

开头
本文旨在对自己近日,阅读Git文档后,对自己的理解用大白话转述。当自己有朝一日,忘记了这些天关于Git的知识点,也有一个可以‘查阅’的地方。如果能帮助读到这篇文章的你,那就最好不过了。同时也期望你能针对此文多多指点。
Git思想&原理
-
Git 和其它版本控制系统的主要差别(来源:Git官网)
- 直接记录快照,而非差异
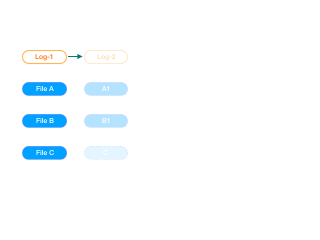
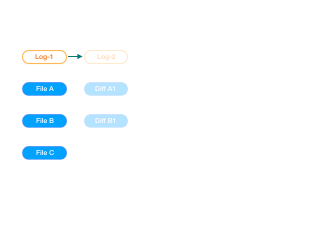
图一是Git的方式,图二是其它的类型,比如小乌龟。Git的每一次提交,保留的只是文件的一个快照(图中蓝色实块),当本次提交没有修改文件时,则保留的是上一个提交(父提交对象)的文件快照引用(图中蓝色虚块)。有些其它版本控制系统,在每一次提交时,保留的是此次提交时的文件与基本文件的差异。
- 近乎所有操作都是本地执行
平时工作中,一般只有pull、fetch、push才需要联网。当然还有一些需要联网的指令,不过不常用。
- Git 保证完整性
这一点我还是理解不太深刻。官网原文:Git 中所有数据在存储前都计算校验和,然后以校验和来引用。 这意味着不可能在 Git 不知情时更改任何文件内容或目录内容。 这个功能建构在 Git 底层,是构成 Git 哲学不可或缺的部分。 若你在传送过程中丢失信息或损坏文件,Git 就能发现。我的理解是,因为校验和唯一的,并且每一次的修改都有一个commitObject,当你修改文件或对已经提交的commit作修改时,Git会计算对比校验和,发现不对就会报错。这样就能保证文件完整,记录完整。
- Git 一般只添加数据
我的理解是:不管你是reset还是rebase。现象上看,好像是撤回等操作。其实对Git来说,都是添加,添加了一个'撤回操作',添加了一个‘回滚操作’。因为这一点,所以Git的所有操作都不会丢失,都能找回。
- 直接记录快照,而非差异
-
文件状态
- 已跟踪
已跟踪的文件是指那些被纳入了版本控制的文件,在上一次快照中有它们的记录,在工作一段时间后,它们的状态可能处于未修改,已修改或已放入暂存区。
- 未跟踪
工作目录中除已跟踪文件以外的所有其它文件都属于未跟踪文件,它们既不存在于上次快照的记录中,也没有放入暂存区。
- 已跟踪
-
Git状态
- 已提交(committed)
- 已修改(modified)
- 已暂存(staged)
-
Git工作区
- 工作目录 Working Directory
- 暂存区 Staging Area (.git/index)
- Git仓库 .git directory
-
Git原理(Git是怎么保存数据的?)
我们来把Git保存数据的过程,做一个基本的描述。-
首先,我们新建一个文件夹(demo/),这个demo/就是我们的工作目录。执行git init,这时就会生成一个demo/.git文件夹,这个.git/文件夹就包含了我们的暂存区和Git仓库。
-
我们接着新建一个index.txt文件。这个时候,因为index.text文件既不存在于上次快照的记录中,也没有放入暂存区,在.git/文件夹里,完全没有这个index.txt文件的任何记录,所以这个文件就是一个未跟踪的文件。在你输入git status时,Git就把工作目录里有修改(增删改都是修改)的文件与.git里做对比,把文件分成已跟踪和未跟踪。再把已跟踪的文件的Git状态分成已提交、已修改和已暂存。
-
然后我们这个时候,执行git add,把index.txt放入暂存区。这个时候,Git会为每一个文件计算校验和,然后把文件的快照(blob对象)放入到Git仓库里,然后把校验和放到暂存区,等待提交。
-
我们再执行git commit,这个时候Git先计算目录(包含每一个子目录)的校验和,然后在Git仓库里把这个校验保存为一个表示目录结构的树对象。然后Git再创建一个提交对象(commitObject),这个commitObject包含:指向树对象的指针、作者的姓名、邮箱、提交时输入的信息以及指向它的父对象(父对象也是一个commitObject)的指针(父对象的数量可能为0、1、2)。这里的树对象里有指向blob类型的文件快照的指针。通过这个树对象,我们就能知道这次提交时,工作目录的情况。
-
我们再执行git log,会得到一个指向commitObject的哈希值。一般多次提交之后,会得到一个哈希值的提交记录链路,这个链路就是父提交对象链路(后面再讲)。此时Git仓库里有三个对象,一个commitObject,一个tree对象,一个blob对象。
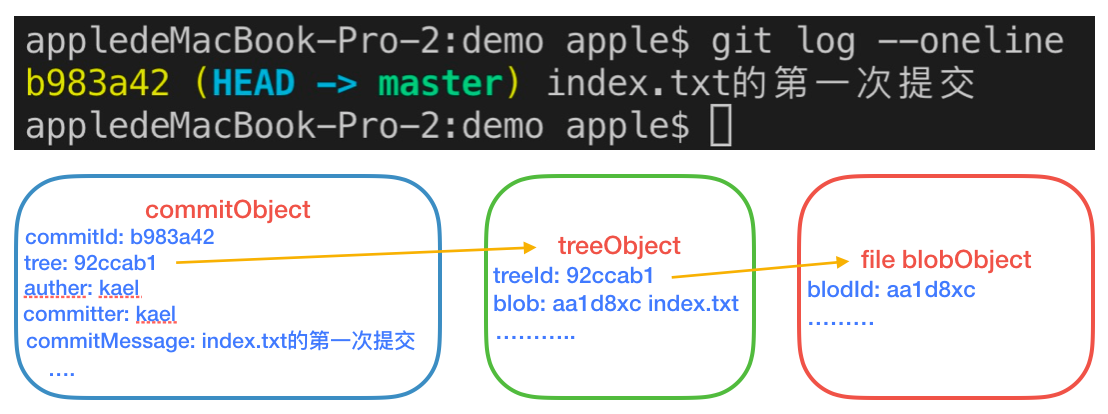
-
随后我做了两次提交,首先是修改了index.txt的内容。然后是新增了一个index.js文件。对图理解,log链其实就是父提交对象的链条。
修改index.txt
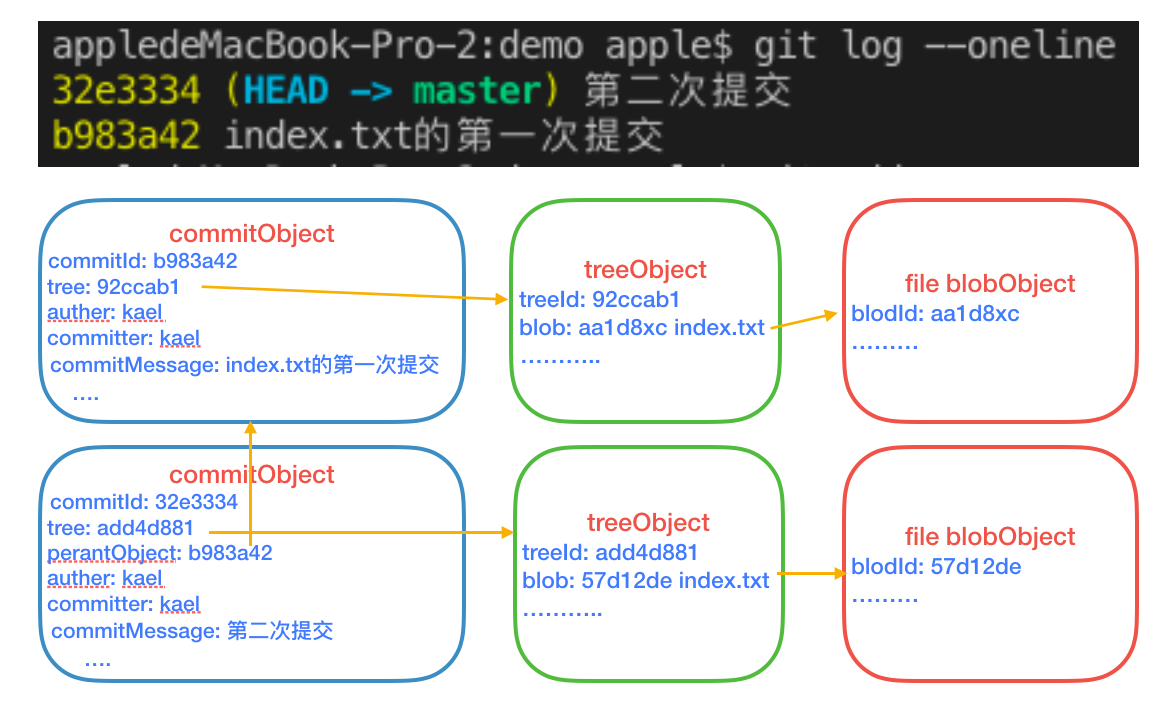
新增index.js
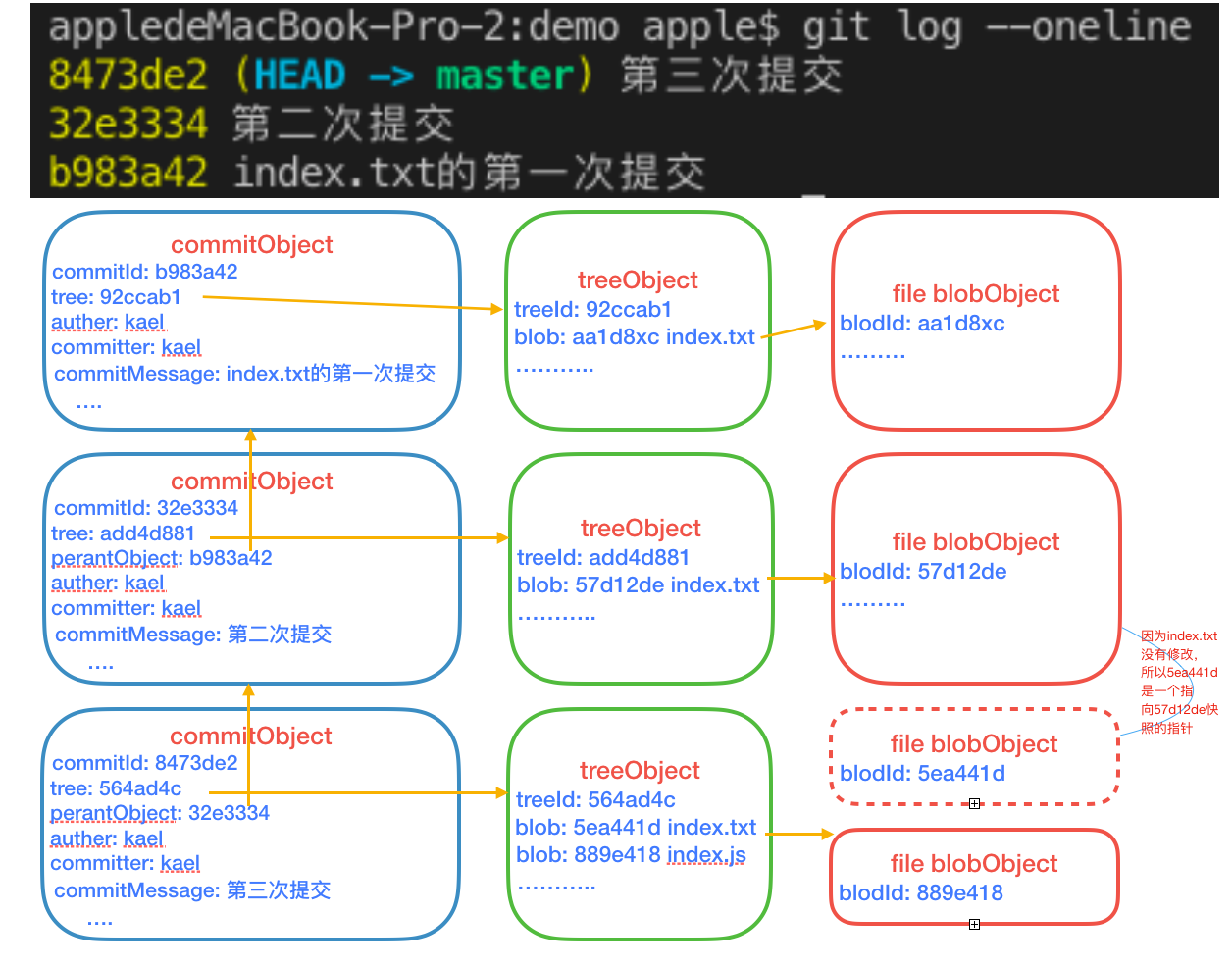
强调:Git里的branch、tag、HEAD、origin/branch、commitId、HEAD@{n}等都是引用,都指向某一个commitObject。也就是说,如果这些引用指向的commitObject是同一个,那它们就是全等的。这个概念的理解很重要!还有一点,在Git里很多需要引用的地方,如果你不写,默认均是操作的HEAD。
-
常用指令使用和分析
-
clone/ init
获取仓库,git clone [url] [自定义文件夹名]
-
status
查看状态,git status -s 状态简览 ?? 、 [M 、 A 、 M] D U
-
add
获取工作区内容,计算文件校验和。把校验和放入暂存区。
- 常用方式:
- git add .
- git add file
- 常用方式:
-
commit
计算目录的校验和,创建提交对象。
- 常用方式:
- git commit --amend 修改上一个commit
- -a 跳过add
- -m 提交信息
- 常用方式:
-
diff
对比
- 常用方式:
- 工作目录与暂存区对比 git diff
- 暂存区与commit对比 git diff --staged
- 工作目录与commitObject对比 git diff 引用(HEAD\HEAD^\branch\commit\tag)
- 常用方式:
-
show
查看一个commitObject,git show 引用,如果不写引用,则查看HEAD, -- 后面可带文件名
- 常用方式:
- git show (相当于查看HEAD指向的commitObject的修改的全部file)
- git show {引用,如branch/tag/commitId等} (相当于查看引用指向的commitObject的修改的全部file)
- git show {引用,如branch/tag/commitId等} -- {file,文件路径} (查看指定引用指向的commitObject里file的修改)
- 常用方式:
-
log
查看commit提交历史,其实就是查看第一父提交对象链路。这是一个很有用的指令
- 常用方式:
- -p 详细信息
- -(n) 查看几条
- --stat 简略信息
- --pretty=oneline 放在一行显示
- --oneline 短commitId
- --graph 合并、移动图
- --since --until 时间限制 --since=2.days
- -S 这个就牛逼了,可以根据字符串筛选 git log -Skael(找出修改里含kael的commitObject)
- -L git log -L :kael:index.js 可能有用
- git log 引用
- 常用方式:
-
fetch
更新远端仓库在本地的副本,就是更新remote/origin,默认名称就是origin
-
merge
把目标引用指向的commitObject与HEAD指向的commitObject,再加上两个分支的分叉点所在的commitObject进行合并,然后再生成一个新的commitObject。此时这个新的commitObject对象里的父对象就有两个。同时把HEAD指向这个新的commitObject,当然,HEAD会带着它挂载的branch一起指向这个新的commitObject。
-
pull
fetch + merge
-
push
把当前 branch 的位置(即它指向的commitObject)上传到远端仓库,并把它的路径上的 commits 一并上传。其实这里说的commits是这个commitObject里第一父提交对象链。
- 常用方式:
- git push origin branch:branch
- git push origin --delete branch 删除远端分支
- git push origin --delete tag tagname 删除远端tag
- git push origin :branch 删除远端分支
- 常用方式:
-
tag
打标签,在tagname后加上引用则是给引用打tag,如果不写,则是HEAD。其实tag可以理解为一个不移动的branch,但是在Git里,tag比branch权重高,如果两者有冲突(重名),名字指向的一定是tag。
- 常用方式:
- git tag -a tagname -m '信息' 附注标签
- git tag -l --sort=-v:refname 倒序显示
- git tag tagname 轻量标签
- git push origin --tags 把标签推送到远端共享
- git tag -d tagname 删除本地标签 git push origin :refs/tags/tagname 删除远端标签
- 常用方式:
-
branch
git branch branchname 引用(不填则为HEAD) 创建一个指向引用的commitObject
- 常用方式:
- -a 查看所有分支
- -vv 查看对应的跟踪分支,也能是-v,两个v的话会显示关联的远端branch
- --merged --no-merged 过滤这个列表中已经合并或尚未合并到当前分支的分支
- -d -D 删除分支
- -u 设置上游分支
- -m oldBranchName newBranchName (更名)
- git remote update origin -p 更新远端分支列表
- 常用方式:
-
checkout
签出commitObject到工作目录,如果工作目录存在 [M 的文件,则git会阻止签出。同时把HEAD指向签出的commitObject。git checkout file 把文件从暂存区复制,再替换掉工作区文件。在这里再解释一个现象,那就是,有的时候我们切换分支,git checkout branch很顺利,但如果在切换分支之前,你对项目里的文件作了修改,也就是 [M 类型的文件,那么你是切不了分支的,除非你修改的文件的快照与你要切换的分支上的文件快照一样。比如,你从master分支上新建了一个test分支,现在这个分支你都没向前走,那么你不管怎么修改文件,你都能在这两个分支之间自由切换。如果你理解了引用,那你一定知道,这个时候,这两个分支其实是全等的,master与test都指向同一个commitObject。
-
rebase
变基,(实质就是改变commitObject对象里的父对象链);与merge不同,merge是把目标合过来,变基是把‘目标分支’移到基准分支上。变基的风险,切记不要对在你的仓库外有副本的分支执行变基。也就是说,你变基的目标分支一定要是你的本地分支。推到远端的分支不要变基!!会导致这个分支推不了代码,合并不了等问题,最终只能回滚了。
- 常用方式:
- git rebase 基准分支 目标分支 (移动目标分支commits到基础分支,之后会自动切换到目标分支)
- git rebase --onto 基准点 (起点 终点] 基准点 --> 起点下一个commit --> ..... --> 终点 (终点最好写branch,如果写HEAD,则会把HEAD从branch脱离)
- 常用方式:
-
reset
撤销(实质就是移动HEAD),带着分支一起走(如果HEAD有关联branch,则会带着一起走。如果没有关联branch,则就是HEAD自己移动,此时效果跟checkout签出一样)
- 常用方式:
- git reset --soft 引用 把HEAD(带上branch)指向引用,其它不动
- git reset --mixed 引用 把HEAD(带上branch)指向引用,复制引用里的文件快照替换掉暂存区的文件。
- git reset --hard 引用 把HEAD(带上branch)指向引用,复制引用里的文件快照替换掉暂存区的文件,然后再复制暂存区的文件快照替换工作区文件。这个命令很危险,因为你工作区修改可能会丢失。
- 常用方式:
-
revert
反转(对某一个commitObject的内容进行反转,然后生成一个新的commitObject)。这里要提醒一下,当你对某一个commitObject进行了revert之后,你会发现,你不管怎么merge或查看changes,这个commitObject就是死活找不到,怎么合并也合并不过来,这就会导致你认为代码丢了。其实,只要记住,当你想把你revert掉的代码加进来的时候,你只要对这个revert的commitObject进行一次revert就行了。
-
cherry-pick(挑选樱桃?)
针对选择commitObject生成一个新的commitObject。 git cherry-pick (引用...引用]。cherry-pick的作用是,把某一个(一批)commitObject的文件快照(只有此commitObject里有修改的文件快照,不包含对其他commitObject文件快照的引用),挑选出来合并。
-
rev-parse
查看引用指向的CommitId (git rev-parse 引用)
-
reflog
引用日志
-
rename rm mv
改名, 删除, 移动
-
stash
暂存
- 常用方式:
- git stash save "save message":执行存储时,添加备注,方便查找,只有git stash 也要可以的,但查找时不方便识别。
- git stash list:查看stash了哪些存储
- git stash show:显示做了哪些改动,默认show第一个存储,如果要显示其他存贮,后面加stash@{$num},比如第二个 git stash show stash@{1}
- git stash show -p:显示第一个存储的改动,如果想显示其他存存储,命令:git stash show stash@{$num} -p ,比如第二个:git stash show stash@{1} -p
- git stash apply:应用某个存储,但不会把存储从存储列表中删除,默认使用第一个存储,即stash@{0},如果要使用其他个,git stash apply stash@{$num} , 比如第二个:git stash apply stash@{1}
- git stash pop:命令恢复之前缓存的工作目录,将缓存堆栈中的对应stash删除,并将对应修改应用到当前的工作目录下,默认为第一个stash,即stash@{0},如果要应用并删除其他stash,命令:git stash pop stash@{$num} ,比如应用并删除第二个:git stash pop stash@{1}
- git stash drop stash@{$num}:丢弃stash@{$num}存储,从列表中删除这个存储
- git stash clear:删除所有缓存的stash
- 常用方式:
-
blame
查看文件里每一行的修改者
- 常用方式:
git blame filename查看filename这个文件里没一行都是谁改的。
- 常用方式:
-
shortlog
汇总git日志输出。
- 常用方式:
git shortlog -sn会统计当前项目里,全部的commit。比如成员A有多少次提交,B有多少次。
- 常用方式:
-
for-each-ref
遍历引用,一般是搜索 refs/ 文件夹下的引用,比如 refs/tags
- 常用方式:
- git for-each-ref --count=1 --sort=-authordate refs/tags 也可以加上 --format 控制显示的格式,--sort后面的key一般是使用 objectsize,authordate,committerdate,creatordate,taggerdate等,其它的没什么意义
- 常用方式:
-
show-ref
显示引用集合
- 常用方式:
- git show-ref
- 常用方式:
-
偏移符
- 常用方式:
- ^ 父提交对象 ^2 第二父提交对象(merge时才会有) HEAD^(HEAD^1) HEAD^2
- ~n 前n个commitObject
- ^ 和 ~ 可以组件使用 git show HEAD~2^^
- 常用方式:
