

第1章 Mysql架构与历史
Mysql最重要、最与众不同的特性是他的存储引擎架构,这种架构的设计将查询处理及其他系统任务和数据的存储/提取隔离。这种处理和存储分离的设计可以在使用时根据性能、特性,以及其他需求来选择数据存储的方式。
1.1 Mysql逻辑架构
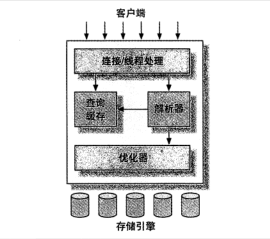
- 最上层是很多软件都有的基础服务层,大多数基于网络的客户端/服务器的工具或者服务都有类似的架构。(连接处理、授权认证、安全等)
- 第二层是Mysql特殊的一层,许多核心功能处于该层,包括查询解析、分析、优化、缓存、以及所有的内置函数,所有跨存储引擎的功能都在这里实现:如存储过程、触发器、视图等
- 第三层包含存储引擎。存储引擎负责Mysql中数据的存储和提取。我们大家所熟知的InnoDB(支持事务、默认锁粒度为行级锁),MyISAM(5.5版本之前是默认的引擎,并发性差,不支持事务,默认锁等级是表锁),MEMORY引擎等。
1.2 并发控制
- 出现并发访问情况时,使用共享锁或排它锁可解决问题,即读、写锁。
- 为了提高并发量可通过控制锁的粒度精准控制资源,但锁本身也需要消耗资源,所以需要在锁的粒度与安全找到一个平衡点,所以现在商业用法一般是行级锁即可
1.3 事务
- 事务四大特性:ACID(原子、一致、隔离、持久)。
1.3.1 隔离级别
隔离级别是SQL标准中定义,与软件无关。
- READ UNCOMMITTED 未提交读
- READ COMMITTED 提交读,解决了脏读(事务可以读取未提交的数据,也就是读取到了脏数据即为脏读)
- REPEATABLE READ 可重复读,解决了不可重复读(两次执行同一个查询,得到不一样的结果,着重结果差异)
- SERIALIZABLE 串行化执行,解决了幻读(某个事务在读取摸个范围内的记录时,另外一个事务又在该范围内插入了新的记录,当之前的事务再次读取时会产生幻行,InnoDB通过MVCC解决了这个问题,着重结果数不同)
1.3.2 死锁
死锁的四个必要条件:循环等待,请求与保持,不可剥夺性,互斥。
处理办法:在写业务代码时最好规定锁获取的优先级,如a,b锁,互相调用产生死锁,规定获取到了a的锁才能拿到b的锁时就不会出现此情况。
1.3.3 事务日志
mysql的事务日志可以提高事务的效率,采用的是追加的方式,类比redis的AOF备份类型(把每条写命令按顺序写入日志文件)。如果数据的修改记录到事务日志并持久化,但数据本身还没有写入,此时系统崩溃,存储引擎在重启时能够根据事务日志进行恢复。具体恢复方式与存储引擎类型有关。
1.4 多版本并发控制(MVCC)
Mysql大多数事务型存储引擎都不只是简单的行级锁,一般还实现了MVCC。
MVCC:mvcc的实现是通过保存某个时间点的快照来实现,不管需要执行多久,每个事务看到的数据是一样的,而事务的开始时间不同,则读取的数据可能不一样。InnoDB的mvcc是通过在每行记录后面保存两个隐藏列,一个保存了行的过期时间,一个保存了系统版本号,每开始一个事务,系统版本号递增,查询开始是记录当前系统版本号,如果查询结束时拿来比对是否相等。MVCC只在提交读和可重复读两个事务级别下使用,未提交读总是读取最新的数据行,不符合当前事务版本的数据行。而串行化会对所有读取的行加锁。
1.5 Mysql的存储引擎
1.5.1 InnoDB
InnoDB是Mysql默认的存储引擎,擅长处理大量短期事务。性能优良。
- 数据存储在表空间中,由一系列数据文件组成。
- 采用MVCC支持高并发,默认是可重复读,通过间隙锁(InnoDB不仅仅锁定查询涉及的行,还会对索引中的间隙进行锁定,以防止幻影行的插入)来防止幻读的问题。
- 基于聚簇索引而建立,对主键查询性能较高,不过他的二级索引中必须包含主键列,如果主键列很大,会导致其他的索引都会很大。因此表中索引较多时,主键应当尽可能小。
- 磁盘读取数据采用可预测性预读,能够自动在内存中创建hash索引以加速读操作的自适应哈希索引,以及能够加速插入操作的插入缓冲区等。
- 支持热备份,其他存储引擎不支持
1.5.2 MyISAM(主要是insert、select类的日志型应用)
不支持事务、不支持崩溃后的自我恢复,在使用只读数据,表比较小,可以忍受修复的情况下可以考虑使用MyISAM。
1.5.6 转换表的存储引擎
alter table test ENZGING = Innodb。
