

一、添加邮件头,抄送等信息
1.mail["From"]表示发送者信息,包括姓名和邮件
2.mail["To"]表示接收者信息,包括姓名和邮件地址
3.mail["Subject"]表示摘要或者主题信息
[url=] [/url]
[/url]
[/url]from
email.mime.text import
MIMETextfrom
email.header import
Headermsg = MIMEText("
Hello world
"
,"
plain
"
,"
utf-8
"
)#
用utf-8编码是因为很可能内容包含非英文字符
header_from = Header("
从我自己的邮箱发送出去有的<1215217867@qq.com>
"
,"
utf-8
"
)#
就是邮件头,注意点:编解码格式相一致
msg["
From
"
] = header_fromheader_to = Header("
去我自己的邮箱1215217867@qq.com
"
,"
utf-8
"
)#
填写接收者的信息
msg["
To
"
] = header_toheader_sub = Header("
这是我的主题
"
,"
utf-8
"
)msg["
Subject
"
] = header_to#
构建发送者地址和登录信息
from_addr = "
1215217867@qq.com
"
from_pwd = ""
#
构建邮件接收者信息
to_addr ="
1215217867@qq.com
"
smtp_srv = "
smtp.qq.com
"
try
: import
smtplib srv = smtplib.SMTP_SSL(smtp_srv.encode(),465) srv.login(from_addr,from_pwd) srv.sendmail(from_addr,[to_addr],msg.as_string()) srv.quit()except
Exception as a: print
(a) [url=][/url]
[/url]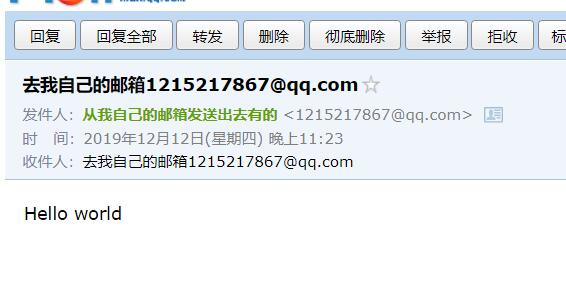
二、同时发送html和text格式
1.构建一个MIMEMutipart格式邮件
2.MIMEMultipart的subtype设置成alternative格式
3.添加HTML和text邮件
[url=][/url]
[/url]from
email.mime.text import
MIMETextfrom
email.mime.multipart import
MIMEMultipart#
构建一个MIMEMultipart邮件
msg = MIMEMultipart("
alternative
"
)#
构建一个HTML邮件内容
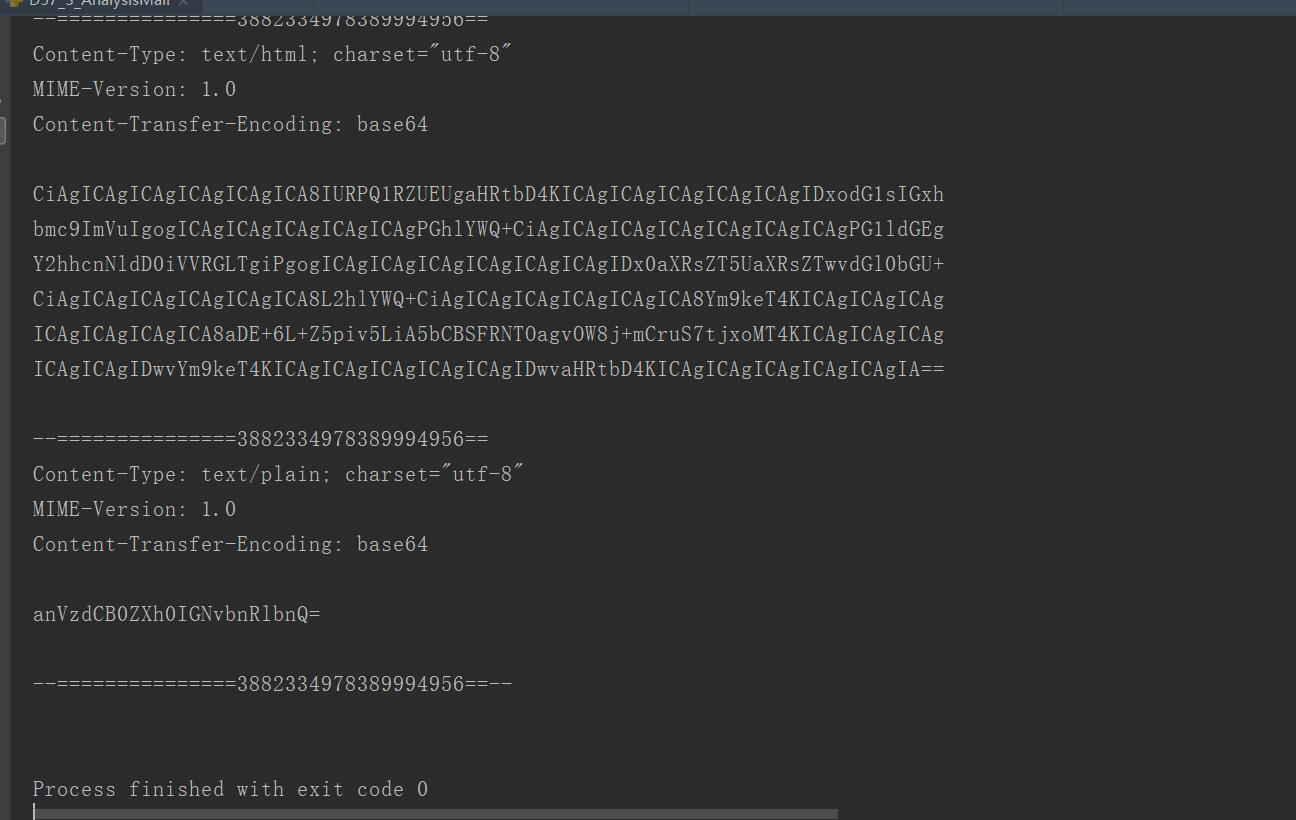
html_content = """
<!DOCTYPE html> <html lang="en" <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <h1>这是一封HTML格式邮件<h1> </body> </html>
"""
msg_html = MIMEText(html_content,"
html
"
,"
utf-8
"
)msg.attach(msg_html)msg_text = MIMEText("
just text content
"
,"
plain
"
,"
utf-8
"
)msg.attach(msg_text)#
发送email地址
#
构建发送者地址和登录信息
from_addr = "
1215217867@qq.com
"
from_pwd = ""
#
构建邮件接收者信息
to_addr = "
1215217867@qq.com
"
smtp_srv = "
smtp.qq.com
"
try
: import
smtplib srv = smtplib.SMTP_SSL(smtp_srv.encode(),465) srv.login(from_addr,from_pwd) srv.sendmail(from_addr,[to_addr],msg.as_string()) srv.quit()except
Exception as a: print
(a)[url=][/url]
[/url]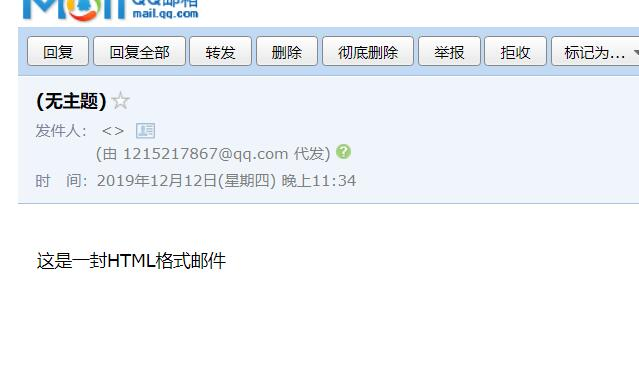
三、POP3协议接受邮件
1.本质上是MDA到MUA的一个过程
2.从MDA下载下来的是一个完整的邮件结构体,需要解析才能得到每个具体
3.步骤:
(1)用poplib下载邮件结构体原始内容
(2)准备相应的内容(邮件地址,密码,POP3实例)
(3)身份认证
(4)根据相应序号,得到某一封信的数据流
(5)利用解析函数进行解析出相应的邮件结构体
(6)用email解析邮件的具体内容
[url=][/url]
[/url]#
导入相关的包
#
poplib负责从MDA到MUA下载
import
poplib#
以下包负责相关邮件结构解析
from
email.parser import
Parserfrom
email.header import
Headerfrom
email.utils import
parseaddr#
得到邮件的原始内容
#
这个过程主要负责从MDA到MUA的下载并且使用Parse粗略解析
def
getMsg(): #
准备相应的信息
email ="
1215217867@qq.com
"
#
邮箱的授权码
pwd = ""
#
pop3服务器地址
pop3_srv = "
pop.qq.com
"
#
端口995
#
ssl代表安全通道
srv = poplib.POP3_SSL(pop3_srv) #
user代表email地址
srv.user(email) #
pass_代表密码
srv.pass_(pwd) #
以下操作根据具体业务具体使用
#
stat返回的是邮件数量以及占用空间
#
注意stat返回了一个tuple格式
msgs,counts = srv.stat() print
("
Message:{0},Size:{1}
"
.format(msgs,counts)) #
list返回所有邮件编号列表
#
mails是所有邮件编号列表
rsp,mails,octets = srv.list() #
可以查看返回的mails列表,类似于[b"1 82923",b"23 2184",.....]
print
(mails) #
获取最新一封邮件,追忆,邮件索引是从1开始的,最新代表索引号最高
index = len(mails) #
retr负责返回一个具体索引号的一封信的内容,此内容不具有可读性
#
lines存储邮件的最原始文本的每一行
rsp,lines,octets = srv.retr(index) #
获取整个邮件的结构体
msg_count = b"
\r\n
"
.join(lines).decode("
utf-8
"
) #
解析出邮件整个结构体
#
参数是解码后的邮件整体
msg = Parser().parsestr(msg_count)#
这一行代表解码
#
关闭链接
srv.quit() return
msgif
__name__
== "
__main__
"
: #
得到邮件的原始内容
msg = getMsg() print
(msg) #
精确解析邮件内容
#
parseMsg(msg,0)
[url=][/url]
[/url]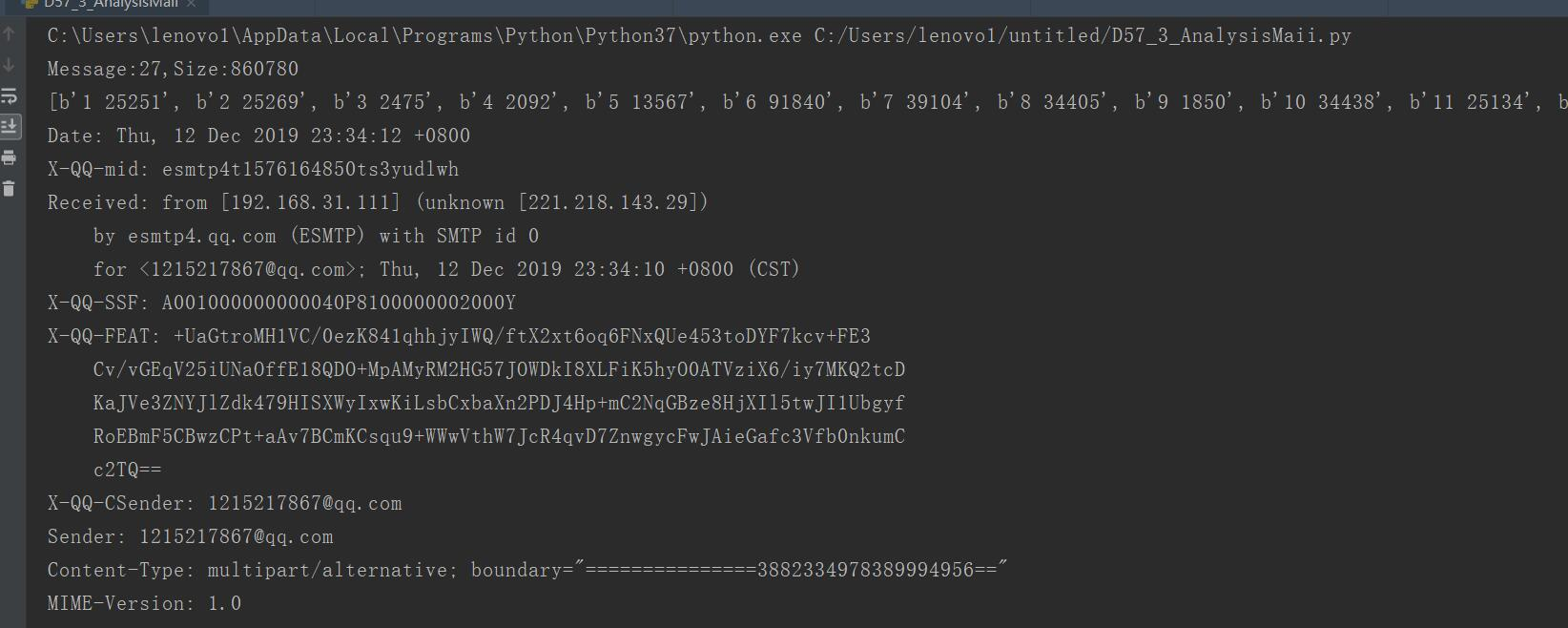
 五、源码
五、源码D57_1_MailHeadAndCC.py
D57_2_SendHTMLAndTextMail.py
D57_3_AnalysisMaii.py
https://github.com/ruigege66/Python_learning/blob/master/D57_1_MailHeadAndCC.py
https://github.com/ruigege66/Python_learning/blob/master/D57_2_SendHTMLAndTextMail.py
https://github.com/ruigege66/Python_learning/blob/master/D57_3_AnalysisMaii.py
更多技术资讯可关注:itheimaGZ获取
