

什么是数据库设计?
数据库设计是指根据业务的需要,建立最适合的存储模型,使之能有效的存储和高效的访问。
优秀的设计可以让数据的存储和访问变得更加优雅。
| 好的设计 | 坏的设计 |
|---|---|
| 减少冗余 | 大量冗余 |
| 维护简单 | 易产生异常 |
| 节约 | 浪费 |
| 高效 | 低效 |
设计的步骤
如图所示,通常数据库设计分为:需求分析,逻辑设计,物理设计,维护优化。
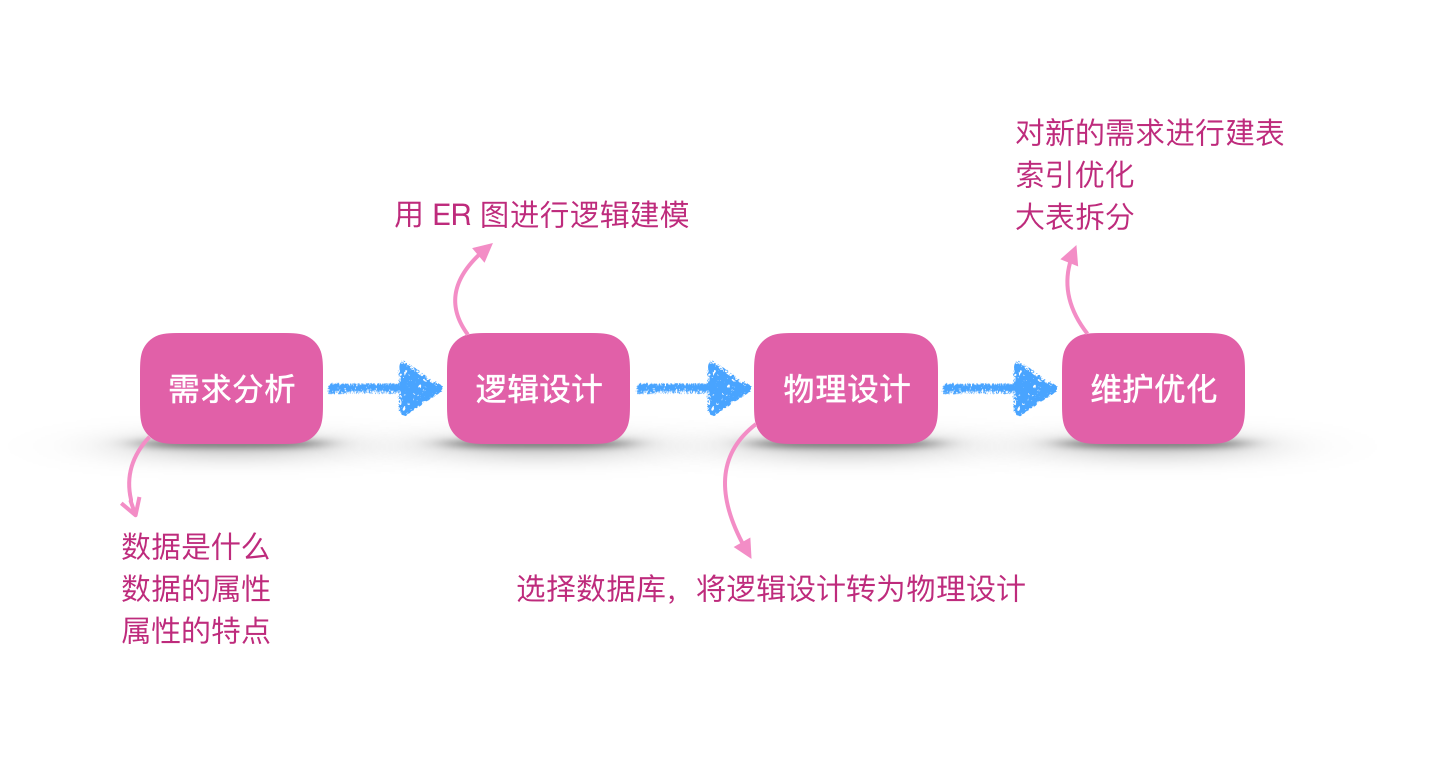
接下来,我们会对这四个步骤依次讲解。
需求分析
在进行需求分析的时候,我们需要了解所要存储的数据,及其存储特点和生命周期。
为此,我们需要搞清楚:
- 实体与实体之间的关系(1对1,1对多,多对多)
- 实体所包含的属性
- 哪些属性或属性的组合可以唯一标识一个实体。
逻辑设计
逻辑设计是指将需求转化为数据库的逻辑模型,通过 ER 图的形式对逻辑模型进行展示。它与所选用的具体的 DBMS 系统无关。
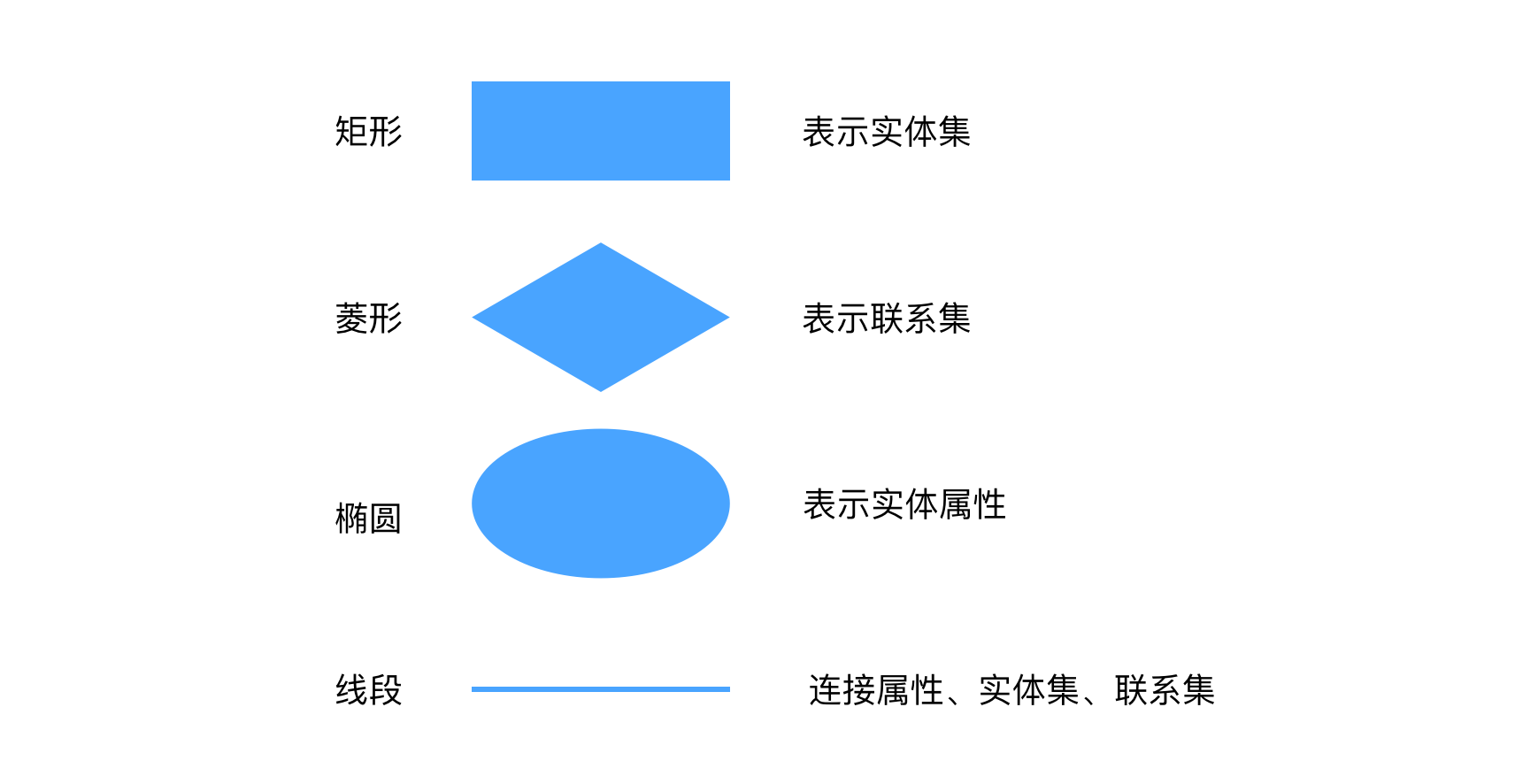
ER 图
ER 图例说明
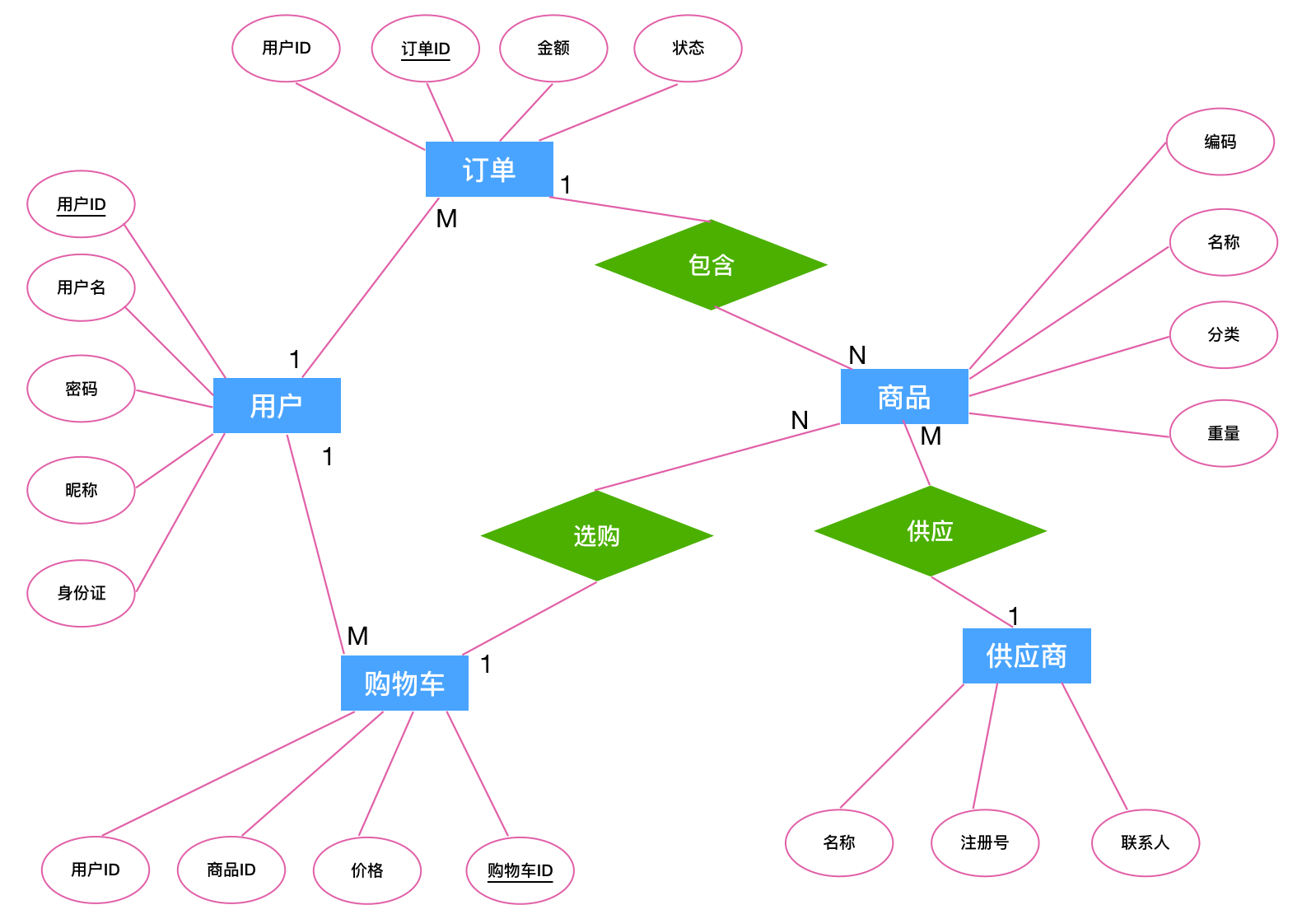
下面是一个简单的电商网站 ER 图示例
设计范式
上面电商网站示例中,用户信息和购物车信息是存在一张表中,还是单独存放?这就涉及到设计范式。
常见的数据库设计范式包括:
- 第一范式
- 第二范式
- 第三范式
- 以及 BC 范式
当然还有第四范式,第五范式。不过在这里我们会把重点放到前三个范式上,这也是大多数数据库设计所要遵循的范式。
遵循这些设计范式,将会极大地减少数据操作异常和冗余。
第一范式(1NF)
🌟 数据库表中的所有字段都是单一属性,不可再分。
换句话说,第一范式要求数据库中的表都是二维表。
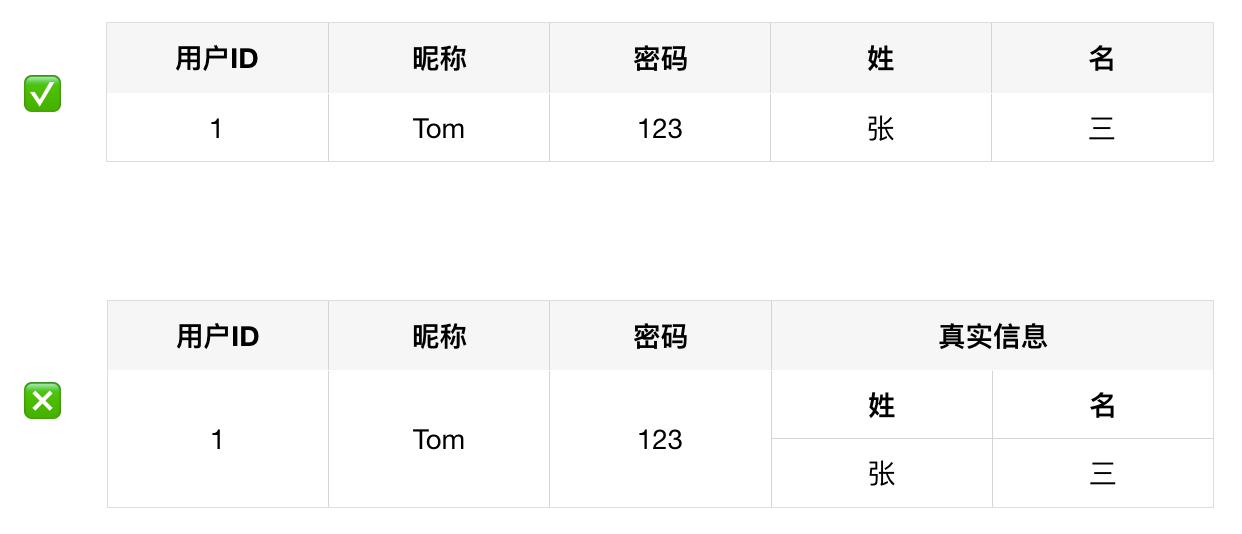
幸运的是,大多数的数据库系统都满足第一范式。
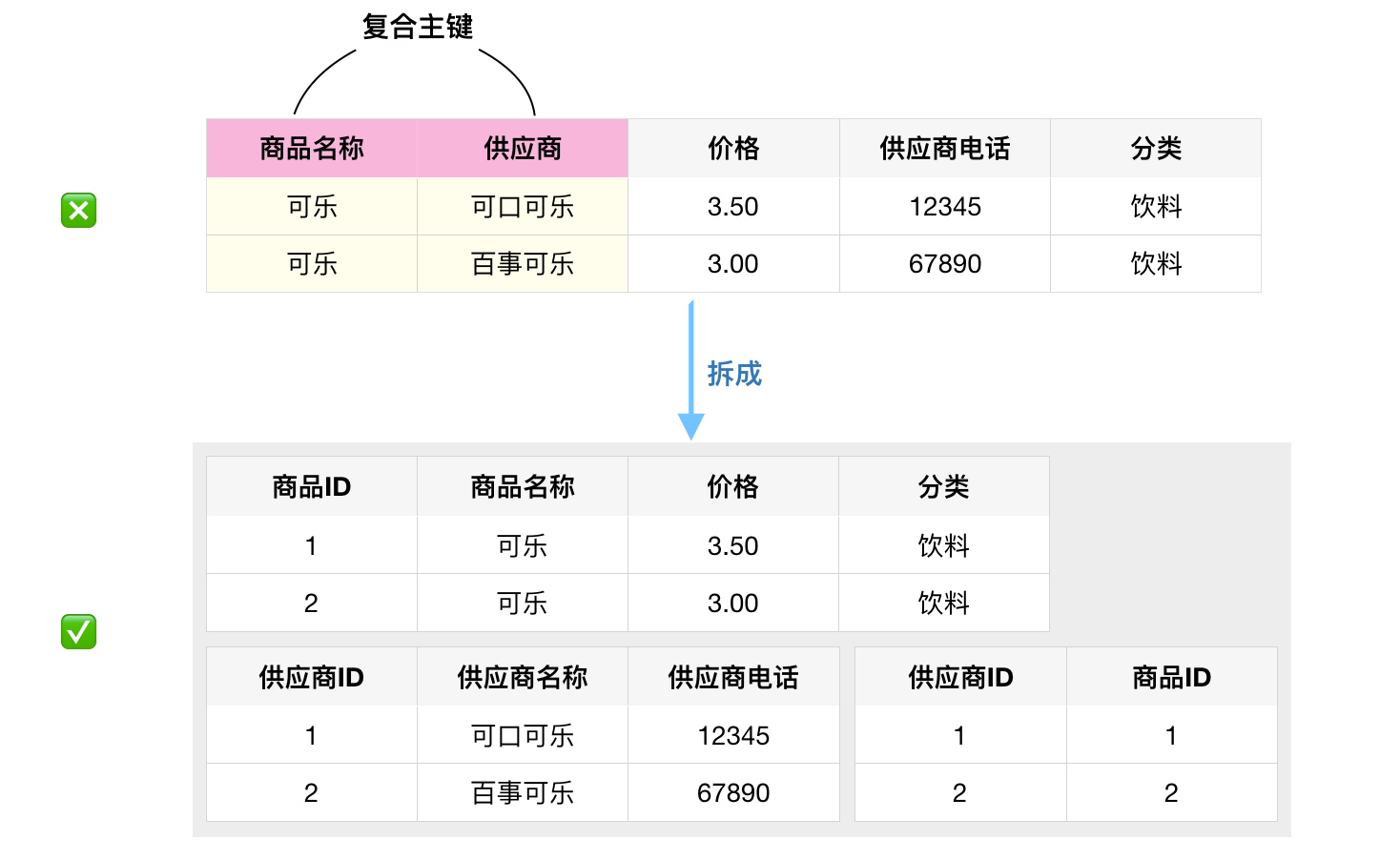
第二范式(2NF)
🌟 表中必须存在业务主键,并且非主键依赖于全部业务主键。
单关键字段的表都满足第二范式。
如下表,商品名称和供应商唯一决定了一条记录,是复合主键。
其中价格依赖于商品名称和供应商,但是供应商电话只依赖于供应商,分类只依赖于商品名称。故该表不满足第二范式。
可以对其拆分,使其满足第二范式。
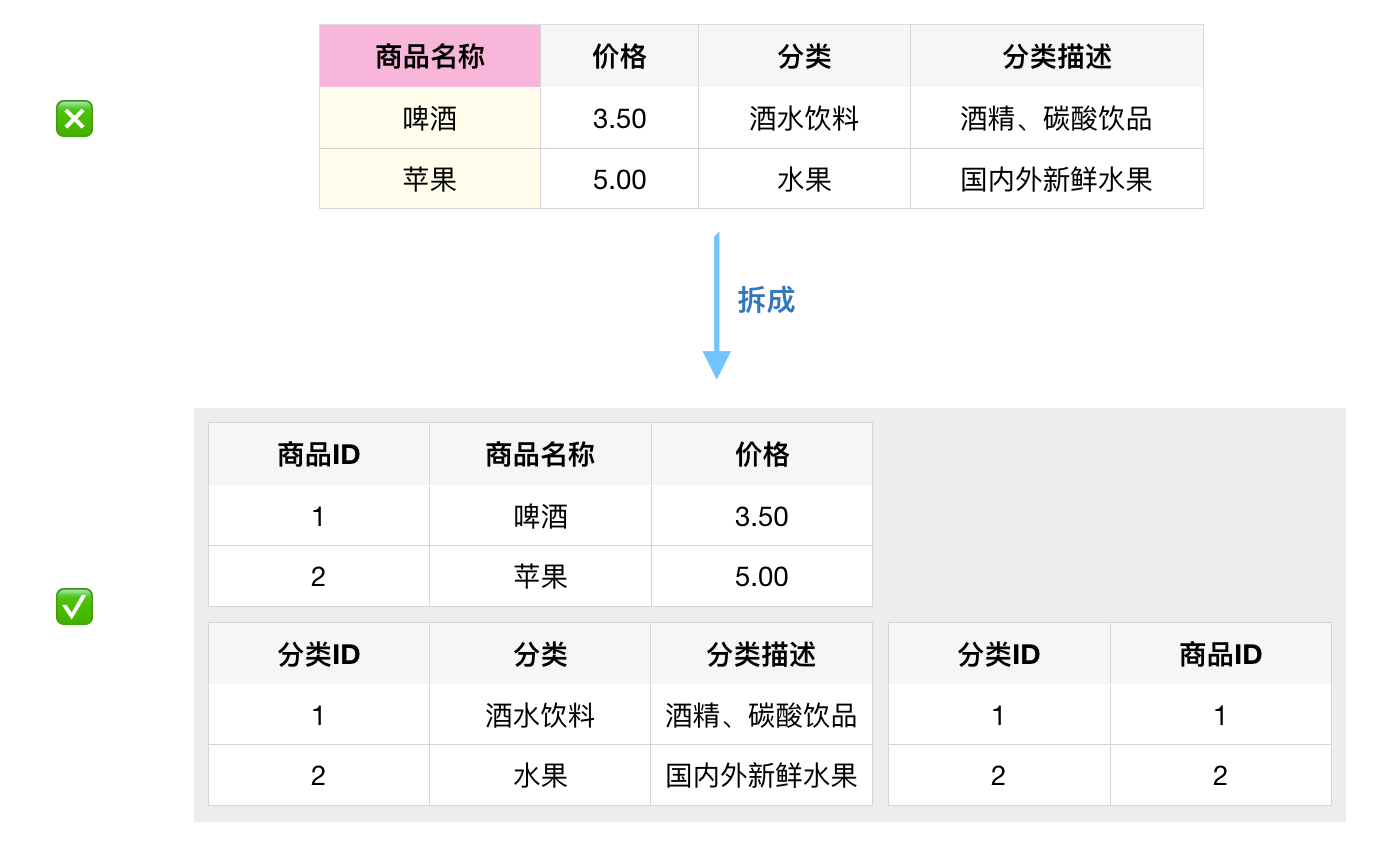
第三范式(3NF)
🌟 表中的非主键列之间不能相互依赖或者传递依赖。
下表中,商品名称是主键列,分类描述依赖于分类,分类依赖于商品名称,则分类描述传递依赖于商品名称。故不满足第三范式。
可以对其拆分,使其满足第三范式。
BC范式(BCNF)
🌟 表中复合关键字之间也不能相互依赖。
物理设计
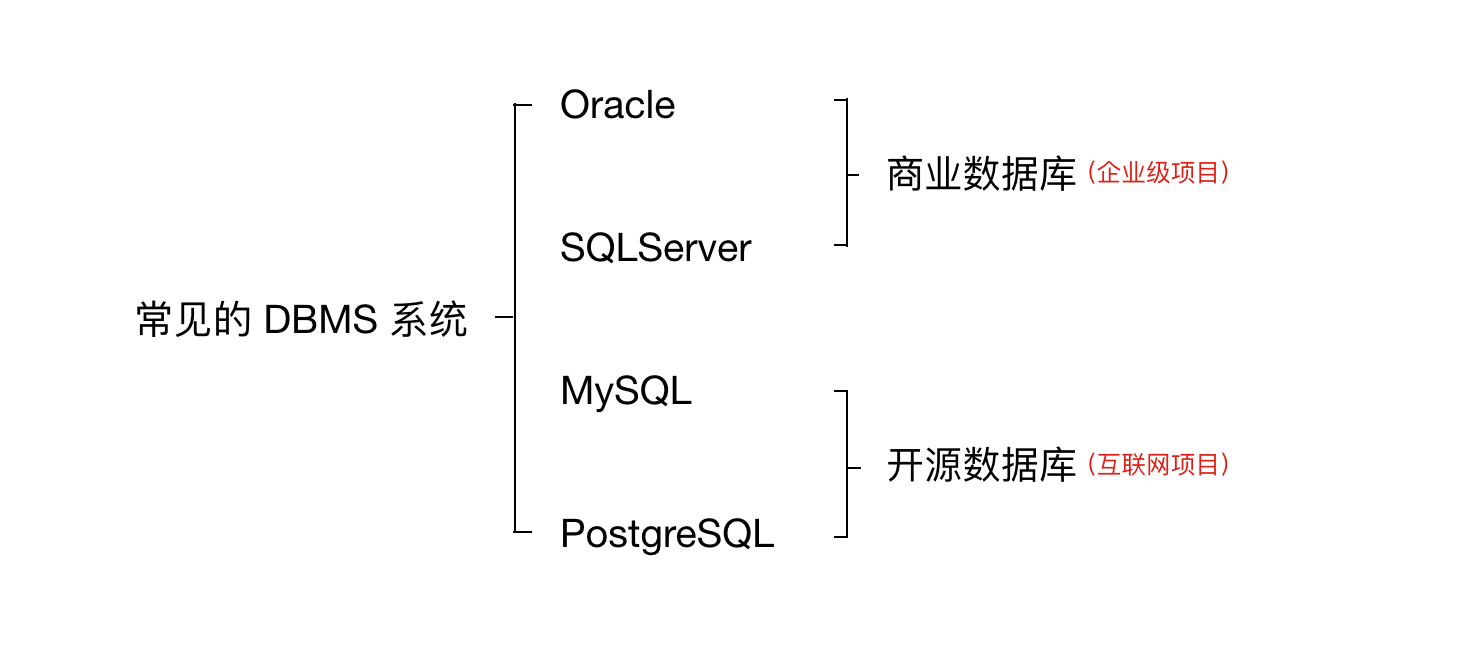
在物理设计阶段,我们首先要选择合适的数据库管理系统,如 Oracle、SQL Server、MySQL,PostgreSQL 等。接下来我们要定义数据库、表及字段的命名规范,然后根据所选的 DBMS 系统选择合适的字段类型。
选择数据库
根据预算及项目的特点选择合适的数据库。
商业数据库价格不菲,适合企业级的项目开发,比如业界口碑较好的 Oracle 。对于普通互联网公司使用免费开源的数据库是一种更好地选择,比如 MySQL 。
同时,还要考虑项目的具体应用场景,对于一些需要频繁使用事务操作的项目,如电商、银行、火车订票系统等,使用某些商业数据库会更好,因为在这些数据库中,事务操作的成本会更低。
另一方面,还要考虑使用的操作系统和编程语言。如 .NET 开发搭配 Windows Server 操作系统和 SQLServer 数据库会更方便。
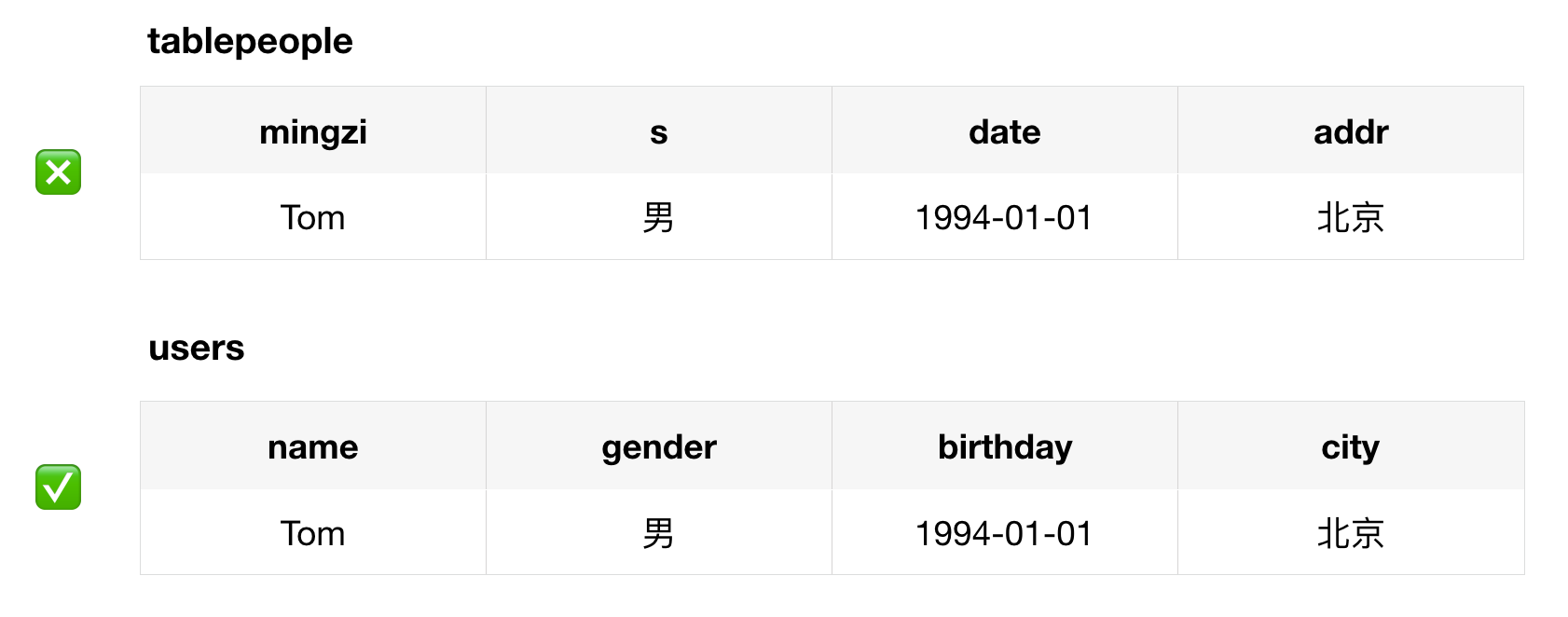
表及字段的命名规则
对象命名应遵循以下规则:
- 可读性原则。使用大小写或下划线来获得更好地可读性。
- 表意性原则。对象的名字应该能直观的描述该对象的含义。
- 长名原则。少使用缩写,多使用全名以消除歧义。不要使用拼音。
字段类型选择的原则
★ 优先选择数字类型,而不是字符串类型。
★ 对于相同数据类型,优先选择可用的存储空间最小的类型。如在 MySQL 中,能使用tinyint,就不要使用int。
以上的选择原则主要从以下两个方面考虑:
- 数据比较的时候,字符处理往往比数字慢。
- 数据从外存调入内存,列的数据长度越小,单次调入的数据总量就越多,越利于性能的提升。
反范式化
前面我们说了第三范式:表中的非主键列之间不能相互依赖或者传递依赖。
反范式化就是为了性能和读取效率,而适当的违反第三范式,允许存在少量的数据冗余。
有时候完全遵循第三范式,会导致频繁的表关联,反而使得查询效率降低。
即使用空间来换时间的策略。
反范式化要适度
维护和优化
要做什么?
- 维护数据字典(如将性别字段的
0和1所代表的含义记录在个人数据字典中) - 维护索引
- 维护表结构
- 适当对表进行拆分
维护数据字典
我们可以使用数据库本身的备注字段来维护数据字典。
以 MySQL 为例:
CREATE TABLE `users` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增 ID',
`name` varchar(50) NOT NULL COMMENT '用户名',
`gender` tinyint(1) DEFAULT 0 COMMENT '用户性别,0表示男,1表示女',
PRIMARY KEY (`id`)
);
则使用以下方式导出数据字典:
SELECT
TABLE_NAME,-- 表名
COLUMN_COMMENT,-- 列注释
COLUMN_NAME,-- 列名
COLUMN_TYPE -- 列的数据类型
FROM
information_schema.COLUMNS
WHERE
TABLE_NAME = 'users'
得到

维护索引
如何选择合适的列建立索引?
- 出现在
WHERE语句,GROUP BY从句,ORDER BY从句中的列 - 可选择性高的列要放到索引的前面
- 索引中不要包括太长的数据类型
索引不是越多越好,过多的索引会降低读写的效率。
维护表结构
维护什么?
- 对表本身的字段进行维护
- 对字典进行维护
- 控制表的宽度和大小
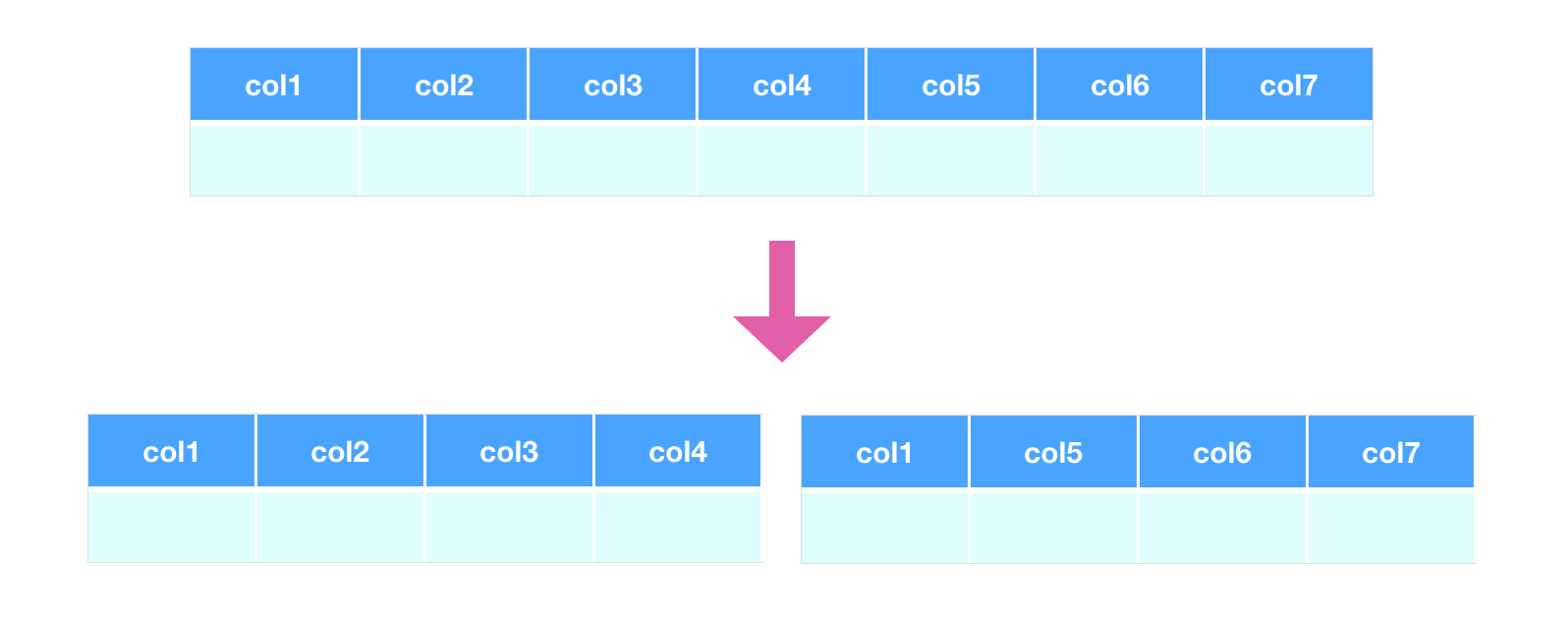
适当对表进行拆分
对宽表进行垂直拆分
将经常一起查询的列拆分到一个表中。对于text、blob等大字段拆分到附加表中。
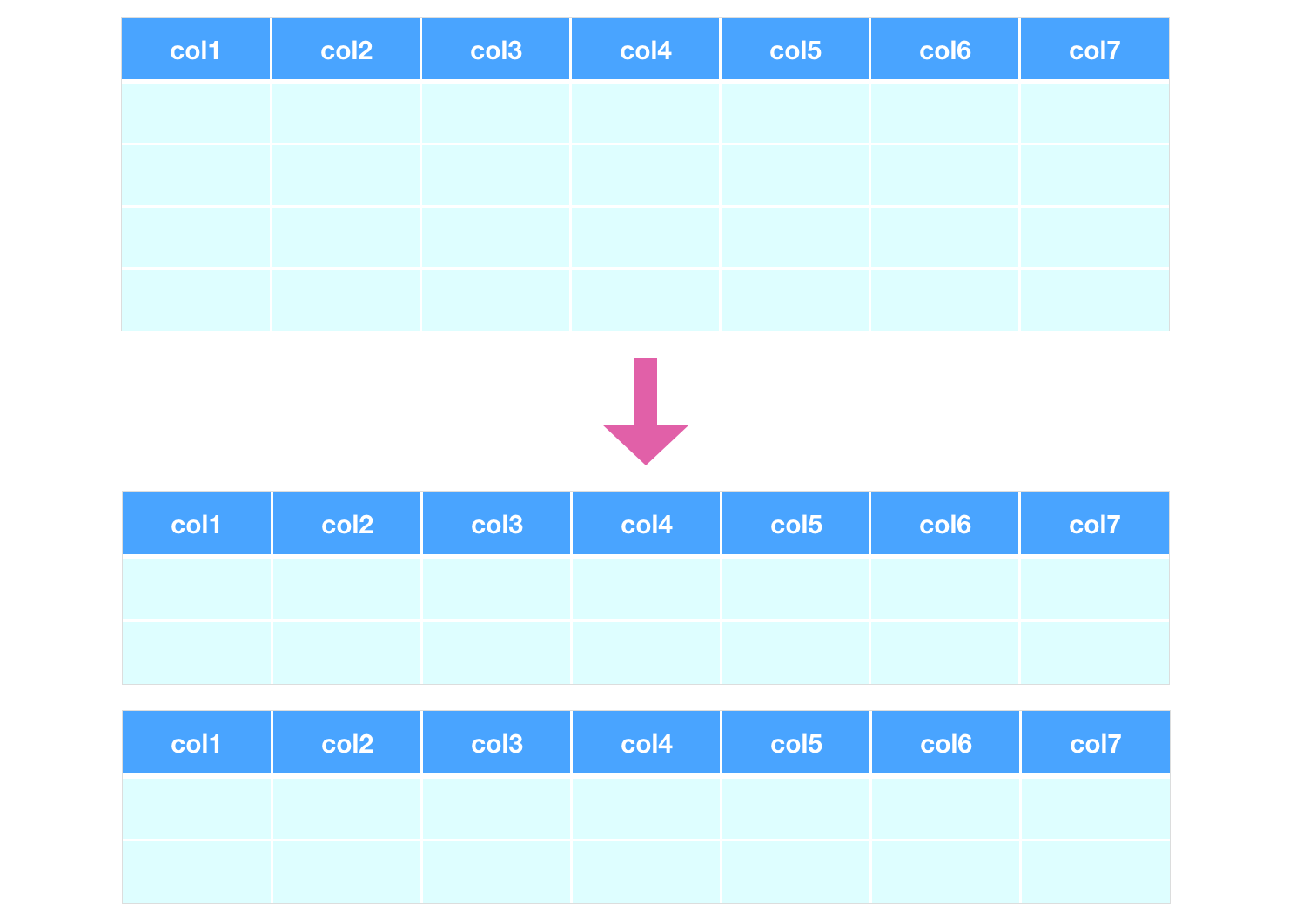
对长表进行水平拆分
可以通过对主键取哈希值,将一个大表水平拆分成若干小表。
That's all.
