

前言
前端入行三年多了,整天疲于业务,虽说业务能力突出,但却不知自己到底处在一个什么水平,突发奇想,用面试来检验自己,于是,开始了为期一个月的大厂面试尝试之路,总结如下:
1、函数柯里化
函数柯里化被问到过很多次,因为他名字听起来想到高端,面试官意在考验我们是否有意识的接触一些不常用的理论或者知识(说白了就是看你爱不爱学习)
那么,什么是函数柯里化?
维基百科上说道:柯里化,英语:Currying(果然是满满的英译中的既视感),是把接受多个参数的函数
变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数而且返回结果的新函数的技术。
这样的解释是不是有点突兀,我的通俗一点的理解就是多次调用函数只传一参数,上代码吧:
// 普通的add函数
function add(x, y) {
return x + y
}
// Curr后
function currAdd(x) {
return function (y) {
return x + y
}
}
add(1, 2) // 3
currAdd(1)(2) // 3
这样就实现了柯里化,你又会说了,这多简单,谁不会啊,那么你就错了,真正难的在下面呢,让你实现一个函数传入一个普通函数,给这个函数转化成一个柯里化函数,废话少说,上代码:
// 初步封装
var currying = function(fn) {
// args 获取第一个方法内的全部参数
var args = Array.prototype.slice.call(arguments, 1)
return function() {
// 将后面方法里的全部参数和args进行合并
var newArgs = args.concat(Array.prototype.slice.call(arguments))
// 把合并后的参数通过apply作为fn的参数并执行
return fn.apply(this, newArgs)
}
}
当然,这是初步封装你想要实现多次调用,这是就得在加点东西了
// 支持多参数传递
function progressCurrying(fn, args) {
var _this = this
var len = fn.length;
var args = args || [];
return function() {
var _args = Array.prototype.slice.call(arguments);
Array.prototype.push.apply(args, _args);
// 如果参数个数小于最初的fn.length,则递归调用,继续收集参数
if (_args.length < len) {
return progressCurrying.call(_this, fn, _args);
}
// 参数收集完毕,则执行fn
return fn.apply(this, _args);
}
}
如此一个柯里化函数算是小有所成了
2、js实现call,apply,bind 方法
其实这是个老生常谈的问题,基本大厂都绕不过这些原理基础就不说废话了,直接上代码,请在理解原理的基础上,背下来:
模拟call
// 模拟 call bar.mycall(null);
//实现一个call方法:
Function.prototype.myCall = function(context) {
//此处没有考虑context非object情况
context.fn = this;
let args = [];
for (let i = 1, len = arguments.length; i < len; i++) {
args.push(arguments[i]);
}
context.fn(...args);
let result = context.fn(...args);
delete context.fn;
return result;
};
模拟apply
// 模拟 apply
Function.prototype.myapply = function(context, arr) {
var context = Object(context) || window;
context.fn = this;
var result;
if (!arr) {
result = context.fn();
} else {
var args = [];
for (var i = 0, len = arr.length; i < len; i++) {
args.push("arr[" + i + "]");
}
//此处使用eval是为了给数组解析成一个个形参,这个地方我的理解是调用了toString方法的隐式转
//换才导致出现这种情况,只有有声明定义的变量eval函数才不会报错,
result = eval("context.fn(" + args + ")");
}
delete context.fn;
return result;
};
模拟bind
// mdn的实现
if (!Function.prototype.bind) {
Function.prototype.bind = function(oThis) {
if (typeof this !== 'function') {
// closest thing possible to the ECMAScript 5
// internal IsCallable function
throw new TypeError('Function.prototype.bind - what is trying to be bound is not callable');
}
var aArgs = Array.prototype.slice.call(arguments, 1),
fToBind = this,
fNOP = function() {},
fBound = function() {
// this instanceof fBound === true时,说明返回的fBound被当做new的构造函数调用
return fToBind.apply(this instanceof fBound
? this
: oThis,
// 获取调用时(fBound)的传参.bind 返回的函数入参往往是这么传递的
aArgs.concat(Array.prototype.slice.call(arguments)));
};
// 维护原型关系
if (this.prototype) {
// Function.prototype doesn't have a prototype property
fNOP.prototype = this.prototype;
}
// 下行的代码使fBound.prototype是fNOP的实例,因此
// 返回的fBound若作为new的构造函数,new生成的新对象作为this传入fBound,新对象的__proto__就是fNOP的实例
fBound.prototype = new fNOP();
return fBound;
};
}
当然这个bind是用来理解的,一般情况下,面试官为了让都会让在不用call或者apply的情况下实现一个bind,其实你细品就会发现bind是个柯里化函数,然后给使用apply的地方给替换成apply源码的写法就成就了一个简单的bind,上代码:
Function.prototype.myBind = function (context) {
let self = this; //此时this指向 test
//为了不用call
//let arg = Array.prototype.slice.call(arguments, 1);
let arg = [...arguments].slice(1)
let fNOP = function () { };
let fbound = function () {
// let innerArg = Array.prototype.slice.call(arguments);
// 此时arguments为传进来的参数,转换成数组
let innerArg = [...arguments]
let totalArg = arg.concat(innerArg);
// 拼接bind进来的参数与bind之后调用的参数 作为test的参数
// return self.apply(context, totalArg);
context.fn = self;
var result;
var args = [];
for (var i = 0, len = totalArg.length; i < len; i++) {
args.push("arr[" + i + "]");
}
if (args.length > 0) {
//此处使用eval是为了给数组解析成一个个形参
//这个地方我的理解是调用了toString方法的隐式转
//换才导致出现这种情况,只有有声明定义的变量eval函数才不会报错,
result = eval("context.fn(" + args + ")");
delete context.fn;
return result;
} else {
result = context.fn()
delete context.fn;
return result
}
}
fNOP.prototype = this.prototype;
fbound.prototype = new fNOP();
return fbound;
}
var a = {
d: function () {
}
}
function b() {
console.log(this)
}
var c = b.myBind(a)
c();
到此为止一个自定义的bind函数就完成了
3、实现防抖和节流函数
防抖节流也是被问到最多的问题,所谓不会防抖节流,怎能代码天秀,好,先来防抖
防抖
防抖函数原理:在事件被触发n秒后再执行回调,如果在这n秒内又被触发,则重新计时。
深入理解防抖原理之后注意一定要深入理解,因为面试官可能会问你这么写的目的,如果不深入理解原理你可能会被问的哑口无言。 我们来手写一个简化版的防抖
// 防抖函数
const debounce = (fn, delay) => {
let timer = null;
return (...args) => {
clearTimeout(timer);
timer = setTimeout(() => {
fn.apply(this, args);
}, delay);
};
};
适用场景:
按钮提交场景:防止多次提交按钮,只执行最后提交的一次
服务端验证场景:表单验证需要服务端配合,只执行一段连续的输入事件的最后一次,还有搜索联想词功能类似
节流
节流函数原理:规定在一个单位时间内,只能触发一次函数。如果这个单位时间内触发多次函数,只有一次生效。
我们来手写一个简化版的节流,注意还是要自己深入理解原理
/ 节流函数
const throttle = (fn, delay = 500) => {
let flag = true;
return (...args) => {
if (!flag) return;
flag = false;
setTimeout(() => {
fn.apply(this, args);
flag = true;
}, delay);
};
};
4、http、浏览器相关知识
这个绝对是大厂必问,私以为大厂招人已经不看业务能力和项目经验怎样了,他们需要底子好,表达能力强(很多大牛就是因为理解这个东西的意思但是表达不出来,而被拒之门外),并且业务能力突入的人,这样这些http以及tcp/ip协议相关的知识显得尤为的重要,但是大多相关文章介绍都是通篇连个标点符号都没有,读起来味同嚼蜡,我们有怎能提炼出考点来供大家参考记忆呢,下面某就站在巨人的肩膀上来总结一下相关知识。
现在看张图
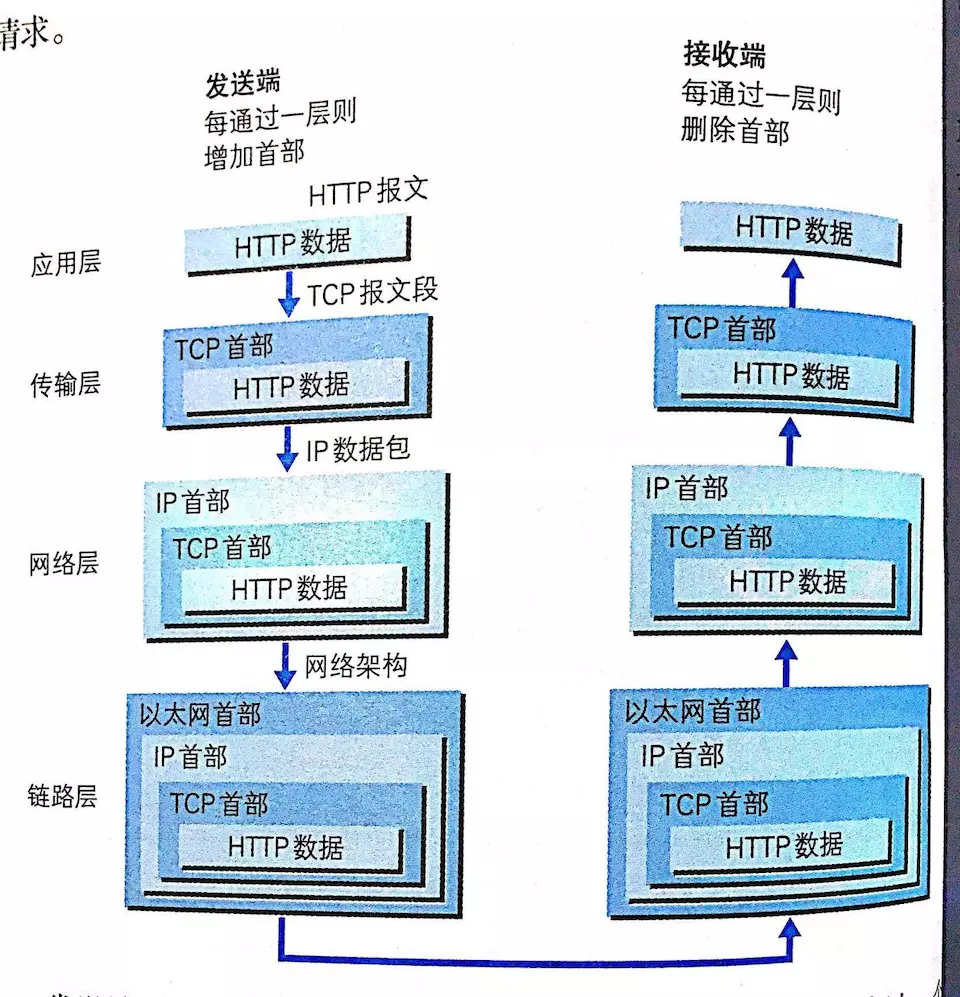
1、在浏览器输入地址发生了什么?
1、浏览器(客户端)进行地址解析。
2、将解析出的域名进行dns解析。
3、通过ip寻址和arp,找到目标(服务器)地址。
4、进行tcp三次握手,建立tcp连接。
5、浏览器使用http协议发送数据,等待服务器响应。
6、服务器处理请求,并对请求做出响应。
7、浏览器收到服务器响应,得到html代码。
8、渲染页面。
通过以上这些步骤,就完成了一次完整的http事务
2、说说浏览器缓存
浏览器缓存是前端性能优化中最重要的一个环节,相比于dns预解析,减少http请求,开启gzip,懒加载,cdn等一些手段,浏览器启用缓存至少有两点显而易见的好处:
(1)减少页面加载时间;
(2)减少服务器负载;
前端缓存如果用的好,效果可谓立竿见影,我们先来看一个前端判断缓存流程图:
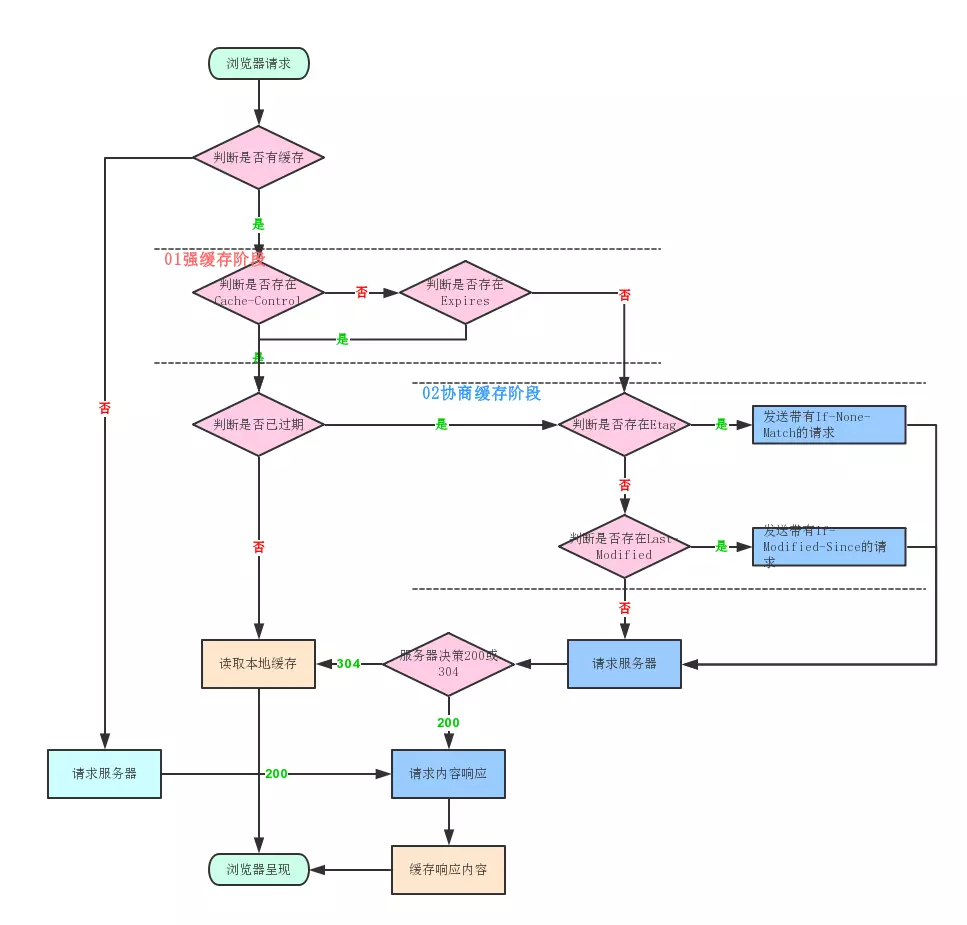
浏览器中缓存可分为强缓存和协商缓存:
1)浏览器在加载资源时,先根据这个资源的一些http的header判断它是否命中强缓存,强缓存如果命中,浏览器直接从自己的缓存中读取资源,不会发请求到服务器。比如:某个css文件,如果浏览器在加载它所在的网页时,这个css文件的缓存配置命中了强缓存,浏览器就直接从缓存中加载这个css,连请求都不会发送到网页所在服务器;
2)当强缓存没有命中的时候,浏览器一定会发送一个请求到服务器,通过服务器端依据资源的另外一些http header验证这个资源是否命中协商缓存,如果协商缓存命中,服务器会将这个请求返回,但是不会返回这个资源的数据,而是告诉客户端可以直接从缓存中加载这个资源,于是浏览器就又会从自己的缓存中去加载这个资源;
3)强缓存与协商缓存的共同点是:如果命中,都是从客户端缓存中加载资源,而不是从服务器加载资源数据;区别是:强缓存不发请求到服务器,协商缓存会发请求到服务器。
4)当协商缓存也没有命中的时候,浏览器直接从服务器加载资源数据。
强缓存
强缓存是利用Expires或者Cache-Control这两个http response header实现的,它们都用来表示资源在客户端缓存的有效期。
Expires是HTTP 1.0提出的一个表示资源过期时间的header,它描述的是一个绝对时间,由服务器返回,用GMT格式的字符串表示,如:Expires:Thu, 31 Dec 2037 23:55:55 GMT,包含了Expires头标签的文件,就说明浏览器对于该文件缓存具有非常大的控制权。
Cache-Control,是HTTP1.1的时候,提出了一个新的header,就是这是一个相对时间,在配置缓存的时候,以秒为单位,用数值表示,如:Cache-Control:max-age=315360000
这两个header可以只启用一个,也可以同时启用,当response header中,Expires和Cache-Control同时存在时,Cache-Control优先级高于Expires:
协商缓存
协商缓存是利用的是【Last-Modified,If-Modified-Since】和【ETag、If-None-Match】以及Cache-Control的Header来管理的。
简单的描述完缓存的一些概念之后,我们问题来了:
3、Cache-Control包括哪些特性呢?
第一,可缓存性:public private no-cache。可缓存性指http的response进过的哪些地方可以进行缓存。public指在response返回经过的任何地方都可以缓存,包括代理服务器,客户端等,这样下次请求将不会到达服务端而直接返回response;private则表示只有返回的浏览器才可以进行缓存;no-cache则表示不可直接用缓存,而是先要到服务器端进行验证。
第二,到期:max-age=,代表缓存的时间(秒);s-maxage=,专门为代理服务器设置,如果与max-age同时返回,则浏览器会读取max-age,而代理服务器则会读取s-maxage这个设置;max-stale=,代表在max-age过期后,如果存在max-stale,而且其时间没有过期,则表示仍然可以用缓存,max-stale只在request发起端设置是有用的,又因为浏览器不会帮助我们带上这个头,所以客户端是浏览器的时候这个max-stale是用不到的。
第三,重新验证:must-revalidate和proxy-revalidate,这两个表示缓存过期时间到达以后,必须要到服务端重新请求和重新验证,这两个属性在浏览器也不怎么出现。
第四,其他,no-store,表示本地和代理服务器都不可以用缓存,必须去重新获取;no-transform,告诉代理服务器不要对返回的body进行处理,比如压缩等(代理服务器比如nginx等可以不遵守,但是这个是规范,最好遵守)。
需要注意的是Cache-Control:no-cache这个字段是是如果在请求头中,则表示浏览器没有缓存,必须重新请求资源
4、HTTP的keep-alive是干什么的?
在早期的HTTP/1.0中,每次http请求都要创建一个连接,而创建连接的过程需要消耗资源和时间,为了减少资源消耗,缩短响应时间,就需要重用连接。在后来的HTTP/1.0中以及HTTP/1.1中,引入了重用连接的机制,就是在http请求头中加入Connection: keep-alive来告诉对方这个请求响应完成后不要关闭,下一次咱们还用这个请求继续交流。协议规定HTTP/1.0如果想要保持长连接,需要在请求头中加上Connection: keep-alive。
HTTP2相对于HTTP1.x有什么优势和特点?
1)HTTP/2 采用二进制格式传输数据,而非 HTTP 1.x 的文本格式,二进制协议解析起来更高效。
2)HTTP/2在客户端和服务器端使用“首部表”来跟踪和存储之前发送的键-值对,对于相同的数据,不再通过每次请求和响应发送
3)服务器推送
4)同域名下所有通信都在单个连接上完成,单个连接可以承载任意数量的双向数据,数据流以消息的形式发送,而消息又由一个或多个帧组成,多个帧之间可以乱序发送,因为根据帧首部的流标识可以重新组装
跨域问题
说起http,就不得不提到跨域问题,虽说这个跨域是浏览器同源策略导致,却是发起http请求的时候触发 解决跨域问题有很多方法,比如jsonp,比如nginx,比如postMessage跨域,不如window.name + iframe 跨域等等,我们今天要说的确实cors,因为这个解决跨域的方法是在响应头中去增加允许跨域的字段
-
Access-Control-Allow-Origin :该字段是必须的。它的值要么是请求时Origin字段的值,要么是一个*,表示接受任意域名的请求
-
Access-Control-Allow-Credentials: 该字段可选。它的值是一个布尔值,表示是否允许发送Cookie。默认情况下,Cookie不包括在CORS请求之中。设为true,即表示服务器明确许可,Cookie可以包含在请求中,一起发给服务器。这个值也只能设为true,如果服务器不要浏览器发送Cookie,删除该字段即可。
-
Access-Control-Expose-Headers:该字段可选。CORS请求时,XMLHttpRequest对象的getResponseHeader()方法只能拿到6个基本字段:Cache-Control、Content-Language、Content-Type、Expires、Last-Modified、Pragma。如果想拿到其他字段,就必须在Access-Control-Expose-Headers里面指定。
cookie相关 http是一个不保存状态的协议,什么叫不保存状态,就是一个服务器是不清楚是不是同一个浏览器在访问他,所以有了cookie的出现,并且可以由服务端通过响应头写入下面我们开说说cookie原理:
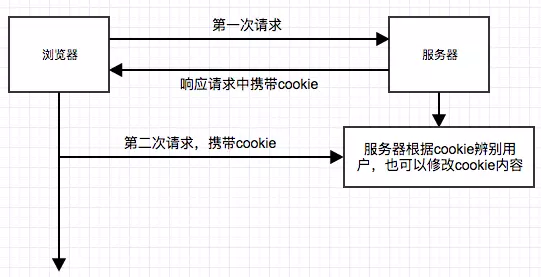
使用cookie有哪些可能引起前端安全的的问题?
xss:用户通过各种方式将恶意代码注入到其他用户的页面中。就可以通过脚本获取信息,发起请求,之类的操作。
csrf:跨站请求攻击,简单地说,是攻击者通过一些技术手段欺骗用户的浏览器去访问一个自己曾经认证过的网站并运行一些操作(如发邮件,发消息,甚至财产操作如转账和购买商品)。由于浏览器曾经认证过,所以被访问的网站会认为是真正的用户操作而去运行。这利用了web中用户身份验证的一个漏洞:简单的身份验证只能保证请求发自某个用户的浏览器,却不能保证请求本身是用户自愿发出的。csrf并不能够拿到用户的任何信息,它只是欺骗用户浏览器,让其以用户的名义进行操作。
5、前端算法相关
算法相关的题在前端面试中的比重越来越高,当然最有效的方法是去LeetCode上刷题,什么排序,查找算法,这些就不在赘述了,网上一大推,某再此列举在大厂中被问到但没解出来的几道题目:
模板引擎实现
function render(template, data) {
const reg = /\{\{(\w+)\}\}/; // 模板字符串正则
if (reg.test(template)) { // 判断模板里是否有模板字符串
const name = reg.exec(template)[1]; // 查找当前模板里第一个模板字符串的字段
template = template.replace(reg, data[name]); // 将第一个模板字符串渲染
return render(template, data); // 递归的渲染并返回渲染后的结构
}
return template; // 如果模板没有模板字符串直接返回
}
let template = '我是{{name}},年龄{{age}},性别{{sex}}';
let data = {
name: '姓名',
age: 18
}
render(template, data); // 我是姓名,年龄18,性别undefined
查找字符串中出现最多的字符和个数
//查找出现最多的字符串的个数
let str = "abcabcabcbbccccc";
let num = 0;
let char = '';
// 使其按照一定的次序排列
str = str.split('').sort().join('');
// "aaabbbbbcccccccc"
// 定义正则表达式
let re = /(\w)\1+/g;
str.replace(re,($0,$1) => {
if(num < $0.length){
num = $0.length;
char = $1;
}
});
取出最大的三个数的下标
// 首先记录之前下标在排序,这样取出前三个就行了,然后在拿到下标就可以了
var arr = [1, 2, 65, 98, 87, 35, 7, 10, 6]
function retrunAarr(arr) {
var arr = arr.map((item, index) => {
return [item, index]
}).sort((a, b) => {
return b[0] - a[0]
})
console.log(arr)
}
//后面循环取出前三个即可
更新算法题
- 实现函数parse,将服务端返回的公交数据按下面定义的规则优先级输出:
-
- 输出常规线路,并按照线路数字从小到大排列(如20路,301路等这些都是常规路线)
-
- 输出地铁线路,并按照线路数字从小到大排序
-
- 输出其它线路,并按照线路名称长短从小到大排序
- parse的函数签名是:
- declare function parse(res: Object): Object;
- 下面代码为示例数据按照上述规则和函数签名转换后结果,请参照该示例数据实现对应效果
//开始的数据
var res = {
code: 0,
data: {
lines: '20路,301路,5路,地铁5号线,机场大巴线,107路,机场快轨',
lineids: 'lzbd,lwes,lxid,lwic,lwdf,ldfx,loin',
linedetails: {
lwdf: {
name: '机场大巴线'
},
lwes: {
name: '301路'
},
lwic: {
name: '地铁5号线'
},
ldfx: {
name: '107路'
},
lzbd: {
name: '20路'
},
lxid: {
name: '5路'
},
loin: {
name: '机场快轨'
}
}
}
}
//转换的结果
var data = [{
lxid: {
name: '5路'
}
}, {
lzbd: {
name: '20路'
}
}, {
ldfx: {
name: '107路'
}
}, {
lwes: {
name: '301路'
}
}, {
lwic: {
name: '地铁5号线'
}
}, {
loin: {
name: '机场快轨'
}
}, {
lwdf: {
name: '机场大巴线'
}
}]
function parse(res) {
var a = [], b = [], c = [];
res.data.lines.split(',').forEach(element => {
if (element.indexOf('路') > -1) {
a.push(element)
} else if (element.indexOf('地铁') > -1) {
b.push(element)
} else {
c.push(element)
}
});
var d = [a, b, c]
d.forEach(elem => {
elem.sort((a, b) => {
var s1 = a.replace(/[^0-9]/ig, "") || a.length;
var s2 = b.replace(/[^0-9]/ig, "") || b.length;
return s1 - s2
})
})
var f = d.flat();
var result = [], g = [];
var h =
f.forEach(item => {
g.push(res.data.lineids.split(',')[res.data.lines.split(',').indexOf(item)])
})
console.log(g)
g.forEach((item, index) => {
var obj = {};
obj[item] = res.data.linedetails[item]
result.push(obj)
})
console.log(result)
return result;
}
parse(res)
总结
此次面试之旅过程中,以上问题,被问的是哑口无言,记录一下,后期不定时更新,如有理解错误,欢迎大佬指正,以上许多语言组织取自掘金许多大佬的文章,再次表示感谢
站在巨人的肩膀上,定当加倍努力,点亮他人
