

Redis底层数据结构
简单动态字符串SDS
数据结构
struct sdshdr{
//记录buf数组中已使用字节的数量
//等于 SDS 保存字符串的长度 int len;
//记录 buf 数组中未使用字节的数量 int free;
/字节数组,用于保存字符串 char buf[];
}
在c字符串的基础上多了两个字段 free和len
使用sds的好处
- 获取字符串长度的时间复杂度:sds o(1),c字符串o(n)
- 避免缓冲区溢出:使用c字符串的API时,如果字符串长度增加,而忘记重新分配内存,很容易导致缓冲区溢出,而SDS记录了长度,相应的API在改变字符串长度的时候会重新分配内存,避免缓冲区溢出。
- 存取二进制数据:c字符串是以空格作为结束标识,对于一些二进制文件,比如图片等,有可能包含空格,因此不能用c的字符串存取。而sds以len作为字符串结束标识,没有这个问题。
使用场景
- redis中所有的key
- 数据里的字符串
- AOF缓冲区和用户输入缓冲
链表
数据结构
//节点
typedef struct listNode {
//前置节点 struct listNode *prev;
//后置节点 struct listNode *next;
//节点的值 void *value;
} listNode;
//链表
typedef struct list {
/表头节点
listNode.head;
/表尾节点
listNode.tail;
/链表所包含的节点数量
unsigned long len;
//节点值复制函数
void *(*dup)(void *ptr);
//节点值释放函数
void *(*free)(void *ptr);
//节点值对比函数
int (*match)(void *ptr,void *key);
} list;
优势
- 双向:链表具有前置节点和后置节点的引用,获取这两个节点的时间复杂度都是O(1)
- 无环:表头节点的pre和表尾节点的next都是指向null,因此,访问链表都是以null结束
- 带链表长度的计数器:获取链表长度的时间复杂度为O(1)
- 多态:链表节点使用指针保存节点值,可以存储不同类型的值
使用场景
- redis中列表的底层实现之一
字典
字典就是我们常说的map,底层实现就哈希表。字典中每个key都是唯一的,可以通过key来进行查找和修改
数据结构
typedef struct dictht{
//哈希表数组
dictEntry **table;
//哈希表大小
unsigned long size;
//哈希表大小掩码,用于计算索引值
//总是等于
size-1 unsigned long sizemask;
//该哈希表已有节点的数量
unsigned long used; }dictht
/*哈希表是由数组 table 组成,table 中每个元素都是指向 dict.h/dictEntry 结构, dictEntry 结构定义如下:
*/
typedef struct dictEntry{
//键
void *key;
//值
union{
void *val;
uint64_tu64;
int64_ts64;
}v;
//指向下一个哈希表节点,形成链表
struct dictEntry *next;
}dictEntry
使用场景
- redis中的set的实现之一
- redis中hash的实现之一
跳跃表
什么是跳跃表
跳跃表是一种随机化的数据,跳跃表以有序的方式在层次化的链表中保持数据。效率和平衡树媲美,查找,删除,添加等操作都在对数期望时间下完成,并且实现较为简单。下图,是一张跳跃表的图
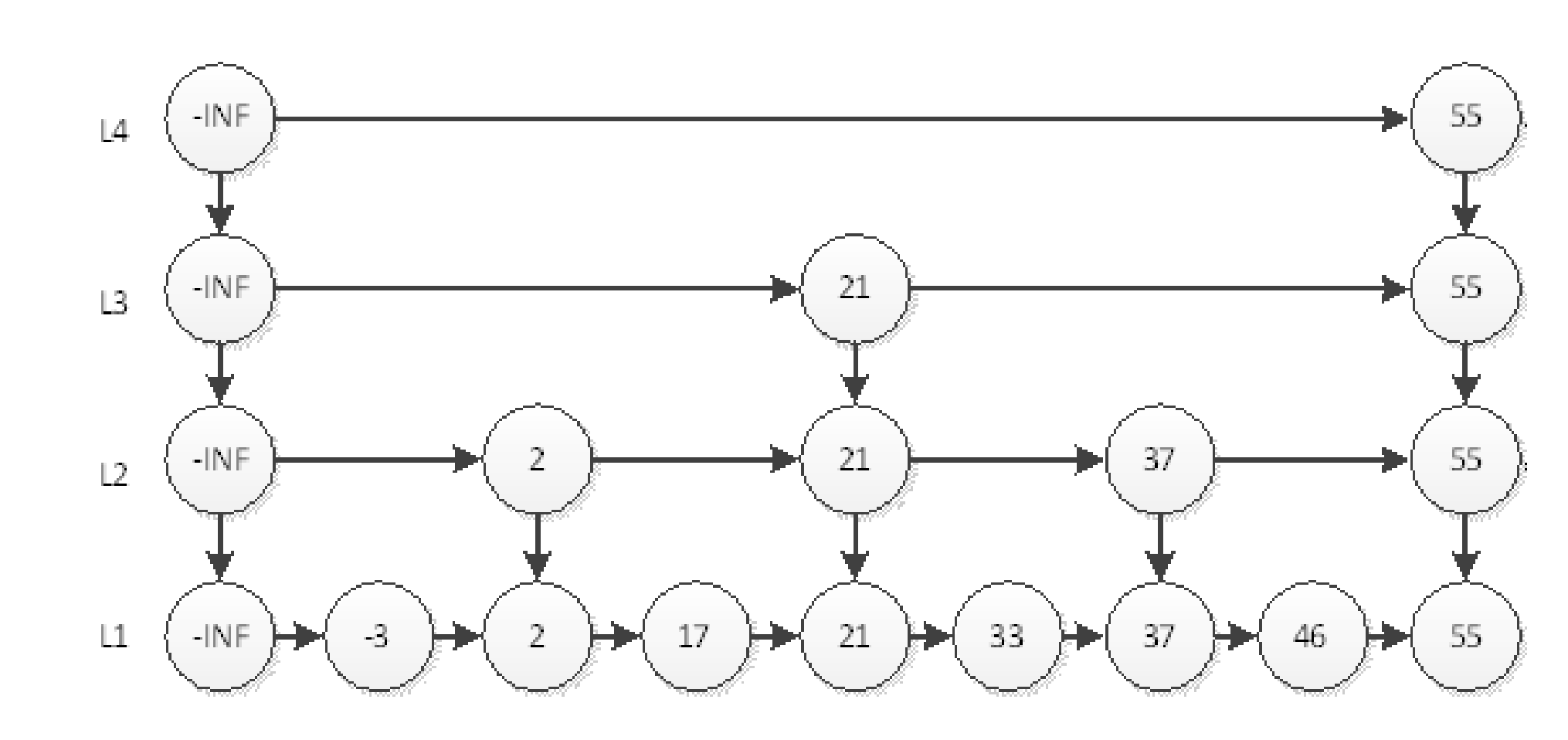
查询
- 查询46:首先从顶层开始查55;然后查L3层21,55;然后查L2层37,55;然后查L1层46。一共查了6次。从最高层的链表节点开始,如果比当前节点要大和比当前层的下一个节点要小,那么则往下 找,也就是和当前层的下一层的节点的下一个节点进行比较,以此类推,一直找到最底层的最后一个节 点,如果找到则返回,反之则返回空。
插入
首先插入2
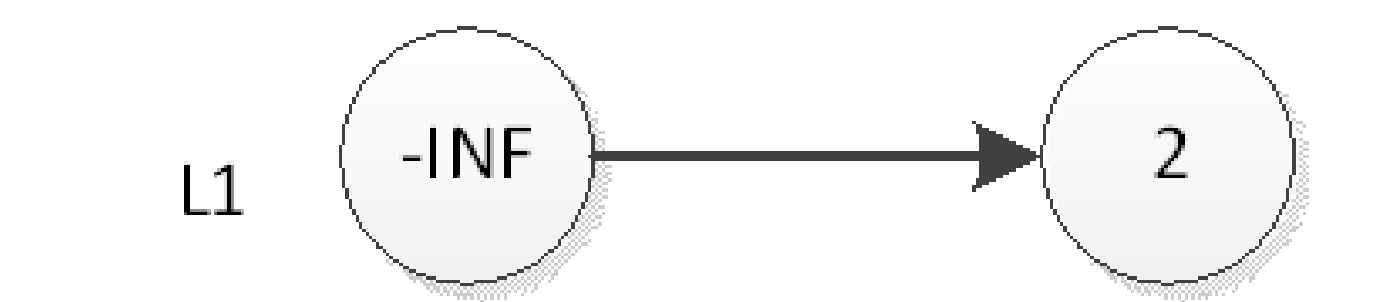
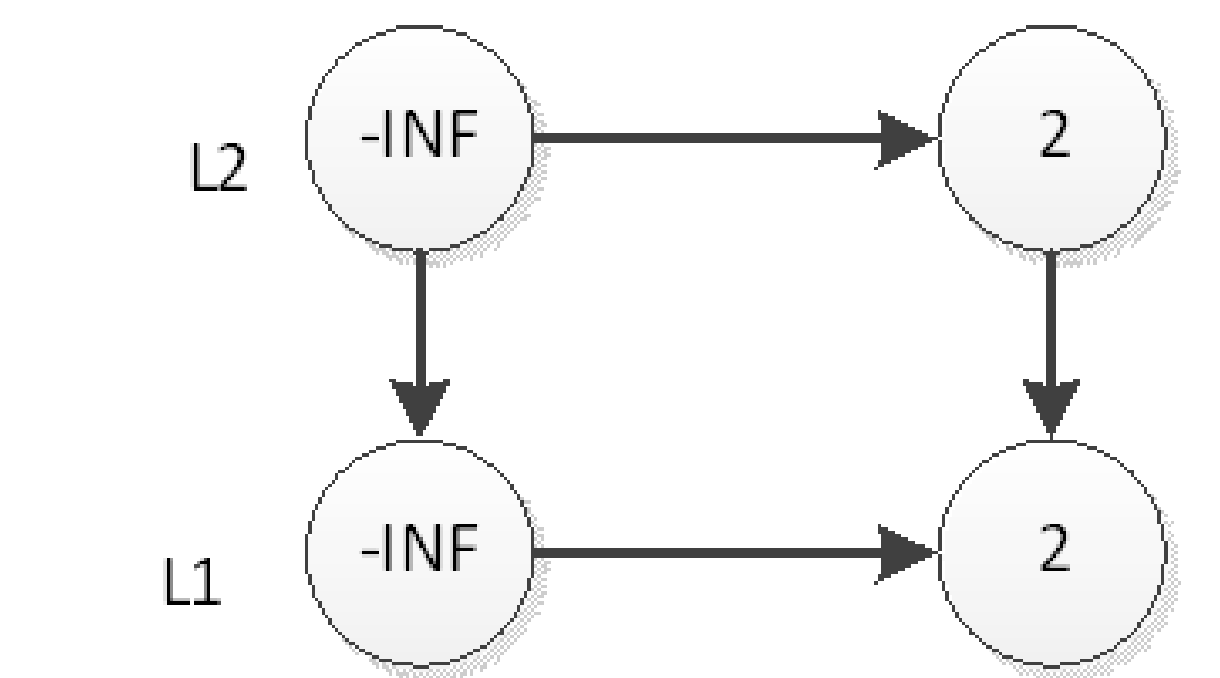
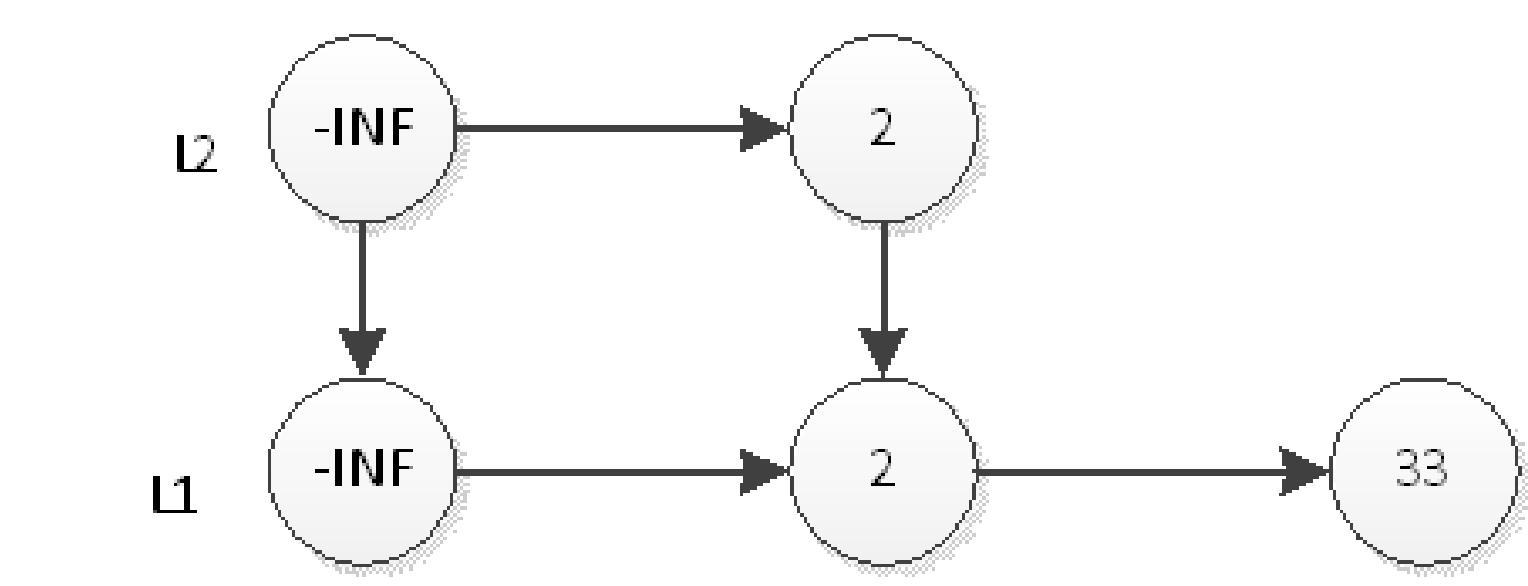
删除
在各个层中找到包含指定值的节点,然后将节点从链表中删除即可,如果删除以后只剩 下头尾两个节点,则删除这一层
数据结构
typedef struct zskiplistNode {
//层
struct zskiplistLevel{
//前进指针
struct zskiplistNode *forward;
//跨度 unsigned int span;
}level[];
//后退指针
struct zskiplistNode *backward;
//分值
double score;
//成员对象
robj *obj;
} zskiplistNode
--链表
typedef struct zskiplist{
/表头节点和表尾节点
structz skiplistNode *header, *tail;
//表中节点的数量
unsigned long length;
//表中层数最大的节点的层数
int level;
}zskiplist;
使用场景
- redis中ZSET的底层实现之一
整数集合
当一个集合中只包含整数,并且集合元素不多的时候,就使用整数集合作为底层实现。
数据结构
typedef struct intset{
//编码方式
uint32_t encoding;
//集合包含的元素数量
uint32_t length;
//保存元素的数组
int8_t contents[];
}intset;
使用场景
- redis中set的底层实现之一
压缩列表
当一个列表只包含少量的列表项,并且列表项是小整数或者短字符串,redis就会用压缩列表作为底层实现。压缩列表是redis开发出来用于节省内存的数据结构,由一系列特殊编码的连续内存块组成的顺序数据结构,一个列表包含多个节点,每个节点存储一个字节数组或者整数值。
节点结构

- previous_entry_ength:记录上一个节点的长度
- encoding:节点存储的数据类型
- content:节点存储的内容
使用场景
- redis中list,set,zset的底层实现之一
对象
redis并不是直接使用上述这些数据结构实现redis的数据存储,而是基于这些数据结构创建了一个对象。根据对象类型可以判断给的命令是否可以执行,根据不同的使用类型,用不同的数据结构实现,优化不同场景下的效率。
数据结构
typedef struct redisObject {
unsigned type:4;
//类型 五种对象类型
unsigned encoding:4;
//编码
void *ptr;
//指向底层实现数据结构的指针
//...
int refcount;
//引用计数
//...
unsigned lru:22;
//记录最后一次被命令程序访问的时间
//...
}robj;
- type:表示对象的类型,就是redis的5中对象类型(字符串,列表,哈希,集合,有序集合)
- encoding:表示对象的实现方式,就是上述的数据结构之一
- lru:记录最后一次被访问的时间,用于淘汰缓存
- refcount:记录对象被引用的次数,用于对象的引用计数和内存回收。当 refcount 变为 0 时,对象占用的内存会被释放。Redis 中被多次使用的对象(refcount>1),称为共享对象。Redis 为了节省内存,当有一些对象重复出现时,新的程序不会创建新的对象,而是仍然使用原来的对象。
- ptr:指针指向具体的存储数据
Redis事务
Redis事务介绍
- redis的事务是通过MULTI,EXEC,DISCARD和WATCH这四个命令完成
- redis的单个命令是原子性的,因此需要确保事务的对象是一个命令集合
- redis将命令集合序列化,并确保同一事务的命令集合连续且不被打断的执行
- redis事务不支持回滚
事务命令
- MULTI:用于标记事务块的开始。Redis会将后续的命令逐个放入队列中,然后使用EXEC命令原子化地执行这个命令序列。
- EXEC:在一个事务中执行所有先前放入队列的命令,然后恢复正常的连接状态
- DISCARD:清除先前事务中放的所有命令,恢复正常连接状态
- WATCH:当某个[事务需要按条件执行]时,就要使用这个命令将给定的[键设置为受监控]的状态。用于实现乐观锁
- UNWATCH:清除之前监控的键
事务失败处理
- redis语法错误:会清除整个事务中的所有命令,也就是所有的都执行失败
- redis运行错误:事务中正确的命令可以执行
使用场景-乐观锁
乐观锁基于CAS思想,就是比较替换,不具有互斥性,不会产生阻塞,提高响应效率,但需要不断重试。
- 使用watch监控一个key的状态
- 获取key的值
- 创建redis事务
- 改变key的值
- 提交事务,如果key在被更改过则回滚,执行失败
redis实现秒杀
public class Second {
public static void main(String[] args) {
String rediskey="second";
Jedis jedis = new Jedis("****",6379);
jedis.set(rediskey,"0");
jedis.close();
ExecutorService executorService = Executors.newFixedThreadPool(20);
CountDownLatch latch = new CountDownLatch(20);
CountDownLatch waitLatch = new CountDownLatch(1);
for (int i = 0; i < 20; i++) {
executorService.execute(()->{
Jedis jedis1 = new Jedis("****",6379);
try {
waitLatch.await();
jedis1.watch(rediskey);
String redisValue = jedis1.get(rediskey);
Integer value = Integer.valueOf(redisValue);
String user = UUID.randomUUID().toString();
if (value<20){
Transaction tx = jedis1.multi();
tx.incr(rediskey);
List<Object> list = tx.exec();
if (null!=list && !list.isEmpty()){
System.out.println("用户:" + user + ",秒杀成功! 当前成功人数:" + (value + 1));
}else {
System.out.println("用户:" + user + ",秒杀失败");
}
}else {
System.out.println("已经有20人秒杀成功,秒杀结束");
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
jedis1.close();
latch.countDown();
}
});
}
waitLatch.countDown();
executorService.shutdown();
}
}
