

前言
前段时间接到一个开发采集网站数据的项目,从事php开发的我立刻想到使用php做爬虫。虽然python爬虫方便,但是php在这方面也不弱,谁让php是世界上最好的语言!这里推荐一款php的爬虫框架phpspider。不建议自己写爬虫,因为效率太低。使用框架爬虫真的要高效许多
官方文档:
https://doc.phpspider.org/
1、下载
官方github下载地址:
https://github.com/owner888/phpspider
下载地址可能无法访问,这里提供一个网盘下载地址:
https://pan.baidu.com/s/10n9ZOUQBlrJzOQx0ShOmMQ
提取码:b2zc
2、文件结构
下载解压后,phpspider的文件结构如图所示:
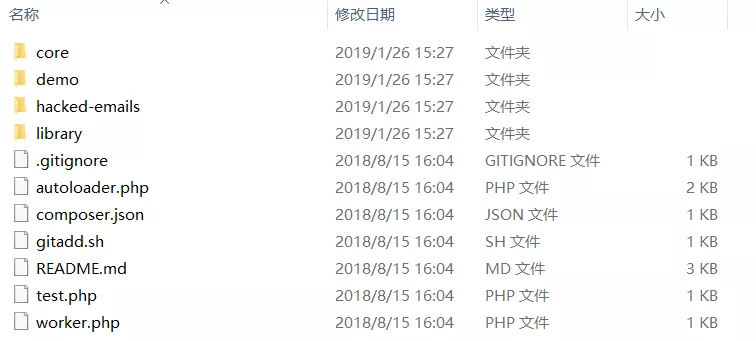
其中demo文件夹放的是phpspider的一些案例,如图所示:

3、创建爬虫并且运行
在demo文件夹下创建爬虫文件。需要注意的是,phpspider有两种运行爬虫文件的方式,一种是在命令行下运行;另外一种是可视化操作(在浏览器下运行)
3.1 在命令行下运行爬虫文件
要爬取的对象链接:
https://www.douban.com/photos/album/1616649448/
要爬取的内容如图所示:
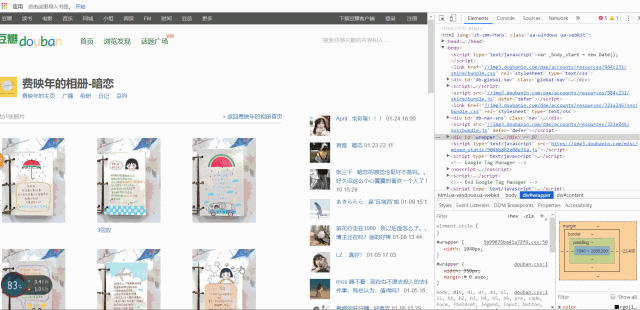
爬取id为wrapper的div所包含的内容
3.1.1 在demo文件夹下新建文件spider.php,代码如下:
<?php
require_once __DIR__ . '/../autoloader.php';
use phpspider\core\phpspider;
/* Do NOT delete this comment */
/* 不要删除这段注释 */
$configs = array(
'name' => '豆瓣',//定义当前爬虫名称
'log_show' => true, //显示日志调试信息
'input_encoding' => 'UTF-8',//输入编码
//定义爬虫爬取哪些域名下的网页, 非域名下的url会被忽略以提高爬取速度
'domains' => array(
'www.douban.com'
),
//定义爬虫的入口链接, 爬虫从这些链接开始爬取,同时这些链接也是监控爬虫所要监控的链接
'scan_urls' => array(
'https://www.douban.com/photos/album/1616649448/'
),
//爬虫爬取数据导出
'export' => array(
'type' => 'csv', //type:导出类型 csv、sql、db
'file' => '../data/abc.csv', //file:导出 csv、sql 文件地址,如果不存在文件自动创建
),
//定义内容页的抽取规则
'fields' => array(
array(
'name' => "wrapper",
'selector' => "//div[@id='wrapper']",
)
)
);
$spider = new phpspider($configs);
$spider->start();3.1.2 在demo文件夹中直接打开cmd命令面板,输入命令行 php -f spider.php 回车,代码跑起来,如图所示:
3.1.3 查看爬取下来的数据
在phpspider文件结构中找到data文件夹下的abc.csv文件,打开文件可看到爬取下来的数据,如图所示:
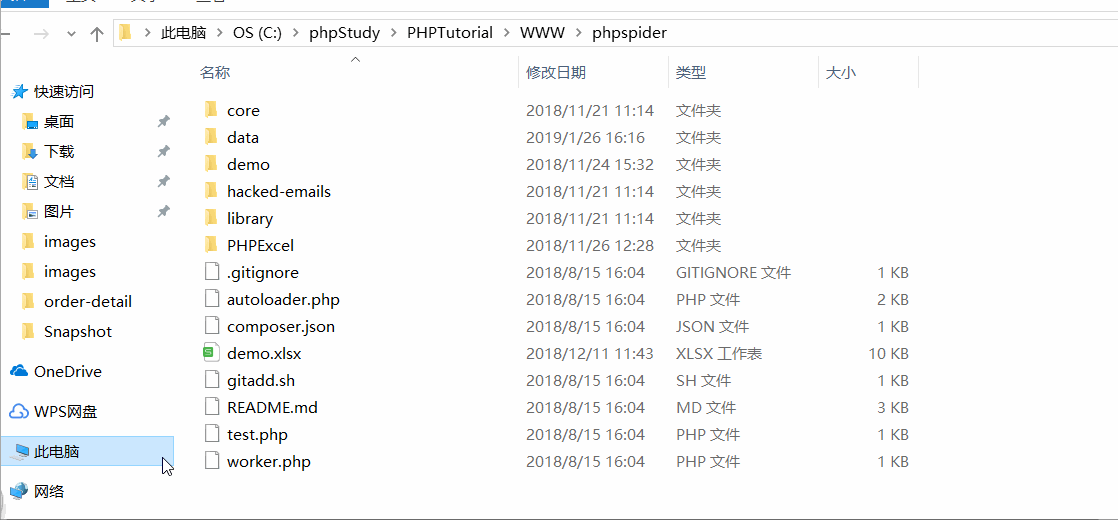
3.2 可视化操作(在浏览器下运行爬虫文件)
要爬取的对象链接:
https://movie.douban.com/subject/26588308/?from=showing
要爬取的内容如图所示:
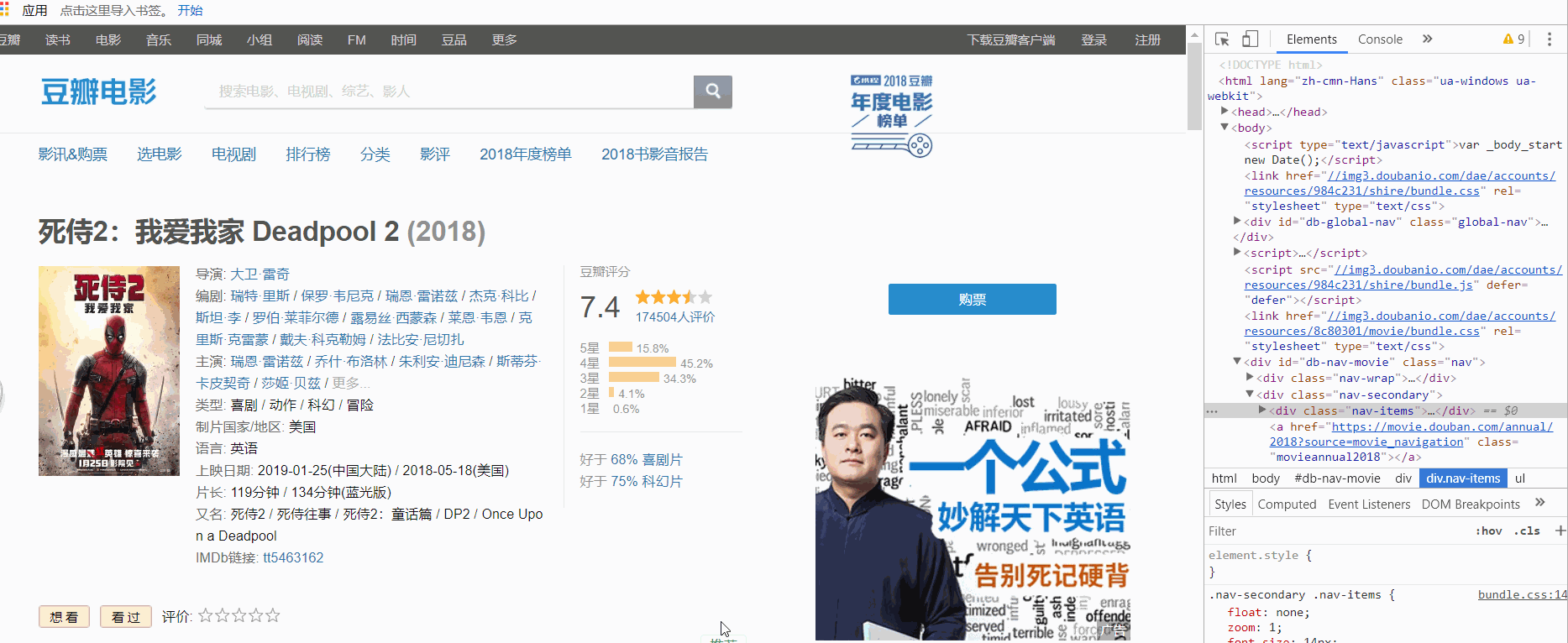
爬取class为nav-items的div所包含的内容
3.2.1 在demo文件夹下新建另外一个文件test.php,代码如下:
<?php
header("Content-Type: text/html;charset=utf-8");
date_default_timezone_set("Asia/Shanghai");
ini_set("memory_limit", "10240M");
require_once __DIR__ . '/../autoloader.php';
use phpspider\core\phpspider;
use phpspider\core\requests;
use phpspider\core\selector;
/* Do NOT delete this comment */
/* 不要删除这段注释 */
$html = requests::get('https://movie.douban.com/subject/26588308/?from=showing');
$data = selector::select($html, "//div[@class='nav-items']");
echo $data;
3.2.2 打开浏览器输入文件地址
结语
以上只是简单的爬虫例子,还可以进行多进程爬取,代理爬虫,很多好玩的,更多操作参考官方文档
https://doc.phpspider.org/
最后
觉得文章不错的话,给我个关注哇,点个赞呗!
如果对文章有疑问或想技术交流,可关注公众号【GitWeb】与我一起探索学习!

