', 'POST'])
def register():
form = RegisterForm(request.form)
if request.method == 'POST' and form.validate():
user = User()
print(form.data)
user.set_attrs(form.data)
print(user.__dict__)
db.session.add(user)
db.session.commit()
return render_template('auth/register.html', form={'data': {}})
再校验数据的时候,我们想要对某些字段实现自定义校验,就使用validate_后面加上需要校验字段的名字
# forms\auth.py
from wtforms import Form, StringField, IntegerField
from wtforms.validators import length, Email, ValidationError, DataRequired
from app.models.user import User
__author__ = '欧阳'
class RegisterForm(Form):
email = StringField(validators=[DataRequired(), length(8, 64), Email(message='电子邮箱不符合规范')])
password = StringField(validators=[DataRequired(message='密码不可为空,请输入您的密码'), length(6, 32)])
nickname = StringField('昵称', validators=[DataRequired(), length(2, 10, message='昵称至少两个字符,最多是个字符')])
def validate_email(self, field):
if User.query.filter_by(email=field.data).first(): # orm,first出发操作
raise ValidationError('该邮箱已被注册')
def validate_nickname(self, field):
if User.query.filter_by(nickname=field.data).first():
raise ValidationError('还用户名已被使用,请更换')
Base作为所有表的基类,我们可以将id和status定义在里面,因为所有的表都需要id,stauts就是状态,我们删除某些数据的时候当然不能将他真的删除,就实现软删除,还有的就是为了防止Base也做当作表去在数据库生成,我们再上面加上__abstract__=True
# models\base.py
from flask_sqlalchemy import SQLAlchemy
from sqlalchemy import SmallInteger, Column, Integer
db = SQLAlchemy()
__author__ = '欧阳'
class Base(db.Model):
__abstract__ = True # 这样定义基类,再同步数据库表的时候就不会同步这个表,类似于忽略处理
id = Column(Integer, primary_key=True)
status = Column(SmallInteger, default=1)
def set_attrs(self, attrs_dict):
for key, value in attrs_dict.items():
if setattr(self, key, value) and key != 'id':
setattr(self, key, value)
User表,这要说的是密码这个字段,我们使用@property将函数变成属性
将其所装饰的函数命名为password
@password.setattr就是设置password的值
# models\user.py
from werkzeug.security import generate_password_hash
from sqlalchemy import Column
from sqlalchemy import String, Integer, Float, Boolean
from app.models.base import Base
__author__ = '欧阳'
class User(Base):
nickname = Column(String(24), nullable=False)
phone_number = Column(String(11), unique=True)
email = Column(String(50), unique=True, nullable=False)
_password = Column('password', String(128)) # 括号内添加的字符串就是指定字段的名字,不使用默认的名字
confirmed = Column(Boolean, default=False)
beans = Column(Float, default=0)
send_counter = Column(Integer, default=0)
receive_counter = Column(Integer, default=0)
wx_open_id = Column(String(50))
wx_name = Column(String(32))
@property
def password(self):
return self._password
@password.setter
def password(self, raw):
self._password = generate_password_hash(raw)
实现重定向
# 在视图函数中导入refirct和url_for
from flask import redirect,url_for
@web.route('/register', methods=['GET', 'POST'])
def register():
form = RegisterForm(request.form)
if request.method == 'POST' and form.validate():
user = User()
print(form.data)
user.set_attrs(form.data)
print(user.__dict__)
db.session.add(user)
db.session.commit()
return redirect(url_for('web.login')) # 实现重定向
return render_template('auth/register.html', form={'data': {}})
5 用户登录
在登录的过程中
- 对用户输入的用户名和密码进行校验,查询用户名受否存在
- 先把密码进行加密处理,和数据库里面的密码进行对比,然会True或者False
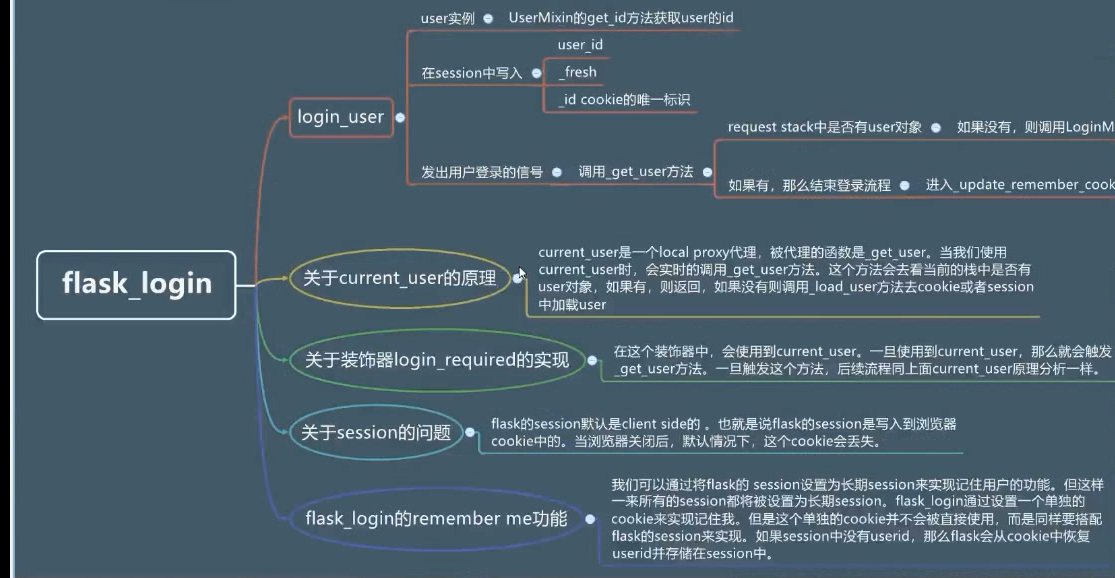
- 我们需要生成cookie,使用flask_login实现
login_user将用户信息写入cookie
1 先导入flask_login---pip install flask-login -i https://pypi.doubanio.com/simple
2 在flask核心对象文件中注册flask_login
from flask_login import LoginManager
login_manager = LoginManager()
def create_app():
...
login_manager.init_app(app)
...
3 在model中导入UserMixin,让User继承
# UserMinxin的作用就是获取创建令牌的关键字段,比如get_id
from flask_login import UserMixin
class User(UserMixin, Base):
4 使用
# 在登录的视图函数中
from flask_login import login_user
@web.route('/login', methods=['GET', 'POST'])
def login():
form = LoginForm(request.form)
if request.method == 'POST' and form.validate(): # 如果请求为post而且通过form验证
user = User.query.filter_by(email=form.email.data).first()
if user and user.check_password(form.password.data):
login_user(user)
pass
else:
flash('账号或密码错误')
return render_template('auth/login.html', form=form)
login_user方法并不是把user内的搜索属性全都写入cookie,login_user需要我们为user类定义几个方法,如get_id用来获取id。如果我们把他定义的方法全都编写出来,太多了,我们可以集成他提供给我们的UserMixin类,如果和他的默认配置不同,复写他的方法即可

6 权限控制
上面实现了用户的注册,使用的使flask_login这个第三方的模块
现在做权限控制也要使用这个flask_login
# 在models/user.py中
# 就在该文件下定义一个方法
from app import login_manager
@login_manager.user_loader
def get_user(uid):
return User.query.get(int(uid))
# 在需要登录才能操作的视图函数中
from flask_login import login_required
# 在视图函数的上方加上之后,就限制了该视图函数只有在登录之后才能访问
@login_required
- 在需要限制登录才能访问的试图函数上,加入@login_required装饰器
@web.route('/my/gifts')
@login_required
def my_gifts():
return "my gifts"
- 在User模型里,编写get_user 方法用来根据id查询用户,并加入@login_manager.user_loader 装饰器(login_manager是从app/init.py中导入)
@login_manager.user_loader
def get_user(self, uid):
# 如果是根据主键查询,不要filter_by,使用get方法即可
return User.query.get(int(uid))
- 在app/init.py中,配置未登录时调整到的页面和提示消息
login_manager.login_view = 'web.login'
login_manager.login_message = '请先登录或注册'
- 登录成功以后,重定向到next页面;如果没有next页面,则跳转到首页;为了防止重定向攻击,应该判断next是否"/"开头
@web.route('/login', methods=['GET', 'POST'])
def login():
form = LoginForm(request.form)
if request.method == 'POST' and form.validate(): # 如果请求为post而且通过form验证
user = User.query.filter_by(email=form.email.data).first()
if user and user.check_password(form.password.data):
# 使用flask_login 的user_login间接的写入cookie
# 但是这样产生的cookie一关掉浏览器就会消失,这个时候我们设置一个remeber=True
login_user(user, remember=True)
next = request.args.get('next') # 获取url中的next
if not next or not next.startswith('/'): # 如果没有或者没有以/开头
next = url_for('web.index') # 只是登录,那就跳转到首页
return redirect(next)
else:
flash('账号或密码错误')
return render_template('auth/login.html', form=form)
八:书籍交易模型(数据库事务、重写Flask中的对象)
1 鱼豆-虚拟货币
- 在赠送书籍的时候,虚拟货币增加,需要记录赠书人的id和书籍的isbn
- 还记得在User模型下面
from app import login_manager
@login_manager.user_loader
def get_user(uid):
return User.query.get(int(uid))
# 使用
from flask_login import current_user
- 我们导入from flask_login import current_user,这个current_user就是User模型
2 current_user的使用
# web/gift.py
from flask_login import login_required,current_user # 验证权限和当前User对象
from app。models.gift import Gift
@web.route('gifts/book/<isbn>')
@login_required
def save_to_gifts(isbn):
if current_user.can_save_to_list(isbn):
gift = Gift()
gift.isbn = isbn
gift.uid = current_user.id
# 就是在配置文件里面配置之后添加到User对象
current_user += current_user.config['BEANS_UPLOAD_ONE_BOOK']
db.session.add(gift)
db.session.connit()
else:
flash('该书已经存在赠送清单或者心愿清单中,请勿重复添加')
# models/user.py
class User(Base):
...
def can_save_to_list(self, isbn):
"""
判断参数是否使isbn类型的
判断数据是否存在
不允许一个用户同时赠送多本相同的图书
一个用户不可能同时成为赠送者和索要者
就是既不在赠送清单,却不在心愿清单的才能添加
:param isbn:
:return:
"""
if is_isbn_or_key(isbn) != 'isbn':
return False
yushu_book = YuShuBook()
yushu_book.search_by_isbn(isbn)
if not yushu_book.first: # 判断数据是否存在
return False
gifting = Gift.query.filter_by(uid=self.id, isbn=isbn, launched=False).first()
wishing = Wish.query.filter_by(uid=self.id, isbn=isbn, launched=False).first()
if not gifting and not wishing:
return False
else:
return True
3 事务与回滚
在使用orm往数据库中写入数据的时候,涉及到是事务与回滚,那怎么实现呢
@web.route('gifts/book/<isbn>')
@login_required
def save_to_gifts(isbn):
if current_user.can_save_to_list(isbn):
try:
gift = Gift()
gift.isbn = isbn
gift.uid = current_user.id
# 就是在配置文件里面配置之后添加到User对象
current_user += current_user.config['BEANS_UPLOAD_ONE_BOOK']
db.session.add(gift)
db.session.connit()
execpt Exception as e:
db.session.rollback() # 如果发生过去,就回滚
raise e
else:
flash('该书已经存在赠送清单或者心愿清单中,请勿重复添加')
4 Python @contextmanager
- 把原来不是上下文管理的类变成上下文管理
- yield 是生成器,可以返回数据也可以不反悔,不返回的时候直接写yield
- 使用with的时候不返回数据 不写as r
我们使用with的时候是这样的
这里使用yield返回数据,yield就是生成器,运行生成器返回后的数据之后,才会接着运行下面的代码
class MyResource:
# def __enter__(self):
# print('this is enter')
#
# def __exit__(self, exc_type, exc_val, exc_tb):
# print('this is exit')
def query(self):
print('query data')
from contextlib import contextmanager
@contextmanager
def my_resource():
print('this is enter')
yield MyResource()
print('this is exit')
with my_resource() as r:
r.query()
"""
运行结果
this is enter
query data
this is exit
"""
@contextmanager的另外一种用法
# 我需要将书名加上《》
from contextlib import contextmanager
@contextmanager
def book_mark():
print('《',end='')
yield
print('》',end='')
with book_mark():
print('且将生活一饮而尽',end='')
"""
打印结果
《且将生活一饮而尽》
"""
5 使用@contextmanager来改写数据库写入方法
-
实现了使用上下文改写数据库写入
-
写入数据发生错误时,实现数据库的事务和回滚
# models/base.py
from flask_sqlalchemy import SQLAlchemy as _SQLAlchemy
class SQLAlchemy(_SQLAlchemy):
@contextmanager
def auto_commit(self):
try:
yield
self.session.commit()
except Exception as e:
self.session.rollback()
raise e
db = SQLALchemy()
# 使用的时候
with db.auto_commit():
# 就不用写db.session.commit()了
6 类变量相关知识
在我们在基类中定义一个create_time的时候,想要给这个属性赋值
class Base(db.Model):
__abstract__ = True # 这样定义基类,再同步数据库表的时候就不会同步这个表,类似于忽略处理
id = Column(Integer, primary_key=True)
status = Column(SmallInteger, default=1)
create_time = Column('create_time', Integer)
def __init__(self):
self.create_time = int(datetime.now().timestamp())
# 赋值的时候,要使用构造函数来赋值,不能直接default赋值
# 因为default赋值,所有的create_time就都是程序运行时候的时间
7 书籍交易视图模型
书籍详情页,除了需要显示书籍详情信息外。还应该显示其他信息,这些信息分为三类 1.默认情况下,显示想要赠送这本书的人的列表,包括名字和上传时间。 2.如果当前用户是此书的赠送者,应该显示索要这本书的人的列表。 3.如果当前用户是此书的索要者,应该显示想要赠送这本书的人的列表。
这样的话我们需要直达书记索要这和书籍捐赠者的信息
trade_gifts = Gift.query.filter_by(isbn=isbn, launched=False).all()
trade_wishs = Wish.query.filter_by(isbn=isbn, launched=False).all()
这个时候需要写一个view_model来处理这些数据
# view_models/trade.py
class TradeInfo:
def __init__(self, goods):
self.total = 0
self.trades = []
self.__parse(goods)
def __parse(self, goods):
self.total = len(goods)
self.trades = [self.__map_to_trade(single) for single in goods]
def __map_to_trade(self, single):
if single.create_datetime:
single_time = single.create_datetime.strftime('%Y-%m-%d')
else:
single_time = '未知'
return dict(
user_name=single.user.nickname,
create_time=single_time,
id=single.id
)
由于craete_time我们是存储的时间戳,这个时候需要将时间戳转换成标准时间格式
# models/base.py
class Base(db.Model):
...
@property
def create_datetime(self):
if self.create_time:
return datetime.fromtimestamp(self.create_time)
else:
return None
8 重写filter_by
由于我们的删除操作都是逻辑删除,所以在查询的时候应该默认查询status=1的记录(即未删除的记录),但是如果在每一个filter_by里都这么写,就太麻烦了,我们的思路是重写默认的filter_by函数,加上status=1的限制条件。
那么我们就需要先了解原来SQLAlchemy的继承关系 Flask的SQLAlchemy中有一个BaseQuery,BaseQuery继承了orm.Query(原SQLAlchemy的类),这里面有filter_by函数;也就是说BaseQuery通过继承orm.Query拥有了filter_by的能力
flask_sqlalchemy
...
...
class SQLAlchemy(object):
Query = None
def __init__(self, app=None, use_native_unicode=True, session_options=None,
metadata=None, query_class=BaseQuery, model_class=Model):
...
...
class BaseQuery(orm.Query):
...
...
orm.Query
def filter_by(self, **kwargs):
# for循环拼接关键字参数查询条件
clauses = [_entity_descriptor(self._joinpoint_zero(), key) == value
for key, value in kwargs.items()]
return self.filter(sql.and_(*clauses))
所以如果我们要重写filter_by,需要自己编写子类,继承BaseQuery,重写filter_by函数,将status=1加入到kwargs
class Query(BaseQuery):
def filter_by(self, **kwargs):
if 'status' not in kwargs:
kwargs['status'] = 1
return super(Query, self).filter_by(**kwargs)
最后,Flask的SQLAlchemy给了我们一种方法,让我们应用自己的Query类,即在实例化的时候传入关键字参数query_class
db = SQLAlchemy(query_class=Query)
九:鱼书业务处理
1 最近的礼物(复杂SQL的编写方案)
业务处理中,首页会显示最新赠送书籍的列表,有三个限制条件
- 只显示30条数据
- 书籍数据按照时间倒叙排列
- 去重
根据上述条件查询赠送清单
# models\gift.py
class Gift(Base):
...
@classmethod
def recent(cls):
recent_gift = Gift.query.filter_by(
launched=False).group_by(
Gift.isbn).order_by(
desc(Gift.create_time)).limit(
current_app.config['PRECENT_BOOK_COUNT']).distinct().all()
return recent_gift
# 为什么定义成类方法而不是一个函数呢,因为对象代表的是一个礼物,而类代表的是一类抽象的事物,不是具体的一个
我们编写的recent方法获取gift列表里面的每一个gift,然后拿着isbn取YuShuBook里面取查询图书信息,最后使用BookViewModel对数据进行过滤
视图函数
# web.main.py
@web.route('/'):
def index():
recent_gift = Gift.recent()
books = [BookViewModel(gift.book) for gift in Gift.recent()]
根据isbn查找图书的详情是gift的行为,应该放到gift.py的Gift下面
# models\gift.py
@property
def book(self):
yushu_book = YuShuBook()
yushu_book.search_by_isbn(self.isbn)
return yushu_book.first
之所以能够在调用的地方用一个很简单的列表推导式就完成了这么复杂的逻辑,就是因为我们封装的非常良好。这里面涉及到了几个对象的相互调用-bookviewmodel,gift,yushubook;这才是在真正的写面向对象的代码,面向对象就是几个对象在相互调用,各自的逻辑是非常清晰的(单一职责模式)
良好的封装是优秀代码的基础
2 我的礼物
1 业务逻辑分析(非常精巧,多看!!!)
赠送清单的业务逻辑如下

其中复杂在于第二点,实现有以下两种思路

如果循环次数可以控制,比如10次,100次,那么我们还可以接受,但是这个循环次数是掌握在用户手里的,所以第一种方案是不能够接受的。我们采取第二种方案
2 代码编写
# web\gift.py
@web.route('/my/gifts')
@login_required
def my_gifts():
uid = current_user.id
gift_of_mine = Gift.get_user_gifts(uid)
isbn_list = [gift.isbn for gift in gift_of_mine]
get_wish_count = Gift.get_wish_count(isbn_list)
print(get_wish_count)
print(gift_of_mine)
view_model = MyGifts(gift_of_mine, get_wish_count)
return render_template('my_gifts.html', gifts=view_model.gifts)
# models\gift.py
class Gift(Base):
...
@classmethod
def get_user_gifts(cls, uid):
gifts = Gift.query.filter_by(uid=uid, launched=False).order_by(
desc(Gift.create_time)).all()
print('hello')
print([i.id for i in gifts])
return gifts
@classmethod
def get_wish_count(cls, isbn_list):
count_list = db.session.query(func.count(Wish.id), Wish.isbn).filter(
Wish.launched == False,
Wish.isbn.in_(isbn_list),
Wish.status == 1
).group_by(Wish.isbn).all()
count_list = [{'count': w[0], 'isbn': w[1]} for w in count_list]
return count_list
# view_models\gift.py
lass MyGifts:
def __init__(self, gifts_of_mine, wish_count_list):
self.gifts = []
self.__gifts_of_mine = gifts_of_mine
self.__wish_count_list = wish_count_list
self.gifts = self.__parse()
def __parse(self):
gifts = []
for gift in self.__gifts_of_mine:
gifts.append(self.__matching(gift))
return gifts
def __matching(self, gift):
count = 0
for wish_count in self.__wish_count_list:
if gift.isbn == wish_count['isbn']:
count = wish_count['count']
my_gift = {
'wishes_count': count,
'book': BookViewModel(gift.book),
'id': gift.id
}
return my_gift
3 原生sql和连表查询
上面获取原始数据,是对两张表分别查询,再组装,我们也可以进行连表查询,下面是两种方式
# 直接进行sql查询
@classmethod
def get_user_gifts_by_sql(cls, uid):
sql = 'select a.id,a.isbn,count(b.id)' \
'from gift a left join wish b on a.isbn = b.isbn ' \
'where b.uid = %s and a.launched = 0 and b.launched = 0 ' \
'and a.status = 1 and b.status = 1 ' \
'group by a.id,a.isbn order by a.create_time desc'.replace('%s', str(uid))
gifts = db.session.execute(sql)
gifts = [{'id': line[0], 'isbn': line[1], 'count':line[2]} for line in gifts]
return gifts
# 使用SQLAlchemy提供的多表查询的方式
@classmethod
def get_user_gifts_by_orm(cls, uid):
gifts = db.session\
.query(Gift.id, Gift.isbn, func.count(Wish.id))\
.outerjoin(Wish, Wish.isbn == Gift.isbn)\
.filter(
Gift.launched == False,
Wish.launched == False,
Gift.status == 1,
Wish.status == 1,
Gift.uid == uid)\
.group_by(Gift.id, Wish.isbn)\
.order_by(desc(Gift.create_time))\
.all()
gifts = [{'id': line[0], 'isbn': line[1], 'count':line[2]} for line in gifts]
return gifts
4 用户注销
from flaks_login import logout_user
@web.route('/logout')
@login_required
def logout():
logout_user()
return redirect(url_for('web.index'))
5 我的心愿
编写我的心愿基本和我的礼物差不多,在我看来,两种逻辑的功能相似,这个时候,完全可以使用同一个view_model
# web\wish.py
@web.route('/my/wish')
def my_wish():
uid = current_user.id
wish_of_mine = Wish.get_user_wishes(uid)
isbn_list = [wish.isbn for wish in wish_of_mine]
get_giftes_count = Wish.get_gift_count(isbn_list)
view_model = MyTrades(wish_of_mine, get_giftes_count)
return render_template('my_wish.html', wishes=view_model.trade)
# models\wish.py
class Wish(Base):
...
@property
def book(self):
yushu_book = YuShuBook()
yushu_book.search_by_isbn(self.isbn)
return yushu_book.first
@classmethod
def get_user_wishes(cls, uid):
wishes = Wish.query.filter_by(
uid=uid, launched=False).order_by(
desc(Wish.create_time)).all()
return wishes
@classmethod
def get_gift_count(cls, isbn_list):
from app.models.gift import Gift # 解决循环导入问题
count_list = db.session.query(func.count(Gift.id), Gift.isbn).filter(
Gift.isbn.in_(isbn_list),
Gift.status == 1,
Gift.launched == False).group_by(
Gift.isbn).all()
count_list = [{'count': i[0], 'isbn': i[1]} for i in count_list]
return count_list
# view_models\trade.py
class MyTrades:
def __init__(self, trade_of_mine, trade_count_list):
self.trade = []
self.__trade_of_mine = trade_of_mine
self.__trade_count_list = trade_count_list
self.trade = self.__parse()
def __parse(self):
temp_count = []
for trade in self.__trade_of_mine:
temp_count.append(self.__matching(trade))
return temp_count
def __matching(self, trade):
count = 0
for wish_count in self.__trade_count_list:
if trade.isbn == wish_count['isbn']:
count = wish_count['count']
r = {
'trades_count': count,
'book': BookViewModel(trade.book),
'id': trade.id
}
print(r)
return r
6 循环导入错误
在我们运行代码的时候,会出现循环导入的错误
在上面的逻辑中,我们在gift.py中导入了Wish,又在wish中导入了Gift,这就导致了循环导入问题
# 解决的方法就是在什么方法中使用就在什么方法中调用,而不是整个文件调用
# 如
def get_gift_count(cls, isbn_list):
from app.models.gift import Gift # 解决循环导入问题
count_list = db.session.query(func.count(Gift.id), Gift.isbn).filter(
Gift.isbn.in_(isbn_list),
Gift.status == 1,
Gift.launched == False).group_by(
Gift.isbn).all()
count_list = [{'count': i[0], 'isbn': i[1]} for i in count_list]
return count_list
十:Python和Flask的综合应用
1 重置密码
重置密码主要流程如下:
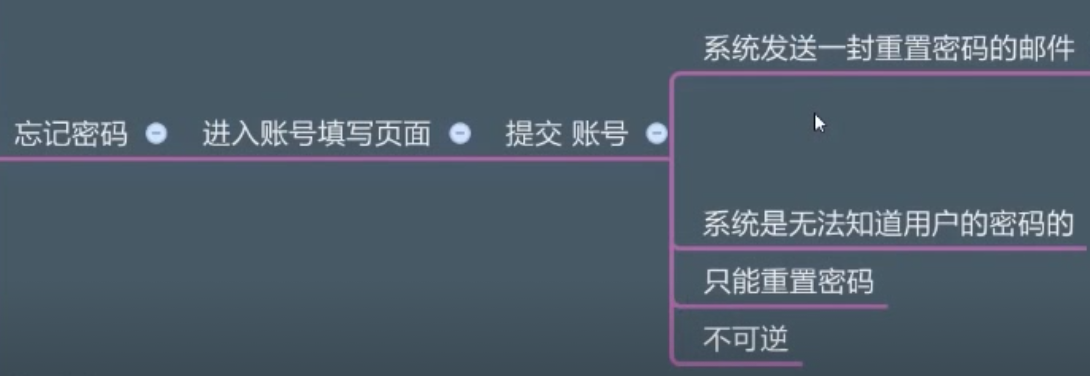
其中,发送重置密码邮件后的流程如下:

1 导入flask-mail
pip install flask-mail -i https://pypi.doubanio.com/simple
2 在app中注册flask_mail
# app/__init__.py
from flask_mail import Mail
mail = Mail()
mail.init_app(app) # 在flask核心对象中注册mail
3 在secure.py中配置Email参数
# email配置
MAIL_SERVER = 'smtp.qq.com'
MAIL_PORT = 465
MAIL_USE_SSL = True
MAIL_USE_TSL = False
MAIL_USERNAME = 'ouyangguoyong@qq.com'
# QQ邮箱->设置->账户->[POP3...]->生成授权码->发送短信->获取授权码
MAIL_PASSWORD = 'korqwumfqbsfbdce'
4 编写邮件发送工具,异步发送(解决flask线程隔离问题)
from threading import Thread
from flask import current_app, render_template
from flask_mail import Message, Mail
__author__ = '欧阳'
mail = Mail()
def _send_async_email(app, msg):
with app.app_context():
try:
mail.send(msg)
except Exception as e:
print(e)
def send_email(to, subject, template, **kwargs):
app = current_app._get_current_object() # 获取flask核心对象
msg = Message('[鱼书]' + ' ' + subject,
sender=app.config['MAIL_USERNAME'], recipients=[to])
msg.html = render_template(template + '.html', **kwargs)
tr = Thread(target=_send_async_email, args=(app, msg))
tr.start()
return tr
# 这个里里面我们使用了上下文管理
# current_app只是app的一个代码,我们想要真的获取app通过如下代码
app = current_app._get_current_object()
5 使用itsdangerous生成token
我们的token应该有过期时间,flask提供了itsdangerous这个非常好用的工具
from itsdangerous import TimedJSONWebSignatureSerializer as Serializer
# 生成token,中间传的参数可以改变,这里使用的是id
def generate_token(self, expiration=600):
s = Serializer(current_app.config['SECRET_KEY'], expiration)
return s.dumps({'id': self.id}).decode('utf-8')
6 重置密码
class User(Base):
...
@staticmethod
def reset_password(token, new_password):
s = Serializer(current_app.config['SECRET_KEY'])
try:
data = s.loads(token.encode('utf-8'))
except:
return False
user = User.query.get(data.get('id'))
if user is not None:
with db.auto_commit():
user.password = new_password
return True
7 视图函数编写
# web/auth.py
# 发送邮件
@web.route('/reset/password', methods=['GET', 'POST'])
def forget_password_request():
form = EmailForm(request.form)
if request.method == 'POST':
if form.validate():
account_email = form.email.data
print(account_email,'要修改密码的邮箱')
user = User.query.filter_by(email=account_email).first_or_404()
from app.libs.email import send_email
send_email(form.email.data, '重置密码',
'email/reset_password', user=user, token=user.generate_token())
flash('一封邮件已发送到邮箱' + account_email + ',请及时查收')
return redirect(url_for('web.login'))
return render_template('auth/forget_password_request.html', form=form)
# 修改密码
@web.route('/reset/password/<token>', methods=['GET', 'POST'])
def forget_password(token):
if not current_user.is_anonymous:
return redirect(url_for('web.index'))
form = ResetPasswordForm(request.form)
if request.method == 'POST' and form.validate():
result = User.reset_password(token, form.password1.data)
if result:
flash('你的密码已更新,请使用新密码登录')
return redirect(url_for('web.login'))
else:
return redirect(url_for('web.index'))
return render_template('auth/forget_password.html')
2 鱼漂
1.业务逻辑编写
当用户在像其他用户发起一个赠书请求的时候,这实际上就是一次交易的发起,我们将这个交易起名为鱼漂(Drift),具体业务逻辑如下
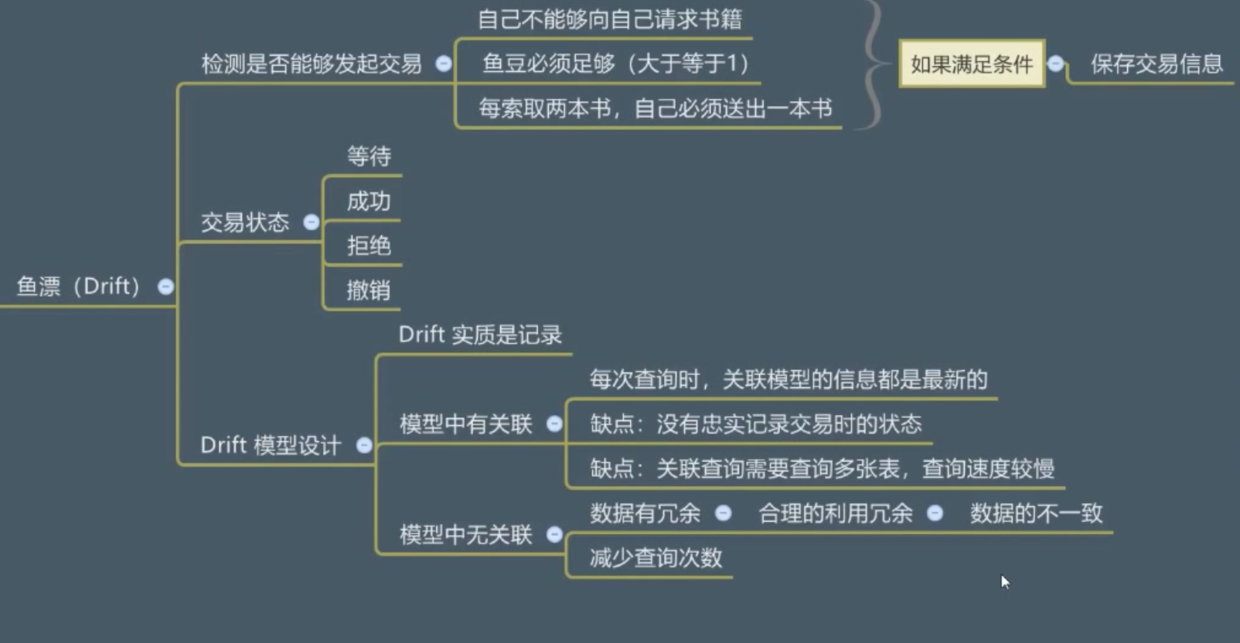
2 模型设计
# models/drift.py
class Drift(Base):
"""
一次具体的交易信息
"""
__tablename__ = 'drift'
id = Column(Integer, primary_key=True)
# 邮寄信息
recipient_name = Column(String(20), nullable=False)
address = Column(String(100), nullable=False)
message = Column(String(200))
mobile = Column(String(20), nullable=False)
# 书籍信息
isbn = Column(String(13))
book_title = Column(String(50))
book_author = Column(String(30))
book_img = Column(String(50))
# 请求者信息
requester_id = Column(Integer)
requester_nickname = Column(String(20))
# 赠送者信息
gifter_id = Column(Integer)
gift_id = Column(Integer)
gifter_nickname = Column(String(20))
# 状态
_pending = Column('pending', SmallInteger, default=1)
状态信息使用枚举
class PendingStatus(Enum):
"""交易状态"""
Waiting = 1
Success = 2
Reject = 3
Redraw = 4
模型冗余而不是模型关联?
1.Drift旨在记录历史状态,而模型关联记录的是实时关联的。所以应该在Drift中直接平铺所有信息
2.模型关联是使得每次查询的时候多次关联,降低查询速度
鱼漂条件检测
1 自己不能向自己索要书籍
# models/gift.py
class Gift(Base):
...
def is_yourself_gift(self, gid):
if self.uid == gid:
return True
2 鱼豆数量必须大于1
3 美索取两本书就要送出去一本书
# models/user.py
class User(Base):
...
def can_send_gift(self):
if self.beans <= 1:
return False
success_gifts_count = Gift.query.filter_by(
uid=self.id, launched=True).count()
success_receive_count = Drift.query.filter_by(
requester_id=self.id, pending=PendingStatus.Success).count()
return True if float(success_receive_count/2) < float(success_gifts_count) else False
完成鱼漂业务逻辑
试图函数
web/drift.py
@web.route('/drift/<int:gid>', methods=['GET', 'POST'])
@login_required
def send_drift(gid):
current_gift = Gift.query.get_or_404(gid)
if current_gift.is_yourself_gift(current_user.id):
flash('这本书是自己的(*^▽^*),不能向自己索要哦')
return redirect(url_for('web.book_detail', isbn=current_gift.isbn))
can = current_user.can_send_drifts()
if not can:
return render_template('not_enough_beans.html', beans=current_user.beans)
form = DriftForm(request.form)
if request.method == 'POST' and form.validate():
save_drift(form, current_gift)
send_mail(current_gift.user.email, '有人想要一本书', 'email/get_gift.html',
wisher=current_user,
gift=current_gift)
# 成功后跳转到鱼漂历史记录界面
return redirect(url_for('web.pending'))
# summary用户的简介频繁使用,且更像是一种用户的属性,所以作为用户的一个属性
gifter = current_gift.user.summary
return render_template('drift.html', gifter=gifter, user_beans=current_user.beans, form=form)
models/user.py
@property
def summary(self):
return dict(
nikename=self.nickname,
beans=self.beans,
email=self.email,
send_receive=str(self.send_counter) + '/' + str(self.receive_counter)
)
save_gift.py
def save_drift(drift_form, current_gift):
if current_user.beans < 1:
# TODO 自定义异常
raise Exception()
with db.auto_commit():
drift = Drift()
drift_form.populate_obj(drift)
drift.gift_id = current_gift.id
drift.requester_id = current_user.id
drift.requester_nickname = current_user.nickname
drift.gifter_nickname = current_gift.user.nickname
drift.gifter_id = current_gift.user.id
book = BookViewModel(current_gift.book)
drift.book_title = book.title
drift.book_author = book.author
drift.book_img = book.image
drift.isbn = book.isbn
db.session.add(drift)
current_user.beans -= 1
3交易记录
1.业务逻辑

这两个条件应该是或者(or)的关系
2.获取鱼漂列表
# select * from drift where requester_id = ? or gifter_id = ?
# order by create_time desc
drifts = Drift.query.filter(
or_(Drift.requester_id == current_user.id,
Drift.gifter_id == current_user.id))\
.order_by(desc(Drift.create_time)).all()
3.Drift ViewModel 编写
Drift ViewModel需要适应当前用户是赠送者和当前用户是索要者两个情况

class DriftCollection:
def __init__(self, drifts, current_user_id):
self.data = []
self.data = self._parse(drifts, current_user_id)
def _parse(self, drifts, current_user_id):
return [DriftViewModel(drift, current_user_id).data for drift in drifts]
class DriftViewModel:
def __init__(self, drift, current_user_id):
self.data = {}
self.data = self._parse(drift, current_user_id)
@staticmethod
def requester_or_gifter(drift, current_user_id):
# 不建议将current_user耦合进DriftViewModel,破坏了封装性,难以扩展,所以当做参数从外部传入
return 'requester' if current_user_id == drift.requester_id else 'gifter'
def _parse(self, drift, current_user_id):
you_are = DriftViewModel.requester_or_gifter(drift, current_user_id)
# pending_status 设计到了4*2=8种状态,这个状态的判断应该在PendingStatus完成
pending_status = PendingStatus.pending_str(drift.pending, you_are)
r = {
'drift_id': drift.id,
'you_are': you_are,
'book_title': drift.book_title,
'book_author': drift.book_author,
'book_img': drift.book_img,
'date': drift.create_datetime.strftime('%Y-%m-%d'),
'operator': drift.requester_nickname if you_are != 'requester' \
else drift.gifter_nickname,
'message': drift.message,
'address': drift.address,
'status_str': pending_status,
'recipient_name': drift.recipient_name,
'mobile': drift.mobile,
'status': drift.pending
}
return r
from enum import Enum
__author__ = '欧阳'
class PendingStatus(Enum):
"""交易状态"""
Waiting = 1
Success = 2
Reject = 3
Redraw = 4
# gifter_redraw = 5
@classmethod
def pending_str(cls, status, key):
key_map = {
cls.Waiting: {
'requester': '等待对方邮寄',
'gifter': '等待你邮寄'
},
cls.Reject: {
'requester': '对方已拒绝',
'gifter': '你已拒绝'
},
cls.Redraw: {
'requester': '你已撤销',
'gifter': '对方已撤销'
},
cls.Success: {
'requester': '对方已邮寄',
'gifter': '你已邮寄,交易完成'
}
}
return key_map[status][key]
对比三种ViewModel
1.BookViewModel将单体和集合分开,单体定义实例属性,清晰明了(最推荐) 2.MyTrade 将单体作为字典融合在集合类里面,代码少,灵活性高,但是不易扩展(最不推荐) 3.DriftViewModel 将单体和集合分开,单体使用字典。坚固了前两中的优点,但是可读性下降(也不是特别推荐)
4 其他操作
1.更好的使用枚举
我们的数据库中pending存储的是数字类型,但是我们在代码中使用的是枚举类型。这肯定是匹配不上的,一种最优雅的解决方式就是为我们的Drift模型的pending属性编写getter/setter方法
# 状态
_pending = Column('pending', SmallInteger, default=1)
@property
def pending(self):
return PendingStatus(self._pending)
@pending.setter
def pending(self, status):
self._pending = status.value
这样就能在外部使用枚举类型操作我们的属性了
2.撤销操作业务逻辑
@web.route('/drift/<int:did>/redraw')
@login_required
def redraw_drift(did):
'''
撤销鱼漂
:param did:
:return:
'''
with db.auto_commit():
drift = Drift.query.filter_by(id=did, requester_id=current_user.id).first_or_404()
drift.pending = PendingStatus.Redraw
current_user.beans -= 1
return redirect(url_for('web.pending'))
3.拒绝操作业务逻辑
@web.route('/drift/<int:did>/reject')
@login_required
def reject_drift(did):
with db.auto_commit():
drift = Drift.query.filter(Drift.id == did, Drift.gifter_id == current_user.id).first_or_404()
drift.pending = PendingStatus.Reject
gifter = Gift.query.get_or_404(drift.requester_id)
gifter.beans += 1
return redirect(url_for('web.pending'))
4.完成邮寄
@web.route('/drift/<int:did>/mailed')
@login_required
def mailed_drift(did):
"""
确认邮寄,只有书籍赠送者才可以确认邮寄
注意需要验证超权
"""
with db.auto_commit():
# requester_id = current_user.id 这个条件可以防止超权
drift = Drift.query.filter_by(
gifter_id=current_user.id, id=did).first_or_404()
drift.pending = PendingStatus.success
current_user.beans += current_app.config['BEANS_EVERY_DRIFT']
gift = Gift.query.filter_by(id=drift.gift_id).first_or_404()
gift.launched = True
# 不查询直接更新;这一步可以异步来操作
Wish.query.filter_by(isbn=drift.isbn, uid=drift.requester_id,
launched=False).update({Wish.launched: True})
return redirect(url_for('web.pending'))
5.撤销赠送
@web.route('/gifts/<gid>/redraw')
def redraw_from_gifts(gid):
gift = Gift.query.filter_by(id=gid, launched=False).first_or_404()
drift = Drift.query.filter_by(gift_id=gid, sending=PendingStatus.Waiting).first()
if drift:
flash('请先去鱼漂完成交易')
else:
with db.auto_commit():
current_user.beans -= current_app.config['BEANS_UPLOAD_ONE_BOOK']
gift.delete()
return redirect(url_for('web.my_gifts'))
6.撤销心愿
@web.route('/wish/book/<isbn>/redraw')
def redraw_from_wish(isbn):
wish = Wish.query.filter_by(isbn=isbn, launched=False).first_or_404()
if wish:
with db.auto_commit():
wish.delete()
return redirect(url_for('web.my_wish'))
7.赠送书籍
"""
向想要这本书的人发送一封邮件
注意,这个接口需要做一定的频率限制
这接口比较适合写成一个ajax接口
"""
wish = Wish.query.get_or_404(wid)
gift = Gift.query.filter_by(uid=current_user.id, isbn=wish.isbn).first()
if not gift:
flash('你还没有上传此书,请点击“加入到赠送清单”添加此书。添加前,请确保自己可以赠送此书')
else:
send_mail(wish.user.email, '有人想送你一本书', 'email/satisify_wish.html', wish=wish,
gift=gift)
flash('已向他/她发送了一封邮件,如果他/她愿意接受你的赠送,你将收到一个鱼漂')
return redirect(url_for('web.book_detail', isbn=wish.isbn))
复制代码
email/satisify_wish.html的内容
<p><stong>亲爱的 {{ wish.user.nickname }},</stong></p>
<p>{{ gift.user.nickname }} 有一本《{{ wish.book.title }}》可以赠送给你</p>
{# 将用户导向send_drift索要数据的试图函数#}
<p>点击<a
href="{{ url_for('web.send_drift', gid=gift.id, _external=True) }}">这里</a>填写书籍邮寄地址,
等待{{ gift.user.nickname }}将书籍寄送给你
</p>
<p>如果无法点击,你也可以将下面的地址复制到浏览器中打开:</p>
<p>{{ url_for('web.send_drift', gid=gift.id, _external=True) }}</p>
<p>你的,</p>
<p>鱼书</p>
<p>
<small>注意,请不要回复此邮件哦</small>
</p>
