

一、二进制
1、十进制转二进制
①问31如何凑成下列等式
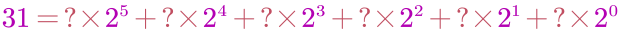
②答案为
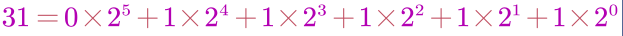
③那么31的二进制为011111
2、二进制转十进制
①二进制数字100011
②写出式子
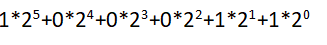
③最后上式等于35,即为100011的十进制表示
二、十六进制
1、优点
因为二进制写起来太慢了:
2、二进制转十六进制
- 二进制数:011110001011010
- 记住8421对应XXXX
- 从右往左每四位改写成一位:011 1100 0101 1010
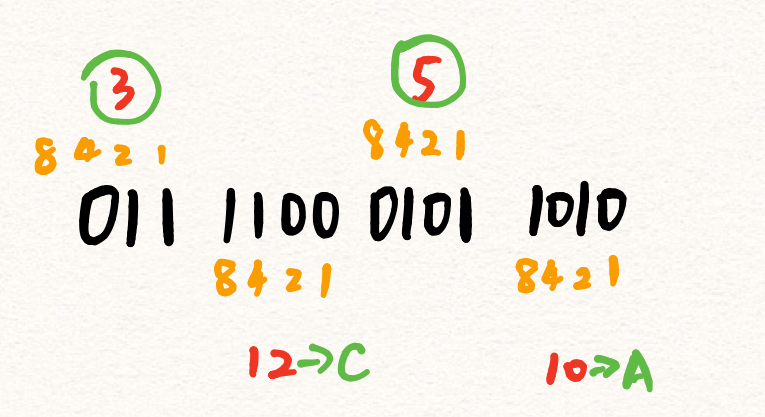
-
得到3,12,5,10
-
把大于9的数字改为ABCDEF
-
于是得到3C5A
3、16进制数:从0000到FFFF一共有62236个
- 一个16进制包含四个{由0和1组成的四个数字组合}的组合,所以一共有16个0或1。
- 所以总共有2的16次方=62236个16进制数字
3、用计算器的程序员模式
HEX表示16进制,BIN表示2进制 OCT表示8进制,DEC表示10进制
三、数字储存方式--存二进制数
把十进制的数字转成二进制便可储存
四、字符储存方式--字符编码--存编码
(一)ASCII 码
-
上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为 ASCII 码,一直沿用至今。
-
ASCII 码一共规定了128个英文字符的编码
-
编码方式:先把这128个字符按照顺序给它一个十进制数字(从0到127)来编号,如下图。
- 然后储存时便会把这些字符的十进制数字变成二进制数字储存
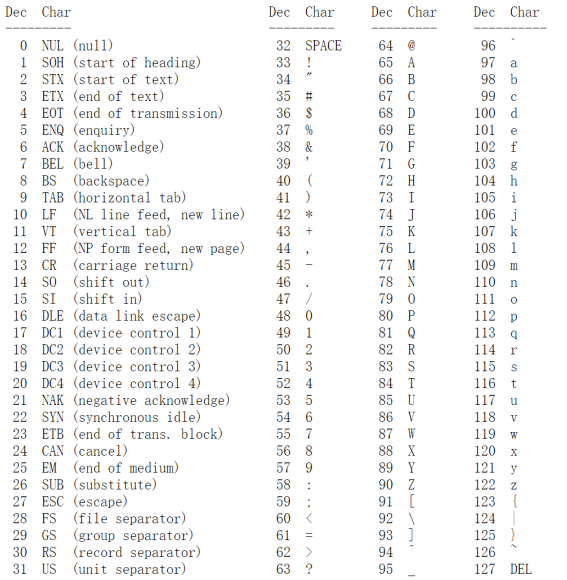
- 比如
- 0表示结束字符
- 10表示换行
- 13表示回车
- 32(二进制00100000)表示空格
- 33到47表示标点
- 48到57表示数字符号
- 49(二进制00110001)是数字符号1
- 65到90表示大写字母
- 65(二进制01000001)是大写的字母A
- 97到122表示小写字母
- 97(二进制01100001)是小写字母a
- 127表示删除键(二进制01111111)
- 2的七次方为128,所以128的二进制为1000 0000
- 因为这128个字符的十进制数最高是127(二进制111 1111),所以换成这128个字符在二进制里最多七位。
- 一个字节是八位
- 所以这128个符号,只占用了一个字节的后面7位,最前面的一位统一规定为0。
(二)GB2312
- 《信息交换用汉字编码字符集》是由中国国家标准总局1980年发布,1981年5月1日开始实施的一套国家标准,标准号是GB2312
- 共收入汉字6763个和非汉字图形字符682个。
- 编码方式:用16进制(从0000到FFFF)来编号。占用两个字节。然后储存时便会把这些十六进制数字变成二进制数字储存

- 例如
- 「你」的GB2312编号为C4E3
- 「牛」的GB2312编号为C5A3
(三)GBK
- 厂商微软利用GB2312未使用的编码空间,扩展了GB2312的范围,含21886个汉字和图形符号,收录了中日韩使用的几乎所有汉字,完全兼容GB2312
- 编码方式:同GB2312,用16进制(从0000到FFFF)来编号。占用两个字节。然后储存时便会把这些十六进制数字变成二进制数字储存
(四)Unicode万国码
- 将世界上所有的符号都纳入其中的一个字符集,已收录13万字符(大于16位),全世界通用。而且一直在更新中。
- 每个字符占三个及以上字节。所以很占内存。
- 字符编码UTF-8
(1) Unicode 的实现方式之一。
(2)它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
(3)这样就节省了不必要使用的空间
(4)UTF-8中8是指最少可用8位,也就是一个字节,来存一个字符
(5)例如存储「a」
- a对应的Unicode编号为97,十六进制为61
- Unicode直接存:00000000 00000000 01100001
- UTF- 8偷懒存法:01100001
- 三字节变一字节,比GBK还省
(6)例如存储「你」
- 你对应的Unicode编号为4F60
- Unicode直接存:00000000 01001111 01100000
- UTF-8偷懒存法:11100100 10111101 10100000
- 还是三字节,汉字似乎没有省,但是字母都能省一点
(7)UTF-8 的编码规则很简单,只有二条:
-
对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
-
对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
(8)举例:以「你a」为例
- 11100100 10111101 10100000 01100001
- 读8位信息11100100
- 发现开头有3个1,说明这个字符有3个八位
- 于是再读两个8位信息10111101 10100000
- 前面的10不要,其他合起来,得01001111 01100000
- 这就还原为Unicode的你了:00000000 01001111 01100000
- 再读8位信息01100001
- 发现开头是0,说明这个字符只占8位
- 这就还原味Unicode的a了:000000000000000001100001
五、问题
- 最后都是都是存数字0101010101,计算机咋知道你存的是数字的010101还是字符的01010101
- 答:计算机不知道。需要我们用一些辅助方式提醒计算机,比如加后缀(.txt就是存字符的编码,Excel就是存数字的数字)
